Optimieren der Leistung und Verwalten von Datenbanken in Azure Database for MySQL – Flexible Server mithilfe von sys_schema
GILT FÜR: Azure Database for MySQL – Single Server Azure Database for MySQL – Flexible Server
Azure Database for MySQL – Single Server Azure Database for MySQL – Flexible Server
Wichtig
Azure Database for MySQL Single Server wird eingestellt. Es wird dringend empfohlen, ein Upgrade auf Azure Database for MySQL Flexible Server auszuführen. Weitere Informationen zum Migrieren zu Azure Database for MySQL Flexible Server finden Sie unter Was geschieht mit Azure Database for MySQL Single Server?
Das Schema performance_schema von MySQL wurde zuerst in MySQL 5.5 eingeführt und ermöglicht die Instrumentierung für viele wichtige Serverressourcen, z.B. Speicherzuteilung, gespeicherte Programme, Metadatensperrung usw. Allerdings enthält performance_schema mehr als 80 Tabellen, und häufig erfordert das Abrufen der erforderlichen Informationen das Verknüpfen von Tabellen in performance_schema und von Tabellen aus information_schema. sys_schema basiert auf performance_schema und information_schema und bietet eine leistungsstarke Sammlung von benutzerfreundlichen Sichten in einer schreibgeschützten Datenbank bei vollständiger Verfügbarkeit in Azure Database for MySQL Flexible Server, Version 5.7.
Es gibt in sys_schema 52 Sichten, die jeweils folgende Präfixe aufweisen:
- Host_summary oder IO: Latenzen im Zusammenhang mit E/A.
- InnoDB: InnoDB-Pufferstatus und -sperren.
- Memory: Auslastung des Arbeitsspeichers durch Host und Benutzer.
- Schema: Schemabezogene Informationen wie automatische Inkremente, Indizes usw.
- Statement: Informationen zu SQL-Anweisungen, etwa Anweisungen, die vollständige Tabellenscans oder langen Abfragezeiten verursacht haben.
- User: Belegte Ressourcen, gruppiert nach Benutzern. Beispiele sind die Datei-E/As, Verbindungen und Arbeitsspeicher.
- Wait: Warteereignisse, gruppiert nach Host oder Benutzer.
Im Folgenden finden Sie einige allgemeine Verwendungsmuster für sys_schema. Zunächst gruppieren wir die Verwendungsmuster in zwei Kategorien: Leistungsoptimieren und Datenbankwartung.
Leistungsoptimierung
sys.user_summary_by_file_io
E/A ist der aufwendigste Vorgang in der Datenbank. Wir ermitteln die durchschnittliche E/A-Wartezeit durch Abfragen der Sicht sys.user_summary_by_file_io. Mit dem standardmäßig bereitgestellten Speicher von 125 GB beträgt die E/A-Wartezeit ca. 15 Sekunden.
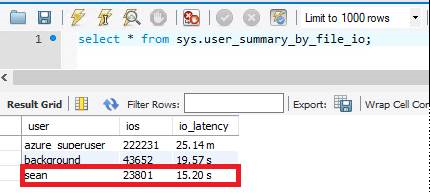
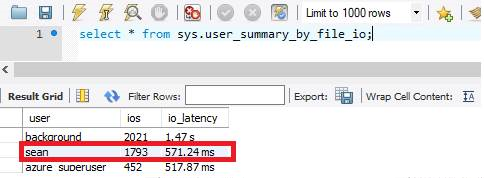
Da Azure Database for MySQL Flexible Server die E/A im Hinblick auf den Speicher skaliert, wird die E/A- nach der Erhöhung des bereitgestellten Speichers auf 1 TB auf 571 ms reduziert.
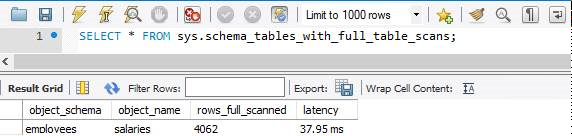
sys.schema_tables_with_full_table_scans
Trotz sorgfältiger Planung können viele Abfragen weiterhin zu vollständigen Tabellenscans führen. Weitere Informationen zu den Indextypen und deren Optimierung finden Sie im Artikel Beheben von Problemen bei der Abfrageleistung. Vollständige Tabellenscans sind ressourcenintensiv und beeinträchtigen die Datenbankleistung. Die schnellste Möglichkeit zum Suchen von Tabellen mit vollständigen Tabellenscans stellt eine Abfrage der Sicht sys.schema_tables_with_full_table_scans dar.
sys.user_summary_by_statement_type
Um Probleme mit der Datenbankleistung zu beheben, kann es nützlich sein, die Ereignisse, die innerhalb der Datenbank eintreten, zu ermitteln. Dazu verwenden Sie die Sicht sys.user_summary_by_statement_type.
