Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tipp
Microsoft Fabric Data Warehouse ist ein relationales Enterprise-Warehouse auf einem Data Lake-Fundament mit zukunftsfähiger Architektur, integrierter KI und neuen Features. Wenn Sie mit Data Warehouse noch nicht vertraut sind, beginnen Sie mit Fabric Data Warehouse. Vorhandene dedizierte SQL-Pool-Workloads können auf Fabric aktualisieren, um neue Funktionen in den Bereichen Data Science, Echtzeitanalyse und Berichterstellung zu nutzen.
Die OPENROWSET(BULK...)-Funktion ermöglicht den Zugriff auf Dateien in Azure Storage. Die OPENROWSET-Funktion liest den Inhalt einer Remotedatenquelle (z. B. einer Datei) und gibt den Inhalt als eine Reihe von Zeilen zurück. Innerhalb des serverlosen SQL-Pools wird die OPENROWSET-Funktion aufgerufen und die BULK-Option angegeben, um auf den OPENROWSET-Massenrowsetanbieter zuzugreifen.
Auf die OPENROWSET-Funktion kann in der FROM-Klausel einer Abfrage so verwiesen werden, als handele es sich um einen Tabellennamen vom Typ OPENROWSET. Sie unterstützt Massenvorgänge über einen integrierten BULK-Anbieter, mit dem Daten aus einer Datei gelesen und als Rowset zurückgegeben werden können.
Hinweis
Die OPENROWSET-Funktion wird in einem dedizierten SQL-Pool nicht unterstützt.
Datenquelle
Die OPENROWSET-Funktion in Synapse SQL liest den Inhalt der Dateien aus einer Datenquelle. Die Datenquelle ist ein Azure-Speicherkonto, auf das in der OPENROWSET-Funktion explizit verwiesen werden oder das dynamisch aus der URL der zu lesenden Dateien abgeleitet werden kann.
Die OPENROWSET-Funktion kann optional einen DATA_SOURCE-Parameter enthalten, um die Datenquelle anzugeben, die Dateien enthält.
Mit
OPENROWSETohneDATA_SOURCEkann der Inhalt der Dateien direkt aus dem URL-Speicherort gelesen werden, der alsBULK-Option angegeben ist:SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.windows.net/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
Dies ist eine schnelle und einfache Möglichkeit, den Inhalt der Dateien ohne Vorkonfiguration zu lesen. Mit dieser Option können Sie die Standardauthentifizierungsoption zum Zugreifen auf den Speicher verwenden (Microsoft Entra-Passthrough für Microsoft Entra-Anmeldungen und SAS-Token für SQL-Anmeldungen).
Mit
OPENROWSETmitDATA_SOURCEkann auf Dateien im angegebenen Speicherkonto zugegriffen werden:SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]Mit dieser Option können Sie den Speicherort des Speicherkontos in der Datenquelle konfigurieren und die Authentifizierungsmethode angeben, die für den Speicherzugriff verwendet werden soll.
Wichtig
OPENROWSETohneDATA_SOURCEbietet eine schnelle und einfache Möglichkeit, auf die Speicherdateien zuzugreifen, weist jedoch eingeschränkte Authentifizierungsoptionen auf. Beispielsweise können Microsoft Entra-Prinzipale nur über ihre Microsoft Entra-Identität oder auf öffentlich verfügbare Dateien zugreifen. Wenn Sie leistungsfähigere Authentifizierungsoptionen benötigen, verwenden Sie dieDATA_SOURCE-Option, und definieren Sie die Anmeldeinformation, die Sie für den Speicherzugriff verwenden möchten.
Sicherheit
Ein Datenbankbenutzer muss über die Berechtigung ADMINISTER BULK OPERATIONS verfügen, um die OPENROWSET-Funktion zu verwenden.
Speicheradministrator*innen müssen Benutzer*innen außerdem den Zugriff auf die Dateien ermöglichen, indem sie ein gültiges SAS-Token bereitstellen oder dem Microsoft Entra-Prinzipal Zugriff auf Speicherdateien gewähren. Weitere Informationen zur Speicherzugriffssteuerung finden Sie in diesem Artikel.
