Analysieren des Azure Site Recovery-Bereitstellungsplaner-Berichts
In diesem Artikel werden die Arbeitsblätter beschrieben, die im Excel-Bericht enthalten sind, der mit dem Azure Site Recovery-Bereitstellungsplaner für das Szenario „Hyper-V zu Azure“ erstellt wird.
On-premises Summary (Lokale Zusammenfassung)
Das Arbeitsblatt „On-premises Summary“ (Lokale Zusammenfassung) enthält eine Übersicht über die Hyper-V-Umgebung für die Profilerstellung.
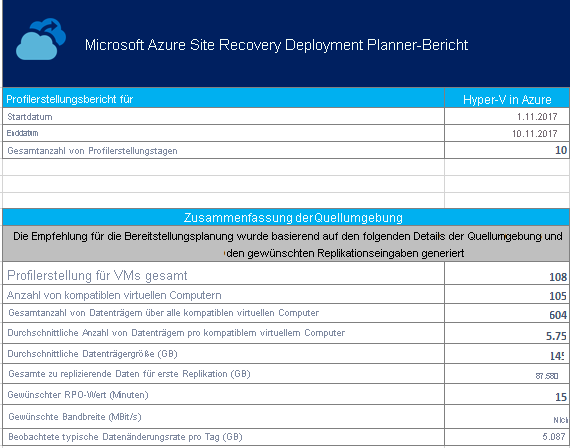
Start date (Startdatum) und End date (Enddatum): Das Start- und Enddatum der Profilerstellungsdaten, die bei der Berichterstellung berücksichtigt werden. Das Startdatum ist standardmäßig das Datum, an dem die Profilerstellung beginnt, und das Enddatum ist das Datum, an dem die Profilerstellung beendet wird. Bei diesen Informationen kann es sich um die Werte von „StartDate“ und „EndDate“ handeln, wenn der Bericht mit diesen Parametern erstellt wird.
Total number of profiling days (Gesamtanzahl von Profilerstellungstagen): Die gesamte Anzahl von Tagen der Profilerstellung zwischen dem Start- und dem Enddatum, für die der Bericht erstellt wird.
Number of compatible virtual machines (Anzahl von kompatiblen virtuellen Computern): Die Gesamtzahl von kompatiblen VMs, für die die erforderliche Netzwerkbandbreite, die erforderliche Anzahl von Speicherkonten und die Azure-Kerne berechnet werden.
Total number of disks across all compatible virtual machines (Gesamtzahl von Datenträgern für alle kompatiblen virtuellen Computer): Die Gesamtzahl von Datenträgern auf allen kompatiblen VMs.
Average number of disks per compatible virtual machine (Durchschnittliche Anzahl von Datenträgern pro kompatiblem virtuellem Computer): Durchschnittliche Anzahl von Datenträgern, die über alle kompatiblen VMs hinweg berechnet wird.
Average disk size (GB) (Durchschnittliche Datenträgergröße (GB)): Durchschnittliche Datenträgergröße, die über alle kompatiblen VMs hinweg berechnet wird.
Desired RPO (minutes) (Gewünschter RPO-Wert (Minuten)): Entweder der RPO-Standardwert (Recovery Point Objective), oder der Wert, der für den Parameter „DesiredRPO“ zum Zeitpunkt der Berichterstellung übergeben wird, um die erforderliche Bandbreite zu schätzen.
Desired bandwidth (Mbps) (Gewünschte Bandbreite (MBit/s)): Der Wert, den Sie für den Parameter „Bandwidth“ zum Zeitpunkt der Berichterstellung übergeben haben, um den erreichbaren RPO-Wert (Recovery Point Objective) zu schätzen.
Observed typical data churn per day (GB) (Beobachtete typische Datenänderungsrate pro Tag (GB)): Die durchschnittliche, über alle Tage der Profilerstellung hinweg beobachtete Datenänderungsrate.
Empfehlungen
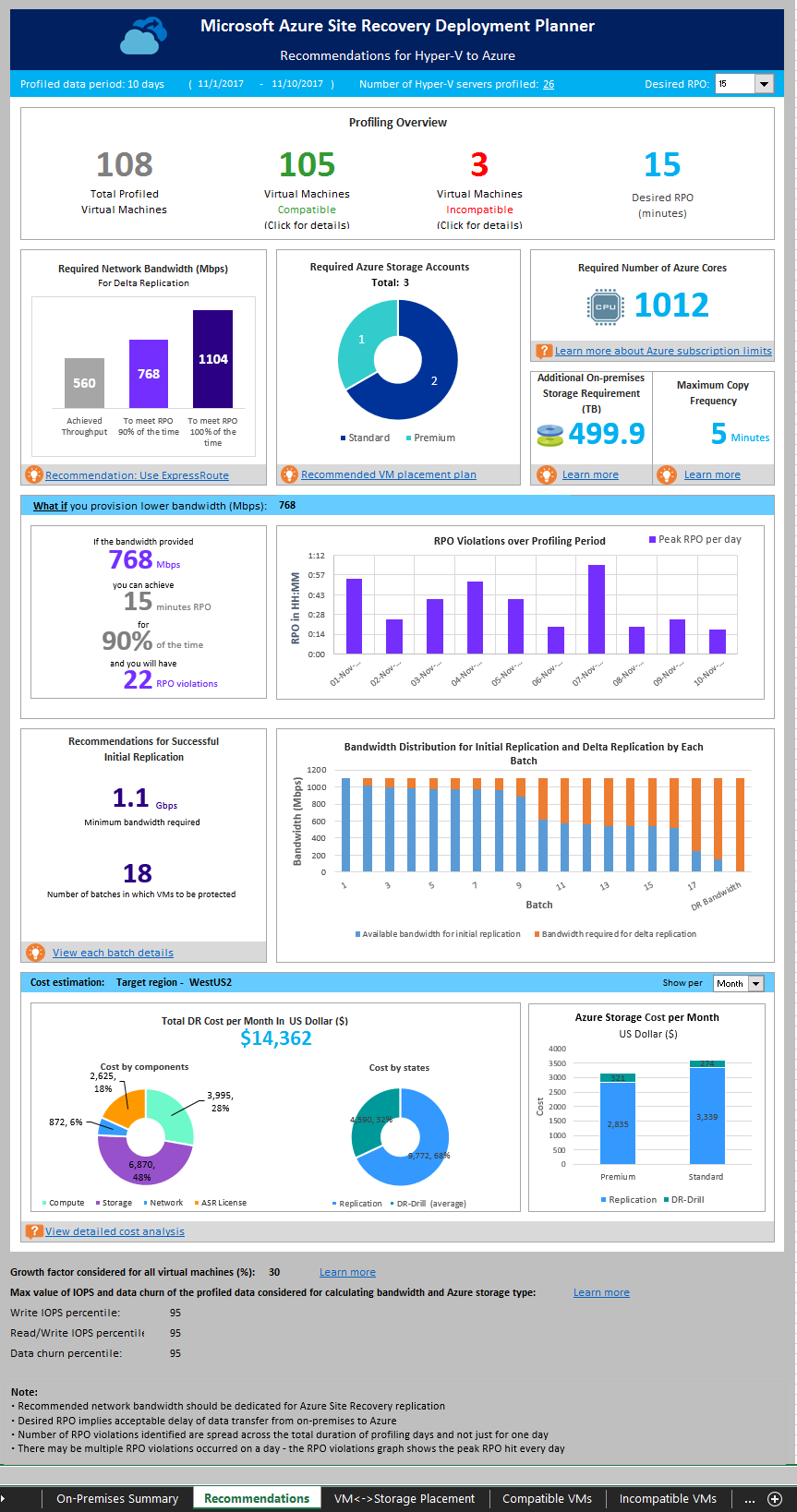
Die Tabelle „Recommendations“ (Empfehlungen) des Berichts für „Hyper-V zu Azure“ enthält je nach ausgewähltem gewünschtem RPO-Wert die folgenden Details:
Profilerstellungsdaten

Profiled data period (Zeitraum der Profilerstellung): Der Zeitraum, in dem die Profilerstellung durchgeführt wurde. Standardmäßig bindet das Tool alle Daten der Profilerstellung in die Berechnung ein. Wenn Sie die Optionen „StartDate“ und „EndDate“ bei der Berichterstellung verwendet haben, wird der Bericht für den jeweiligen Zeitraum erstellt.
Number of Hyper-V servers profiled (Anzahl von Hyper-V-Servern mit Profilerstellung): Die Anzahl von Hyper-V-Servern, für deren VMs der Bericht erstellt wird. Wählen Sie den Wert aus, um den Namen des Hyper-V-Servers anzuzeigen. Die Tabelle „On-premises Storage Requirement“ (Bedarf an lokalem Speicher) wird geöffnet, in der alle Server mit dem dazugehörigen Speicherbedarf aufgeführt sind.
Desired RPO (Gewünschter RPO-Wert): Der RPO-Wert (Recovery Point Objective) für Ihre Bereitstellung. Standardmäßig wird die erforderliche Netzwerkbandbreite für RPO-Werte von 15, 30 und 60 Minuten berechnet. Basierend auf der Auswahl werden die betroffenen Werte auf dem Blatt aktualisiert. Wenn Sie beim Erstellen des Berichts den Parameter „DesiredRPOinMin“ verwendet haben, wird dieser Wert als Ergebnis unter „Desired RPO“ (Gewünschter RPO-Wert) angezeigt.
Übersicht über die Profilerstellung

Total Profiled Virtual Machines (VMs mit Profilerstellung insgesamt): Die Gesamtanzahl der VMs, deren Profilerstellungsdaten verfügbar sind. Wenn „VMListFile“ Namen von VMs enthält, für die keine Profile erstellt wurden, werden diese VMs in der Berichterstellung nicht berücksichtigt und aus der Gesamtzahl von VMs für die Profilerstellung ausgeschlossen.
