Tutorial: Erstellen eines benutzerdefinierten Analysetools für Telefonnummern
Bei Suchlösungen kann die Arbeit mit Zeichenfolgen, die komplexe Muster oder Sonderzeichen enthalten, eine Herausforderung darstellen, da das Standardanalysetool sinnvolle Teile eines Musters entfernt oder falsch interpretiert. Telefonnummern sind ein klassisches Beispiel für Zeichenfolgen, die schwer zu analysieren sind. Sie kommen in verschiedenen Formaten vor, und sie enthalten Sonderzeichen, die das Standardanalysetool ignoriert.
Dieses Tutorial befasst sich mit dem Thema Telefonnummern und zeigt Ihnen, wie Sie das Problem der strukturierten Daten mit Hilfe eines benutzerdefinierten Analysetools lösen können. Der hier beschriebene Ansatz kann unverändert für Telefonnummern verwendet oder für Felder mit denselben Merkmalen (strukturiert, mit Sonderzeichen) angepasst werden, z. B. URLs, E-Mails, Postleitzahlen und Daten.
In diesem Tutorial verwenden Sie einen REST-Client und die REST-APIs der Azure KI-Suche für folgende Aufgaben:
- Das Problem verstehen
- Entwickeln eines ersten benutzerdefinierten Analysetools für die Behandlung von Telefonnummern
- Testen des benutzerdefinierten Analysetools
- Optimieren des Designs des benutzerdefinierten Analysetools zur weiteren Verbesserung der Ergebnisse
Voraussetzungen
Für dieses Tutorial sind folgende Dienste und Tools erforderlich:
Visual Studio Code mit einem REST-Client.
Azure KI Search. Erstellen oder suchen Sie eine vorhandene Azure AI Search-Ressource unter Ihrem aktuellen Abonnement. Für diesen Schnellstart können Sie einen kostenlosen Dienst verwenden.
Herunterladen von Dateien
Der Quellcode für dieses Tutorial ist die Datei custom-analyzer.rest im GitHub-Repository Azure-Samples/azure-search-rest-samples.
Kopieren eines Schlüssels und einer URL
Die REST-Aufrufe in diesem Tutorial erfordern einen Suchdienstendpunkt und einen Administrator-API-Schlüssel. Diese Werte erhalten Sie im Azure-Portal.
Melden Sie sich beim Azure-Portalan, navigieren Sie zur Seite Übersicht, und kopieren Sie die URL. Ein Beispiel für einen Endpunkt ist
https://mydemo.search.windows.net.Kopieren Sie unter Einstellungensschlüssel> einen Administratorschlüssel. Administratorschlüssel werden verwendet, um Objekte hinzuzufügen, zu ändern und zu löschen. Es gibt zwei austauschbare Administratorschlüssel. Kopieren Sie eine der Beiden.
Ein gültiger API-Schlüssel stellt für jede Anforderung eine Vertrauensstellung her zwischen der Anwendung, die die Anforderung sendet, und dem Suchdienst, der sie verarbeitet.
Erstellen eines Anfangsindexes
Öffnen Sie eine neue Textdatei in Visual Studio Code.
Legen Sie Variablen auf den Suchendpunkt und den API-Schlüssel fest, den Sie im vorherigen Schritt ermittelt haben.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-URL-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERESpeichern Sie die Datei nicht mit einer
.rest-Dateierweiterung.Fügen Sie das folgende Beispiel ein, um einen kleinen Index mit dem Namen
phone-numbers-indexmit zwei Feldern zu erstellen:idundphone_number. Wir haben noch kein Analysetool definiert, sodass das Analysetoolstandard.lucenestandardmäßig verwendet wird.### Create a new index POST {{baseUrl}}/indexes?api-version=2023-11-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false } ] }Klicken Sie auf Anforderung senden. Es sollte die Antwort
HTTP/1.1 201 Createdangezeigt werden, deren Antworttext die JSON-Darstellung des Indexschemas enthält.Laden Sie Daten in den Index, indem Sie Dokumente verwenden, die verschiedene Telefonnummernformate enthalten. Dies sind Ihre Testdaten.
