Microsoft Entra Connect Sync: Grundlegendes zur Architektur
In diesem Thema wird die grundlegende Architektur für Microsoft Entra Connect Sync behandelt. Wenn Sie mit früheren Identitätssynchronisierungstechnologien vertraut sind, sind Ihnen auch die Inhalte dieses Themas vertraut. Dieses Thema ist für Sie auch geeignet, falls Sie sich mit der Synchronisierung noch nicht auskennen. Es ist jedoch nicht erforderlich, alle Details dieses Themas zu kennen, um erfolgreich Anpassungen an Microsoft Entra Connect Sync (in diesem Thema als „Synchronisierungsmodul“ bezeichnet) vornehmen zu können.
Aufbau
Das Synchronisierungsmodul erstellt eine integrierte Ansicht der Objekte, die in mehreren verbundenen Datenquellen gespeichert sind, und verwaltet die Identitätsinformationen in diesen Datenquellen. Diese integrierte Ansicht wird anhand der Identitätsinformationen ermittelt, die aus verbundenen Datenquellen abgerufen werden, sowie mit einer Gruppe von Regeln, mit denen die Verarbeitung dieser Informationen bestimmt wird.
Verbundene Datenquellen und Connectors
Das Synchronisierungsmodul verarbeitet Identitätsinformationen aus verschiedenen Datenrepositorys, z.B. Active Directory oder einer SQL Server-Datenbank. Jedes Datenrepository, das seine Daten in einem datenbankähnlichen Format organisiert und standardmäßige Methoden für den Datenzugriff bereitstellt, ist ein potenzieller Datenquellenkandidat für das Synchronisierungsmodul. Die Datenrepositorys, die vom Synchronisierungsmodul synchronisiert werden, werden als verbundene Datenquellen oder verbundene Verzeichnisse (Connected Directories, CD) bezeichnet.
Das Synchronisierungsmodul kapselt die Interaktion mit einer verbundenen Datenquelle in einem Modul, das als Connectorbezeichnet wird. Jede Art von verbundener Datenquelle verfügt über einen bestimmten Connector. Der Connector übersetzt einen erforderlichen Vorgang in das Format, das von der verbundenen Datenquelle verstanden wird.
Connectors führen API-Aufrufe durch, um mit einer verbundenen Datenquelle Identitätsinformationen auszutauschen (Lesen und Schreiben). Es ist auch möglich, einen benutzerdefinierten Connector mit dem Extensible Connectivity-Framework hinzuzufügen. In der folgenden Abbildung ist dargestellt, wie ein Connector eine verbundene Datenquelle mit dem Synchronisierungsmodul verbindet.
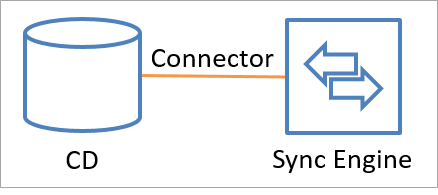
Daten können in beide Richtungen fließen, aber nicht in beide Richtungen gleichzeitig. Anders ausgedrückt: Ein Connector kann so konfiguriert werden, dass der Datenfluss von der verbundenen Datenquelle zum Synchronisierungsmodul oder vom Synchronisierungsmodul zur verbundenen Datenquelle zugelassen wird. Für ein Objekt und Attribut kann aber jeweils nur einer dieser Vorgänge durchgeführt werden. Die Richtung kann sich für unterschiedliche Objekte und unterschiedliche Attribute unterscheiden.
Zum Konfigurieren eines Connectors geben Sie die Objekttypen an, die Sie synchronisieren möchten. Mit dem Angeben der Objekttypen wird der Bereich der Objekte definiert, die in den Synchronisierungsvorgang einbezogen sind. Der nächste Schritt ist das Auswählen der Attribute, die synchronisiert werden sollen. Dies wird als Aufnahmeliste für Attribute bezeichnet. Diese Einstellungen können als Reaktion auf Änderungen Ihrer Geschäftsregeln jederzeit geändert werden. Wenn Sie den Microsoft Entra Connect-Installations-Assistenten verwenden, werden diese Einstellungen für Sie konfiguriert.
Um Objekte auf eine verbundene Datenquelle zu exportieren, muss die Aufnahmeliste für Attribute mindestens die Attribute enthalten, die zum Erstellen eines bestimmten Objekttyps in einer verbundenen Datenquelle erforderlich sind. Das Attribut sAMAccountName muss beispielsweise in die Aufnahmeliste für Attribute eingefügt werden, um ein Benutzerobjekt nach Active Directory zu exportieren. Der Grund ist, dass für alle Benutzerobjekte in Active Directory das Attribut sAMAccountName definiert sein muss. Diese Konfiguration wird ebenfalls vom Installations-Assistenten für Sie vorgenommen.
Wenn die verbundene Datenquelle zum Organisieren von Objekten strukturelle Komponenten nutzt, z. B. Partitionen oder Container, können Sie die Bereiche in der verbundenen Datenquelle begrenzen, die für eine bestimmte Lösung verwendet werden.
