Anmerkung
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen, dich anzumelden oder die Verzeichnisse zu wechseln.
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen , die Verzeichnisse zu wechseln.
In diesem Tutorial erfahren Sie, wie Sie eine Spark-Auftragsdefinition in Microsoft Fabric erstellen.
Der Erstellungsvorgang der Spark-Auftragsdefinition ist schnell und einfach, und es gibt mehrere Möglichkeiten für den Einstieg.
Sie können eine Spark-Auftragsdefinition über das Fabric-Portal oder mithilfe der Rest-API von Microsoft Fabric erstellen. Dieser Artikel konzentriert sich auf das Erstellen einer Spark-Auftragsdefinition aus dem Fabric-Portal. Informationen zum Erstellen einer Spark-Auftragsdefinition mithilfe der REST-API finden Sie unter Apache Spark-Auftragsdefinitions-API v1 und Apache Spark-Auftragsdefinitions-API v2.
Voraussetzungen
Bevor Sie beginnen, benötigen Sie Folgendes:
- Ein Fabric-Mandantenkonto mit einem aktiven Abonnement. Sie können kostenlos ein Konto erstellen.
- Ein Arbeitsbereich in Microsoft Fabric. Weitere Informationen finden Sie unter Erstellen und Verwalten von Arbeitsbereichen in Microsoft Fabric.
- Mindestens ein Seehaus im Arbeitsbereich. Das Lakehouse dient als Standarddateisystem für die Spark-Auftragsdefinition. Weitere Informationen finden Sie unter Erstellen eines Seehauses.
- Eine Hauptdefinitionsdatei für den Spark-Auftrag. Diese Datei enthält die Anwendungslogik und ist obligatorisch, um einen Spark-Auftrag auszuführen. Jede Spark-Auftragsdefinition kann nur eine Hauptdefinitionsdatei enthalten.
Sie müssen Ihrer Spark-Auftragsdefinition bei der Erstellung einen Namen geben. Der Name muss innerhalb des aktuellen Arbeitsbereichs eindeutig sein. Die neue Spark-Auftragsdefinition wird in Ihrem aktuellen Arbeitsbereich erstellt.
Erstellen einer Spark-Auftragsdefinition im Fabric-Portal
Führen Sie die folgenden Schritte aus, um eine Spark-Auftragsdefinition im Fabric-Portal zu erstellen:
- Melden Sie sich beim Microsoft Fabric-Portalan.
- Navigieren Sie zu dem gewünschten Arbeitsbereich, in dem Sie die Spark-Auftragsdefinition erstellen möchten.
- Wählen Sie " Neue Element>Spark Job Definition" aus.
- Geben Sie im Bereich "Neue Spark-Auftragsdefinition " die folgenden Informationen an:
- Name: Geben Sie einen eindeutigen Namen für die Spark-Auftragsdefinition ein.
- Standort: Wählen Sie den Speicherort des Arbeitsbereichs aus.
- Wählen Sie "Erstellen" aus, um die Spark-Auftragsdefinition zu erstellen.
Ein alternativer Einstiegspunkt zum Erstellen einer Spark-Auftragsdefinition ist die Datenanalyse mithilfe einer SQL-Kachel auf der Fabric-Startseite. Sie können dieselbe Option finden, indem Sie die Kachel "Allgemein" auswählen.

Wenn Sie die Kachel auswählen, werden Sie aufgefordert, einen neuen Arbeitsbereich zu erstellen oder eine vorhandene zu wählen. Nachdem Sie den Arbeitsbereich ausgewählt haben, wird die Spark-Auftragsdefinitionserstellungsseite geöffnet.
Anpassen einer Spark-Auftragsdefinition für PySpark (Python)
Bevor Sie eine Spark-Auftragsdefinition für PySpark erstellen, benötigen Sie eine Muster-Parkettdatei, die in das Seehaus hochgeladen wurde.
- Laden Sie die Muster-Parkettdatei yellow_tripdata_2022-01.Parkett herunter.
- Wechseln Sie zum Seehaus, in dem Sie die Datei hochladen möchten.
