Erstellen von Bewertungsskripts für Batchbereitstellungen
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Batchendpunkte ermöglichen es Ihnen, Modelle bereitzustellen, um zeitintensive Rückschlüsse im großen Stil durchzuführen. Beim Bereitstellen von Modellen müssen Sie ein Bewertungsskript (auch als Batchtreiberskript bezeichnet) erstellen und festlegen, um anzugeben, wie es für die Eingabedaten verwenden werden soll, um Vorhersagen zu erstellen. In diesem Artikel erfahren Sie, wie Sie Bewertungsskripts in Modellbereitstellungen für verschiedene Szenarien verwenden. Außerdem erfahren Sie mehr über bewährte Methoden für Batchendpunkte.
Tipp
MLflow-Modelle erfordern kein Bewertungsskript. Es wird automatisch generiert. Weitere Informationen zur Funktionsweise von Batchendpunkten mit MLflow-Modellen finden Sie in dem dedizierten Tutorial Verwenden von MLflow-Modellen in Batchbereitstellungen.
Warnung
Um ein automatisiertes ML-Modell unter einem Batchendpunkt bereitzustellen, beachten Sie, dass Automated ML ein Bewertungsskript bereitstellt, das nur für Onlineendpunkte funktioniert. Dieses Bewertungsskript ist nicht für die Batchausführung konzipiert. Befolgen Sie diese Richtlinien, um weitere Informationen zum Erstellen eines auf die Funktionsweise Ihres Modells angepassten Bewertungsskripts zu erhalten.
Grundlegendes zum Bewertungsskript
Das Bewertungsskript ist eine Python-Datei (.py), die angibt, wie das Modell ausgeführt und die Eingabedaten gelesen werden sollen, die der Batchbereitstellungsausführer übermittelt. Jede Modellbereitstellung stellt das Bewertungsskript (zusammen mit allen anderen erforderlichen Abhängigkeiten) zur Erstellungszeit bereit. Das Bewertungsskript sieht in der Regel wie folgt aus:
deployment.yml
code_configuration:
code: code
scoring_script: batch_driver.py
Das Bewertungsskript muss zwei Methoden enthalten:
Die init -Methode
Verwenden Sie die init()-Methode für aufwendige oder allgemeine Vorbereitungen. Ein Beispiel wäre etwa das Laden des Modells in den Speicher. Der Start des gesamten Batchauftrags ruft diese Funktion einmal auf. Die Dateien Ihres Modells sind in einem Pfad verfügbar, der von der Umgebungsvariablen AZUREML_MODEL_DIR bestimmt wird. Je nachdem, wie Ihr Modell registriert wurde, sind die Dateien möglicherweise in einem Ordner enthalten. Im nächsten Beispiel verfügt das Modell über mehrere Dateien in einem Ordner mit dem Namen model. Weitere Informationen finden Sie unter Wie Sie den Ordner bestimmen können, den Ihr Modell verwendet.
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
# load the model
model = load_model(model_path)
In diesem Beispiel platzieren wir das Modell in einer globalen Variablen model. Verwenden Sie globale Variablen, um alle Ressourcen verfügbar zu machen, die zum Durchführen von Rückschlüssen auf Ihre Bewertungsfunktion erforderlich sind.
Die run -Methode
Verwenden Sie die run(mini_batch: List[str]) -> Union[List[Any], pandas.DataFrame]-Methode, um die Bewertung der einzelnen Minibatches zu behandeln, die von der Batchbereitstellung generiert werden. Diese Methode wird für jede mini_batch-Generierung für Ihre Eingabedaten einmal aufgerufen. Batchbereitstellungen lesen Daten in Batches entsprechend der Konfiguration der Bereitstellung.
import pandas as pd
from typing import List, Any, Union
def run(mini_batch: List[str]) -> Union[List[Any], pd.DataFrame]:
results = []
for file in mini_batch:
(...)
return pd.DataFrame(results)
Die Methode empfängt eine Liste mit Dateipfaden als Parameter (mini_batch). Sie können diese Liste verwenden, um jede Datei einzeln zu durchlaufen oder den gesamten Batch zu lesen und alle gleichzeitig zu verarbeiten. Die optimale Option hängt von Ihrem Computespeicher und dem zu erreichenden Durchsatz ab. Ein Beispiel, in dem beschrieben wird, wie ganze Datenbatches gleichzeitig gelesen werden, finden Sie unter Bereitstellungen mit hohem Durchsatz.