### Load documents POST {{baseUrl}}/indexes/phone-numbers-index/docs/index?api-version=2023-11-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "value": [ { "@search.action": "upload", "id": "1", "phone_number": "425-555-0100" }, { "@search.action": "upload", "id": "2", "phone_number": "(321) 555-0199" }, { "@search.action": "upload", "id": "3", "phone_number": "+1 425-555-0100" }, { "@search.action": "upload", "id": "4", "phone_number": "+1 (321) 555-0199" }, { "@search.action": "upload", "id": "5", "phone_number": "4255550100" }, { "@search.action": "upload", "id": "6", "phone_number": "13215550199" }, { "@search.action": "upload", "id": "7", "phone_number": "425 555 0100" }, { "@search.action": "upload", "id": "8", "phone_number": "321.555.0199" } ] }Lassen Sie uns ein paar Abfragen ausprobieren, die dem entsprechen, was ein Benutzer oder eine Benutzerin eingeben könnte. Ein Benutzer oder eine Benutzerin könnte in einem der oben gezeigten Formate nach
(425) 555-0100suchen und dennoch erwarten, dass Ergebnisse zurückgegeben werden. Wir beginnen mit der Suche nach(425) 555-0100:### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2023-11-01&search=(425) 555-0100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}Diese Abfrage gibt drei von vier erwarteten Ergebnissen zurück, jedoch auch zwei unerwartete Ergebnisse:
{ "value": [ { "@search.score": 0.05634898, "phone_number": "+1 425-555-0100" }, { "@search.score": 0.05634898, "phone_number": "425 555 0100" }, { "@search.score": 0.05634898, "phone_number": "425-555-0100" }, { "@search.score": 0.020766128, "phone_number": "(321) 555-0199" }, { "@search.score": 0.020766128, "phone_number": "+1 (321) 555-0199" } ] }Versuchen wir es erneut ohne Formatierung:
4255550100.### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2023-11-01&search=4255550100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}Diese Abfrage schneidet noch schlechter ab, da sie nur eine von vier richtigen Übereinstimmungen zurückgibt.
{ "value": [ { "@search.score": 0.6015292, "phone_number": "4255550100" } ] }
Wenn diese Ergebnisse verwirrend finden, sind Sie nicht allein. Im nächsten Abschnitt untersuchen wir, warum wir diese Ergebnisse erhalten.
So funktionieren Analysetools
Um diese Suchergebnisse zu verstehen, müssen wir verstehen, was das Analysetool tut. Anschließend können wir das Standardanalysetool mit der Analyse-API testen und dann aus den Erkenntnissen ein Analysetool erstellen, das unseren Anforderungen besser entspricht.
Ein Analysetool ist eine Komponente der Volltext-Suchmaschine, mit der Text in Abfragezeichenfolgen und indizierten Dokumenten verarbeitet wird. Verschiedene Analysetools bearbeiten Text je nach Szenario auf verschiedene Arten. In diesem Szenario müssen wir ein Analysetool erstellen, das auf Telefonnummern zugeschnitten ist.
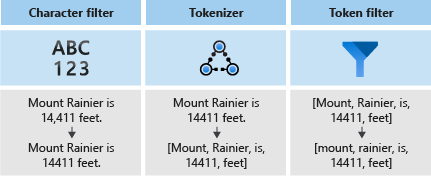
Analysetools bestehen aus drei Komponenten:
- Aus Zeichenfiltern, die einzelne Zeichen aus dem Eingabetext entfernen oder ersetzen.
- Aus einem Tokenizer, der den Eingabetext in Token zerlegt, die zu Schlüsseln im Suchindex werden.
- Aus Tokenfiltern, die die vom Tokenizer generierten Token manipulieren.
