Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:✅ Fabric Data Engineering und Data Science
Ressourcenprofile in Fabric Data Engineering helfen Ihnen, optimierte Spark-Computekonfigurationen ohne manuelle Optimierung zu erhalten. Sie beschreiben Ihre Arbeitsauslastung, indem Sie einen primären Anwendungsfall, ein Datenvolumen und einige andere allgemeine Eingaben auswählen. Das System 'Fabric' erstellt dann basierend auf bewährten Methoden und internen Leistungsdaten eine empfohlene Konfiguration, einschließlich Knotengrößen, Autoskaleneinstellungen und Laufzeitversion.
Gründe für die Verwendung von Ressourcenprofilen
Ressourcenprofile bieten Folgendes:
- Optimiert von Anfang an: Ihre erste Spark-Sitzung verwendet Computing-Ressourcen, die für Ihre Workload abgestimmt sind – kein iteratives Benchmarking erforderlich.
- Konsistenz: Alle Spark-Aufträge im Arbeitsbereich verwenden dieselbe leistungsorientierte Konfiguration.
- Bessere Preisleistung: Ressourcen in der richtigen Größe reduzieren Den Abfall und verbessern den Durchsatz.
- Geringerer Betriebsaufwand: Weniger Optimierungszyklen und weniger Unterstützungseskalationen.
Voraussetzungen
Zum Konfigurieren von Ressourcenprofilen müssen Sie über die Administratorrolle für den Arbeitsbereich verfügen.
Konfigurieren eines Ressourcenprofils
So konfigurieren Sie ein Ressourcenprofil für Ihren Arbeitsbereich:
Wechseln Sie zu Ihrem Arbeitsbereich, und wählen Sie "Arbeitsbereichseinstellungen" aus.
Erweitern Sie "Data Engineering/Science " im linken Bereich, und wählen Sie dann "Spark"-Einstellungen aus.
Um eine empfohlene Computekonfiguration zur Optimierung der Ressourcennutzung zu erhalten, wählen Sie unter "Optimieren für Ihren Anwendungsfall" die Option " Erste Schritte" aus.
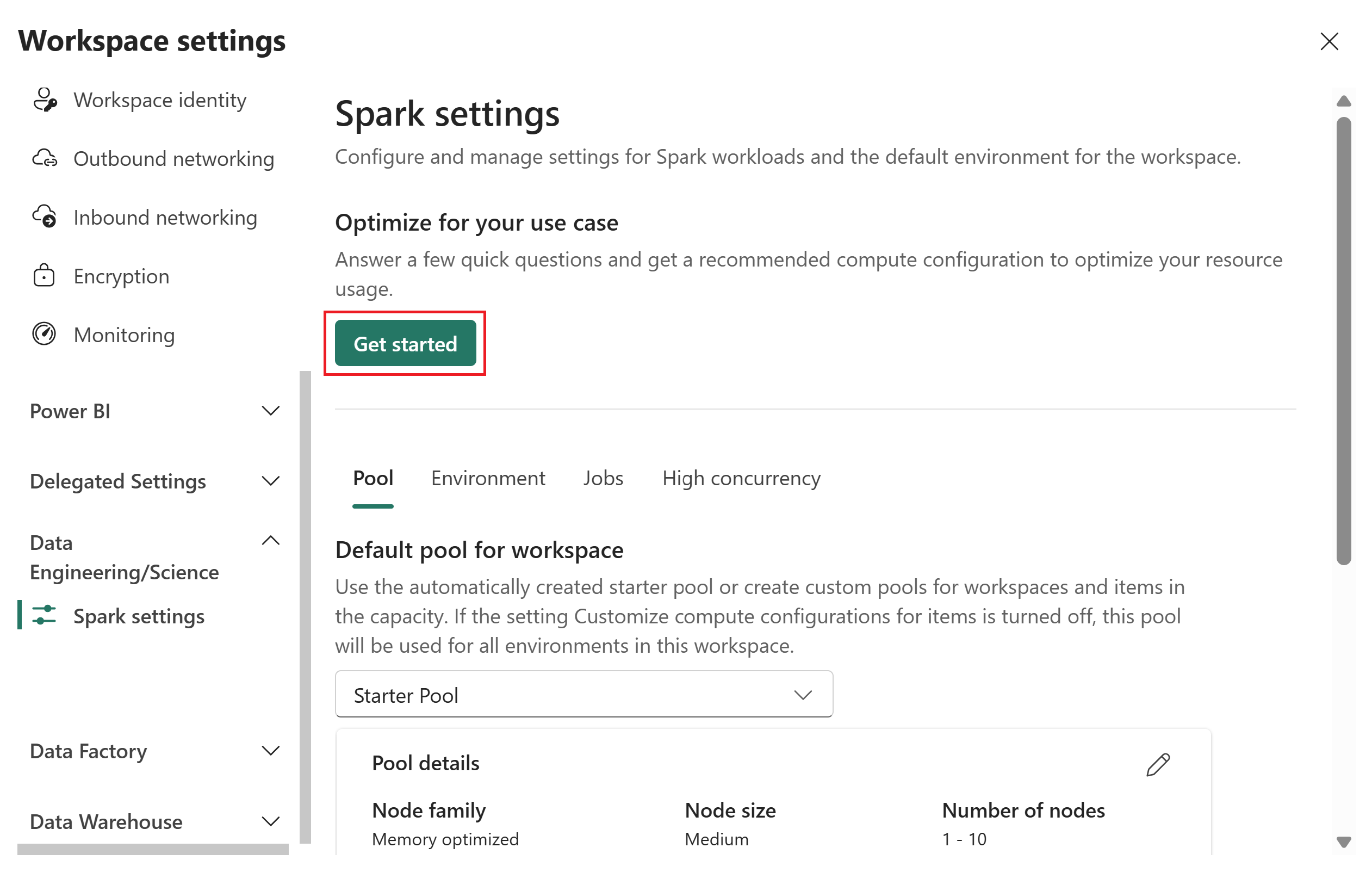
Geben Sie auf der Seite "Optimieren für Ihren Anwendungsfall " die folgenden Eingaben an:
- Primärer Anwendungsfall: Wählen Sie entweder Medallion-Ebene oder Aufgabenbasiert aus und wählen Sie dann eine spezifische Option aus dem Dropdown-Menü. Medaillenschichtoptionen sind Bronze, Silber oder Gold. Aufgabenbasierte Optionen sind "Leseoptimiert" oder "Schreiboptimiert". Anleitungen zum Auswählen eines Anwendungsfalles finden Sie unter "Primäre Anwendungsfallreferenz".
- Typisches Datenvolume: Wählen Sie ein Volume aus der Dropdownliste aus: Bis zu 1 GB, 10 GB, 100 GB, 1 TB oder über 1 TB.
- Maximale Kapazitätseinheiten (CU): Verwenden Sie den Schieberegler, um den maximalen CU-Grenzwert für den Spark-Pool festzulegen.
Wählen Sie "Empfehlung abrufen" aus.
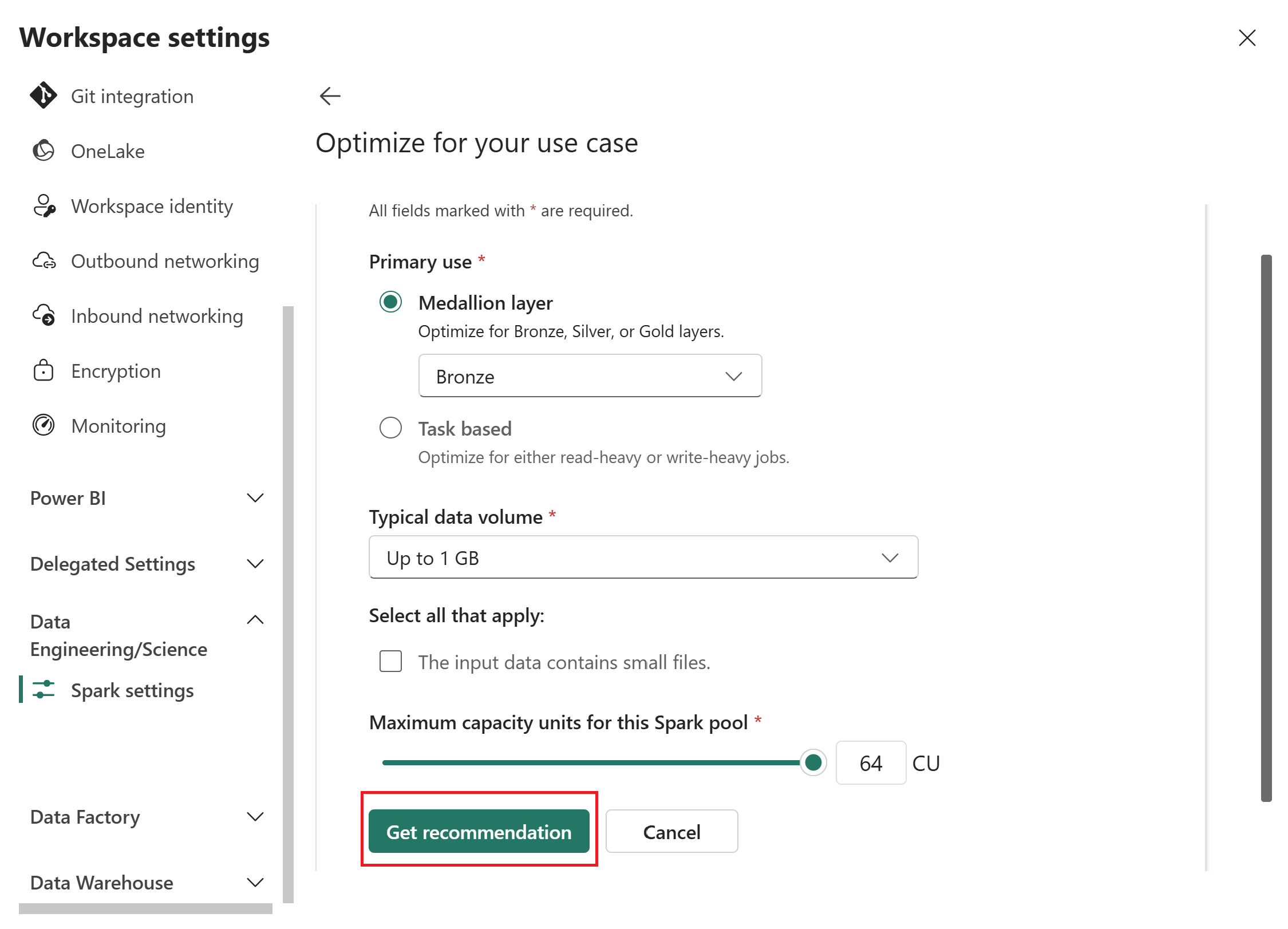
Fabric generiert eine optimierte Konfiguration basierend auf Ihren Eingaben.
Überprüfen Sie die Empfehlung. Die Empfehlung enthält Werte für zwei Kategorien:
- Sparkpool: Pooltyp, Knotenfamilie, Knotengröße, Autoskalierung und dynamische Executorzuweisung.
- Umgebung: Laufzeitversion, Spark-Treiberkerne und Arbeitsspeicher, Spark-Executorkerne, Arbeitsspeicher und Instanzen.
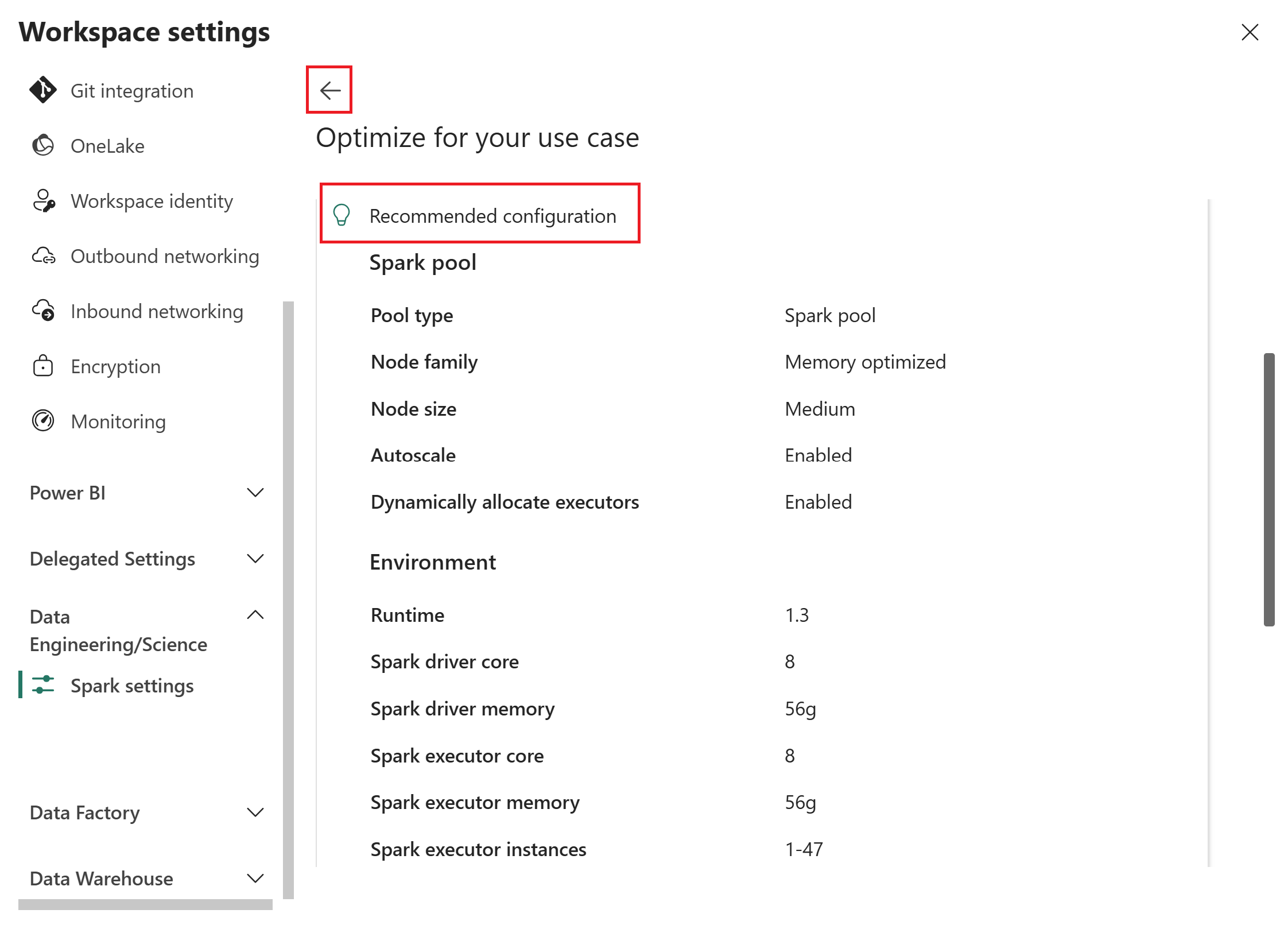