Hinweis
Wie wird die Arbeit verteilt?
Batchbereitstellungen verteilen die Arbeit auf Dateiebene. Demnach generiert ein Ordner mit 100 Dateien mit Minibatches von 10 Dateien 10 Batches mit jeweils 10 Dateien. Beachten Sie, dass die Größe der relevanten Dateien keine Relevanz hat. Bei Dateien, die zu groß sind, um in großen Minibatches verarbeitet zu werden, wird empfohlen, die Dateien entweder in kleinere Dateien aufzuteilen, um ein höheres Maß an Parallelität zu erzielen, oder die Anzahl Dateien pro Minibatch zu verringern. Derzeit kann die Batchbereitstellung keine Abweichung in der Größenverteilung der Datei berücksichtigen.
Von der Methode run() sollte ein Pandas-DataFrame oder ein Array/eine Liste zurückgegeben werden. Jedes zurückgegebene Ausgabeelement deutet auf eine erfolgreiche Ausführung eines Eingabeelements im Eingabe-mini_batch hin. Bei Datei- oder Ordnerdatenobjekten stellt jede zurückgegebene Zeile/jedes zurückgegebene Element eine einzelne verarbeitete Datei dar. Bei einem Tabellendatenobjekt stellt jede zurückgegebene Zeile/jedes zurückgegebene Element eine Zeile in einer verarbeiteten Datei dar.
Wichtig
Wie schreibe ich Vorhersagen?
Alles, was die run()-Funktion zurückgibt, wird in der Ausgabevorhersagedatei angefügt, die der Batchauftrag generiert. Es ist wichtig, den richtigen Datentyp aus dieser Funktion zurückzugeben. Geben Sie Arrays zurück, wenn Sie eine einzelne Vorhersage ausgeben müssen. Geben Sie pandas-DataFrames zurück, wenn Sie mehrere Informationsteile zurückgeben müssen. Für tabellarische Daten können Sie beispielsweise Ihre Vorhersagen an den ursprünglichen Datensatz anfügen. Verwenden Sie dazu einen Pandas DataFrame. Obwohl ein Pandas DataFrame möglicherweise Spaltennamen enthält, enthält die Ausgabedatei diese Namen nicht.
Um Vorhersagen auf eine andere Art und Weise zu schreiben, können Sie Ausgaben in Batchbereitstellungen anpassen.
Warnung
Geben Sie in der run-Funktion keine komplexen Datentypen (oder Listen komplexer Datentypen) anstelle von pandas.DataFrame aus. Diese Ausgaben werden in eine Zeichenfolge umgewandelt und sind schwer zu lesen.
Der resultierende DataFrame oder das resultierende Array wird an die angegebene Ausgabedatei angefügt. Es gibt keine Anforderungen an die Kardinalität der Ergebnisse. Eine Datei kann 1 oder viele Zeilen/Elemente in der Ausgabe generieren. Alle Elemente im resultierenden DataFrame oder Array werden unverändert in die Ausgabedatei geschrieben (vorausgesetzt, output_action ist nicht summary_only).
Python-Pakete für die Bewertung
Jede Bibliothek, die für die Ausführung Ihres Bewertungsskripts erforderlich ist, muss in der Umgebung angegeben werden, in der Ihre Batchbereitstellung ausgeführt wird. Bei Bewertungsskripts werden Umgebungen pro Bereitstellung angegeben. In der Regel geben Sie Ihre Anforderungen mithilfe einer conda.yml-Abhängigkeitsdatei an, die wie folgt aussehen kann:
mnist/environment/conda.yaml
name: mnist-env
channels:
- conda-forge
dependencies:
- python=3.8.5
- pip<22.0
- pip:
- torch==1.13.0
- torchvision==0.14.0
- pytorch-lightning
- pandas
- azureml-core
- azureml-dataset-runtime[fuse]
Weitere Informationen zum Angeben der Umgebung für Ihr Modell finden Sie unter Erstellen einer Batchbereitstellung.
Schreiben von Vorhersagen auf eine andere Weise
Standardmäßig schreibt die Batchbereitstellung die Vorhersagen des Modells in eine einzelne Datei, wie in der Bereitstellung angegeben. In einigen Fällen müssen Sie jedoch die Vorhersagen in mehrere Dateien schreiben. Für partitionierte Eingabedaten sollten Sie z. B. auch partitionierte Ausgaben generieren. In diesen Fällen können Sie Ausgaben in Batchbereitstellungen anpassen, um Folgendes anzugeben:
- Das zum Schreiben von Vorhersagen verwendete Dateiformat (CSV, Parquet, JSON usw.)