Compatible Virtual Machines (Kompatible virtuelle Computer): Die Anzahl von VMs, die mit Azure Site Recovery in Azure geschützt werden können. Dies ist die Gesamtzahl von kompatiblen VMs, für die die erforderliche Netzwerkbandbreite, die Anzahl von Speicherkonten und die Anzahl von Azure-Kernen berechnet werden. Die Details der einzelnen kompatiblen VMs sind im Abschnitt „Kompatible VMs“ enthalten.
Incompatible Virtual Machines (Inkompatible virtuelle Computer): Die Anzahl von VMs, für die Profile erstellt wurden und die mit dem Schutz mit Site Recovery inkompatibel sind. Die Gründe für die Inkompatibilität sind im Abschnitt „Inkompatible VMs“ beschrieben. Wenn „VMListFile“ Namen von VMs enthält, für die keine Profile erstellt wurden, werden diese VMs aus der Anzahl von inkompatiblen VMs ausgeschlossen. Diese VMs werden unten im Abschnitt „Incompatible VMs“ (Inkompatible VMs) unter „Data not found“ (Daten nicht gefunden) aufgeführt.
Desired RPO (Gewünschter RPO-Wert): Ihr gewünschter RPO-Wert (Recovery Point Objective) in Minuten. Der Bericht wird für drei RPO-Werte erstellt: 15 (Standard), 30 und 60 Minuten. Die Bandbreitenempfehlung im Bericht wird basierend auf Ihrer Auswahl in der Dropdownliste Desired RPO (Gewünschter RPO-Wert) oben rechts in der Tabelle geändert. Wenn Sie den Bericht mit dem Parameter „-DesiredRPO“ und einem benutzerdefinierten Wert erstellt haben, wird dieser benutzerdefinierte Wert in der Dropdownliste Desired RPO (Gewünschter RPO-Wert) als Standardwert angezeigt.
Erforderliche Netzwerkbandbreite (MBit/s)
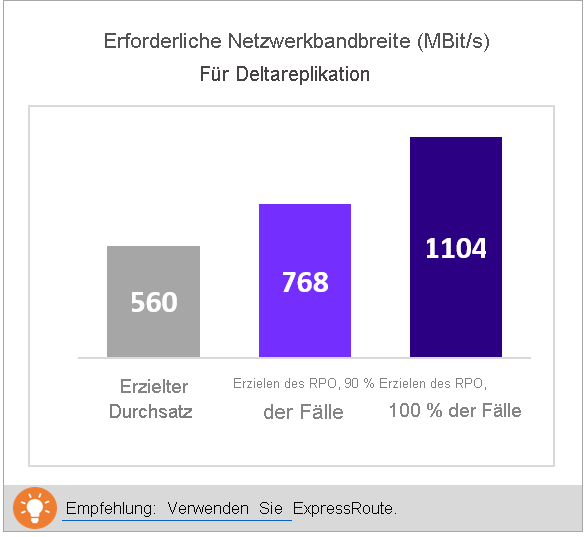
To meet RPO 100% of the time (Erreichung des RPO-Werts in 100 % der Fälle): Die empfohlene Bandbreite in MBit/s, die zugeordnet werden sollte, um den gewünschten RPO-Wert in 100% der Fälle zu erzielen. Diese Menge an Bandbreite muss dediziert für die Deltareplikation im stabilen Zustand für alle kompatiblen VMs bereitgestellt werden, um RPO-Verletzungen zu vermeiden.
To meet RPO 90% of the time (Erreichung des RPO-Werts in 90 % der Fälle): Es kann sein, dass Sie aufgrund der Breitbandpreise oder aus einem anderen Grund nicht die Bandbreite bereitstellen können, die zur Erreichung des gewünschten RPO-Werts in 100% der Fälle erforderlich ist. Sie können dann auch eine geringere Menge an Bandbreite bereitstellen, mit der der gewünschte RPO-Wert in 90% der Fälle erreicht wird. Zum besseren Verständnis der Auswirkungen, die mit dem Festlegen dieser geringeren Bandbreite verbunden sind, enthält der Bericht eine Was-wäre-wenn-Analyse zu Anzahl und Dauer der zu erwartenden RPO-Verletzungen.
Achieved Throughput: (Erzielter Durchsatz): Der Durchsatz von dem Server, auf dem Sie den GetThroughput-Befehl ausführen, zu der Azure-Region, in der sich das Speicherkonto befindet. Mit diesem Durchsatzwert wird die geschätzte Ebene angegeben, die Sie erreichen können, wenn Sie die kompatiblen VMs mit Azure Site Recovery schützen. Die Speicher- und Netzwerkmerkmale des Hyper-V-Servers müssen in Bezug auf den Server, auf dem Sie das Tool ausführen, unverändert bleiben.
Für alle Site Recovery-Bereitstellungen für Unternehmen empfehlen wir die Verwendung von ExpressRoute.
Erforderliche Speicherkonten
Im folgenden Diagramm wird die Gesamtzahl von Speicherkonten (Standard und Premium) angegeben, die zum Schützen aller kompatiblen VMs erforderlich sind. Informationen dazu, welches Speicherkonto für eine VM jeweils verwendet werden sollte, finden Sie im Abschnitt „VM/Speicher-Anordnung“.

Erforderliche Anzahl von Azure-Kernen
Dieses Ergebnis gibt die Gesamtzahl von Kernen an, die eingerichtet werden sollten, bevor ein Failover oder Testfailover für alle kompatiblen VMs durchgeführt wird. Falls im Abonnement zu wenig Kerne verfügbar sind, können von Site Recovery bei einem Testfailover oder Failover keine VMs erstellt werden.

Additional on-premises storage requirement (Zusätzlicher Bedarf an lokalem Speicher)
Gesamter freier Speicherplatz, der auf Hyper-V-Servern für die erfolgreiche anfängliche Replikation und Deltareplikation erforderlich ist, um sicherzustellen, dass es durch die VM-Replikation für Ihre Produktionsanwendungen nicht zu unerwünschten Ausfallzeiten kommt. Weitere Informationen zum Bedarf einzelner Volumes finden Sie unter On-premises Storage Requirement (Bedarf an lokalem Speicher).
Eine Antwort auf die Frage, warum freier Speicherplatz für die Replikation erforderlich ist, finden Sie in demselben Abschnitt unter Warum benötige ich auf dem Hyper-V-Server für die Replikation freien Speicherplatz?.

Maximum copy frequency (Maximale Kopierhäufigkeit)
Die empfohlene maximale Kopierhäufigkeit muss für die Replikation festgelegt werden, um den gewünschten RPO-Wert zu erzielen. Der Standardwert lautet 5 Minuten. Sie können die Kopierhäufigkeit auf 30 Sekunden festlegen, um einen besseren RPO-Wert zu erzielen.
Was-wäre-wenn-Analyse
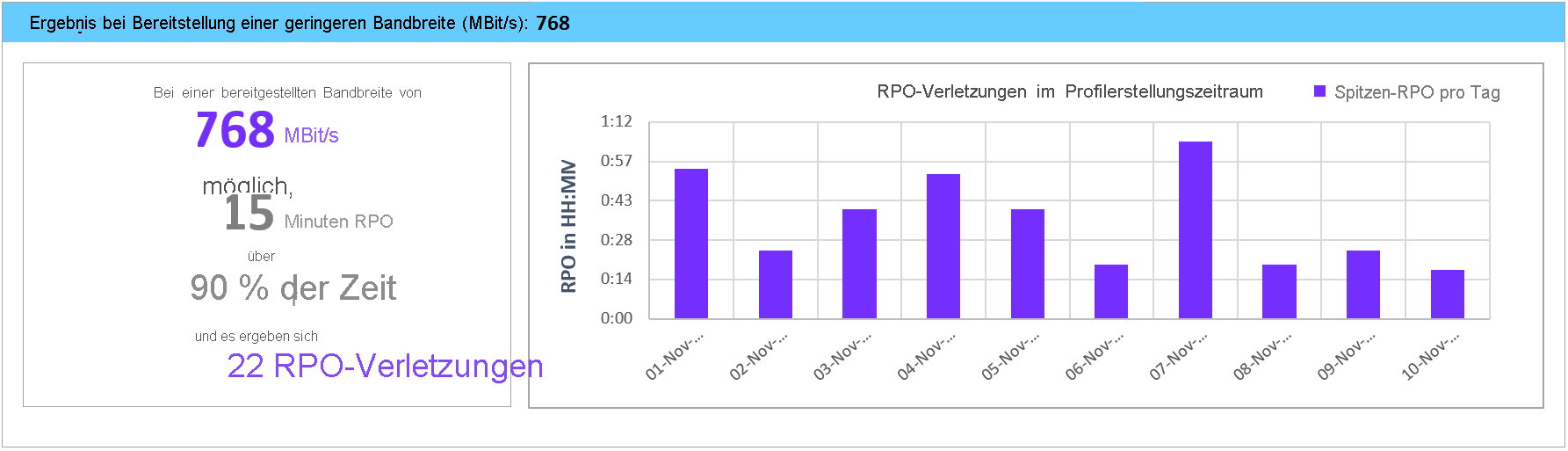 Bei dieser Analyse wird angegeben, wie viele Regelverletzungen während des Zeitraums der Profilerstellung auftreten können, wenn Sie eine geringere Bandbreite festlegen, um den gewünschten RPO-Wert nur in 90 Prozent der Fälle zu erreichen. Jeden Tag können eine oder mehrere RPO-Verletzungen auftreten. Im Graphen wird der RPO-Spitzenwert des Tages angezeigt. Anhand dieser Analyse können Sie entscheiden, ob die Anzahl von RPO-Verletzungen über alle Tage hinweg und die RPO-Spitzenwerte pro Tag für die angegebene geringere Bandbreite akzeptabel sind. Wenn es akzeptabel ist, können Sie die geringere Bandbreite für die Replikation zuordnen. Falls es nicht akzeptabel ist, sollten Sie die höhere Bandbreite gemäß Vorschlag zuordnen, um den gewünschten RPO-Wert in 100 Prozent der Fälle zu erreichen.