Interne Struktur des Synchronisierungsmodul-Namespace
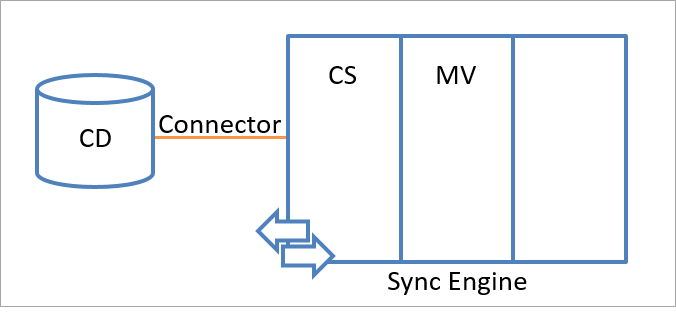
Der gesamte Synchronisierungsmodul-Namespace besteht aus zwei Namespaces, in denen die Identitätsinformationen gespeichert werden. Die beiden Namespaces lauten:
- Connectorbereich (Connector Space, CS)
- Metaverse (MV)
Der Connectorbereich ist ein Stagingbereich, der Darstellungen der angegebenen Objekte aus einer verbundenen Datenquelle und die Attribute enthält, die in der Aufnahmeliste für Attribute angegeben sind. Das Synchronisierungsmodul verwendet den Connectorbereich, um zu bestimmen, was sich in der verbundenen Datenquelle geändert hat, und um eingehende Änderungen bereitzustellen. Außerdem verwendet das Synchronisierungsmodul den Connectorbereich zum Bereitstellen ausgehender Änderungen für den Export in die verbundene Datenquelle. Das Synchronisierungsmodul verwaltet einen speziellen Connectorbereich als Stagingbereich für jeden Connector.
Durch den Einsatz eines Stagingbereichs bleibt das Synchronisierungsmodul von den verbundenen Datenquellen unabhängig und ist von deren Verfügbarkeits- und Zugänglichkeitsaspekten nicht betroffen. Sie können die Identitätsinformationen also jederzeit verarbeiten, indem Sie die Daten im Stagingbereich verwenden. Das Synchronisierungsmodul kann nur die Änderungen anfordern, die seit dem Ende der letzten Kommunikationssitzung in der verbundenen Datenquelle vorgenommen wurden, bzw. nur die Änderungen von Identitätsinformationen per Pushvorgang übertragen, die von der verbundenen Datenquelle noch nicht empfangen wurden. So wird der Netzwerkdatenverkehr zwischen dem Synchronisierungsmodul und der verbundenen Datenquelle reduziert.
Darüber hinaus werden im Synchronisierungsmodul Statusinformationen zu allen Objekten gespeichert, die es im Connectorbereich bereitstellt. Wenn neue Daten empfangen werden, wertet das Synchronisierungsmodul immer aus, ob die Daten bereits synchronisiert wurden.
Der Metaverse ist ein Speicherbereich, der die aggregierten Identitätsinformationen mehrerer verbundener Datenquellen enthält und eine globale integrierte Ansicht aller kombinierten Objekte bereitstellt. Metaverseobjekte werden basierend auf Identitätsinformationen, die aus den verbundenen Datenquellen abgerufen werden, und einer Gruppe von Regeln erstellt, mit denen Sie den Synchronisierungsprozess anpassen können.
Die folgende Abbildung zeigt den Connectorbereich-Namespace und den Metaverse-Namespace im Synchronisierungsmodul.
Identitätsobjekte des Synchronisierungsmoduls
Die Objekte im Synchronisierungsmodul sind entweder Darstellungen von Objekten in der verbundenen Datenquelle oder der integrierten Ansicht, über die das Synchronisierungsmodul für diese Objekte verfügt. Jedes Objekt des Synchronisierungsmoduls benötigt einen global eindeutigen Bezeichner (GUID). Mit GUIDs wird die Datenintegrität ermöglicht, und es werden Beziehungen zwischen Objekten ausgedrückt.
Objekte des Connectorbereichs
Wenn das Synchronisierungsmodul mit einer verbundenen Datenquelle kommuniziert, liest es die Identitätsinformationen in der verbundenen Datenquelle und verwendet diese Informationen, um im Connectorbereich eine Darstellung des Identitätsobjekts zu erstellen. Sie können diese Objekte nicht einzeln erstellen oder löschen. Allerdings können Sie alle Objekte in einem Connectorbereich manuell löschen.
Alle Objekte im Connectorbereich verfügen über zwei Attribute:
- Einen global eindeutigen Bezeichner (GUID)
- Einen Distinguished Name (DN)
Objekte im Connectorbereich können auch ein Ankerattribut enthalten, wenn die verbundene Datenquelle einem Objekt ein eindeutiges Attribut zuweist. Der Ankerattribut wird verwendet, um ein Objekt in der verbundenen Datenquelle eindeutig zu identifizieren. Vom Synchronisierungsmodul wird der Anker zum Ermitteln der entsprechenden Darstellung dieses Objekts in der verbundenen Datenquelle verwendet. Das Synchronisierungsmodul geht davon aus, dass sich der Anker eines Objekts während der Lebensdauer des Objekts nicht ändert.
Für viele Connectors wird ein eindeutiger Bezeichner verwendet, um für jedes Objekt beim Import automatisch einen Anker zu generieren. Der Active Directory Connector nutzt als Anker das Attribut objectGUID . Für verbundene Datenquellen, die keinen klar definierten eindeutigen Bezeichner bereitstellen, können Sie die Generierung eines Ankers bei der Connectorkonfiguration angeben.