OPENROWSET verwendet die folgenden Regeln, um zu bestimmen, wie die Authentifizierung beim Speicher erfolgt:
- Bei
OPENROWSETohneDATA_SOURCEist der Authentifizierungsmechanismus abhängig vom Aufrufertyp.- Jeder Benutzer kann
OPENROWSETohneDATA_SOURCEzum Lesen öffentlich verfügbarer Dateien im Azure-Speicher verwenden. - Microsoft Entra-Anmeldungen können über ihre eigene Microsoft Entra-Identität auf geschützte Dateien zugreifen, wenn Azure Storage den Microsoft Entra-Benutzer*innen den Zugriff auf zugrunde liegende Dateien erlaubt (z. B. wenn der Aufrufer über die Berechtigung
Storage Readerin Azure Storage verfügt). - SQL-Anmeldungen können
OPENROWSETauch ohneDATA_SOURCEverwenden, um auf öffentlich verfügbare Dateien, Dateien, die mit einem SAS-Token geschützt sind, oder eine verwaltete Identität des Synapse-Arbeitsbereichs zuzugreifen. Sie müssen eine serverbezogene Anmeldeinformation erstellen, um den Zugriff auf Speicherdateien zuzulassen.
- Jeder Benutzer kann
- Bei
OPENROWSETmitDATA_SOURCEist der Authentifizierungsmechanismus in der datenbankbezogenen Anmeldeinformation definiert, die der referenzierten Datenquelle zugewiesen wurde. Mit dieser Option können Sie auf öffentlich verfügbaren Speicher zugreifen oder für den Speicherzugriff ein SAS-Token, die verwaltete Identität des Arbeitsbereichs oder die Microsoft Entra-Identität des Aufrufers verwenden (wenn der Aufrufer der Microsoft Entra-Prinzipal ist). WennDATA_SOURCEauf nicht öffentlichen Azure-Speicher verweist, müssen Sie eine datenbankbezogene Anmeldeinformation erstellen und inDATA SOURCEdarauf verweisen, um den Zugriff auf Speicherdateien zu erlauben.
Der Aufrufer muss über die Berechtigung REFERENCES für die Anmeldeinformation verfügen, um sie für die Authentifizierung beim Speicher zu verwenden.
Syntax
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
Argumente
Bei den Eingabedateien mit den Zieldaten für die Abfrage stehen drei Optionen zur Auswahl. Gültige Werte sind:
'CSV': Eine beliebige Textdatei mit Zeilen- und Spaltentrennzeichen. Als Feldtrennzeichen kann ein beliebiges Zeichen verwendet werden. Für durch Tabstopp getrennte Werte wäre dies beispielsweise: FIELDTERMINATOR = tab.
PARQUET: Binärdatei im Parquet-Format.
DELTA: Eine Reihe von Parquet-Dateien, die im Delta Lake-Format (Vorschauversion) organisiert sind.
Werte mit Leerraum sind ungültig. Beispielsweise ist CSV kein gültiger Wert.
'unstructured_data_path'
Der unstructured_data_path, der einen Pfad zu den Daten festlegt, kann ein absoluter oder relativer Pfad sein.
- Der absolute Pfad im Format
\<prefix>://\<storage_account_path>/\<storage_path>ermöglicht Benutzern, die Dateien direkt zu lesen. - Der relative Pfad im Format
<storage_path>muss mit dem ParameterDATA_SOURCEverwendet werden und beschreibt das Dateimuster innerhalb des Speicherorts <Speicherkontopfad>, der inEXTERNAL DATA SOURCEdefiniert ist.