In der folgenden Abbildung sehen Sie, wie diese drei Komponenten zusammenwirken, um einen Satz in Token zu zerlegen:
Diese Token werden dann in einem invertierten Index gespeichert, der eine schnelle Volltextsuche ermöglicht. Ein invertierter Index ermöglicht Volltextsuche, indem er alle eindeutigen Begriffe, die bei der lexikalischen Analyse extrahiert wurden, den Dokumenten zuordnet, in denen sie vorkommen. Ein Beispiel sehen Sie in der folgenden Abbildung:

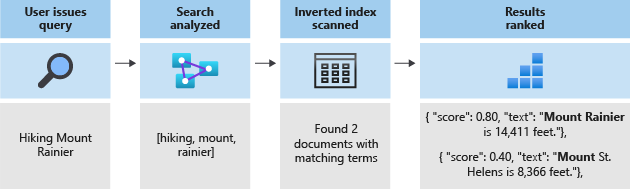
Die gesamte Suche läuft auf die Suche nach den im invertierten Index gespeicherten Begriffen hinaus. Wenn ein Benutzer eine Abfrage ausgibt:
- Wird die Abfrage analysiert, und die Abfragebegriffe werden analysiert.
- Der invertierte Index wird dann nach Dokumenten mit übereinstimmenden Begriffen gescannt.
- Schließlich wird die Rangfolge der abgerufenen Dokumente durch den Bewertungsalgorithmus ermittelt.
Wenn die Abfragebegriffe nicht mit den Begriffen in Ihrem invertierten Index übereinstimmen, werden keine Ergebnisse zurückgegeben. Weitere Informationen zur Funktionsweise von Abfragen finden Sie im Artikel zur Volltextsuche.
Hinweis
Bei partiellen Begriffsabfragen handelt es sich um eine wichtige Ausnahme von dieser Regel. Diese Abfragen (Präfixabfrage, Platzhalterabfrage, Regex-Abfrage) umgehen den lexikalischen Analyseprozess im Gegensatz zu regulären Begriffsabfragen. Partielle Begriffe werden nur in Kleinbuchstaben umgewandelt, bevor Sie mit Begriffen im Index verglichen werden. Wenn ein Analysetool nicht für die Unterstützung dieser Abfrage Typen konfiguriert ist, erhalten Sie häufig unerwartete Ergebnisse, weil keine übereinstimmenden Begriffe im Index vorhanden sind.
Testen des Analysetools mit der Analyse-API
Die Azure KI-Suche stellt eine Analyse-API zur Verfügung, die es Ihnen ermöglicht, Analysetools zu testen, um zu verstehen, wie sie Text verarbeiten.
Die Analyse-API wird mithilfe der folgenden Anforderung aufgerufen:
POST {{baseUrl}}/indexes/phone-numbers-index/analyze?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "(425) 555-0100",
"analyzer": "standard.lucene"
}
Die API gibt die Token zurück, die aus dem Text extrahiert wurden, wobei das von Ihnen angegebene Analysetool verwendet wird. Das Lucene-Standardanalysetool unterteilt die Telefonnummer in drei separate Token:
{
"tokens": [
{
"token": "425",
"startOffset": 1,
"endOffset": 4,
"position": 0
},
{
"token": "555",
"startOffset": 6,
"endOffset": 9,
"position": 1
},
{
"token": "0100",
"startOffset": 10,
"endOffset": 14,
"position": 2
}
]
}
Umgekehrt wird die ohne jegliche Interpunktion formatierte Telefonnummer 4255550100 in ein einziges Token umgewandelt.
{
"text": "4255550100",
"analyzer": "standard.lucene"
}
Antwort:
{
"tokens": [
{
"token": "4255550100",
"startOffset": 0,
"endOffset": 10,
"position": 0
}
]
}
Denken Sie daran, dass sowohl die Suchbegriffe als auch die indizierten Dokumente analysiert werden. Wenn wir an die Suchergebnisse aus dem vorherigen Schritt zurückdenken, können wir anfangen zu verstehen, warum diese Ergebnisse zurückgegeben wurden.
Bei der ersten Abfrage wurden unerwartete Telefonnummern zurückgegeben, weil einer ihrer Token (555) mit einem der von uns gesuchten Begriffe übereinstimmte. In der zweiten Abfrage wurde nur die eine Nummer zurückgegeben, da dies der einzige Datensatz war, bei dem ein Token mit 4255550100 übereinstimmte.
