Semantische Rangfolge in Azure KI Search
In Azure KI-Suche ist der semantische Sortierer ein Feature, das die Suchrelevanz durch die Verwendung der Language Understanding-Modelle von Microsoft verbessert, um Suchergebnisse neu zu bewerten. Dieser Artikel enthält eine allgemeine Einführung in das Verhalten und die Vorteile des semantischen Sortierers.
Der semantische Sortierer ist ein Premium-Feature mit nutzungsbasierter Abrechnung. Es wird empfohlen, diesen Artikel zu lesen, um Hintergrundinformationen zu erhalten. Falls Sie aber direkt loslegen möchten, können Sie die hier angegebenen Schritte ausführen.
Hinweis
Der semantische Sortierer verwendet weder generative KI noch Vektoren. Wenn Sie Vektorunterstützung und Ähnlichkeitssuche benötigen, lesen Sie Vektorsuche in Azure KI-Suche, um ausführliche Informationen zu erhalten.
Was ist die semantische Rangfolge?
Beim semantischen Sortierer handelt es sich um eine Sammlung abfrageseitiger Funktionen, die die Qualität eines anfänglichen Suchergebnisses mit BM25- oder RRF-Bewertung für textbasierte Abfragen, Vektorabfragen und Hybridabfragen verbessern. Wenn Sie die semantische Rangfolge für Ihren Suchdienst aktivieren, erweitert sie die herkömmliche Abfrageausführungspipeline auf zwei Arten:
Zuerst wird eine sekundäre Rangfolge für ein anfängliches Resultset hinzugefügt, das mit BM25 oder RRF (Reciprocal Rank Fusion) bewertet wurde. Diese sekundäre Rangfolge verwendet mehrsprachige Deep Learning-Modelle, die von Microsoft Bing übernommen wurden, um die semantisch relevantesten Ergebnisse zu höherzustufen.
Zweitens werden Beschriftungen und Antworten extrahiert und zurückgegeben, die Sie auf einer Suchseite ausgeben können, um das Benutzererlebnis bei der Suche zu verbessern.
Hier sind die Funktionen des semantischen Neusortierers.
| Funktion | Beschreibung |
|---|---|
| L2-Rangfolge | Verwendet den Kontext oder die semantische Bedeutung einer Abfrage, um einen neuen Relevanzbewertung für vorab bewertete Ergebnisse zu berechnen. |
| Semantische Titel und Markierungen | Extrahiert Sätze und Ausdrücke wortgetreu aus Feldern, die den Inhalt am besten zusammenfassen, und hebt wichtige Passagen zum einfachen Überfliegen hervor. Beschriftungen, die ein Ergebnis zusammenfassen, sind nützlich, wenn einzelne Inhaltsfelder für die Suchergebnisseite zu dicht sind. Der markierte Text hebt die relevantesten Begriffe und Ausdrücke hervor, sodass Benutzer schnell ermitteln können, warum eine Entsprechung als relevant eingestuft wurde. |
| Semantische Antworten | Eine optionale und zusätzliche Unterstruktur, die von einer Semantikabfrage zurückgegeben wird. Sie bietet eine direkte Antwort auf eine Abfrage, die wie eine Frage aussieht. Ein Dokument muss Text mit den Merkmalen einer Antwort enthalten. |
Funktionsweise des semantischen Sortierers
Der semantische Sortierer übergibt eine Abfrage und Ergebnisse an Language Understanding-Modelle, die von Microsoft gehostet werden, und sucht nach besseren Übereinstimmungen.
In der folgenden Abbildung wird das Konzept erläutert. Nehmen wir den englischen Begriff „capital“. Er hat unterschiedliche Bedeutungen – je nachdem, ob er im Zusammenhang mit Finanzen, Recht, Geographie oder Grammatik verwendet wird. Durch Language Understanding kann der semantische Bewerter den Kontext erkennen und Ergebnisse höherstufen, die zur Abfrageabsicht passen.
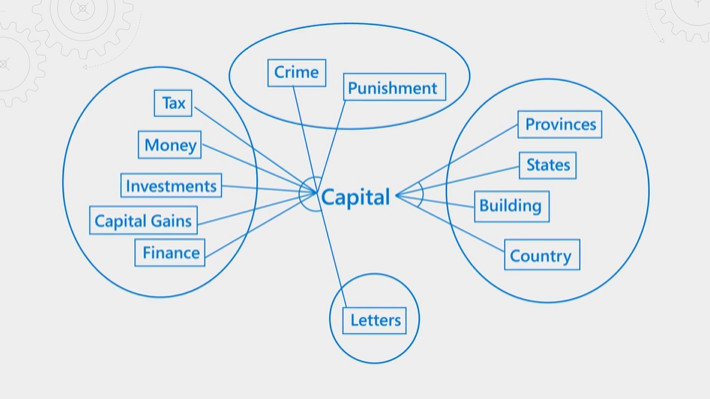
Das semantische Ranking ist sowohl ressourcen- als auch zeitintensiv. Um die Verarbeitung innerhalb der erwarteten Wartezeit eines Abfragevorgangs abzuschließen, werden Eingaben für den semantischen Bewerter konsolidiert und reduziert, damit der Schritt der Neubewertung schnellstmöglich abgeschlossen werden kann.