Im Folgenden finden Sie die relevanten <Speicherkonto-Pfadwerte> für die Verknüpfung mit Ihrer speziellen externen Datenquelle.
| Externe Datenquelle | Präfix | Speicherkontopfad |
|---|---|---|
| Azure Blob Storage (Azure-BLOB-Speicher) | http[s] | <storage_account>.blob.core.windows.net/path/file |
| Azure Blob Storage (Azure-BLOB-Speicher) | wasb[s] | <container>@<storage_account.blob.core.windows.net/path/file> |
| Azure Data Lake Store Gen1 | http[s] | < >storage_account.azuredatalakestore.net/webhdfs/v1 |
| Azure Data Lake Store Gen2 | http[s] | <storage_account>.dfs.core.windows.net/path/file |
| Azure Data Lake Store Gen2 | abfs[s] | <file_system>@<account_name>.dfs.core.windows.net/path/file |
'<storage_path>'
Dient zum Angeben eines Pfads innerhalb Ihres Speichers, der auf den zu lesenden Ordner oder auf die zu lesende Datei verweist. Verweist der Pfad auf einen Container oder Ordner, werden alle Dateien aus diesem Container oder Ordner gelesen. Dateien in Unterordnern werden nicht einbezogen.
Sie können Platzhalter verwenden, um mehrere Dateien oder Ordner anzusprechen. Dabei können mehrere nicht aufeinander folgende Platzhalter verwendet werden.
Im folgenden Beispiel werden alle mit population beginnenden CSV-Dateien aus allen mit /csv/population beginnenden Ordnern gelesen:
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
Wenn Sie den Pfad für unstrukturierte Daten (unstructured_data_path) als Ordner angeben, werden bei einer Abfrage des serverlosen SQL-Pools Dateien aus diesem Ordner abgerufen.
Durch Angabe von „/**“ am Ende des Pfads können Sie den serverlosen SQL-Pool anweisen, Ordner zu durchlaufen. Beispiel: https://sqlondemandstorage.blob.core.windows.net/csv/population/**
Hinweis
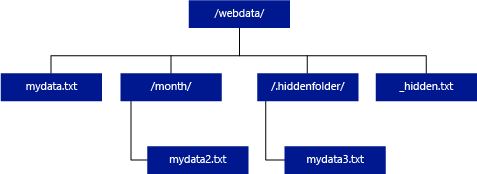
Im Gegensatz zu Hadoop und PolyBase werden vom serverlosen SQL-Pool nur dann Unterordner zurückgegeben, wenn Sie „/**“ am Ende des Pfads angeben. Wie bei Hadoop und PolyBase werden keine Dateien zurückgegeben, deren Dateiname mit einem Unterstrich (_) oder einem Punkt (.) beginnt.
Das folgende Beispiel zeigt: Bei Verwendung von „unstructured_data_path=https://mystorageaccount.dfs.core.windows.net/webdata/“ werden von einer Abfrage des serverlosen SQL-Pools Zeilen aus „mydata.txt“ zurückgegeben. „mydata2.txt“ und „mydata3.txt“ werden nicht zurückgegeben, da sie sich in einem Unterordner befinden.
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
Mit der WITH-Klausel können Sie Spalten angeben, die aus Dateien gelesen werden sollen.
Geben Sie bei CSV-Datendateien Spaltennamen und den jeweiligen Datentyp an, um alle Spalten zu lesen. Wenn Sie sich nur für eine Teilmenge der Spalten interessieren, verwenden Sie Ordinalzahlen, um die Spalten aus den Ursprungsdatendateien anhand der Ordinalzahl auszuwählen. Spalten werden anhand der Ordnungszahl gebunden. Bei Verwendung von „HEADER_ROW = TRUE“ erfolgt die Spaltenbindung nach Spaltenname und nicht nach Ordinalposition.
Tipp
Die WITH-Klausel kann für CSV-Dateien auch weggelassen werden. Datentypen werden automatisch aus Dateiinhalten abgeleitet. Mit dem Argument „HEADER_ROW“ können Sie angeben, dass eine Kopfzeile vorhanden ist. In diesem Fall werden Spaltennamen aus der Kopfzeile gelesen. Ausführliche Informationen finden Sie unter Automatische Schemaerkennung.