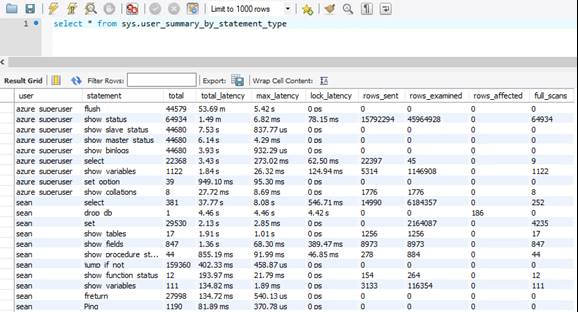
In diesem Beispiel benötigt Azure Database for MySQL Flexible Server 53 Minuten, um das langsame Abfrageprotokoll 44579-mal zu leeren. Dies ist eine lange Zeit und bedeutet viele E/As. Sie können diese Aktivität reduzieren, indem Sie Ihr Protokoll für langsame Abfragen deaktivieren oder die Häufigkeit der Anmeldung langsamer Abfragen am Azure-Portal verringern.
Datenbankwartung
sys.innodb_buffer_stats_by_table
[!WICHTIG]
Das Abfragen dieser Ansicht kann sich auf die Leistung auswirken. Es wird empfohlen, diese Problembehandlung in ruhigeren Geschäftszeiten durchzuführen.
Der InnoDB-Pufferpool befindet sich im Arbeitsspeicher. Er ist der wichtigste Mechanismus zur Zwischenspeicherung zwischen dem DBMS und dem Speicher. Die Größe des InnoDB-Pufferpools wird durch die Leistungsstufe begrenzt und kann nur geändert werden, indem eine andere Produkt-SKU ausgewählt wird. Wie beim Arbeitsspeicher im Betriebssystem werden alte Seiten ausgelagert, um Platz für neuere Daten bereitzustellen. Um herauszufinden, welche Tabellen den meisten Speicher im InnoDB-Pufferpool belegen, können Sie die Sicht sys.innodb_buffer_stats_by_table abfragen.
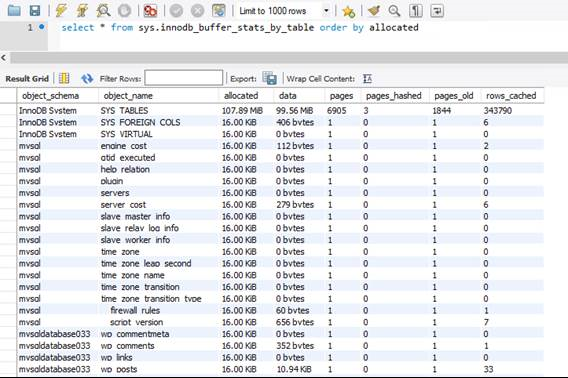
In der Abbildung oben wird ersichtlich, dass mit Ausnahme der Systemtabellen und -sichten alle Tabellen in der Datenbank „mysqldatabase033“, die eine WordPress-Website hostet, 16 KB oder 1 Seite der Daten im Arbeitsspeicher belegen.
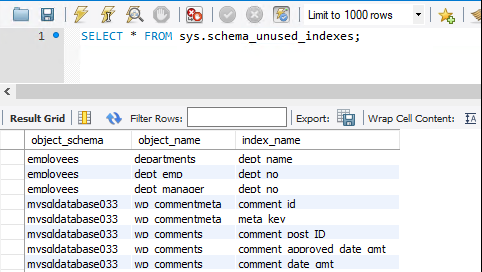
Sys.schema_unused_indexes & sys.schema_redundant_indexes
Indizes sind hervorragende Tools zur Verbesserung der Leistung bei Lesevorgängen, sie verursachen jedoch zusätzliche Kosten für Einfügevorgänge und Speicher. sys.schema_unused_indexes und sys.schema_redundant_indexes geben Einblick in nicht genutzte oder doppelte Indizes.

Zusammenfassung
Zusammenfassend lässt sich sagen, dass sys_schema ein großartiges Tool sowohl für die Leistungsoptimierung als auch für die Datenbankwartung ist. Nutzen Sie dieses Feature in Ihrer Instanz von Azure Database for MySQL Flexible Server.
Nächste Schritte
- Um Antworten anderer Benutzer auf häufige Fragen zu erhalten oder eine neue Frage/Antwort zu veröffentlichen, besuchen Sie Stack Overflow.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für