Wenn Sie Ihre Eingaben anpassen möchten, wählen Sie den Pfeil "Zurück" aus, um zur vorherigen Seite zurückzukehren, ihre Auswahl zu aktualisieren, und wählen Sie dann erneut "Empfehlung abrufen " aus.
Geben Sie einen Spark-Poolnamen und eine Umgebung für die Konfiguration ein, und wählen Sie dann "Übernehmen" aus, um ihn im Arbeitsbereich zu speichern.
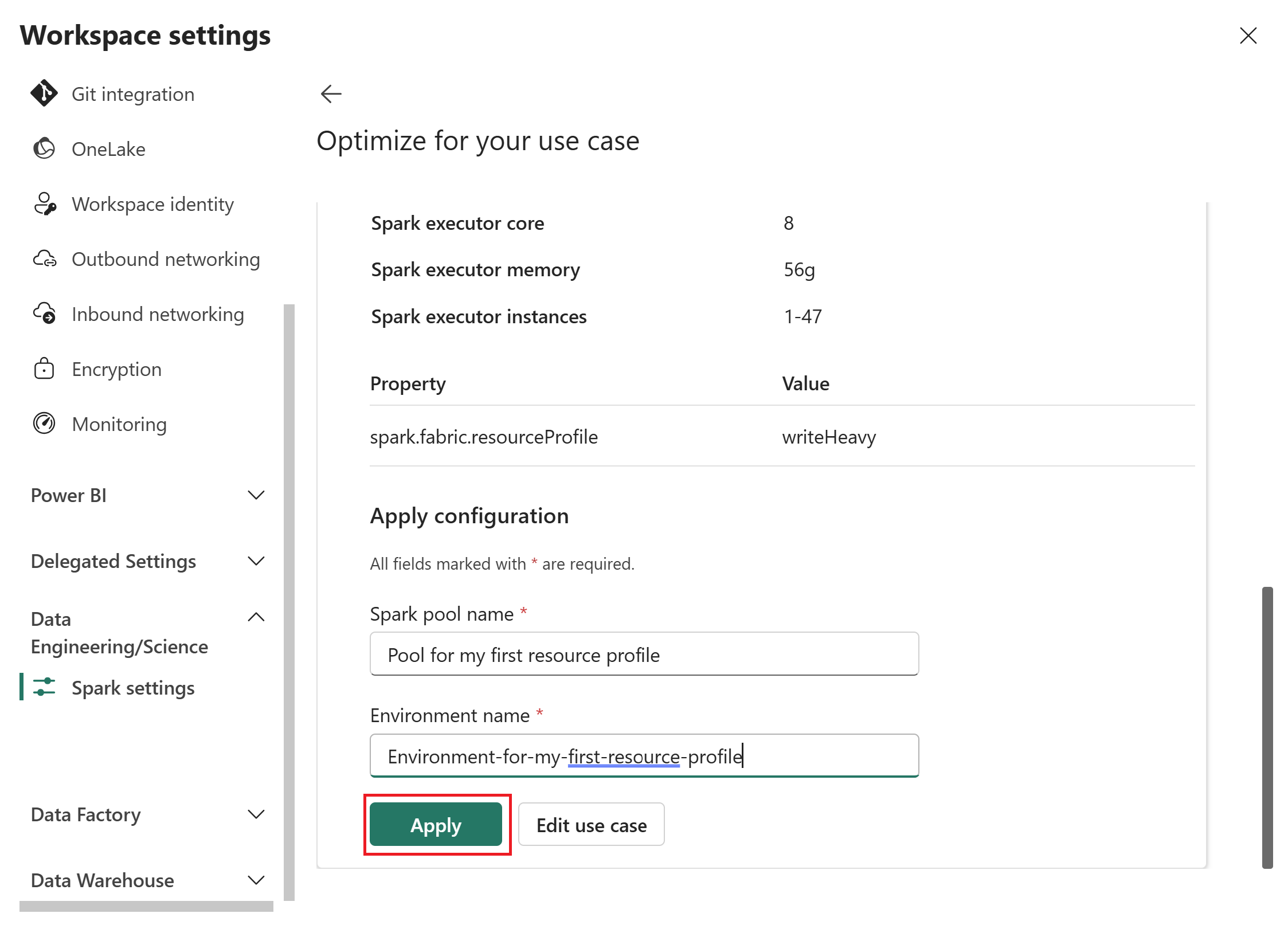




Nachdem Sie ein Ressourcenprofil angewendet haben, erstellt Fabric einen benutzerdefinierten Spark-Pool mit den empfohlenen Einstellungen.
Hinweis
Wenn Ihr Arbeitsbereich noch nicht über einen benutzerdefinierten Pool verfügt, wird der neue Pool automatisch als Standardpool für den Arbeitsbereich festgelegt. Wenn Ihr Arbeitsbereich bereits über einen Standardpool verfügt, müssen Sie in den Spark-Arbeitsbereichseinstellungen manuell zum neuen Pool wechseln. Aktive Sitzungen sind nicht betroffen, bis sie neu gestartet werden.
Primäre Anwendungsfallreferenz