Geben Sie bei Parquet- oder Delta Lake-Dateien Spaltennamen an, die den Spaltennamen in den Ursprungsdatendateien entsprechen. Die Spalten werden nach Name gebunden, und die Groß-/Kleinschreibung ist relevant. Fehlt die WITH-Klausel, werden alle Spalten aus Parquet-Dateien zurückgegeben.
Wichtig
Bei Spaltennamen in Parquet- und Delta Lake-Dateien ist die Groß-/Kleinschreibung relevant. Wenn Sie einen Spaltennamen angeben, dessen Groß-/Kleinschreibung sich von der Schreibweise in den Dateien unterscheidet, werden für diese Spalte
NULL-Werte zurückgegeben.
column_name: Der Name für die Ausgabespalte. Wird der Name angegeben, überschreibt er den Spaltennamen in der Quelldatei und den Spaltennamen im JSON-Pfad, sofern vorhanden. Wird „json_path“ nicht angegeben, wird automatisch „$.column_name“ hinzugefügt. Überprüfen Sie das Argument „json_path“ auf das Verhalten.
column_type: Der Datentyp für die Ausgabespalte. Hier findet die implizite Datentypkonvertierung statt.
column_ordinal: Die Ordinalzahl der Spalte in den Quelldateien. Dieses Argument wird bei Parquet-Dateien ignoriert, da die Bindung auf dem Namen basiert. Im folgenden Beispiel wird nur bei Verwendung einer CSV-Datei eine zweite Spalte zurückgegeben:
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path: Der JSON-Pfadausdruck zur Spalte oder geschachtelten Eigenschaft. Standardmäßig ist der Pfadmodus lax.
Hinweis
Im Strict-Modus tritt bei der Abfrage ein Fehler auf, wenn der angegebene Pfad nicht vorhanden ist. Im Lax-Modus wird die Abfrage erfolgreich ausgeführt, und der JSON-Pfadausdruck wird zu NULL ausgewertet.
<Massenoptionen>
FIELDTERMINATOR ='field_terminator'
Spezifiziert das zu verwendende Feldabschlusszeichen. Das Standard-Feldabschlusszeichen ist ein Komma ( , ).
ROWTERMINATOR ='row_terminator'`
Dient zum Angeben des zu verwendenden Zeilenabschlusszeichens. Wenn kein Zeilenabschlusszeichen angegeben wird, wird eines der Standardabschlusszeichen verwendet. Standardabschlusszeichen für „PARSER_VERSION = '1.0'“ sind „\r\n“, „\n“ und „\r“. Standardabschlusszeichen für „PARSER_VERSION = '2.0'“ sind „\r\n“ und „\n“.
Hinweis
Wenn Sie PARSER_VERSION='1.0' verwenden und \n (Zeilenvorschub) als Zeilenabschlusszeichen angeben, wird dieses Zeichen automatisch mit dem Präfix \r (Wagenrücklauf) versehen, was zum Zeilenabschlusszeichen \r\n führt.
ESCAPE_CHAR = 'char'
Dient zum Angeben des Zeichens in der Datei, das als Escapezeichen für sich selbst und für alle Trennzeichenwerte in der Datei fungiert. Wenn auf das Escapezeichen ein Wert folgt, bei dem es sich nicht um das Escapezeichen selbst oder um einen der Trennzeichenwerte handelt, wird das Escapezeichen beim Lesen des Werts gelöscht.
Der Parameter ESCAPECHAR wird in jedem Fall angewendet, unabhängig davon, ob FIELDQUOTE aktiviert ist oder nicht. Er fungiert nicht als Escapezeichen für das Zitierzeichen. Das Anführungszeichen muss mit einem weiteren Anführungszeichen als Escapezeichen versehen werden. Anführungszeichen können nur in Spaltenwerten enthalten sein, wenn der Wert mit Anführungszeichen gekapselt ist.