In diesem Fall wird der Anker aus einem oder mehreren eindeutigen Attributen eines Objekttyps erstellt, die sich nicht ändern. Hiermit wird das Objekt im Connectorbereich eindeutig identifiziert (z. B. eine Mitarbeiternummer oder Benutzer-ID).
Ein Connectorbereichsobjekt kann Folgendes sein:
- Ein Stagingobjekt
- Ein Platzhalter
Stagingobjekte
Ein Stagingobjekt stellt eine Instanz der angegebenen Objekttypen von der verbundenen Datenquelle dar. Zusätzlich zur GUID und dem Distinguished Name verfügt ein Stagingobjekt immer über einen Wert, der den Objekttyp angibt.
Importierte Stagingobjekte weisen immer einen Wert für das Ankerattribut auf. Stagingobjekte, die vom Synchronisierungsmodul neu bereitgestellt wurden und sich in der verbundenen Datenquelle in der Phase der Erstellung befinden, haben keinen Wert für das Ankerattribut.
Außerdem verfügen Stagingobjekte über aktuelle Werte von Geschäftsattributen sowie über Betriebsinformationen, die das Synchronisierungsmodul zum Durchführen des Synchronisierungsprozesses benötigt. Die Betriebsinformationen enthalten Flags, mit denen der Typ der Updates angegeben wird, die im Stagingobjekt bereitgestellt werden. Wenn ein Stagingobjekt von der verbundenen Datenquelle neue Identitätsinformationen erhalten hat, die noch nicht verarbeitet wurden, wird das Objekt mit Import steht ausgekennzeichnet. Wenn ein Stagingobjekt über neue Identitätsinformationen verfügt, die noch nicht in die verbundene Datenquelle exportiert wurden, wird es mit Export steht ausgekennzeichnet.
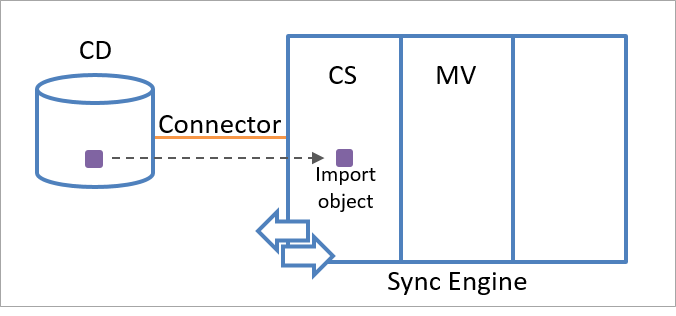
Bei einem Stagingobjekt kann es sich um ein Importobjekt oder ein Exportobjekt handeln. Das Synchronisierungsmodul erstellt ein Importobjekt, indem es Objektinformationen von der verbundenen Datenquelle verwendet. Wenn das Synchronisierungsmodul Informationen zum Vorhandensein eines neuen Objekts empfängt, das mit einem der im Connector ausgewählten Objekttypen übereinstimmt, wird im Connectorbereich ein Importobjekt als Darstellung des Objekts in der verbundenen Datenquelle erstellt.
Die folgende Abbildung zeigt ein Importobjekt, mit dem ein Objekt in der verbundenen Datenquelle dargestellt wird.
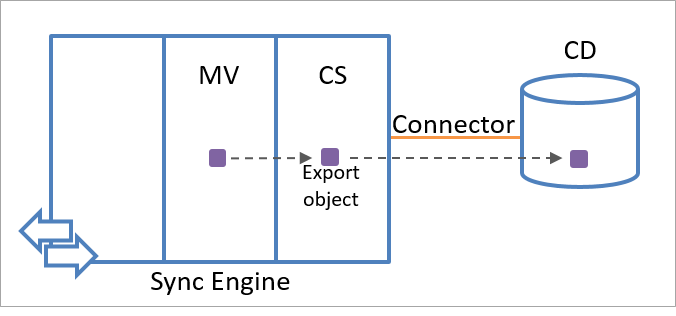
Das Synchronisierungsmodul erstellt ein Exportobjekt anhand von Objektinformationen im Metaverse. Exportobjekte werden während der nächsten Kommunikationssitzung in die verbundene Datenquelle exportiert. Aus Sicht des Synchronisierungsmoduls sind in der verbundenen Datenquelle noch keine Exportobjekte vorhanden. Aus diesem Grund ist das Ankerattribut für ein Exportobjekt nicht verfügbar. Nach dem Erhalt des Objekts vom Synchronisierungsmodul erstellt die verbundene Datenquelle einen eindeutigen Wert für das Ankerattribut des Objekts.
Die folgende Abbildung zeigt, wie Sie ein Exportobjekt erstellen, indem Sie Identitätsinformationen im Metaverse verwenden.
Das Synchronisierungsmodul bestätigt den Export des Objekts, indem das Objekt erneut aus der verbundenen Datenquelle importiert wird. Exportobjekte werden zu Importobjekten, wenn das Synchronisierungsmodul diese im Rahmen des nächsten Importvorgangs von der verbundenen Datenquelle empfängt.