Bei dieser Analyse wird angegeben, wie viele Regelverletzungen während des Zeitraums der Profilerstellung auftreten können, wenn Sie eine geringere Bandbreite festlegen, um den gewünschten RPO-Wert nur in 90 Prozent der Fälle zu erreichen. Jeden Tag können eine oder mehrere RPO-Verletzungen auftreten. Im Graphen wird der RPO-Spitzenwert des Tages angezeigt. Anhand dieser Analyse können Sie entscheiden, ob die Anzahl von RPO-Verletzungen über alle Tage hinweg und die RPO-Spitzenwerte pro Tag für die angegebene geringere Bandbreite akzeptabel sind. Wenn es akzeptabel ist, können Sie die geringere Bandbreite für die Replikation zuordnen. Falls es nicht akzeptabel ist, sollten Sie die höhere Bandbreite gemäß Vorschlag zuordnen, um den gewünschten RPO-Wert in 100 Prozent der Fälle zu erreichen.
Empfehlung für eine erfolgreiche erste Replikation
In diesem Abschnitt wird die Anzahl von Batches beschrieben, in denen die VMs geschützt werden sollen, sowie die erforderliche Mindestbandbreite für die erfolgreiche Durchführung der ersten Replikation (Initial Replication, IR).
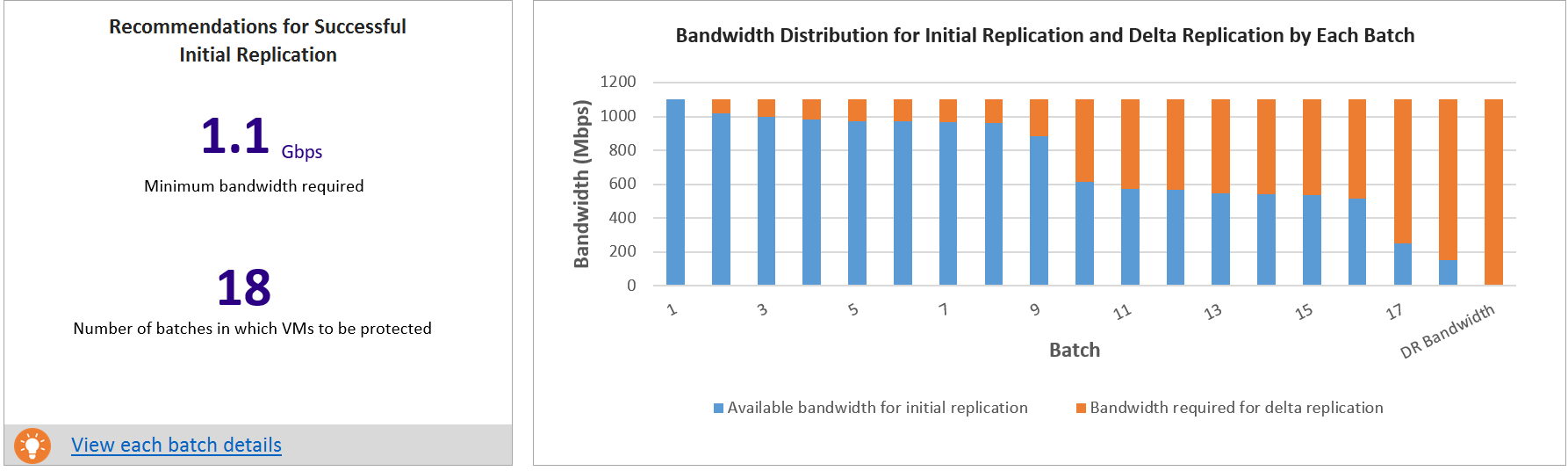
VMs müssen in der angegebenen Batchreihenfolge geschützt werden. Jeder Batch verfügt über eine bestimmte Liste mit VMs. Die VMs von Batch 1 müssen vor den VMs von Batch 2 geschützt werden. Die VMs von Batch 2 müssen vor den VMs von Batch 3 geschützt werden usw. Nachdem die erste Replikation für VMs von Batch 1 abgeschlossen ist, können Sie die Replikation für VMs von Batch 2 aktivieren. Entsprechend können Sie nach Abschluss der ersten Replikation für die VMs von Batch 2 die Replikation für die VMs von Batch 3 aktivieren usw.
Wenn die Batchreihenfolge nicht eingehalten wird, ist für die VMs, die später geschützt werden sollen, unter Umständen nicht genügend Bandbreite für die erste Replikation verfügbar. Das Ergebnis ist, dass die erste Replikation für VMs entweder niemals abgeschlossen wird oder dass für einige geschützte VMs der Modus für die erneute Synchronisierung aktiviert wird. Die IR-Batchverarbeitung für die gewählte RPO-Tabelle enthält die ausführlichen Informationen dazu, welche VMs in den einzelnen Batches enthalten sein sollen.
In diesem Graphen ist die Bandbreitenverteilung für die erste Replikation und die Deltareplikation über Batches in der angegebenen Batchreihenfolge hinweg dargestellt. Wenn Sie den ersten Batch mit VMs schützen, ist die vollständige Bandbreite für die erste Replikation verfügbar. Nach Abschluss der ersten Replikation für den ersten Batch wird ein Teil der Bandbreite für die Deltareplikation benötigt. Die verbleibende Bandbreite ist für die erste Replikation des zweiten Batchs mit VMs verfügbar.
Mit dem Balken für Batch 2 werden die erforderliche Bandbreite für die Deltareplikation für VMs von Batch 1 und die verfügbare Bandbreite für die erste Replikation für die VMs von Batch 2 dargestellt. Entsprechend werden mit dem Balken für Batch 3 die erforderliche Bandbreite für die Deltareplikation für vorherige Batches (VMs von Batch 1 und Batch 2) und die verfügbare Bandbreite für die erste Replikation für Batch 3 dargestellt usw. Nachdem die erste Replikation aller Batches abgeschlossen ist, zeigt der letzte Balken die erforderliche Bandbreite für die Deltareplikation für alle geschützten VMs an.
Warum ist die Batchverarbeitung für die erste Replikation erforderlich? Die Dauer der ersten Replikation basiert auf der VM-Datenträgergröße, dem genutzten Datenträgerspeicherplatz und dem verfügbaren Netzwerkdurchsatz. Dieses Detail ist bei der IR-Batchverarbeitung für eine ausgewählte RPO-Tabelle verfügbar.
Cost Estimation (Kostenvorkalkulation)
Im Graphen ist die Übersicht über die geschätzten Gesamtkosten der Notfallwiederherstellung (Disaster Recovery, DR) in Azure für Ihre gewählte Zielregion und Währung dargestellt, die Sie für die Berichterstellung angegeben haben.
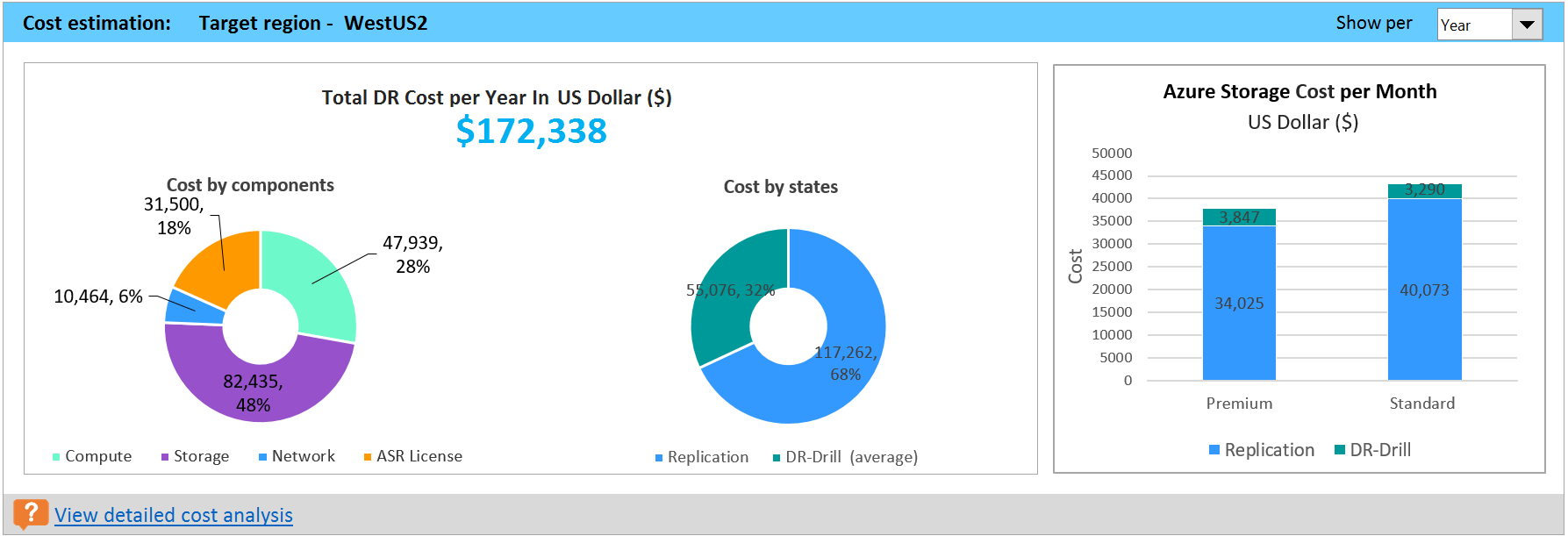
Die Zusammenfassung erleichtert das Verständnis der Kosten, die für Speicher, Compute, Netzwerk und Lizenzierung anfallen, wenn Sie Ihre gesamten kompatiblen VMs in Azure mit Site Recovery schützen. Die Kosten werden für kompatible VMs berechnet, nicht für alle VMs, für die eine Profilerstellung durchgeführt wurde.
Sie können die Kosten entweder monatlich oder jährlich anzeigen. Erfahren Sie mehr zu unterstützten Zielregionen und unterstützten Währungen.