FIRSTROW = 'first_row'
Gibt die Nummer der ersten zu ladenden Zeile an. Der Standardwert ist 1 und kennzeichnet die erste Zeile in der angegebenen Datendatei. Die Zeilennummern werden durch Zählen der Zeilenabschlusszeichen bestimmt. FIRSTROW ist einsbasiert.
FIELDQUOTE = 'field_quote'
Gibt ein Zeichen an, das als Anführungszeichen in der CSV-Datei verwendet wird. Ohne diese Angabe wird das Anführungszeichen (") verwendet.
DATA_COMPRESSION = 'Datenkomprimierungsmethode'
Gibt die Komprimierungsmethode an. Nur in PARSER_VERSION='1.0' unterstützt. Die folgende Komprimierungsmethode wird unterstützt:
- GZIP
PARSER_VERSION = 'parser_version'
Gibt die beim Lesen von Dateien zu verwendende Parserversion an. Zurzeit werden die CSV-Parserversionen 1.0 und 2.0 unterstützt:
- PARSER_VERSION = '1,0'
- PARSER_VERSION = '2,0'
Die CSV-Parserversion 1.0 ist die funktionsreiche Standardversion. Version 2.0 wurde mit dem Fokus auf Leistung erstellt und unterstützt nicht alle Optionen und Codierungen.
Einzelheiten zu CSV-Parserversion 1.0:
- Die folgenden Optionen werden nicht unterstützt: HEADER_ROW.
- Die Standardabschlusszeichen lauten \r\n, \n und \r.
- Wenn Sie \n (Zeilenvorschub) als Zeilenabschlusszeichen angeben, wird dieses Zeichen automatisch mit dem Präfix \r (Wagenrücklauf) versehen, was zum Zeilenabschlusszeichen \r\n führt.
Einzelheiten zu CSV-Parserversion 2.0:
- Nicht alle Datentypen werden unterstützt.
- Die maximal zulässige Zeichenlänge für Spalten beträgt 8.000.
- Die maximale Zeilengröße beträgt 8 MB.
- Die folgenden Optionen werden nicht unterstützt: DATA_COMPRESSION.
- Eine leere Zeichenfolge in Anführungszeichen ("") wird als leere Zeichenfolge interpretiert.
- Die Option DATEFORMAT SET wird nicht berücksichtigt.
- Unterstütztes Format für DATE-Datentyp: JJJJ-MM-TT
- Unterstütztes Format für TIME-Datentyp: HH:MM:SS[.Sekundenbruchteile]
- Unterstütztes Format für DATETIME2-Datentyp: YYYY-MM-DD HH:MM:SS[.Sekundenbruchteile]
- Die Standardabschlusszeichen lauten \r\n und \n.
HEADER_ROW = { TRUE | FALSE }
Gibt an, ob eine CSV-Datei eine Kopfzeile enthält. Standardwert: FALSE. Unterstützt in: PARSER_VERSION='2.0'. Bei „TRUE“ werden die Spaltennamen aus der ersten Zeile gelesen (gemäß FIRSTROW-Argument). Bei „TRUE“ und Schemaangabe mit „WITH“ wird für die Bindung von Spaltennamen der Spaltenname und nicht die Ordinalposition herangezogen.
DATAFILETYPE = { 'char' | 'widechar' }
Gibt die Codierung an: char wird für UTF8 verwendet, widechar für UTF16-Dateien.
CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' }
Gibt die Codepage für die in der Datendatei enthaltenen Daten an. Der Standardwert ist 65001 (UTF-8-Codierung). Weitere Details zu dieser Option finden Sie hier.
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}'
Mit dieser Option wird die Überprüfung von Dateiänderungen während der Abfrageausführung deaktiviert, und es werden die Dateien gelesen, die während der Abfrageausführung aktualisiert werden. Dies ist eine nützliche Option, wenn Sie Dateien vom Typ „Nur anfügen“ lesen müssen, in denen während der Abfrageausführung Daten hinzugefügt werden. In erweiterbaren Dateien wird der vorhandene Inhalt nicht aktualisiert, und es werden nur neue Zeilen hinzugefügt. Dadurch wird die Wahrscheinlichkeit falscher Ergebnisse im Vergleich zu den aktualisierbaren Dateien minimiert. Mit dieser Option können Sie möglicherweise oft angehängte Dateien lesen, ohne Fehler behandeln zu müssen. Weitere Informationen finden Sie im Abschnitt Abfragen von anfügbaren CSV-Dateien.