Platzhalter
Das Synchronisierungsmodul verwendet zum Speichern von Objekten einen flachen Namespace. Für einige verbundene Datenquellen, z. B. Active Directory, wird aber ein hierarchischer Namespace verwendet. Beim Transformieren von Informationen aus einem hierarchischen Namespace in einen flachen Namespace nutzt das Synchronisierungsmodul Platzhalter, um die Hierarchie zu erhalten.
Jeder Platzhalter stellt eine Komponente (z.B. eine Organisationseinheit) des hierarchischen Namens eines Objekts dar, die nicht in das Synchronisierungsmodul importiert wurde, aber zum Erstellen des hierarchischen Namens erforderlich ist. Hiermit werden Lücken gefüllt, die aufgrund von Verweisen in der verbundenen Datenquelle auf Objekte entstehen, bei denen es sich nicht um Stagingobjekte im Connectorbereich handelt.
Das Synchronisierungsmodul verwendet Platzhalter auch, um referenzierte Objekte zu speichern, die noch nicht importiert wurden. Wenn die Synchronisierung beispielsweise so konfiguriert ist, dass sie das manager-Attribut für das Objekt Abbie Spencer enthält, und der empfangene Wert für ein noch nicht importiertes Objekt steht, z.B. CN=Lee Sperry,CN=Users,DC=fabrikam,DC=com, gilt Folgendes: Die Managerinformationen werden als Platzhalter im Connectorbereich gespeichert. Wenn das manager-Objekt später importiert wird, wird das Platzhalterobjekt von dem Stagingobjekt überschrieben, das den Manager darstellt.
Metaverseobjekte
Ein Metaverseobjekt enthält die aggregierte Ansicht, über die das Synchronisierungsmodul in Bezug auf die Stagingobjekte im Connectorbereich verfügt. Das Synchronisierungsmodul erstellt Metaverseobjekte anhand der Informationen in den Importobjekten. Mehrere Connectorbereichsobjekte können mit einem einzelnen Metaverseobjekt verknüpft werden, aber ein Connectorbereichsobjekt kann nicht mit mehr als einem Metaverseobjekt verknüpft werden.
Metaverseobjekte können nicht manuell erstellt oder gelöscht werden. Vom Synchronisierungsmodul werden Metaverseobjekte, die nicht über einen Link zu einem Connectorbereichsobjekt im Connectorbereich verfügen, automatisch gelöscht.
Um Objekte in einer verbundenen Datenquelle einem entsprechenden Objekttyp im Metaverse zuzuordnen, stellt das Synchronisierungsmodul ein erweiterbares Schema mit einem vordefinierten Satz von Objekttypen und zugeordneten Attributen bereit. Sie können für Metaverseobjekte neue Objekttypen und Attribute erstellen. Attribute können einwertig oder mehrwertig sein, und die Attributtypen können Zeichenfolgen, Verweise, Zahlen und boolesche Werte sein.
Beziehungen zwischen Stagingobjekten und Metaverseobjekten
Innerhalb des Synchronisierungsmodul-Namespace wird der Datenfluss durch die Linkbeziehung zwischen Stagingobjekten und Metaverseobjekten ermöglicht. Ein Stagingobjekt, das mit einem Metaverseobjekt verknüpft ist, wird als verknüpftes Objekt (oder Connectorobjekt) bezeichnet. Ein Stagingobjekt, das nicht mit einem Metaverseobjekt verknüpft ist, wird als getrenntes Objekt (oder Disconnectorobjekt) bezeichnet. Die Ausdrücke „verknüpft“ und „getrennt“ werden bevorzugt verwendet, um eine Verwechslung mit den Connectors zu vermeiden, die zum Importieren und Exportieren von Daten aus einem verbundenen Verzeichnis bestimmt sind.
Keine Verknüpfung von Platzhaltern und Metaverseobjekt
Ein verknüpftes Objekt besteht aus einem Stagingobjekt und dessen Verknüpfungsbeziehung zu einem einzelnen Metaverseobjekt. Verknüpfte Objekte werden zum Synchronisieren von Attributwerten zwischen einem Connectorbereichsobjekt und einem Metaverseobjekt verwendet.
Wenn ein Stagingobjekt während der Synchronisierung zu einem verknüpften Objekt wird, können Attribute zwischen dem Stagingobjekt und dem Metaverseobjekt fließen. Der Attributfluss ist bidirektional und wird mit Importattributregeln und Exportattributregeln konfiguriert.
Ein einzelnes Connectorbereichsobjekt kann nur mit einem einzelnen Metaverseobjekt verknüpft sein. Aber jedes Metaverseobjekt kann mit mehreren Connectorbereichsobjekten in demselben oder in verschiedenen Connectorbereichen verknüpft werden. Dies ist in der folgenden Abbildung dargestellt.