Die semantische Rangfolge umfasst drei Schritte:
- Sammeln und Zusammenfassen von Eingaben
- Bewerten von Ergebnissen mit dem semantischen Sortierer
- Ausgeben neu bewerteter Ergebnisse, Beschriftungen und Antworten
Sammlung und Zusammenfassung von Eingaben
Bei der semantischen Rangfolge übergibt das Abfragesubsystem Suchergebnisse als Eingabe an Zusammenfassungs- und Bewertungsmodelle. Da die Eingabegrößen von Bewertungsmodellen eingeschränkt und die Modelle rechenintensiv sind, müssen Suchergebnisse für eine effiziente Handhabung dimensioniert und strukturiert (zusammengefasst) werden.
Der semantische Sortierer beginnt mit einem Ergebnis mit BM25-Bewertung aus einer Textabfrage oder mit einem Ergebnis mit RRF-Bewertung aus einer Vektor- oder Hybridabfrage. In der Übung zur Neubewertung werden nur Textfelder verwendet, und nur die 50 besten Ergebnisse werden für die semantischen Rangfolge verwendet, auch wenn mehr als 50 Ergebnisse vorhanden sind. In der Regel sind Felder, die in der semantischen Rangfolge verwendet werden, informativ und beschreibend.
Für jedes Dokument im Suchergebnis akzeptiert das Zusammenfassungsmodell bis zu 2.000 Token, wobei ein Token etwa zehn Zeichen umfasst. Eingaben werden aus den Feldern „title“, „keyword“ und „content“ der semantischen Konfiguration zusammengefasst.
Zu lange Zeichenfolgen werden gekürzt, um sicherzustellen, dass die Gesamtlänge den Eingabeanforderungen des Zusammenfassungsschritts entspricht. Aus diesem Grund ist es wichtig, Ihrer semantischen Konfiguration Felder in Prioritätsreihenfolge hinzuzufügen. Wenn Sie sehr große Dokumente mit textlastigen Feldern haben, wird alles nach der Maximalgrenze ignoriert.
Semantikfeld Tokengrenzwert "title" 128 Token "keywords" 128 Token "content" Verbleibende Token Die Zusammenfassungsausgabe ist eine Zusammenfassungszeichenfolge für jedes Dokument, bestehend aus den relevantesten Informationen aus den einzelnen Feldern. Zusammenfassungszeichenfolgen werden zur Bewertung an den Bewerter sowie an Modelle für maschinelles Leseverständnis für Beschriftungen und Antworten gesendet.
Jede generierte Zusammenfassungszeichenfolge, die an den semantischen Bewerter übergeben wird, darf maximal 256 Token lang sein.
Vorgehensweise bei der Bewertung
Die Bewertung erfolgt über die Beschriftung und unter Berücksichtigung aller anderen Inhalte aus der Zusammenfassungszeichenfolge, die die Länge von 256 Token ausfüllen.
Beschriftungen werden hinsichtlich ihrer konzeptioneller und semantischer Relevanz bewertet, in Bezug zur bereitgestellten Abfrage.
@search.rerankerScore wird jedem Dokument auf der Grundlage der semantischen Relevanz des Dokuments für die spezifische Abfrage zugewiesen. Die Bewertungen liegen zwischen 4 und 0 (hoch bis niedrig), wobei eine höhere Bewertung eine größere Relevanz darstellt.
Ergebnis Bedeutung 4,0 Das Dokument ist hochrelevant und beantwortet die Frage vollständig, die Passage enthält jedoch möglicherweise zusätzlichen Text, der nichts mit der Frage zu tun hat. 3.0 Das Dokument ist relevant, aber es fehlen Details, die es vollständig machen würden. 2.0 Das Dokument ist ein bisschen relevant. Es beantwortet die Frage entweder teilweise oder nur einige Aspekte der Frage. 1.0 Das Dokument hängt mit der Frage zusammen und beantwortet einen kleinen Teil davon. 0,0 Das Dokument ist irrelevant. Übereinstimmungen werden absteigend nach Bewertung aufgeführt und in die Nutzdaten der Abfrageantwort aufgenommen. Die Nutzlast umfasst Antworten, nur-Text und markierte Beschriftungen sowie alle Felder, die Sie als abrufbar markiert oder in einer Select-Klausel angegeben haben.
Hinweis
Bei jeder Abfrage können die Verteilungen von @search.rerankerScore aufgrund von Bedingungen auf Infrastrukturebene geringfügige Abweichungen aufweisen. Es ist bekannt, dass Bewertungsmodellaktualisierungen die Verteilung beeinflussen. Aus diesen Gründen sollten Sie die Grenzwerte nicht granular machen, wenn Sie benutzerdefinierten Code für Mindestschwellenwerte schreiben oder für Vektor- und Hybridabfragen die Schwellenwerteigenschaft festlegen.