- Die Art und Weise, wie Daten in der Ausgabe partitioniert werden
Besuchen Sie Anpassen von Ausgaben in Batchbereitstellungen, um weitere Informationen dazu zu erhalten, wie Sie sie erreichen können.
Quellcodeverwaltung von Bewertungsskripts
Es wird dringend empfohlen, Bewertungsskripts in die Quellcodeverwaltung aufzunehmen.
Bewährte Methoden zum Schreiben von Bewertungsskripts
Beim Schreiben von Bewertungsskripts, die große Datenmengen verarbeiten, müssen Sie mehrere Faktoren berücksichtigen, einschließlich
- Die Größe jeder Datei
- Die Datenmenge für jede Datei
- Die Menge an Arbeitsspeicher, die zum Lesen der einzelnen Dateien erforderlich ist
- Die Menge an Arbeitsspeicher, die zum Lesen eines gesamten Dateibatches erforderlich ist
- Der Speicherbedarf des Modells
- Der Speicherbedarf des Modells beim Ausführen der Eingabedaten
- Der verfügbare Arbeitsspeicher in Ihrer Compute-Instanz
Batchbereitstellungen verteilen Arbeit auf Dateiebene. Dies bedeutet, dass ein Ordner, der 100 Dateien enthält, in Minibatches von 10 Dateien 10 Batches von jeweils 10 Dateien generiert (unabhängig von der Größe der beteiligten Dateien). Wenn Ihre Dateien zu groß sind, um in großen Minibatches verarbeitet zu werden, wird empfohlen, die Dateien entweder in kleinere Dateien aufzuteilen, um ein höheres Maß an Parallelität zu erzielen, oder die Anzahl Dateien pro Minibatch zu verringern. Derzeit kann die Batchbereitstellung keine Abweichung in der Größenverteilung der Datei berücksichtigen.
Beziehung zwischen dem Grad der Parallelität und dem Bewertungsskript
Ihre Bereitstellungskonfiguration steuert sowohl die Größe jedes Minibatches als auch die Anzahl der Worker auf jedem Knoten. Dies wird wichtig, wenn Sie entscheiden, ob der gesamte Minibatch gelesen werden soll, um die Rückschlussdatei nach Datei auszuführen, oder die Rückschlusszeile nach Zeile auszuführen (für tabellarisch). Besuchen Sie Ausführen von Rückschlüssen auf der Minibatch-, Datei- oder Zeilenebene, um weitere Informationen zu erhalten.
Wenn Sie mehrere Worker in derselben Instanz ausführen, sollten Sie berücksichtigen, dass der Speicher für alle Worker freigegeben ist. In der Regel sollte das Erhöhen der Anzahl von Workern pro Knoten mit einer Verringerung der Minibatchgröße oder einer Änderung der Bewertungsstrategie einhergehen (wenn die Datengröße und Compute-SKU gleich bleibt).
Ausführen des Rückschlusses auf Minibatch-, Datei- oder Zeilenebene
Batchendpunkte rufen die Funktion run() in Ihrem Bewertungsskript einmal pro Minibatch auf. Sie können jedoch entscheiden, ob Sie den Rückschluss über den gesamten Batch, jeweils über eine Datei oder jeweils über eine Zeile für tabellarische Daten ausführen möchten.
Minibatchebene
In der Regel sollten Sie einen Rückschluss über den Batch auf einmal ausführen, um einen hohen Durchsatz in Ihrem Batchbewertungsprozess zu erreichen. Dies geschieht, wenn Sie einen Rückschluss über eine GPU ausführen, bei der Sie die Sättigung des Rückschlussgeräts erreichen möchten. Sie können sich auch auf ein Datenladeprogramm verlassen, das die Batchverarbeitung selbst übernehmen kann, wenn Daten nicht in den Arbeitsspeicher passen, z. B. TensorFlow- oder PyTorch-Datenladeprogramme. In diesen Fällen möchten Sie möglicherweise einen Rückschluss für den gesamten Batch ausführen.