Reject-Optionen
Hinweis
Das Feature für abgelehnte Zeilen befindet sich in der Public Preview. Beachten Sie, dass das Feature für abgelehnte Zeilen nur für Textdateien mit Trennzeichen und PARSER_VERSION 1.0 funktioniert.
Sie können Reject-Parameter angeben, um zu bestimmen, wie der Dienst fehlerhafte Datensätze behandelt, die aus der externen Datenquelle abgerufen werden. Ein Datensatz gilt als fehlerhaft, wenn die tatsächlichen Datentypen nicht den Spaltendefinitionen der externen Tabelle entsprechen.
Wenn Sie die Reject-Optionen nicht angeben oder ändern, verwendet der Dienst Standardwerte. Der Dienst verwendet die Reject-Optionen, um die Anzahl der Zeilen zu bestimmen, die abgelehnt werden können, bevor bei der eigentlichen Abfrage ein Fehler auftritt. Die Abfrage gibt (Teil-) Ergebnisse zurück, bis der Reject-Schwellenwert überschritten wird. Daraufhin schlägt es mit der entsprechenden Fehlermeldung fehl.
MAXERRORS = reject_value
Gibt die Anzahl der Zeilen an, die zurückgewiesen werden dürfen, bevor die Abfrage fehlschlägt. MAXERRORS muss eine ganze Zahl zwischen 0 und 2.147.483.647 sein.
ERRORFILE_DATA_SOURCE = Datenquelle
Gibt die Datenquelle an, in die abgelehnte Zeilen und die entsprechende Fehlerdatei geschrieben werden sollen.
ERRORFILE_LOCATION = Verzeichnis-Ort
Gibt das Verzeichnis in DATA_SOURCE oder ERROR_FILE_DATASOURCE an, sofern angegeben, in das die abgelehnten Zeilen und die entsprechende Fehlerdatei geschrieben werden sollen. Falls der angegebene Pfad nicht existiert, erstellt der Service ihn in Ihrem Auftrag. Es wird ein untergeordnetes Verzeichnis mit dem Namen „rejectedrows“ erstellt. Mit dem „ “-Zeichen wird sichergestellt, dass das Verzeichnis für andere Datenverarbeitungsvorgänge übergangen wird, es sei denn, es ist explizit im LOCATION-Parameter angegeben. In diesem Verzeichnis befindet sich ein Ordner, der ausgehend von der Zeit der Lastübermittlung im Format „JahrMonatTag_StundeMinuteSekunde_Anweisungs-ID“ erstellt wurde (z. B. 20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891). Sie können die Anweisungs-ID verwenden, um den Ordner mit der Abfrage zu verknüpfen, die ihn erzeugt hat. In diesen Ordner werden zwei Dateien geschrieben: die Datei „error.json“ und die Datendatei.
Die Datei error.json enthält ein JSON-Array mit den aufgetretenen Fehlern im Zusammenhang mit abgelehnten Zeilen. Jedes Element, das einen Fehler darstellt, enthält die folgenden Attribute:
| Attribut | BESCHREIBUNG |
|---|---|
| Fehler | Der Grund, warum die Zeile abgelehnt wird. |
| Zeile | Die Ordinalzahl der abgelehnten Zeile in der Datei. |
| Spalte | Die Ordinalzahl der abgelehnten Spalte. |
| Wert | Abgelehnter Spaltenwert. Wenn der Wert größer als 100 Zeichen ist, werden nur die ersten 100 Zeichen angezeigt. |
| Datei | Der Pfad zur Datei, zu der die Zeile gehört. |
Schnelle Analyse von Text mit Trennzeichen
Es gibt zwei Versionen von Textparsern mit Trennzeichen, die Sie verwenden können. Die CSV-Parserversion 1.0 ist die Standardversion und bietet zahlreiche Features. Die Parserversion 2.0 ist dagegen auf hohe Leistung ausgelegt. Die höhere Leistung der Parserversion 2.0 wird durch erweiterte Analysetechniken und Multithreading erreicht. Der Geschwindigkeitsunterschied nimmt zu, je größer die Datei ist.