Verwenden Sie die folgenden Anleitungen, um die richtige Primäre Anwendungsfalleingabe auszuwählen, wenn Sie ein Ressourcenprofil konfigurieren:
Medaillonschicht
Wählen Sie Medallion-Ebene aus, wenn Ihre Datenpipeline dem Medallion-Architekturmuster folgt, in dem daten durch Bronze (roh), Silber (gereinigt) und Gold (kuratiert) verschoben werden. Jede Option ist auf die typischen Lese-/Schreibeigenschaften dieser Phase abgestimmt.
| Anwendungsfall | Wann verwenden |
|---|---|
| Bronze | Erfassung von Rohdaten, hoher Schreibdurchsatz, verschiedene Formate |
| Silber | Reinigung und Anreicherung, ausgewogener Lese-/Schreibzugriff mit moderaten Verknüpfungen |
| Gold | Aggregierung und Berichterstellung, optimiert für Analysen und Power BI |
Vorgangsbasiert
Wählen Sie auf Aufgaben basierend aus, wenn Ihre Arbeitsauslastung nicht dem Medaillon-Muster folgt oder wenn sie von einem einzigen Zugriffsmuster dominiert wird. Verwenden Sie diese Option beispielsweise für eigenständige ETL-Aufträge, interaktive Analysenotizbücher oder Streamingpipelinen.