Cost by components (Kosten nach Komponenten): Die Gesamtkosten für die Notfallwiederherstellung sind in vier Komponenten unterteilt: Compute, Speicher, Netzwerk und Site Recovery-Lizenzkosten. Die Kosten werden basierend auf dem Verbrauch berechnet, zu dem es während der Replikation und des DR-Drills kommt. Für die Berechnungen werden die Bereiche Compute, Speicher (Premium und Standard), die zwischen dem lokalen Standort und Azure konfigurierte ExpressRoute/VPN-Verbindung und die Site Recovery-Lizenz herangezogen.
Cost by states (Kosten nach Zustand): Die Gesamtkosten für die Notfallwiederherstellung werden basierend auf zwei unterschiedlichen Zuständen kategorisiert: Replikation und DR-Drill.
Replication cost (Replikationskosten): Die Kosten, die während der Replikation anfallen. Hierin sind die Kosten für Speicher, Netzwerk und die Site Recovery-Lizenz enthalten.
DR-Drill cost (Kosten für DR-Drills): Die Kosten, die bei Testfailovern anfallen. Während des Testfailovers startet Site Recovery virtuelle Computer (VMs). Die Kosten für DR-Drills decken die Compute- und Speicherkosten für die ausgeführten VMs ab.
Azure Storage Cost per Month/Year (Azure-Speicherkosten pro Monat/Jahr): Im Balkendiagramm werden die Speichergesamtkosten angezeigt, die bei der Replikation und bei DR-Drills für Storage Premium und Standardspeicher anfallen. Sie können die ausführliche Kostenanalyse pro VM in der Tabelle Cost Estimation (Kostenvorkalkulation) anzeigen.
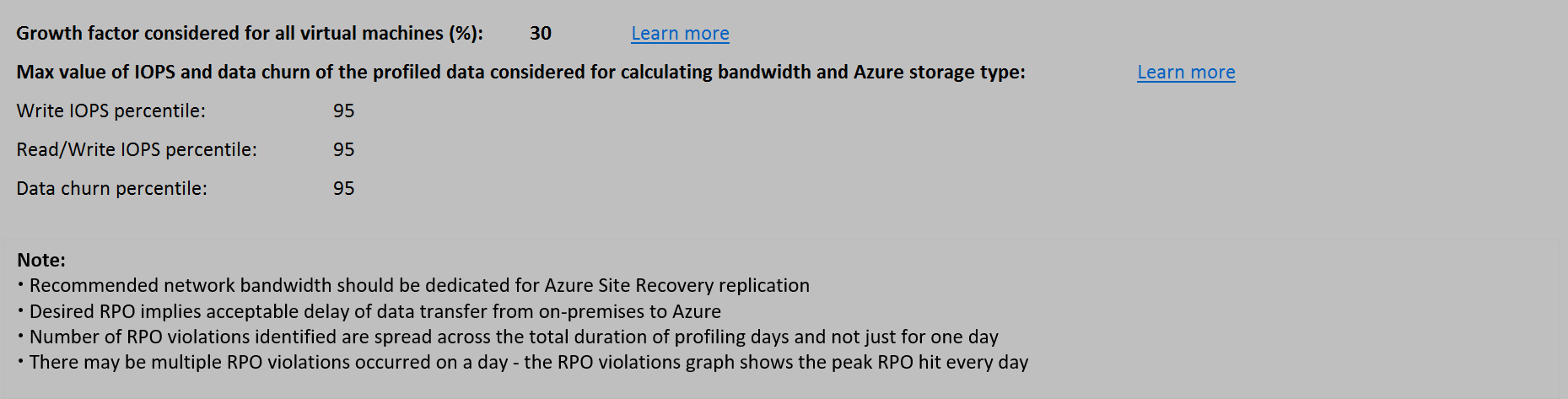
Verwendeter Zuwachsfaktor und Perzentilwerte
In diesem Abschnitt wird unten auf dem Blatt der verwendete Perzentilwert für alle Leistungsindikatoren der virtuellen Computer für die Profilerstellung (Standardeinstellung: 95. Perzentil) angezeigt. Außerdem wird der für alle Berechnungen verwendete Zuwachsfaktor (Standardeinstellung: 30 Prozent) angezeigt.
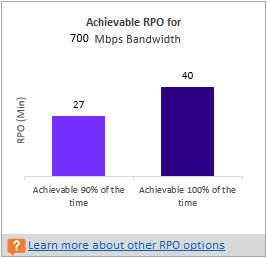
Empfehlungen mit verfügbarer Bandbreite als Eingabe

Es kann sein, dass Sie in einer bestimmten Situation wissen, dass Sie keine höhere Bandbreite als x MBit/s für die Site Recovery-Replikation festlegen können. Sie können das Tool verwenden, um die verfügbare Bandbreite (mit Verwendung des Parameters „-Bandwidth“ während der Berichterstellung) einzugeben und den erreichbaren RPO-Wert in Minuten zu ermitteln. Anhand dieser Angabe zum erreichbaren RPO-Wert können Sie entscheiden, ob Sie zusätzliche Bandbreite bereitstellen müssen oder ob eine Lösung für die Notfallwiederherstellung mit diesem RPO-Wert für Sie ausreicht.
Empfehlung für VM/Speicher-Anordnung
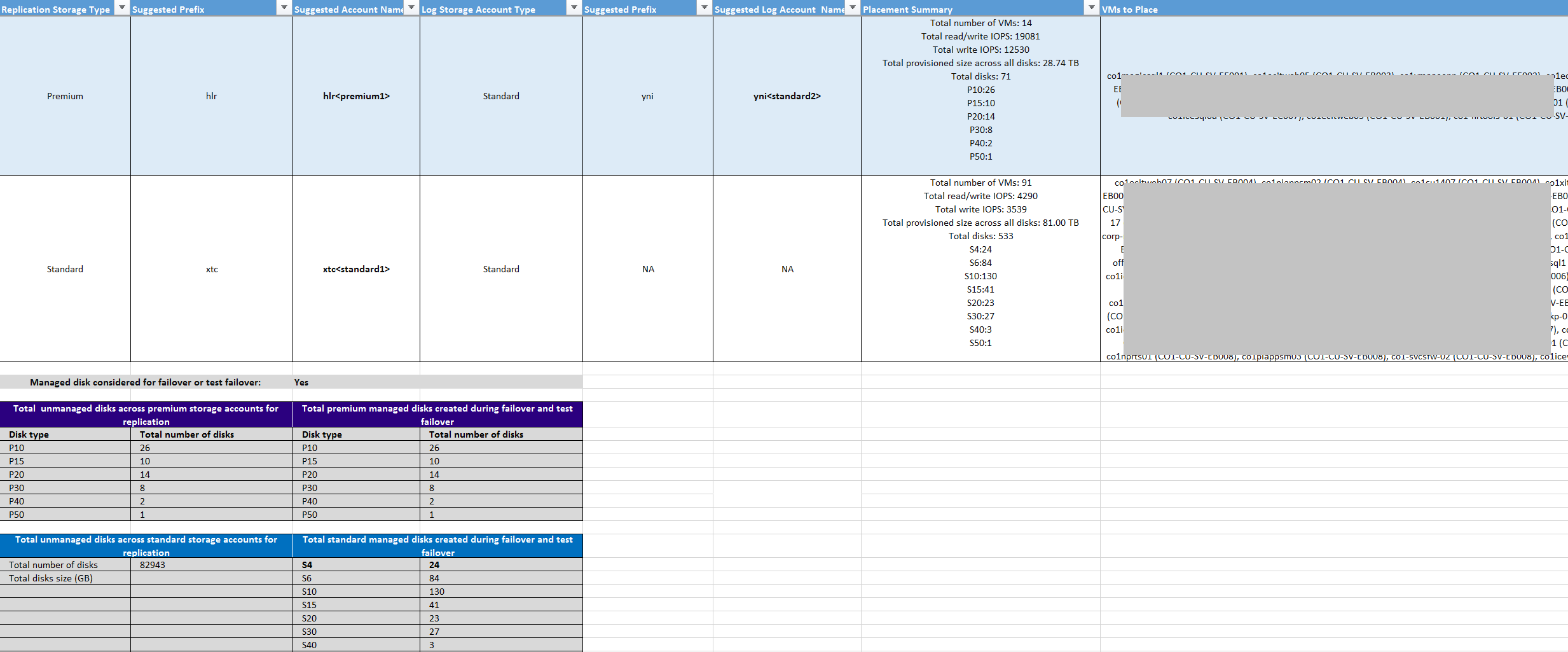
Disk Storage Type (Datenträger-Speichertyp): Entweder „Standard“ oder „Premium“. Dies ist das Speicherkonto, das zum Replizieren aller entsprechenden VMs verwendet wird, die in der Spalte VMs to Place (Anzuordnende VMs) angegeben sind.
Suggested Prefix (Vorgeschlagenes Präfix): Das vorgeschlagene Präfix aus drei Zeichen, das zum Benennen des Speicherkontos verwendet werden kann. Sie können ein eigenes Präfix verwenden, aber der Vorschlag des Tools basiert auf der Partitionsbenennungskonvention für Speicherkonten.
Suggested Account Name (Vorgeschlagener Kontoname): Der Speicherkontoname nach Einbindung des vorgeschlagenen Präfix. Ersetzen Sie den Namen innerhalb der spitzen Klammern (< und >) durch Ihre eigene Eingabe.
Log Storage Account (Protokollspeicherkonto): Alle Replikationsprotokolle werden in einem Speicherkonto vom Typ „Standard“ gespeichert. Richten Sie für VMs, die in einem Storage Premium-Konto repliziert werden, ein zusätzliches Standard-Speicherkonto für die Protokollspeicherung ein. Ein einzelnes Standard-Protokollspeicherkonto kann von mehreren Premium-Replikationsspeicherkonten genutzt werden. Für VMs, die unter Standardspeicherkonten repliziert werden, wird dasselbe Speicherkonto für Protokolle verwendet.