Warnung
Das Ausführen des Rückschlusses auf Batchebene erfordert möglicherweise eine genaue Kontrolle über die Größe der Eingabedaten, um die Arbeitsspeicheranforderungen ordnungsgemäß berücksichtigen und Ausnahmen durch nicht ausreichenden Arbeitsspeicher vermeiden zu können. Ob Sie den gesamten Minibatch im Arbeitsspeicher laden können, hängt von der Größe des Minibatches, der Größe der Instanzen im Cluster und der Anzahl der Worker auf jedem Knoten ab.
Besuchen Sie Bereitstellungen mit hohem Durchsatz, um zu erfahren, wie Sie dies erreichen können. In diesem Beispiel wird ein vollständiger Batch von Dateien gleichzeitig verarbeitet.
Dateiebene
Eine der einfachsten Methoden zum Durchführen von Rückschlüssen besteht darin, alle Dateien im Minibatch zu durchlaufen und Ihr Modell dann darüber auszuführen. In einigen Fällen, z. B. Bildverarbeitung, kann dies eine gute Idee sein. Für tabellarische Daten müssen Sie möglicherweise eine gute Schätzung über die Anzahl der Zeilen in jeder Datei vornehmen. Diese Schätzung kann zeigen, ob Ihr Modell die Speicheranforderungen verarbeiten kann, um die gesamten Daten in den Arbeitsspeicher zu laden und einen Rückschluss darüber durchzuführen. Einige Modelle (insbesondere solche Modelle, die auf wiederkehrenden neuralen Netzwerken basieren), entfalten sich und haben einen Speicherbedarf mit einer potenziell nichtlinearen Zeilenanzahl. Bei einem Modell mit hohen Speicherkosten sollten Sie den Rückschluss auf Zeilenebene in Betracht ziehen.
Tipp
Erwägen Sie das Aufteilen von Dateien, die zu groß zum Lesen sind, in mehrere kleinere Dateien, um eine bessere Parallelisierung zu schaffen.
Um zu erfahren, wie Sie dies tun, besuchen Sie Bildbearbeitung mit Batchbereitstellungen. In diesem Beispiel wird jeweils nur eine Datei verarbeitet.
Zeilenebene (tabellarisch)
Bei Modellen, bei denen ihre Eingabegrößen Herausforderungen darstellen, sollten Sie einen Rückschluss auf Zeilenebene ausführen. Ihre Batchbereitstellung bietet weiterhin Ihr Bewertungsskript mit einem Minibatch von Dateien. Sie lesen jedoch jeweils eine Datei, Zeile für Zeile. Dies mag ineffizient erscheinen, aber für einige Deep Learning-Modelle ist es möglicherweise der einzige Weg, einen Rückschluss durchzuführen, ohne Ihre Hardwareressourcen zu skalieren.
Besuchen Sie die Textverarbeitung mit Batchbereitstellungen, um zu erfahren, wie Sie dies tun. In diesem Beispiel wird jeweils nur eine Zeile verarbeitet.
Verwenden von Modellen, die Ordner sind
Die AZUREML_MODEL_DIR-Umgebungsvariable enthält den Pfad zum ausgewählten Modellspeicherort und die init()-Funktion verwendet ihn in der Regel, um das Modell in den Arbeitsspeicher zu laden. Einige Modelle enthalten ihre Dateien jedoch möglicherweise in einem Ordner und Sie müssen dies unter Umständen beim Laden berücksichtigen. Sie können die Ordnerstruktur Ihres Modells wie hier gezeigt bestimmen:
Navigieren Sie zum Azure Machine Learning-Portal.
Navigieren Sie zum Abschnitt Modelle.
Wählen Sie das Modell aus, das Sie bereitstellen möchten, und wählen Sie die Registerkarte Artefakte aus.
Notieren Sie sich den angezeigten Ordner. Dieser Ordner wurde beim Registrieren des Modells angegeben.
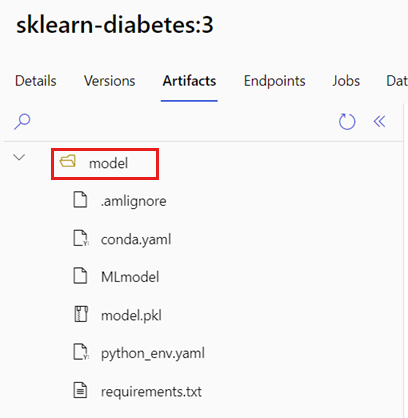

Verwenden Sie diesen Pfad, um das Modell zu laden:
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
model = load_model(model_path)
Nächste Schritte
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für