Automatische Schemaerkennung
Sie können mühelos CSV- und Parquet-Dateien abfragen, ohne das Schema zu kennen oder anzugeben, indem Sie die WITH-Klausel weglassen. Spaltennamen und Datentypen werden aus Dateien abgeleitet.
Parquet-Dateien enthalten Spaltenmetadaten, die gelesen werden. Typzuordnungen finden Sie unter Typzuordnung für Parquet. Beispiele finden Sie unter Lesen von Parquet-Dateien ohne Angabe eines Schemas.
Bei CSV-Dateien können Spaltennamen aus der Kopfzeile gelesen werden. Mithilfe des Arguments „HEADER_ROW“ können Sie angeben, ob eine Kopfzeile vorhanden ist. Bei „HEADER_ROW = FALSE“ werden generische Spaltennamen verwendet: C1, C2, ... Cn, wobei „n“ die Anzahl von Spalten in der Datei ist. Datentypen werden aus den ersten 100 Datenzeilen abgeleitet. Beispiele finden Sie unter Lesen von CSV-Dateien ohne Angabe eines Schemas.
Beachten Sie, dass, wenn Sie mehrere Dateien gleichzeitig lesen, das Schema aus der ersten Datei abgeleitet wird, die der Dienst aus dem Speicher abruft. Dies kann bedeuten, dass einige der erwarteten Spalten weggelassen werden, weil die vom Dienst zum Definieren des Schemas verwendete Datei diese Spalten nicht enthielt. Verwenden Sie die OPENROWSET WITH-Klausel in diesem Fall.
Wichtig
Es kann vorkommen, dass der passende Datentyp aufgrund fehlender Informationen nicht abgeleitet werden kann und stattdessen ein größerer Datentyp verwendet wird. Dies führt zu Mehraufwand und ist insbesondere für Zeichenspalten relevant, die als „varchar(8000)“ abgeleitet werden. Um eine optimale Leistung zu erzielen, überprüfen Sie die abgeleiteten Datentypen, und verwenden Sie passende Datentypen.
Typzuordnung für Parquet
Parquet- und Delta Lake-Dateien enthalten Typbeschreibungen für die einzelnen Spalten. In der folgenden Tabelle wird beschrieben, wie Parquet-Typen den nativen SQL-Typen zugeordnet werden.