Suggested Log Account Name (Vorgeschlagener Protokollkontoname): Der Name des Speicherprotokollkontos nach Einbindung des vorgeschlagenen Präfix. Ersetzen Sie den Namen innerhalb der spitzen Klammern (< und >) durch Ihre eigene Eingabe.
Placement Summary (Zusammenfassung der Anordnung): Eine Übersicht über die gesamte VM-Last für das Speicherkonto zum Zeitpunkt der Replikation und des Testfailovers bzw. Failovers. Die Zusammenfassung enthält Folgendes:
- Gesamtzahl von VMs, die dem Speicherkonto zugeordnet sind
- Lese/Schreib-IOPS-Gesamtwert für alle im Speicherkonto angeordneten VMs
- Schreib-IOPS-Gesamtwert (Replikation)
- Eingerichtete Gesamtgröße aller Datenträger
- Gesamtzahl von Datenträgern
VMs to Place (Anzuordnende VMs): Eine Liste mit allen VMs, die im jeweiligen Speicherkonto angeordnet werden sollten, um die optimale Leistung und Nutzung zu erzielen.
Kompatible VMs
Der Excel-Bericht, der mit dem Site Recovery-Bereitstellungsplaner erstellt wurde, enthält alle kompatiblen VM-Details in der Tabelle „Compatible VMs“ (Kompatible VMs).
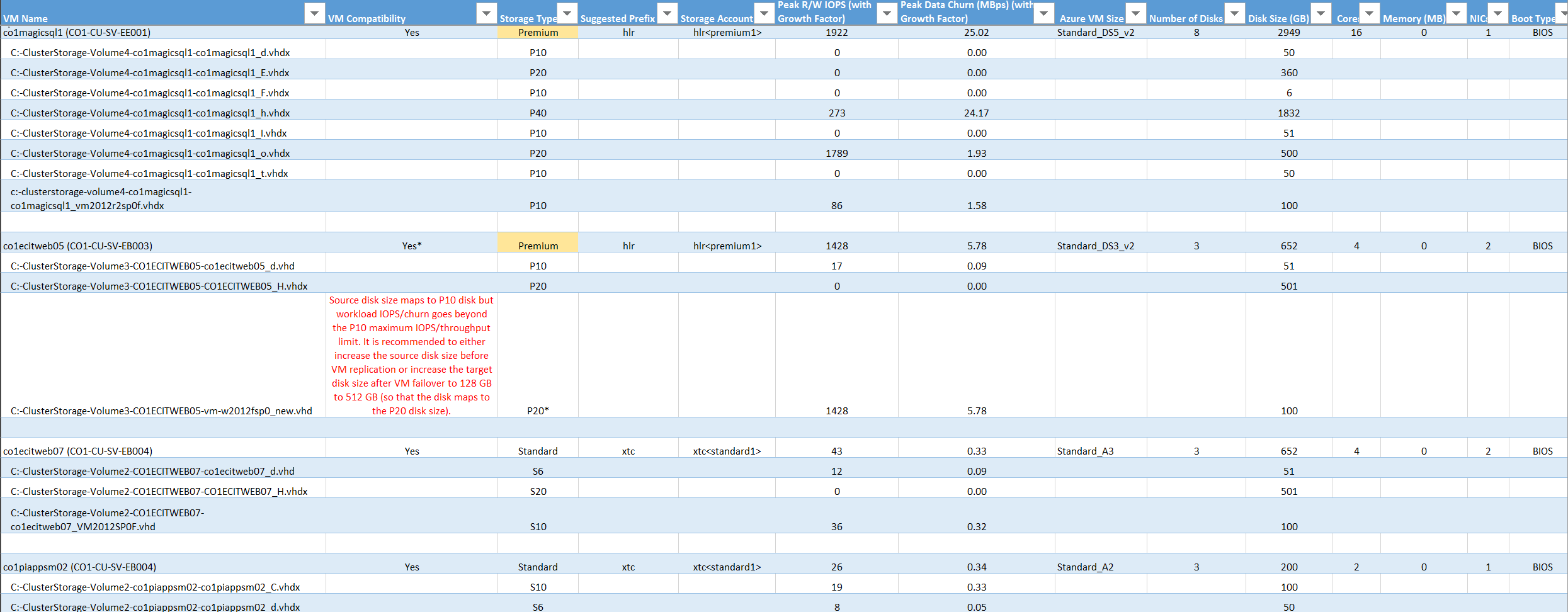
VM Name (Name des virtuellen Computers): Der VM-Name, der in „VMListFile“ verwendet wird, wenn ein Bericht erstellt wird. In dieser Spalte sind auch die Datenträger (VHDs) angegeben, die an die VMs angefügt sind. Die Namen enthalten die Hyper-V-Hostnamen, für die die VMs angeordnet wurden, als sie vom Tool während des Profilerstellungszeitraums erkannt wurden.
VM-Kompatibilität: Die Werte sind Ja und Ja*. Yes* steht für Fälle, in denen die VM für Premium-SSDs geeignet ist. Hier wird für die hohe Datenänderungsrate der Profilerstellung bzw. den IOPS-Datenträger eine höhere Premium-Datenträgergröße als die Größe verwendet, die dem Datenträger zugeordnet ist. Das Speicherkonto entscheidet basierend auf der Größe, welchem Storage Premium-Datenträgertyp ein Datenträger zugeordnet wird:
- <Bei bis 128 GB wird die Kategorie P10 verwendet.
- Bei 128 GB bis 256 GB wird die Kategorie P15 verwendet.
- Bei 256 GB bis 512 GB wird die Kategorie P20 verwendet.
- Bei 512 GB bis 1.024 GB wird die Kategorie P30 verwendet.
- Bei 1.025 GB bis 2.048 GB wird die Kategorie P40 verwendet.
- Bei 2.049 GB bis 4.095 GB wird die Kategorie P50 verwendet.
Wenn beispielsweise eine Festplatte aufgrund ihrer Workload-Merkmale in die Kategorie P20 oder P30 fällt, aber aufgrund ihrer Größe einem niedrigeren Premium-Speicherplattentyp zugeordnet wird, markiert das Tool diese VM als Ja*. Sie erhalten vom Tool außerdem die Empfehlung, dass Sie entweder die Größe des Quelldatenträgers an den empfohlenen Storage Premium-Datenträgertyp anpassen oder den Typ des Zieldatenträgers nach dem Failover ändern sollten.
Storage Type (Speichertyp): Standard oder Premium.
Suggested Prefix (Empfohlenes Präfix): Das dreistellige Präfix für das Speicherkonto.
Storage Account (Speicherkonto): Der Name, für den das vorgeschlagene Speicherkontopräfix verwendet wird.
Peak R/W IOPS (with Growth Factor) (Lese/Schreib-IOPS-Spitzenwert (mit Zuwachsfaktor)): Der Lese/Schreib-IOPS-Wert für die Spitzenworkload auf dem Datenträger (Standardeinstellung: 95. Perzentil) und der Faktor für den zukünftigen Zuwachs (Standardeinstellung: 30 Prozent). Der Lese/Schreib-IOPS-Gesamtwert einer VM ist nicht immer die Summe der Lese/Schreib-IOPS-Werte der einzelnen Datenträger aller VMs. Der Lese/Schreib-IOPS-Spitzenwert der VM ist der Spitzenwert der Summe aller Lese/Schreib-IOPS-Werte der einzelnen Datenträger für jede Minute des Profilerstellungszeitraums.
Peak Data Churn in MB/s (with Growth Factor) (Spitzendatenänderung (MB/s) (mit Zuwachsfaktor)): Die Spitzenänderungsrate auf dem Datenträger (Standardeinstellung: 95. Perzentil) und der Faktor für den zukünftigen Zuwachs (Standardeinstellung: 30 Prozent). Die gesamte VM-Datenänderung ist nicht immer die Summe der Datenänderung der einzelnen VM-Datenträger. Der Spitzenwert der VM-Datenänderung ist der Spitzenwert der Summe der Datenänderung seiner einzelnen Datenträger für jede Minute des Profilerstellungszeitraums.
Azure VM Size (Größe des virtuellen Azure-Computers): Die Idealgröße für die Zuordnung von Azure Cloud Services-VMs für diese lokale VM. Die Zuordnung basiert auf dem lokalen Arbeitsspeicher der VM, der Anzahl von Datenträgern/Kernen/NICs und dem Lese/Schreib-IOPS-Wert. Die Empfehlung ist immer die niedrigste Azure-VM-Größe, bei der alle Merkmale der lokalen VM erfüllt werden.
Number of Disks (Anzahl von Datenträgern): Die Gesamtzahl von Datenträgern auf dem virtuellen Computer (VHDs).
Disk Size (GB) (Datenträgergröße (GB)): Gesamtgröße aller Datenträger der VM. Im Tool wird auch die Datenträgergröße für die einzelnen Datenträger der VM angezeigt.
Cores (Kerne): Die Anzahl von CPU-Kernen auf der VM.
Memory (MB) (Arbeitsspeicher (MB)): Der Arbeitsspeicher (RAM) auf der VM.
NICs: Die Anzahl von NICs auf der VM.
Boot Type (Starttyp): Dies ist der Starttyp der VM. Er kann entweder „BIOS“ oder „EFI“ lauten.
Inkompatible VMs
Der Excel-Bericht, der mit dem Site Recovery-Bereitstellungsplaner erstellt wurde, enthält alle Details zu inkompatiblen VMs in der Tabelle „Incompatible VMs“ (Inkompatible VMs).