Erstellen eines benutzerdefinierten Analysetools
Da wir nun die Ergebnisse verstehen, die ausgegeben werden, erstellen wir ein benutzerdefiniertes Analysetool, um die Tokenisierungslogik zu verbessern.
Ziel ist es, eine intuitive Suche nach Telefonnummern zu ermöglichen, unabhängig davon, in welchem Format die Abfrage oder die indizierte Zeichenfolge vorliegt. Um dieses Ergebnis zu erzielen, geben wir einen Zeichenfilter, einen Tokenizer und einen Tokenfilter an.
Zeichenfilter
Zeichenfilter werden verwendet, um Text zu verarbeiten, bevor er an den Tokenizer übergeben wird. Zu den häufigen Verwendungsmöglichkeiten von Zeichenfiltern gehören das Filtern von HTML-Elementen oder das Ersetzen von Sonderzeichen.
Bei Telefonnummern möchten wir Leerzeichen und Sonderzeichen entfernen, da nicht alle Telefonnummerformate dieselben Sonderzeichen und Leerzeichen enthalten.
"charFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.MappingCharFilter",
"name": "phone_char_mapping",
"mappings": [
"-=>",
"(=>",
")=>",
"+=>",
".=>",
"\\u0020=>"
]
}
]
Der Filter entfernt die Zeichen -()+. und Leerzeichen aus der Eingabe.
| Eingabe | Output |
|---|---|
(321) 555-0199 |
3215550199 |
321.555.0199 |
3215550199 |
Tokenizer
Tokenizer teilen Text in Token auf und verwerfen einige Zeichen, z. B. Interpunktion. In vielen Fällen besteht das Ziel der Tokenisierung darin, einen Satz in einzelne Wörter aufzuteilen.
In diesem Szenario verwenden wir einen Schlüsselworttokenizer (keyword_v2), weil wir die Telefonnummer als einen einzelnen Begriff erfassen möchten. Beachten Sie, dass dies nicht die einzige Möglichkeit ist, dieses Problem zu lösen. Weitere Informationen finden Sie unten im Abschnitt Alternative Ansätze.
Schlüsselworttokenizer geben immer denselben Text aus, den sie als einen einzigen Begriff erhalten haben.
| Eingabe | Output |
|---|---|
The dog swims. |
[The dog swims.] |
3215550199 |
[3215550199] |
Tokenfilter
Tokenfilter werden verwendet, um die von einem Tokenizer generierten Token herauszufiltern oder zu ändern. Eine häufige Verwendung eines Tokenfilters besteht darin, alle Zeichen mithilfe eines Kleinbuchstabentokenfilters in Kleinbuchstaben umzuwandeln. Eine weitere häufige Verwendung ist das Herausfiltern von Stoppwörtern wie the, and oder is.
Während wir für dieses Szenario keinen dieser beiden Filter verwenden müssen, werden wir einen nGram-Token-Filter verwenden, um eine partielle Suche nach Telefonnummern zu ermöglichen.
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2",
"name": "custom_ngram_filter",
"minGram": 3,
"maxGram": 20
}
]
NGramTokenFilterV2
Der nGram_v2-Tokenfilter teilt Token basierend auf den Parametern minGram und maxGram in n-Gramme einer bestimmten Größe auf.
Für das Telefonnummern-Analysetool legen wir minGram auf 3 fest, da dies die kürzeste Teilzeichenfolge ist, nach der Benutzern wahrscheinlich suchen. maxGram wird auf 20 festgelegt, um sicherzustellen, dass alle Telefonnummern (selbst mit Durchwahlen) in ein einzelnes n-Gramm passen.