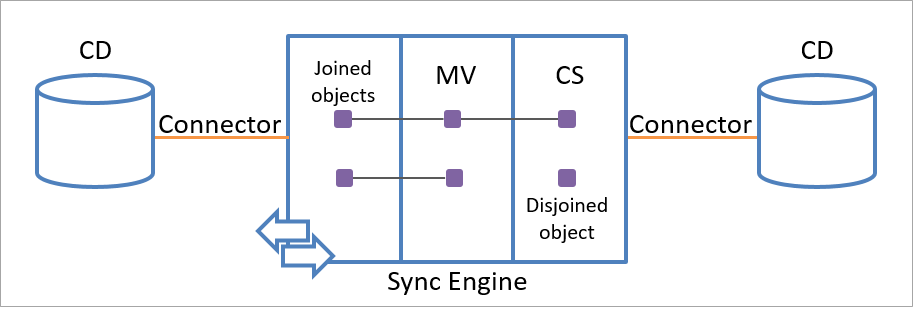
Die Verknüpfungsbeziehung zwischen dem Stagingobjekt und einem Metaverseobjekt ist dauerhafter Art und kann nur mit Regeln entfernt werden, die Sie angeben.
Ein getrenntes Objekt ist ein Stagingobjekt, das nicht mit einem Metaverseobjekt verknüpft ist. Die Attributwerte eines getrennten Objekts werden im Metaverse nicht weiter verarbeitet. Die Attributwerte des entsprechenden Objekts in der verbundenen Datenquelle werden vom Synchronisierungsmodul nicht aktualisiert.
Indem Sie getrennte Objekte verwenden, können Sie Identitätsinformationen im Synchronisierungsmodul speichern und zu einem späteren Zeitpunkt verarbeiten. Das Beibehalten eines Stagingobjekts als getrenntes Objekt im Connectorbereich hat viele Vorteile. Da das System die erforderlichen Informationen zu diesem Objekt schon bereitgestellt hat, ist es nicht erforderlich, während des nächsten Importvorgangs von der verbundenen Datenquelle erneut eine Darstellung dieses Objekts zu erstellen. So verfügt das Synchronisierungsmodul immer über eine vollständige Momentaufnahme der verbundenen Datenquelle. Dies gilt auch, wenn gerade keine Verbindung mit der verbundenen Datenquelle besteht. Getrennte Objekte können in verknüpfte Objekte konvertiert werden (und umgekehrt). Dies hängt von den Regeln ab, die Sie angeben.
Ein Importobjekt wird als getrenntes Objekt erstellt. Ein Exportobjekt muss ein verknüpftes Objekt sein. Die Systemlogik erzwingt diese Regel und löscht alle Exportobjekte, bei denen es sich nicht um ein verknüpftes Objekt handelt.
Identitätsverwaltungsprozess des Synchronisierungsmoduls
Der Identitätsverwaltungsprozess steuert, wie Identitätsinformationen zwischen unterschiedlichen verbundenen Datenquellen aktualisiert werden. Die Identitätsverwaltung umfasst drei Vorgänge:
- Importieren
- Synchronization
- Exportieren
Während des Importvorgangs wertet das Synchronisierungsmodul die eingehenden Identitätsinformationen aus einer verbundenen Datenquelle aus. Wenn Änderungen erkannt werden, werden entweder neue Stagingobjekte erstellt oder vorhandene Stagingobjekte im Connectorbereich für die Synchronisierung aktualisiert.
Während des Synchronisierungsprozesses aktualisiert das Synchronisierungsmodul den Metaverse, um Änderungen widerzuspiegeln, zu denen es im Connectorbereich gekommen ist. Außerdem wird der Connectorbereich aktualisiert, um die Änderungen widerzuspiegeln, die im Metaverse aufgetreten sind.
Während des Exportvorgangs sendet das Synchronisierungsmodul per Pushvorgang die Änderungen, die in Stagingobjekten bereitgestellt werden und mit „Export steht aus“ gekennzeichnet sind.
Die folgende Abbildung zeigt, wo die einzelnen Prozesse stattfinden, wenn Identitätsinformationen von einer verbundenen Datenquelle zu einer anderen fließen.

Importvorgang
Während des Importvorgangs wertet das Synchronisierungsmodul Aktualisierungen der Identitätsinformationen aus. Das Synchronisierungsmodul vergleicht die von der verbundenen Datenquelle empfangenen Identitätsinformationen mit den Identitätsinformationen zu einem Stagingobjekt und ermittelt, ob für das Stagingobjekt Updates erforderlich sind. Falls das Stagingobjekt mit neuen Daten aktualisiert werden muss, wird das Stagingobjekt mit der Kennzeichnung „Import steht aus“ versehen.
Indem Stagingobjekte vor der Synchronisierung im Connectorbereich bereitgestellt werden, kann das Synchronisierungsmodul nur die Identitätsinformationen verarbeiten, die sich geändert haben. Dieser Prozess hat folgende Vorteile:
- Effiziente Synchronisierung: Die Datenmenge, die während der Synchronisierung verarbeitet wird, wird verringert.
- Effiziente Neusynchronisierung: Sie können ändern, wie das Synchronisierungsmodul die Identitätsinformationen verarbeitet, ohne für das Synchronisierungsmodul erneut eine Verbindung mit der Datenquelle herzustellen.
- Vorschau für Synchronisierung: Sie können für die Synchronisierung eine Vorschau anzeigen, um zu bestätigen, dass Ihre Annahmen zum Prozess der Identitätsverwaltung richtig sind.
Für alle im Connector angegebenen Objekte versucht das Synchronisierungsmodul zuerst, eine Darstellung des Objekts im Connectorbereich des Connectors zu ermitteln. Das Synchronisierungsmodul untersucht alle Stagingobjekte im Connectorbereich und versucht, ein entsprechendes Stagingobjekt mit einem übereinstimmenden Ankerattribut zu finden. Falls kein vorhandenes Stagingobjekt über ein passendes Ankerattribut verfügt, sucht das Synchronisierungsmodul nach einem entsprechenden Stagingobjekt mit dem gleichen Distinguished Name.