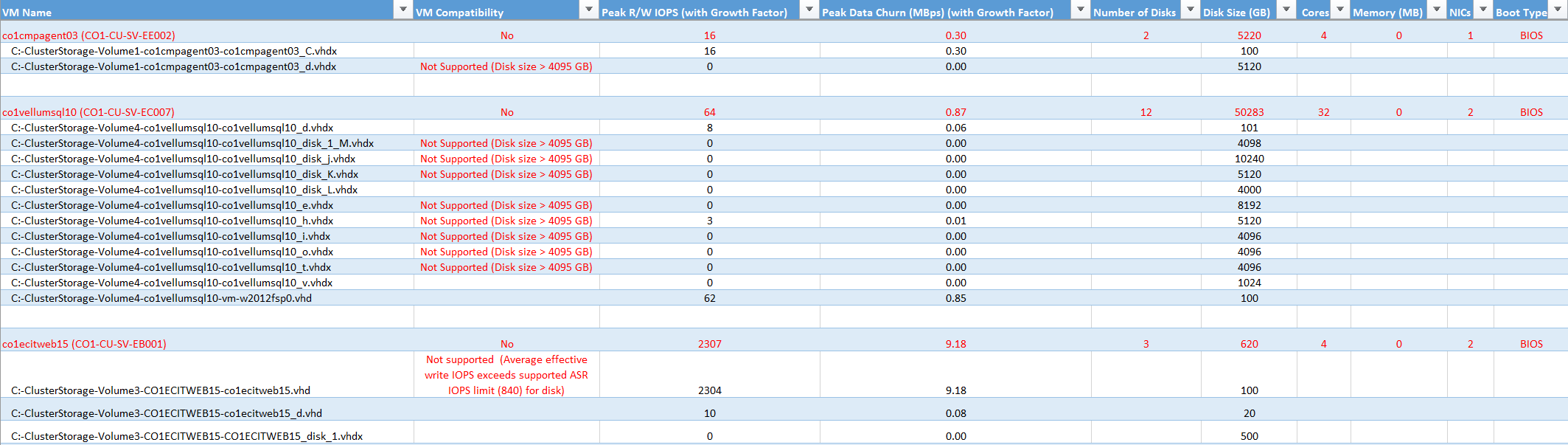
VM Name (Name des virtuellen Computers): Der VM-Name, der in „VMListFile“ verwendet wird, wenn ein Bericht erstellt wird. In dieser Spalte sind auch die Datenträger (VHDs) angegeben, die an die VMs angefügt sind. Die Namen enthalten die Hyper-V-Hostnamen, für die die VMs angeordnet wurden, als sie vom Tool während des Profilerstellungszeitraums erkannt wurden.
VM Compatibility (VM-Kompatibilität): Gibt an, warum die jeweilige VM für die Verwendung mit Site Recovery nicht kompatibel ist. Die Gründe werden für jeden inkompatiblen Datenträger der VM beschrieben. Basierend auf den veröffentlichten Speichergrenzwerten können dies folgende Gründe sein:
Die Datenträgergröße ist höher als 4.095 GB. Azure Storage unterstützt derzeit keine Datenträger, die größer als 4.095 GB sind.
Der Betriebssystemdatenträger ist für VMs der Generation 1 (Starttyp BIOS) größer als 2.047 GB. Site Recovery unterstützt für VMs der Generation 1 keine Betriebssystemdatenträger, die größer als 2.047 GB sind.
Der Betriebssystemdatenträger ist für VMs der Generation 2 (Starttyp EFI) größer als 300 GB. Site Recovery unterstützt für VMs der Generation 2 keine Betriebssystemdatenträger, die größer als 300 GB sind.
Für VM-Namen werden die folgenden Zeichen nicht unterstützt: “” [] `. Das Tool kann keine Profilerstellungsdaten für VMs abrufen, deren Name eines dieser Zeichen enthält.
Eine VHD wird von zwei oder mehr VMs gemeinsam verwendet. Azure unterstützt keine VMs mit einer freigegebenen virtuellen Festplatte (VHD).
Eine VM mit Virtual Fiber Channel wird nicht unterstützt. Site Recovery unterstützt keine VMs mit Virtual Fiber Channel.
Ein Hyper-V-Cluster enthält keinen Replikationsbroker. Site Recovery unterstützt eine VM eines Hyper-V-Clusters nicht, wenn der Hyper-V-Replikatbroker für den Cluster nicht konfiguriert ist.
Eine VM ist nicht hoch verfügbar. Site Recovery unterstützt keine VMs von Hyper-V-Clusterknoten, deren VHDs nicht auf dem Clusterdatenträger gespeichert sind, sondern auf dem lokalen Datenträger.
Die VM-Gesamtgröße (Replikation + Testfailover) übersteigt den Grenzwert für die Unterstützung von Storage Premium-Konten (35 TB). Diese Inkompatibilität tritt normalerweise auf, wenn ein einzelner Datenträger der VM über ein Leistungsmerkmal verfügt, das den unterstützten Azure- oder Site Recovery-Grenzwert für Standardspeicher überschreitet. Hierdurch fällt die VM in die Storage Premium-Zone. Die maximal unterstützte Größe eines Storage Premium-Kontos beträgt aber 35 TB. Eine einzelne geschützte VM kann nicht über mehrere Speicherkonten hinweg geschützt werden.
Wenn ein Testfailover auf einer geschützten VM durchgeführt wird und ein nicht verwalteter Datenträger für das Testfailover konfiguriert ist, erfolgt dies unter demselben Speicherkonto, unter dem die Replikation durchgeführt wird. Hierbei wird als zusätzlicher Speicherplatz die gleiche Menge wie für die Replikation benötigt. So wird sichergestellt, dass die Replikation und das Testfailover parallel durchgeführt werden können und der Vorgang erfolgreich ist. Wenn ein verwalteter Datenträger für das Testfailover konfiguriert ist, muss für die Testfailover-VM kein zusätzlicher Speicherplatz bereitgehalten werden.
Der IOPS-Quellwert übersteigt den unterstützten IOPS-Speichergrenzwert von 7.500 pro Datenträger.
Der IOPS-Quellwert übersteigt den unterstützten IOPS-Speichergrenzwert von 80.000 pro VM.
Die durchschnittliche Datenänderungsrate des virtuellen Quellcomputers übersteigt den unterstützten Grenzwert für die Site Recovery-Datenänderungsrate von 20 MB/s für die durchschnittliche E/A-Größe.
Der durchschnittliche effektive Schreib-IOPS-Wert des virtuellen Quellcomputers übersteigt den unterstützten Site Recovery-IOPS-Grenzwert von 840.
Der berechnete Momentaufnahmespeicher übersteigt den unterstützten Grenzwert für Momentaufnahmespeicher von 10 TB.
Peak R/W IOPS (with Growth Factor) (Lese/Schreib-IOPS-Spitzenwert (mit Zuwachsfaktor)): Der IOPS-Wert für die Spitzenworkload auf dem Datenträger (Standardeinstellung: 95. Perzentil) und der Faktor für den zukünftigen Zuwachs (Standardeinstellung: 30 Prozent). Der Lese/Schreib-IOPS-Gesamtwert der VM ist nicht immer die Summe der Lese/Schreib-IOPS-Werte der einzelnen VM-Datenträger. Der Lese/Schreib-IOPS-Spitzenwert der VM ist der Spitzenwert der Summe aller Lese/Schreib-IOPS-Werte der einzelnen Datenträger für jede Minute des Profilerstellungszeitraums.
Peak Data Churn (MB/s) (with Growth Factor) (Spitzendatenänderung (MB/s) (mit Zuwachsfaktor)): Die Spitzenänderungsrate auf dem Datenträger (Standardeinstellung: 95. Perzentil) und der Faktor für den zukünftigen Zuwachs (Standardeinstellung: 30 Prozent). Beachten Sie, dass die gesamte VM-Datenänderung nicht immer die Summe der Datenänderung der einzelnen VM-Datenträger ist. Der Spitzenwert der VM-Datenänderung ist der Spitzenwert der Summe der Datenänderung seiner einzelnen Datenträger für jede Minute des Profilerstellungszeitraums.
Number of Disks (Anzahl von Datenträgern): Die Gesamtzahl von VHDs auf der VM.
Disk Size (GB) (Datenträgergröße (GB)): Eingerichtete Gesamtgröße aller Datenträger der VM. Im Tool wird auch die Datenträgergröße für die einzelnen Datenträger der VM angezeigt.
Cores (Kerne): Die Anzahl von CPU-Kernen auf der VM.
Memory (MB) (Arbeitsspeicher (MB)): Die Größe des Arbeitsspeichers (RAM) auf der VM.
NICs: Die Anzahl von NICs auf der VM.
Boot Type (Starttyp): Dies ist der Starttyp der VM. Er kann entweder „BIOS“ oder „EFI“ lauten.
Azure Site Recovery-Grenzwerte
Die folgende Tabelle enthält die Site Recovery-Grenzwerte. Diese Grenzwerte basieren auf Tests, können aber nicht alle möglichen E/A-Kombinationen für Anwendungen abdecken. Die tatsächlichen Ergebnisse können je nach Ihrer E/A-Mischung für die Anwendungen variieren. Führen Sie zur Erzielung der bestmöglichen Ergebnisse auch nach der Planung der Bereitstellung umfangreiche Anwendungstests per Testfailover durch, um sich ein eindeutiges Bild der Anwendungsleistung zu verschaffen.
| Replikationsspeicherziel | Durchschnittliche E/A-Größe des virtuellen Quellcomputers | Durchschnittliche Datenänderungsrate des virtuellen Quellcomputers | Gesamte Datenänderungsrate des virtuellen Quellcomputers pro Tag |
|---|---|---|---|
| Standardspeicher | 8 KB | 2 MB/s pro virtuellem Computer | 168 GB pro virtuellem Computer |
| Storage Premium | 8 KB | 5 MB/s pro virtuellem Computer | 421 GB pro virtuellem Computer |
| Storage Premium | 16 KB oder höher | 20 MB/s pro virtuellem Computer | 1.684 GB pro virtuellem Computer |
Diese Grenzwerte sind Durchschnittswerte, bei denen eine E/A-Überlappung von 30% angenommen wird. Site Recovery kann einen höheren Durchsatz basierend auf dem Überlappungsverhältnis, höheren Schreibgrößen und dem tatsächlichen Workload-E/A-Verhalten verarbeiten. Für die obigen Zahlen wurde ein typischer Backlog von ca. fünf Minuten vorausgesetzt. Dies bedeutet, dass die Daten nach dem Hochladen verarbeitet werden und innerhalb von fünf Minuten ein Wiederherstellungspunkt erstellt wird.