Der unglückliche Nebeneffekt von n-Grammen besteht darin, dass einige falsch positive Ergebnisse zurückgegeben werden. Dieses Problem wird in einem späteren Schritt behoben, indem ein separates Analysetool für Suchvorgänge erstellt wird, das nicht den n-Gramm-Tokenfilter enthält.
| Eingabe | Output |
|---|---|
[12345] |
[123, 1234, 12345, 234, 2345, 345] |
[3215550199] |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Analysetool
Nachdem wir die Zeichenfilter, den Tokenizer und die Tokenfilter eingerichtet haben, können wir unser Analysetool definieren.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer",
"tokenizer": "keyword_v2",
"tokenFilters": [
"custom_ngram_filter"
],
"charFilters": [
"phone_char_mapping"
]
}
]
Aus der Analyse-API werden Ausgaben des benutzerdefinierten Analysetools anhand der folgenden Eingaben in der folgenden Tabelle angezeigt.
| Eingabe | Ausgabe |
|---|---|
12345 |
[123, 1234, 12345, 234, 2345, 345] |
(321) 555-0199 |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Alle Token in der Ausgabespalte sind im Index vorhanden. Wenn unsere Abfrage einen dieser Begriffe enthält, wird die Telefonnummer zurückgegeben.
Neuerstellen mithilfe des neuen Analysetools
Löschen Sie den aktuellen Index:
### Delete the index DELETE {{baseUrl}}/indexes/phone-numbers-index?api-version=2023-11-01 HTTP/1.1 api-key: {{apiKey}}Erstellen Sie den Index mithilfe des neuen Analysetools neu. Dieses Indexschema fügt eine Definition für das benutzerdefinierte Analysetool und eine Zuweisung des benutzerdefinierten Analysetools im Feld „Telefonnummer“ hinzu.
### Create a new index POST {{baseUrl}}/indexes?api-version=2023-11-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index-2", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false, "analyzer": "phone_analyzer" } ], "analyzers": [ { "@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer", "name": "phone_analyzer", "tokenizer": "keyword_v2", "tokenFilters": [ "custom_ngram_filter" ], "charFilters": [ "phone_char_mapping" ] } ], "charFilters": [ { "@odata.type": "#Microsoft.Azure.Search.MappingCharFilter", "name": "phone_char_mapping", "mappings": [ "-=>", "(=>", ")=>", "+=>", ".=>", "\\u0020=>" ] } ], "tokenFilters": [ { "@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2", "name": "custom_ngram_filter", "minGram": 3, "maxGram": 20 } ] }
Testen des benutzerdefinierten Analysetools
Nachdem Sie den Index neu erstellt haben, können Sie das Analysetool nun mithilfe der folgenden Anforderung testen:
POST {{baseUrl}}/indexes/tutorial-first-analyzer/analyze?api-version=2023-11-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "+1 (321) 555-0199",
"analyzer": "phone_analyzer"
}
Sie sollten jetzt die Sammlung der sich aus der Telefonnummer ergebenden Token sehen können:
{
"tokens": [
{
"token": "132",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "1321",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "13215",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
...
...
...
]
}
Überarbeiten des benutzerdefinierten Analysetools zur Behandlung falsch positiver Ergebnisse
Nachdem Sie einige Beispielabfragen für den Index mit dem benutzerdefinierten Analysetool durchgeführt haben, werden Sie feststellen, dass sich die Trefferquote verbessert hat und nun alle übereinstimmenden Telefonnummern zurückgegeben werden. Der n-Gramm-Tokenfilter bewirkt jedoch, dass auch einige falsch positive Ergebnisse zurückgegeben werden. Dies ist ein gängiger Nebeneffekt eines n-Gramm-Tokenfilters.
Um falsch positive Ergebnisse zu vermeiden, erstellen wir ein separates Analysetool für Abfragen. Dieses Analysetool ist identisch mit dem vorherigen, mit der Ausnahme von custom_ngram_filter.
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_search",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [],
"charFilters": [
"phone_char_mapping"
]
}
In der Indexdefinition geben wir dann ein indexAnalyzer- und ein searchAnalyzer-Element an.
{
"name": "phone_number",
"type": "Edm.String",
"sortable": false,
"searchable": true,
"filterable": false,
"facetable": false,
"indexAnalyzer": "phone_analyzer",
"searchAnalyzer": "phone_analyzer_search"
}
Mit dieser Änderung haben Sie alles erledigt. Führen Sie als Nächstes folgende Schritte aus:
Löschen des Indexes.