Wenn das Synchronisierungsmodul ein Stagingobjekt findet, bei dem anstelle des Ankers der Distinguished Name übereinstimmt, tritt das folgende spezielle Verhalten auf:
- Wenn das im Connectorbereich ermittelte Objekt keinen Anker aufweist, entfernt das Synchronisierungsmodul dieses Objekt aus dem Connectorbereich und versieht das Metaverseobjekt, mit dem es verknüpft ist, mit der Kennzeichnung Bereitstellung beim nächsten Synchronisierungslauf erneut versuchen. Anschließend wird das neue Importobjekt erstellt.
- Wenn das im Connectorbereich befindliche Objekt über einen Anker verfügt, wird vom Synchronisierungsmodul angenommen, dass dieses Objekt im verbundenen Verzeichnis entweder umbenannt oder gelöscht wurde. Es weist dem Connectorbereichsobjekt einen vorübergehenden, neuen Distinguished Name zu, damit es das eingehende Objekt bereitstellen kann. Das alte Objekt erhält dann den Status Übergang, während darauf gewartet wird, dass der Connector die Umbenennung oder Löschung importiert, um eine Lösung zu erzielen.
Vorübergehende Objekte sind nicht immer ein Problem und können sogar in einer intakten Umgebung vorkommen. Mithilfe der Endpunkt-API für die Microsoft Entra Connect-Synchronisierung, Version 2 sollten vorübergehende Objekte in nachfolgenden Deltasynchronisierungszyklen automatisch aufgelöst werden. Ein gängiges Beispiel, bei dem vorübergehende Objekte generiert werden, finden Sie auf im Stagingmodus installierten Microsoft Entra Connect-Servern, wenn ein Administrator ein Objekt direkt in Microsoft Entra ID mithilfe von PowerShell dauerhaft löscht und es später erneut synchronisiert.
Wenn das Synchronisierungsmodul ein Stagingobjekt ermittelt, das dem im Connector angegebenen Objekt entspricht, wird bestimmt, welche Änderungen angewendet werden müssen. Beispielsweise kann das Synchronisierungsmodul das Objekt in der verbundenen Datenquelle umbenennen oder löschen oder nur die Attributwerte des Objekts aktualisieren.
Stagingobjekte mit aktualisierten Daten werden mit der Kennzeichnung „Import steht aus“ versehen. Es sind verschiedene Arten von ausstehenden Importen verfügbar. Je nach Ergebnis des Importvorgangs verfügt ein Stagingobjekt im Connectorbereich über einen der folgenden ausstehenden Importtypen:
- Keine. Es sind keine Änderungen von Attributen des Stagingobjekts verfügbar. Vom Synchronisierungsmodul wird dieser Typ nicht als „Import steht aus“ gekennzeichnet.
- Hinzufügen: Das Stagingobjekt ist ein neues Importobjekt im Connectorbereich. Vom Synchronisierungsmodul wird dieser Typ als ausstehender Import zur weiteren Verarbeitung im Metaverse gekennzeichnet.
- Aktualisieren: Das Synchronisierungsmodul findet ein entsprechendes Stagingobjekt im Connectorbereich und kennzeichnet es als ausstehenden Import, sodass die Aktualisierungen der Attribute im Metaverse verarbeitet werden können. Die Aktualisierungen umfassen auch die Umbenennung von Objekten.
- Löschen: Das Synchronisierungsmodul findet ein entsprechendes Stagingobjekt im Connectorbereich und kennzeichnet es als ausstehenden Import, damit das verknüpfte Objekt gelöscht werden kann.
- Löschen/Hinzufügen: Das Synchronisierungsmodul findet ein entsprechendes Stagingobjekt im Connectorbereich, aber die Objekttypen stimmen nicht überein. In diesem Fall wird eine Änderung vom Typ „Löschen/Hinzufügen“ bereitgestellt. Bei einer Änderung vom Typ „Löschen/Hinzufügen“ wird für das Synchronisierungsmodul angegeben, dass eine vollständige Neusynchronisierung dieses Objekts durchgeführt werden muss. Der Grund ist, dass für dieses Objekt andere Regelsätze gelten, wenn sich der Objekttyp ändert.
Durch das Festlegen des Status „Import steht aus“ für ein Stagingobjekt ist es möglich, die Menge der Daten, die während der Synchronisierung verarbeitet werden, erheblich zu reduzieren. Das System kann dann nur die Objekte verarbeiten, die über aktualisierte Daten verfügen.
Synchronisierungsvorgang
Die Synchronisierung umfasst zwei zusammenhängende Prozesse:
- Die eingehende Synchronisierung, bei der der Inhalt des Metaverse anhand der Daten im Connectorbereich aktualisiert wird.
- Die ausgehende Synchronisierung, bei der der Inhalt des Connectorbereichs anhand der Daten im Metaverse aktualisiert wird.