Ausgaben des semantischen Sortierers
Anhand der einzelnen Zusammenfassungszeichenfolgen suchen die Modelle für maschinelles Leseverständnis nach den repräsentativsten Passagen.
Die Ausgaben umfassen Folgendes:
Eine semantische Beschriftung für das Dokument. Jede Beschriftung ist in einer reinen Textversion und einer Highlight-Version verfügbar und umfasst häufig weniger als 200 Wörter pro Dokument.
Eine optionale semantischen Antwort, sofern Sie den Parameter
answersangegeben haben, die Abfrage als Frage gestellt wurde und in der langen Zeichenfolge eine Passage gefunden wurde, die eine wahrscheinliche Antwort auf die Frage darstellt.
Bei Beschriftungen und Antworten handelt es sich immer um wortgetreuen Text aus Ihrem Index. In diesem Workflow gibt es kein generatives KI-Modell, das neue Inhalte erstellt oder erstellt.
Semantische Funktionen und Einschränkungen
Der semantische Sortierer ist eine neuere Technologie. Daher ist es wichtig zu wissen, was von ihr erwartet werden kann und was nicht. Folgendes ist mit der Technologie möglich:
Höherstufen von Übereinstimmungen, die semantisch näher an der Absicht der ursprünglichen Abfrage liegen.
Finden von Zeichenfolgen, die als Beschriftungen und Antworten verwendet werden können. Beschriftungen und Antworten werden in der Antwort zurückgegeben und können auf einer Suchergebnisseite gerendert werden.
Der semantische Sortierer kann eine Abfrage nicht erneut für den gesamten Korpus ausführen, um semantisch relevante Ergebnisse zu finden. Die semantische Rangfolge bewertet das vorhandene Resultset neu, das aus den 50 besten Ergebnissen besteht, die vom Standardalgorithmus für die Rangfolge ermittelt wurden. Darüber hinaus kann der semantische Sortierer keine neuen Informationen oder Zeichenfolgen erstellen. Beschriftungen und Antworten werden wortgetreu aus Ihren Inhalten extrahiert. Wenn die Ergebnisse also keinen antwortähnlichen Text enthalten, erzeugen die Sprachmodelle keine Antwort.
Die semantische Rangfolge ist zwar nicht in jedem Szenario von Vorteil, bestimmte Inhalte können jedoch erheblich von ihren Funktionen profitieren. Die Sprachmodelle im semantischen Sortierer eignen sich am besten für durchsuchbare Inhalte, die viele Informationen enthalten und in offener Textform strukturiert sind. Für Wissensdatenbanken, Onlinedokumentationen oder Dokumente, die beschreibende Inhalte enthalten, bieten die Funktionen des semantischen Sortierers die meisten Vorteile.
Die zugrunde liegende Technologie stammt von Bing und Microsoft Research und ist als Add-On-Feature in die Infrastruktur von Azure KI Search integriert. Weitere Informationen zu den Forschungs- und KI-Investitionen, die dem semantischen Sortierer zugrunde liegen, finden Sie im Microsoft Research Blog How AI from Bing is powering Azure AI Search (Wie Azure KI-Suche durch KI von Bing unterstützt wird).
Im folgenden Video erhalten Sie eine Übersicht zu den Funktionen.
Verfügbarkeit und Preismodell
Der semantische Sortierer steht für Suchdienste ab der Ebene „Basic“ zur Verfügung (sofern regional verfügbar).
Wenn Sie den semantischen Sortierer aktivieren, wählen Sie einen Preisplan für das Feature aus:
- Bei niedrigeren Abfragevolumen (unter 1.000 pro Monat) ist die semantische Rangfolge kostenlos.
- Wählen Sie bei höheren Abfragevolumen den Standardpreisplan aus.
Auf der Preisseite zu Azure KI Search finden Sie die Abrechnungsrate für verschiedene Währungen und Intervalle.
Gebühren für den semantischen Sortierer werden erhoben, wenn Abfrageanforderungen queryType=semantic enthalten und die Suchzeichenfolge nicht leer ist (z. B. search=pet friendly hotels in New York). Wenn Ihre Suchzeichenfolge leer ist (search=*), werden Ihnen auch dann keine Gebühren berechnet, wenn „queryType“ auf „semantic“ festgelegt ist.
Erste Schritte mit dem semantischen Sortierer
Melden Sie sich beim Azure-Portal an, um zu überprüfen, ob Ihr Suchdienst mindestens die Dienstebene „Basic“ hat.
Aktivieren Sie den semantischen Sortierer, und wählen Sie einen Preisplan aus.
Konfigurieren Sie den semantischen Sortierer in einem Suchindex.
Richten Sie Abfragen zum Zurückgeben semantischer Beschriftungen und Hervorhebungen ein.