On-premises Storage Requirement (Bedarf an lokalem Speicher)
Im Arbeitsblatt wird der gesamte freie Speicherplatz für jedes Volume der Hyper-V-Server (auf denen sich VHDs befinden) angegeben, der für eine erfolgreiche erste Replikation und Deltareplikation benötigt wird. Fügen Sie vor dem Aktivieren der Replikation den erforderlichen Speicherplatz auf den Volumes hinzu, um sicherzustellen, dass die Replikation keine unerwünschten Ausfallzeiten Ihrer Produktionsanwendungen verursacht.
Der Site Recovery-Bereitstellungsplaner identifiziert den optimalen Speicherplatzbedarf basierend auf der Größe der VHD und der Netzwerkbandbreite für die Replikation.
Warum benötige ich auf dem Hyper-V-Server für die Replikation freien Speicherplatz?
Wenn Sie die Replikation einer VM aktivieren, erstellt Site Recovery eine Momentaufnahme für jede VHD der VM für die erste Replikation. Während die erste Replikation durchgeführt wird, werden von der Anwendung neue Änderungen auf die Datenträger geschrieben. Site Recovery verfolgt diese Deltaänderungen in den Protokolldateien nach, und hierfür ist zusätzlicher Speicherplatz erforderlich. Bis zum Abschluss der ersten Replikation werden die Protokolldateien lokal gespeichert.
Falls nicht genügend Speicherplatz für die Protokolldateien und die Momentaufnahme (AVHDX) verfügbar ist, wird für die Replikation der Modus für die erneute Synchronisierung aktiviert und die Replikation niemals abgeschlossen. Im schlimmsten Fall benötigen Sie 100 Prozent zusätzlichen freien Speicherplatz der VHD-Größe für die erste Replikation.
Nachdem die erste Replikation abgeschlossen ist, beginnt die Deltareplikation. Site Recovery verfolgt diese Deltaänderungen in den Protokolldateien, die auf dem Volume gespeichert sind, auf dem sich die VHDs der VM befinden. Diese Protokolldateien werden in Azure mit der konfigurierten Kopierhäufigkeit repliziert. Je nach verfügbarer Netzwerkbandbreite dauert es einige Zeit, bis die Protokolldateien in Azure repliziert werden.
Wenn nicht genügend freier Speicherplatz zum Speichern der Protokolldateien verfügbar ist, wird die Replikation angehalten. Der Replikationsstatus der VM wechselt in diesem Fall zu „Neusynchronisierung erforderlich“.
Falls die Netzwerkbandbreite nicht ausreicht, um die Protokolldateien per Pushvorgang nach Azure zu übertragen, bildet sich auf dem Volume für die Protokolldateien ein Rückstau. Wenn die Größe der Protokolldateien auf 50 Prozent der VHD-Größe erhöht wird, führt die Replikation der VM im ungünstigsten Fall zu "Resynchronisierung erforderlich". Im ungünstigsten Fall benötigen Sie 50 Prozent zusätzlichen freien Speicherplatz der Größe VHD für Deltareplikation.
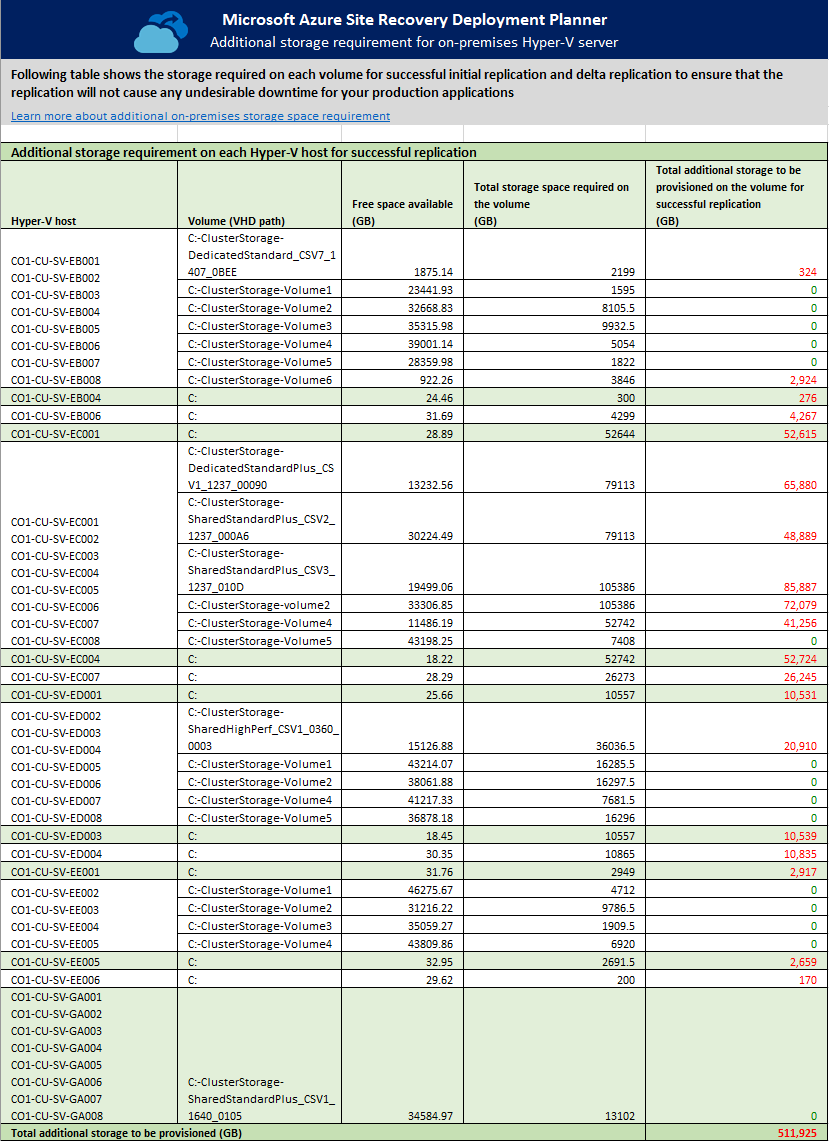
Hyper-V-Host: Die Liste mit den Hyper-V-Servern für die Profilerstellung. Wenn ein Server Teil eines Hyper-V-Clusters ist, werden alle Clusterknoten gruppiert.
Volume (VHD path) (Volume (VHD-Pfad)): Jedes Volume mit einem Hyper-V-Host, auf dem VHDs/VHDXs vorhanden sind.
Free space available (GB) (Verfügbarer freier Speicher (GB)): Der verfügbare freie Speicherplatz auf dem Volume.
Total storage space required on the volume (GB) (Gesamter benötigter Speicher auf dem Volume (GB)): Der gesamte freie Speicherplatz, der auf dem Volume benötigt wird, um die erste Replikation und die Deltareplikation erfolgreich durchführen zu können.
Total additional storage to be provisioned on the volume for successful replication (GB) (Gesamter auf dem Volume bereitzustellender zusätzlicher Speicher, der für eine erfolgreiche Replikation erforderlich ist (GB)): Gibt die Empfehlung für den gesamten zusätzlichen Speicher an, der auf dem Volume bereitgestellt werden muss, damit die erste Replikation und die Deltareplikation erfolgreich durchgeführt werden können.
Batchverarbeitung für die erste Replikation
Warum ist die Batchverarbeitung für die erste Replikation erforderlich?
Wenn alle virtuellen Computer gleichzeitig geschützt werden, wird deutlich mehr freier Speicherplatz benötigt. Falls nicht genügend Speicherplatz verfügbar ist, wird für die Replikation der VMs der Modus „Neusynchronisierung“ aktiviert. Außerdem ist der Bedarf an Netzwerkbandbreite deutlich höher, damit die erste Replikation für alle VMs zusammen erfolgreich abgeschlossen wird.
Batchverarbeitung für die erste Replikation für einen gewählten RPO-Wert
Dieses Arbeitsblatt enthält eine ausführliche Übersicht über die einzelnen Batches für die erste Replikation. Für jeden RPO-Wert wird ein separates Arbeitsblatt für die IR-Batchverarbeitung erstellt.
Nachdem Sie für jedes Volume die Empfehlung zum erforderlichen lokalen Speicher befolgt haben, benötigen Sie als wichtigste Information für die Replikation die Liste mit den VMs, die parallel geschützt werden können. Diese VMs werden zu einem Batch gruppiert, und es können mehrere Batches vorhanden sein. Schützen Sie die VMs in der angegebenen Batchreihenfolge. Schützen Sie zuerst die VMs von Batch 1. Schützen Sie nach Abschluss der ersten Replikation dann die VMs von Batch 2 usw. Sie können die Liste mit den Batches und den entsprechenden VMs in diesem Arbeitsblatt ablesen.