Durch die Verwendung der im Konnektorraum bereitgestellten Informationen schafft der eingehende Synchronisierungsprozess eine integrierte Sicht auf die Daten im Metaverse, die in den verbundenen Datenquellen gespeichert sind. Es werden entweder alle Stagingobjekte oder nur diejenigen mit Informationen vom Typ „Import steht aus“ aggregiert. Dies hängt von den Regeln ab, die Sie konfiguriert haben.
Beim Prozess der ausgehenden Synchronisierung werden Exportobjekte aktualisiert, wenn sich Metaverseobjekte ändern.
Bei der eingehenden Synchronisierung wird die integrierte Ansicht im Metaverse der Identitätsinformationen erstellt, die von den verbundenen Datenquellen empfangen werden. Das Synchronisierungsmodul kann die Identitätsinformationen jederzeit verarbeiten, indem es die aktuellen Identitätsinformationen von der verbundenen Datenquelle verwendet.
Eingehende Synchronisierung
Die eingehende Synchronisierung umfasst die folgenden Prozesse:
- Bereitstellung (wird auch als Projektion bezeichnet, wenn dieser Prozess von der Bereitstellung im Rahmen der ausgehenden Synchronisierung unterschieden werden soll). Das Synchronisierungsmodul erstellt basierend auf einem Stagingobjekt ein neues Metaverseobjekt und verknüpft die Objekte. Die Bereitstellung ist ein Vorgang auf Objektebene.
- Verknüpfung: Das Synchronisierungsmodul verknüpft ein Stagingobjekt mit einem vorhandenen Metaverseobjekt. Eine Verknüpfung ist ein Vorgang auf Objektebene.
- Importattributfluss: Das Synchronisierungsmodul aktualisiert die Attributwerte (als Attributfluss bezeichnet) des Objekts im Metaverse. Der Importattributfluss ist ein Vorgang auf Attributebene, für den eine Verknüpfung zwischen einem Stagingobjekt und einem Metaverseobjekt erforderlich ist.
Die Bereitstellung ist der einzige Prozess, bei dem Objekte im Metaverse erstellt werden. Von der Bereitstellung sind nur Importobjekte betroffen, bei denen es sich um getrennte Objekte handelt. Während der Bereitstellung wird vom Synchronisierungsmodul ein Metaverseobjekt erstellt, das dem Objekttyp des importierten Objekts entspricht. Es wird eine Verknüpfung zwischen den beiden Objekten erstellt und so ein verknüpftes Objekt geschaffen.
Beim Verknüpfungsprozess wird auch eine Verknüpfung zwischen Importobjekten und einem Metaverseobjekt erstellt. Der Unterschied zwischen der Verknüpfung und der Bereitstellung besteht darin, dass das Importobjekt beim Verknüpfungsprozess mit einem vorhandenen Metaverseobjekt verknüpft sein muss. Beim Bereitstellungsprozess wird dagegen ein neues Metaverseobjekt erstellt.
Das Synchronisierungsmodul versucht, ein Importobjekt mit einem Metaverseobjekt zu verknüpfen, indem Kriterien genutzt werden, die in der Konfiguration für die Synchronisierungsregel angegeben sind.
Während der Bereitstellungs- und Verknüpfungsprozesse verknüpft das Synchronisierungsmodul ein getrenntes Objekt mit einem Metaverseobjekt, um die Verknüpfung herzustellen. Nach Abschluss dieser Vorgänge auf Objektebene kann das Synchronisierungsmodul die Attributwerte des zugehörigen Metaverseobjekts aktualisieren. Dieser Vorgang wird als Importattributfluss bezeichnet.
Der Importattributfluss tritt für alle Importobjekte auf, die über neue Daten verfügen und mit einem Metaverseobjekt verknüpft sind.
Ausgehende Synchronisierung
Bei der ausgehenden Synchronisierung werden Exportobjekte aktualisiert, wenn ein Metaverseobjekt geändert, aber nicht gelöscht wird. Das Ziel der ausgehenden Synchronisierung besteht darin zu ermitteln, ob für Änderungen an Metaverseobjekten Aktualisierungen von Stagingobjekten in den Connectorbereichen erforderlich sind. In einigen Fällen kann sich aufgrund der Änderungen die Anforderung ergeben, dass Stagingobjekte in allen Connectorbereichen aktualisiert werden. Stagingobjekte, die geändert werden, werden als „Export steht aus“ gekennzeichnet und so zu Exportobjekten. Diese Exportobjekte werden später während des Exportvorgangs an die verbundene Datenquelle übertragen.
Die ausgehende Synchronisierung besteht aus drei Vorgängen:
- Bereitstellung
- Aufhebung der Bereitstellung
- Exportattributfluss
Die Bereitstellung und Aufhebung der Bereitstellung sind Vorgänge auf Objektebene. Die Aufhebung der Bereitstellung hängt von der Bereitstellung ab, da sie nur von der Bereitstellung initiiert werden kann. Ausgelöst wird die Aufhebung der Bereitstellung, wenn bei der Bereitstellung die Verknüpfung zwischen einem Metaverseobjekt und einem Exportobjekt entfernt wird.