Erstellen Sie den Index neu, nachdem Sie das neue benutzerdefinierte Analysetool (
phone_analyzer-search) hinzugefügt haben, und dieses Analysetool im Feldphone-numberder EigenschaftsearchAnalyzerhinzugefügt haben.Laden Sie die Daten neu.
Testen Sie die Abfragen erneut, um zu überprüfen, ob die Suche wie erwartet funktioniert. Wenn Sie die Beispieldatei verwenden, erstellt dieser Schritt den dritten Index mit dem Namen
phone-number-index-3.
Alternative Ansätze
Das im vorherigen Abschnitt beschriebene Analysetool dient dazu, die Flexibilität für die Suche zu maximieren. Dies geschieht jedoch auf Kosten der Speicherung vieler potenziell unwichtiger Begriffe im Index.
Das folgende Beispiel zeigt ein alternatives Analysetool, das bei der Tokenisierung effizienter ist, jedoch auch Nachteile aufweist.
Aufgrund einer Eingabe von 14255550100 kann das Analysetool die Telefonnummer nicht logisch abblocken. Beispielsweise kann die Landesvorwahl (1) nicht von der Ortsvorwahl (425) getrennt werden. Diese Diskrepanz würde dazu führen, dass die Telefonnummer nicht zurückgegeben wird, wenn bei der Suche keine Landesvorwahl angegeben wird.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_shingles",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [
"custom_shingle_filter"
]
}
],
"tokenizers": [
{
"@odata.type": "#Microsoft.Azure.Search.StandardTokenizerV2",
"name": "custom_tokenizer_phone",
"maxTokenLength": 4
}
],
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.ShingleTokenFilter",
"name": "custom_shingle_filter",
"minShingleSize": 2,
"maxShingleSize": 6,
"tokenSeparator": ""
}
]
Im folgenden Beispiel sehen Sie, dass die Telefonnummer in die Blöcke aufgeteilt wird, nach denen ein Benutzer oder eine Benutzerin normalerweise suchen würde.
| Eingabe | Ausgabe |
|---|---|
(321) 555-0199 |
[321, 555, 0199, 321555, 5550199, 3215550199] |
Je nach Ihren Anforderungen ist dies möglicherweise ein effizienterer Ansatz für das Problem.
Wesentliche Punkte
In diesem Tutorial wurde der Prozess zum Erstellen und Testen eines benutzerdefinierten Analysetools veranschaulicht. Sie haben einen Index erstellt, Daten indiziert und dann anhand des Index abgefragt, um zu sehen, welche Suchergebnisse zurückgegeben wurden. Dann haben Sie die Analyse-API verwendet, um den lexikalischen Analyseprozess in Aktion zu sehen.
Während das in diesem Tutorial definierte Analysetool eine einfache Lösung für die Suche nach Telefonnummern bietet, kann derselbe Prozess verwendet werden, um ein benutzerdefiniertes Analysetool für jedes denkbare Szenario mit ähnlichen Merkmalen zu erstellen.
Bereinigen von Ressourcen
Wenn Sie in Ihrem eigenen Abonnement arbeiten, ist es ratsam, nach Abschluss eines Projekts die nicht mehr benötigten Ressourcen zu entfernen. Ressourcen, die weiterhin ausgeführt werden, können Sie Geld kosten. Sie können entweder einzelne Ressourcen oder aber die Ressourcengruppe löschen, um den gesamten Ressourcensatz zu entfernen.
Ressourcen können im Portal über den Link Alle Ressourcen oder Ressourcengruppen im linken Navigationsbereich gesucht und verwaltet werden.
Nächste Schritte
Nachdem Sie nun mit dem Erstellen eines benutzerdefinierten Analysetools vertraut sind, sehen wir uns die verschiedenen Filter, Tokenizer und Analysetools an, die Ihnen zur Verfügung stehen, um eine umfangreiche Suchfunktion zu erstellen.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für