| Anwendungsfall | Wann verwenden |
|---|---|
| Lesen optimiert | Häufige Lese- und Abfragen, interaktive Notizbücher |
| Schreiben optimiert | Datenverarbeitung mit hohem Volumen, ETL-Pipelines, Streaming |
Ressourcenprofile automatisch aktualisieren
Ressourcenprofile unterstützen eine Funktion für die automatische Aktualisierung, mit der Ihre Spark-Computekonfiguration auf die neuesten Optimierungen von Fabric abgestimmt bleibt. Wenn die automatische Aktualisierung aktiviert ist, wendet Fabric workloadspezifische Spark-Eigenschaften basierend auf Ihrem Ressourcenprofiltyp an, ohne dass eine manuelle Optimierung erforderlich ist.
Konfigurationen für automatische Updates
Fabric stellt drei Profile für automatische Updates bereit, die jeweils für ein bestimmtes Workloadmuster abgestimmt sind:
Leseintensiv für Spark-Workloads
Festlegen über spark.fabric.resourceProfile.readHeavyForSparkAutoUpdate:
{
"spark.databricks.delta.optimizeWrite.enabled": "true",
"spark.databricks.delta.optimizeWrite.partitioned.enabled": "true",
"spark.databricks.delta.optimizeWrite.binSize": "128"
}
Verwenden Sie dieses Profil, wenn Ihre Arbeitslast hauptsächlich aus Spark-Lesevorgängen besteht und der Bedarf an Schreiboptimierung moderat ist.
Leseintensive Arbeitslasten für Power BI
Festlegen über spark.fabric.resourceProfile.readHeavyForPBIAutoUpdate:
{
"spark.sql.parquet.vorder.default": "true",
"spark.databricks.delta.optimizeWrite.enabled": "true",
"spark.databricks.delta.optimizeWrite.binSize": "1g"
}
Verwenden Sie dieses Profil, wenn Ihre Daten in erster Linie von Power BI genutzt werden. V-Order ist für eine optimale DirectLake-Leistung aktiviert, und eine größere Bin-Größe erzeugt weniger, größere Dateien, die für analytische Lesevorgänge geeignet sind.
Workloads mit vielen Schreibvorgängen
Festlegen über spark.fabric.resourceProfile.writeHeavyAutoUpdate:
{
"spark.sql.parquet.vorder.default": "false",
"spark.databricks.delta.optimizeWrite.binSize": "128",
"spark.databricks.delta.optimizeWrite.partitioned.enabled": "true"
}
Verwenden Sie dieses Profil, wenn Ihre Arbeitslast schreibintensiv ist (z. B. Datenaufnahme in hohem Volumen oder ETL). V-Order ist deaktiviert, um den Schreibaufwand zu reduzieren und optimierte Schreibvorgänge mit Partitionierung sind für ein effizientes Dateilayout aktiviert.
Funktionsweise der automatischen Aktualisierung
Wenn ein Ressourcenprofil mit automatischer Aktualisierung angewendet wird:
- Fabric wählt die entsprechende Konfiguration für automatische Updates basierend auf Ihrem primären Anwendungsfall und Workloadtyp aus.
- Die Spark-Eigenschaften werden automatisch auf neue Sitzungen im Arbeitsbereich angewendet.
- Aktive Sitzungen sind nicht betroffen, bis sie neu gestartet werden.
Hinweis
Automatische Aktualisierungskonfigurationen optimieren das Schreibverhalten und das Dateilayout von Delta Lake innerhalb der Grenzen Ihrer ursprünglichen Profileingaben. Sie ändern ihre Poolgröße, Die Knotenkonfiguration oder die Einstellungen für die automatische Skalierung nicht.
Konfigurationsreferenz
| Setting | Angewendete Eigenschaften | Wann verwenden |
|---|---|---|
spark.fabric.resourceProfile.readHeavyForSparkAutoUpdate |
Optimierter Schreibvorgang aktiviert, partitionierter Schreibvorgang, Bin-Größe: 128 MB | Leselastige Spark-Analysen |
spark.fabric.resourceProfile.readHeavyForPBIAutoUpdate |
V-Order aktiviert, optimiertes Schreiben, 1-GB-Bin-Größe | Leseintensives Power BI/DirectLake |
spark.fabric.resourceProfile.writeHeavyAutoUpdate |
V-Order deaktiviert, Schreibvorgang optimieren, Bin-Größe 128 MB, partitioniert | Schreibintensive Datenaufnahme und ETL |