Die Bereitstellung wird immer ausgelöst, wenn Änderungen auf Objekte im Metaverse angewendet werden. Wenn Änderungen an Metaverseobjekten vorgenommen werden, kann das Synchronisierungsmodul im Rahmen des Bereitstellungsprozesses die folgenden Aufgaben ausführen:
- Erstellen von verknüpften Objekten, bei denen ein Metaverseobjekt mit einem neu erstellten Exportobjekt verknüpft ist
- Umbenennen eines verknüpften Objekts
- Trennen von Verknüpfungen zwischen einem Metaverseobjekt und Stagingobjekten, um ein getrenntes Objekt zu erstellen
Falls es für die Bereitstellung erforderlich ist, dass vom Synchronisierungsmodul ein neues Connectorobjekt erstellt wird, ist das Stagingobjekt, mit dem das Metaverseobjekt verknüpft ist, immer ein Exportobjekt. Der Grund ist, dass das Objekt in der verbundenen Datenquelle noch nicht vorhanden ist.
Falls es für die Bereitstellung erforderlich ist, dass vom Synchronisierungsmodul ein verknüpftes Objekt getrennt und so ein getrenntes Objekt geschaffen wird, wird die Aufhebung der Bereitstellung ausgelöst. Das Objekt wird vom Prozess zur Aufhebung der Bereitstellung gelöscht.
Während der Aufhebung der Bereitstellung wird ein Exportobjekt beim Löschvorgang nicht physisch gelöscht. Das Objekt wird als Gelöscht gekennzeichnet. Dies bedeutet, dass der Löschvorgang für das Objekt bereitgestellt wird.
Der Exportattributfluss tritt auch während des Prozesses der ausgehenden Synchronisierung auf. Dies ähnelt dem Importattributfluss bei der eingehenden Synchronisierung. Der Exportattributfluss tritt nur zwischen Metaverse- und Exportobjekten auf, die verknüpft sind.
Exportvorgang
Während des Exportvorgangs untersucht das Synchronisierungsmodul alle Exportobjekte, die im Connectorbereich mit „Export steht aus“ gekennzeichnet sind, und sendet Aktualisierungen dann an die verbundene Datenquelle.
Das Synchronisierungsmodul kann den Erfolg eines Exports ermitteln, aber es kann nicht in ausreichendem Maße bestimmen, ob der Prozess der Identitätsverwaltung abgeschlossen ist. Objekte in der verbundenen Datenquelle können sich immer durch andere Prozesse ändern. Da das Synchronisierungsmodul nicht über eine permanente Verbindung mit der verbundenen Datenquelle verfügt, reicht das Treffen von Annahmen zu den Eigenschaften eines Objekts in der verbundenen Datenquelle ausschließlich anhand einer Benachrichtigung über den erfolgreichen Export nicht aus.
Mit einem Prozess in der verbundenen Datenquelle können die Attribute des Objekts beispielsweise wieder in die ursprünglichen Werte geändert werden (die verbundene Datenquelle kann die Werte also unter Umständen sofort überschreiben, nachdem die Daten vom Synchronisierungsmodul übertragen und in der verbundenen Datenquelle erfolgreich angewendet wurden).
Das Synchronisierungsmodul speichert Statusinformationen zum Export und Import für jedes Stagingobjekt. Wenn sich die Werte der Attribute, die in der Aufnahmeliste der Attribute angegeben sind, seit dem letzten Export geändert haben, ermöglicht die Speicherung des Import- und Exportstatus dem Synchronisierungsmodul die richtige Reaktion. Das Synchronisierungsmodul verwendet den Importvorgang, um die Attributwerte zu bestätigen, die in die verbundene Datenquelle exportiert wurden. Anhand eines Vergleichs zwischen den importierten und exportierten Informationen (siehe folgende Abbildung) kann das Synchronisierungsmodul ermitteln, ob der Export erfolgreich war oder wiederholt werden muss.
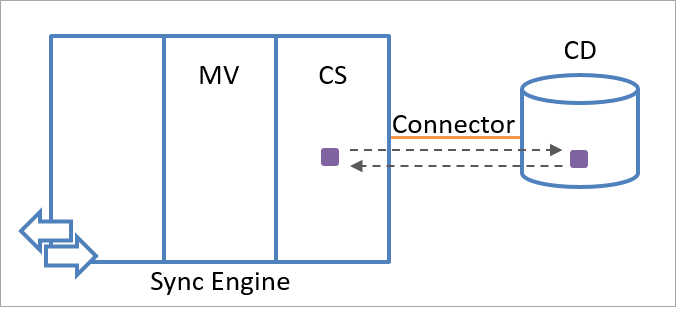
Wenn das Synchronisierungsmodul beispielsweise Attribut C mit dem Wert 5 in eine verbundene Datenquelle exportiert, wird im Exportstatusspeicher „C=5“ abgelegt. Jeder weitere Export für dieses Objekt führt zu einem Versuch, „C=5“ erneut in die verbundene Datenquelle zu exportieren, da vom Synchronisierungsmodul angenommen wird, dass dieser Wert nicht dauerhaft auf das Objekt angewendet wurde (es sei denn, von der verbundenen Datenquelle wurde vor Kurzem ein anderer Wert importiert). Der Exportspeicher wird gelöscht, wenn C=5 während eines Importvorgangs für das Objekt empfangen wird.
Nächste Schritte
Weitere Informationen finden Sie in der Konfiguration von Microsoft Entra Connect Sync.
Erfahren Sie mehr über das Integrieren Ihrer lokalen Identitäten mit Microsoft Entra ID.