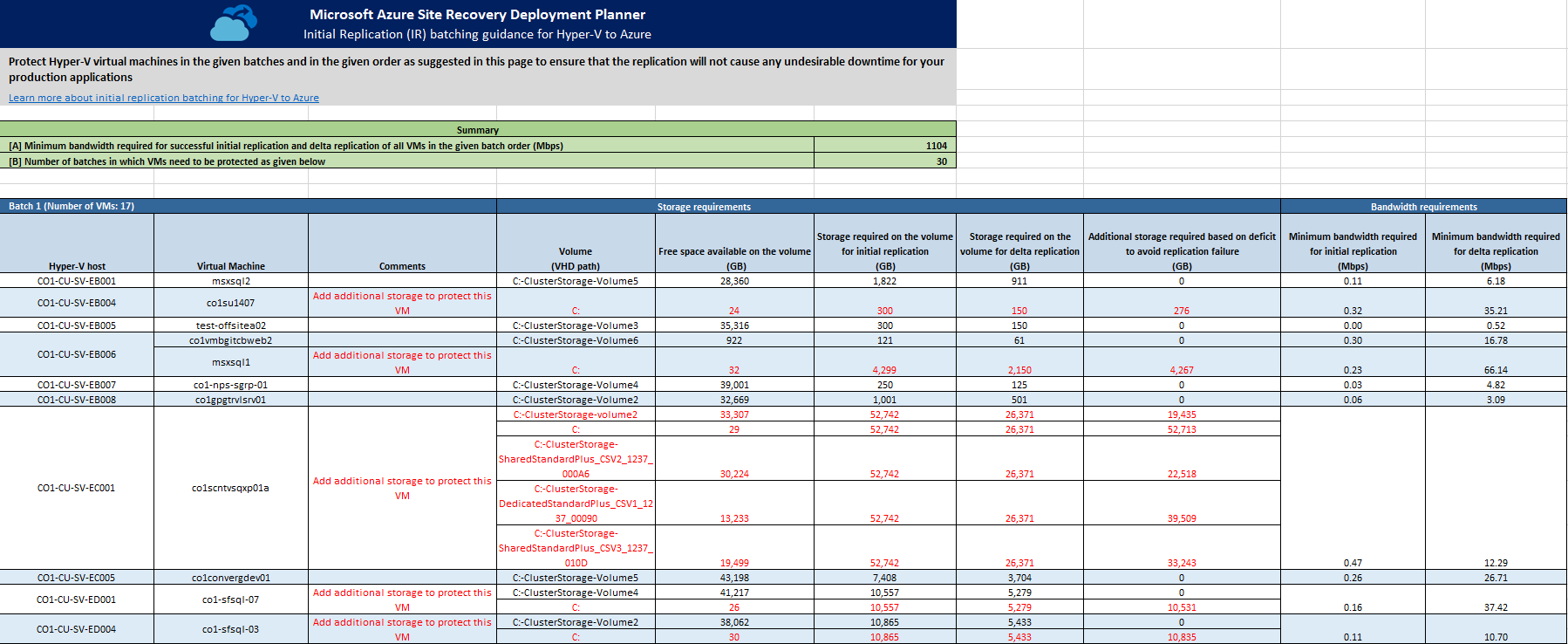
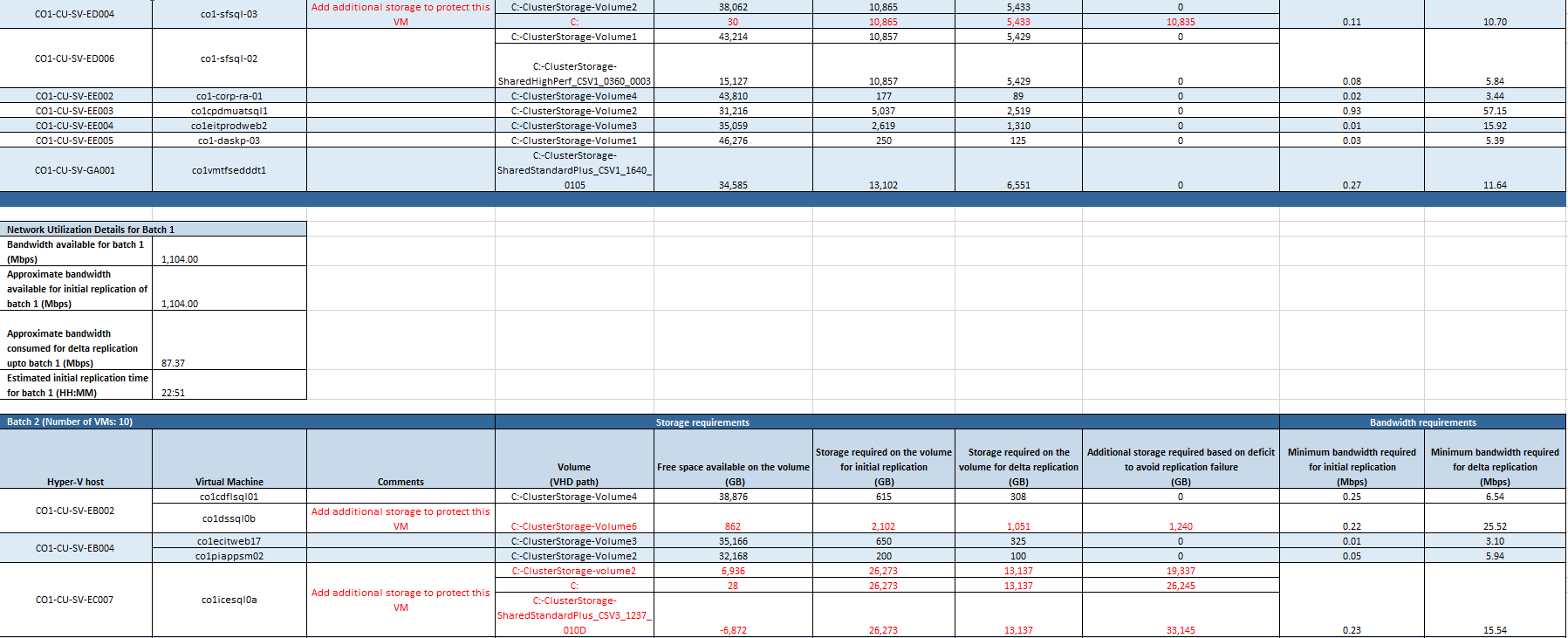
Für jeden Batch werden die folgenden Informationen angegeben:
Hyper-V host (Hyper-V-Host): Der Hyper-V-Host der zu schützenden VM.
Virtual Machine (Virtueller Computer): Die zu schützende VM.
Comments (Kommentare): Falls für ein bestimmtes Volume einer VM eine Aktion erforderlich ist, wird der Kommentar hier angegeben. Wenn auf dem Volume beispielsweise nicht genügend Speicherplatz verfügbar ist, lautet der Kommentar „Add additional storage to protect this VM“ (Zum Schützen dieser VM zusätzlichen Speicherplatz hinzufügen).
Volume (VHD path) (Volume (VHD-Pfad)): Der Name des Volumes, auf dem sich die VHDs der VM befinden.
Free space available on the volume (GB) (Verfügbarer freier Speicher auf dem Volume (GB)): Der freie Speicherplatz, der auf dem Volume für die VM verfügbar ist. Beim Berechnen des verfügbaren freien Speicherplatzes auf den Volumes wird der Speicherplatz auf dem Datenträger berücksichtigt, der für die Deltareplikation von den VMs der vorherigen Batches verwendet wird, deren VHDs sich auf demselben Volume befinden.
Beispielsweise können sich VM1, VM2 und VM3 auf einem Volume befinden, z.B. „E:\VHDpath“. Vor der Replikation beträgt der freie Speicherplatz auf dem Volume 500 GB. VM1 ist Teil von Batch 1, VM2 ist Teil von Batch 2 und VM3 ist Teil von Batch 3. Für VM1 beträgt der verfügbare freie Speicherplatz 500 GB. Für VM2 beträgt der verfügbare freie Speicherplatz 500 GB abzüglich des Speicherplatzes auf dem Datenträger, der für die Deltareplikation für VM1 benötigt wird. Wenn VM1 300 GB Speicherplatz für die Deltareplikation benötigt, beträgt der verfügbare freie Speicherplatz für VM2 500 GB - 300 GB = 200 GB. Entsprechend benötigt VM2 für die Deltareplikation 300 GB. Der verfügbare freie Speicherplatz für VM3 beträgt 200 GB - 300 GB = -100 GB.
Storage required on the volume for initial replication (GB) (Erforderlicher Speicher auf dem Volume für die erste Replikation (GB)): Der freie Speicherplatz, der auf dem Volume für die VM für die erste Replikation benötigt wird.
Storage required on the volume for delta replication (GB) (Erforderlicher Speicher auf dem Volume für die Deltareplikation (GB)): Der freie Speicherplatz, der auf dem Volume für die VM für die Deltareplikation benötigt wird.
Additional storage required based on deficit to avoid replication failure (GB) (Zusätzlicher erforderlicher Speicher gemäß Defizit zur Vermeidung eines Replikationsfehlers (GB)): Der zusätzliche Speicherplatz, der auf dem Volume für die VM benötigt wird. Dieser Wert ist der Höchstwert des Speicherplatzbedarfs für die erste Replikation und Deltareplikation abzüglich des verfügbaren freien Speichers auf dem Volume.
Minimum bandwidth required for initial replication (Mbps) (Erforderliche Mindestbandbreite für die erste Replikation (MBit/s)): Die erforderliche Mindestbandbreite für die erste Replikation der VM.
Minimum bandwidth required for delta replication (Mbps) (Erforderliche Mindestbandbreite für die Deltareplikation (MBit/s)): Die erforderliche Mindestbandbreite für die Deltareplikation der VM.
Details zur Netzwerknutzung für jeden Batch
Jede Batchtabelle enthält eine Zusammenfassung der Netzwerknutzung des Batchs.
Bandwidth available for batch (Verfügbare Bandbreite für Batch): Die verfügbare Bandbreite für den Batch nach Berücksichtigung der Bandbreite für die Deltareplikation des vorherigen Batchs.
Approximate bandwidth available for initial replication of batch (Ungefähre verfügbare Bandbreite für die erste Replikation des Batchs): Die verfügbare Bandbreite für die erste Replikation der VMs des Batchs.
Approximate bandwidth consumed for delta replication of batch (Ungefähre verbrauchte Bandbreite für die Deltareplikation des Batchs): Die erforderliche Bandbreite, die für die Deltareplikation der VMs des Batchs benötigt wird.
Estimated initial replication time for batch (HH:MM) (Geschätzte Dauer der ersten Replikation für den Batch (HH:MM)): Die geschätzte Dauer für die erste Replikation in Stunden:Minuten.
Nächste Schritte
Erfahren Sie mehr über die Kostenvorkalkulation.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für