- Laden Sie es in den Abschnitt "Dateien" des Seehauses hoch.
Erstellen einer Spark-Auftragsdefinition für PySpark:
Wählen Sie PySpark (Python) in der Dropdownliste Sprache aus.
Laden Sie die createTablefromParquet.py Beispieldefinitionsdatei herunter. Laden Sie sie als Hauptdefinitionsdatei hoch. Die Hauptdefinitionsdatei (job.Main) ist die Datei, die die Anwendungslogik enthält, und ist obligatorisch, um einen Spark-Auftrag auszuführen. Für jede Spark-Auftragsdefinition kann nur eine Hauptdefinitionsdatei hochgeladen werden.
Hinweis
Sie können die Hauptdefinitionsdatei vom lokalen Desktop oder aus einem vorhandenem Azure Data Lake Storage (ADLS) Gen2-Pfad hochladen, indem Sie den vollständigen ABFSS-Pfad der Datei angeben. Beispiel:
abfss://your-storage-account-name.dfs.core.windows.net/your-file-path.Laden Sie optional Referenzdateien als
.py(Python)-Dateien hoch. Die Referenzdateien sind die Python-Module, die die Hauptdefinitionsdatei importiert. Genau wie die Hauptdefinitionsdatei können Sie die Verweisdateien von Ihrem Desktop oder aus einem vorhandenen ADLS Gen2-Pfad hochladen. Es werden mehrere Referenzdateien unterstützt.Tipp
Wenn Sie einen ADLS Gen2-Pfad verwenden, stellen Sie sicher, dass auf die Datei zugegriffen werden kann. Sie müssen dem Benutzerkonto, das den Auftrag ausführt, die richtige Berechtigung für das Speicherkonto erteilen. Hier sind zwei verschiedene Möglichkeiten, wie Sie die Berechtigung erteilen können:
- Weisen Sie dem Benutzerkonto die Rolle „Mitwirkender” für das Speicherkonto zu.
- Weisen Sie dem Benutzerkonto Lese- und Ausführungsberechtigungen für die Datei über die Zugriffssteuerungsliste (ACL) für ADLS Gen2 zu.
Bei einem manuellen Ausführen wird das Konto des aktuellen angemeldeten Benutzers zum Ausführen des Auftrags verwendet.
Geben Sie bei Bedarf Befehlszeilenargumente für den Auftrag an. Verwenden Sie das Leerzeichen als Trennzeichen, um die Argumente zu trennen.
Fügen Sie dem Auftrag den Lakehouse-Verweis hinzu. Sie müssen dem Auftrag mindestens einen Lakehouse-Verweis hinzugefügt haben. Dieses Lakehouse stellt den Lakehouse-Standardkontext für den Auftrag dar.
Mehrere Lakehouse-Verweise werden unterstützt. Den nicht standardmäßigen Lakehouse-Namen und die vollständige OneLake-URL finden Sie auf der Seite Spark-Einstellungen.

Anpassen einer Spark-Auftragsdefinition für Scala/Java
Erstellen einer Spark-Auftragsdefinition für Scala/Java:
Wählen Sie in der Dropdownliste SpracheSpark(Scala/Java) aus.
Laden Sie die Hauptdefinitionsdatei als
.jar(Java)-Datei hoch. Die Hauptdefinitionsdatei ist die Datei, die die Anwendungslogik dieses Auftrags enthält, und ist obligatorisch, um einen Spark-Auftrag auszuführen. Für jede Spark-Auftragsdefinition kann nur eine Hauptdefinitionsdatei hochgeladen werden. Geben Sie den Main-Klassennamen an.Laden Sie optional Referenzdateien als
.jar(Java)-Dateien hoch. Die Referenzdateien sind die Dateien, auf die die Hauptdefinitionsdatei verweist/importiert.Geben Sie bei Bedarf Befehlszeilenargumente für den Auftrag an.
Fügen Sie dem Auftrag den Lakehouse-Verweis hinzu. Sie müssen dem Auftrag mindestens einen Lakehouse-Verweis hinzugefügt haben. Dieses Lakehouse stellt den Lakehouse-Standardkontext für den Auftrag dar.