| Parquet-Typ | Logischer Parquet-Typ (Anmerkung) | SQL-Datentyp |
|---|---|---|
| BOOLEAN | bit | |
| BINARY/BYTE_ARRAY | varbinary | |
| Double | float | |
| GLEITKOMMAZAHL | echt | |
| INT32 | INT | |
| INT64 | BIGINT | |
| INT96 | datetime2 | |
| FIXED_LEN_BYTE_ARRAY | binär | |
| BINARY | UTF8 | varchar *(UTF8-Sortierung) |
| BINARY | STRING | varchar *(UTF8-Sortierung) |
| BINARY | ENUM | varchar *(UTF8-Sortierung) |
| FIXED_LEN_BYTE_ARRAY | UUID | UNIQUEIDENTIFIER |
| BINARY | DECIMAL | Dezimal |
| BINARY | JSON | varchar(8000) *(UTF8-Sortierung) |
| BINARY | BSON | Nicht unterstützt |
| FIXED_LEN_BYTE_ARRAY | DECIMAL | Dezimal |
| Byte-Array | Intervall | Nicht unterstützt |
| INT32 | INT(8; true) | SMALLINT |
| INT32 | INT(16; wahr) | SMALLINT |
| INT32 | INT(32; wahr) | INT |
| INT32 | INT(8, false) | TINYINT |
| INT32 | INT(16, false) | INT |
| INT32 | INT(32, false) | BIGINT |
| INT32 | DATUM | Datum |
| INT32 | DECIMAL | Dezimal |
| INT32 | ZEIT (Millisekunden) | Zeit |
| INT64 | INT(64; wahr) | BIGINT |
| INT64 | INT(64, false) | decimal(20,0) |
| INT64 | DECIMAL | Dezimal |
| INT64 | TIME (MICROS) | Zeit |
| INT64 | ZEIT (ns) | Nicht unterstützt |
| INT64 | TIMESTAMP (normalisiert in UTC) (MILLIS/MICROS) | datetime2 |
| INT64 | TIMESTAMP (nicht normalisiert in UTC) (MILLIS/MICROS) | bigint: Stellen Sie sicher, dass Sie den bigint-Wert explizit um den Offset der Zeitzone anpassen, bevor Sie ihn in einen datetime-Wert konvertieren. |
| INT64 | TIMESTAMP (NANOS) | Nicht unterstützt |
| Komplexer Typ | LISTE | varchar(8000), serialisiert in JSON |
| Komplexer Typ | MAP | varchar(8000), serialisiert in JSON |
Beispiele
Lesen von CSV-Dateien ohne Angabe eines Schemas
Im folgenden Beispiel wird eine CSV-Datei mit einer Kopfzeile gelesen, ohne Spaltennamen und Datentypen anzugeben:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
Im folgenden Beispiel wird eine CSV-Datei ohne Kopfzeile gelesen, ohne Spaltennamen und Datentypen anzugeben:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
Lesen von Parquet-Dateien ohne Angabe eines Schemas
Im folgenden Beispiel werden alle Spalten der ersten Zeile aus dem Zensus-Dataset im Parquet-Format zurückgegeben, ohne dass die Spaltennamen und Datentypen angegeben werden:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
Lesen von Delta Lake-Dateien ohne Angabe eines Schemas
Im folgenden Beispiel werden alle Spalten der ersten Zeile aus dem Erhebungsdataset im Delta Lake-Format zurückgegeben, ohne dass die Spaltennamen und Datentypen angegeben werden:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
Lesen bestimmter Spalten aus einer CSV-Datei
Im folgenden Beispiel werden nur zwei Spalten mit den Ordinalzahlen 1 und 4 aus den Dateien „population*.csv“ zurückgegeben. Da in den Dateien keine Kopfzeile vorhanden ist, beginnt der Lesevorgang in der ersten Zeile:
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
Lesen bestimmter Spalten aus einer Parquet-Datei
Im folgenden Beispiel werden nur zwei Spalten der ersten Zeile aus dem Zensus-Dataset im Parquet-Format zurückgegeben:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
Angeben von Spalten mithilfe von JSON-Pfaden
Im folgenden Beispiel wird gezeigt, wie Sie JSON-Pfadausdrücke in der WITH-Klausel verwenden. Darüber hinaus wird der Unterschied zwischen den PATH-Modi „Strict“ und „Lax“ veranschaulicht:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
Angeben mehrerer Dateien/Ordner im BULK-Pfad
Das folgende Beispiel zeigt, wie Sie mehrere Datei-/Ordnerpfade im BULK-Parameter verwenden können:
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
Nächste Schritte
Weitere Beispiele finden Sie im Schnellstart zum Abfragen von Daten im Speicher. Dort erfahren Sie, wie Sie OPENROWSET zum Lesen von CSV-, PARQUET-, DELTA LAKE- und JSON-Dateiformaten verwenden. Machen Sie sich mit den bewährten Methoden vertraut, um eine optimale Leistung zu erzielen. Sie erfahren außerdem, wie Sie die Ergebnisse Ihrer Abfrage mithilfe von CETAS in Azure Storage speichern.