Anpassen einer Spark-Auftragsdefinition für R
Erstellen einer Spark-Auftragsdefinition für SparkR(R):
Wählen Sie in der Dropdownliste Sprache die Option SparkR(R) aus.
Laden Sie die Hauptdefinitionsdatei als (
.rR)-Datei hoch. Die Hauptdefinitionsdatei ist die Datei, die die Anwendungslogik dieses Auftrags enthält, und ist obligatorisch, um einen Spark-Auftrag auszuführen. Für jede Spark-Auftragsdefinition kann nur eine Hauptdefinitionsdatei hochgeladen werden.Laden Sie optional Referenzdateien als
.r(R)-Dateien hoch. Die Verweisdateien sind die Dateien, auf die die Hauptdefinitionsdatei verweist bzw. die von dieser importiert werden.Geben Sie bei Bedarf Befehlszeilenargumente für den Auftrag an.
Fügen Sie dem Auftrag den Lakehouse-Verweis hinzu. Sie müssen dem Auftrag mindestens einen Lakehouse-Verweis hinzugefügt haben. Dieses Lakehouse stellt den Lakehouse-Standardkontext für den Auftrag dar.
Hinweis
Die Spark-Auftragsdefinition wird in Ihrem aktuellen Arbeitsbereich erstellt.
Optionen zum Anpassen von Spark-Auftragsdefinitionen
Es gibt eine Reihe von Optionen, um die Ausführung der Spark-Auftragsdefinition weiter anzupassen.
Spark Compute: Auf der Registerkarte "Spark Compute " können Sie die Fabric-Laufzeitversion sehen, die zum Ausführen des Spark-Auftrags verwendet wird. Sie können auch die Spark-Konfigurationseinstellungen sehen, die zum Ausführen des Auftrags verwendet werden. Sie können die Spark-Konfigurationseinstellungen anpassen, indem Sie die Schaltfläche "Hinzufügen " auswählen.
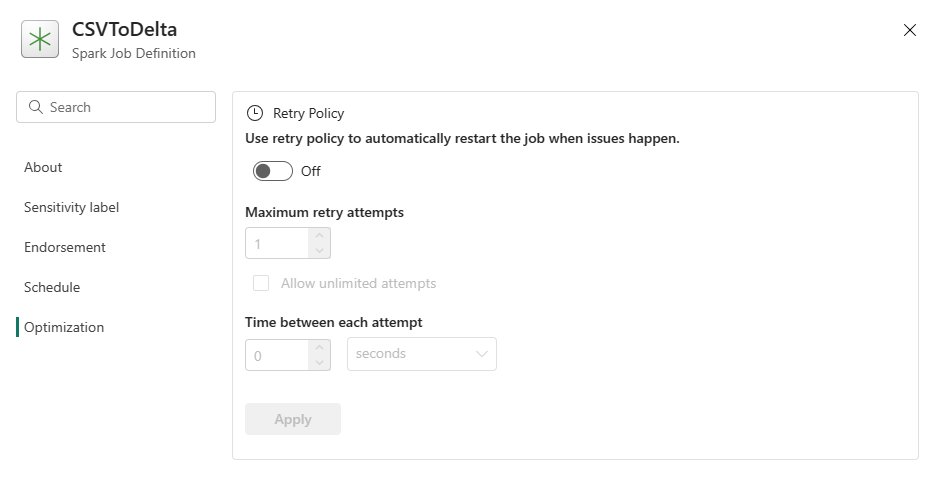
Optimierung: Auf der Registerkarte Optimierung können Sie die Wiederholungsrichtlinie für den Auftrag aktivieren und einrichten. Wenn sie aktiviert ist, wird der Auftrag bei einem Fehler wiederholt. Sie können ferner die maximale Anzahl von Wiederholungen und das Intervall zwischen den Wiederholungen festlegen. Für jeden Wiederholungsversuch wird der Auftrag neu gestartet. Stellen Sie sicher, dass der Auftrag idempotent ist.