Anmerkung
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen, dich anzumelden oder die Verzeichnisse zu wechseln.
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen , die Verzeichnisse zu wechseln.
Erfahren Sie, wie Git-Integrations- und Bereitstellungspipelinen mit DER API für GraphQL in Microsoft Fabric arbeiten. In diesem Artikel erfahren Sie, wie Sie eine Verbindung mit Ihrem Repository einrichten, Ihre API für GraphQL verwalten und in verschiedenen Umgebungen bereitstellen können.
Wer verwendet die Quellcodeverwaltung und Bereitstellung?
Git-Integrations- und Bereitstellungspipelines sind für Folgendes unerlässlich:
- Datentechniker , die Fabric GraphQL-API-Konfigurationen über Versionssteuerung und CI/CD-Workflows verwalten
- Fabric-Arbeitsbereichsadministratoren koordinieren Bereitstellungen für Entwicklungs-, Test- und Produktions-Fabric-Arbeitsbereiche
- DevOps-Teams , die Bereitstellungspipelinen für Fabric-APIs in mehreren Umgebungen und Kapazitäten implementieren
- Plattformteams, die Governance-, Tracking- und Rollbackfunktionen für Fabric-API-Änderungen benötigen
Verwenden Sie Quellcodeverwaltungs- und Bereitstellungspipelinen, wenn Sie GraphQL-APIs als Teil eines strukturierten Entwicklungslebenszyklus mit mehreren Umgebungen verwalten müssen.
Hinweis
Die API für die GraphQL-Quellcodeverwaltung und -Bereitstellung befindet sich derzeit in der Vorschau.
Voraussetzungen
- Sie müssen über eine API für GraphQL in Fabric verfügen. Weitere Informationen finden Sie unter Erstellen einer API für GraphQL in Fabric und Hinzufügen von Daten.
Überblick
Fabric bietet leistungsstarke Tools für CI/CD (kontinuierliche Integration und kontinuierliche Bereitstellung) und Das Lebenszyklusmanagement der Entwicklung über zwei Hauptkomponenten: Git-Integration (CI) und Bereitstellungspipelinen (CD). Arbeitsbereiche dienen als zentrale Komponenten für git-Synchronisierungs- und Bereitstellungsphasen.
Git-Integration (CI): Synchronisiert Arbeitsbereichselemente (z. B. Code, Konfigurationen, APIs) mit Versionssteuerungsrepositorys, Aktivieren der Versionssteuerung und Änderungsnachverfolgung über Git.
Bereitstellungspipelinen (CD): Ermöglicht die Erstellung von Phasen (z. B. Entwicklung, Test, Produktion) mit verknüpften Arbeitsbereichen. Elemente, die in jeder Phase unterstützt werden, werden automatisch in nachfolgende Phasen repliziert und Änderungen in einer Arbeitsbereichstriggerbereitstellung in einer Releasepipeline ausgelöst. Sie können die Pipeline konfigurieren, um sicherzustellen, dass Änderungen in allen Umgebungen getestet und effizient bereitgestellt werden.
Fabric unterstützt verschiedene CI/CD-Workflows, die auf gängige Szenarien zugeschnitten sind. Weitere Informationen finden Sie unter CI/CD-Workflowoptionen in Fabric.
Hinweis
Während der Bereitstellung werden nur Metadaten kopiert; und Daten werden nicht kopiert.
Elemente aus dem Arbeitsbereich werden im zugeordneten Git-Repository als Infrastruktur als Code (IaC) gespeichert. Codeänderungen im Repository können die Bereitstellung in Pipelines auslösen. Mit dieser Methode können Sie Codeänderungen für Test- und Produktionsfreigabezwecke automatisch repliziert haben.
Methoden für die Datenquellenauthentifizierung
Beim Erstellen Ihrer API für GraphQL wählen Sie aus, wie Clients authentifiziert und auf Ihre Datenquellen zugreifen. Diese Auswahl hat erhebliche Auswirkungen auf Bereitstellungspipelinen und das verhalten der automatischen Bindung. Das Verständnis dieser Authentifizierungsmethoden ist für die Planung Ihres CI/CD-Workflows unerlässlich. Weitere Informationen zur automatischen Bindung und zum Bereitstellungsprozess finden Sie unter Grundlegendes zum Bereitstellungsprozess.
Beim Verbinden von Datenquellen mit Ihrer API für GraphQL stehen zwei Konnektivitätsoptionen zur Verfügung: Einmaliges Anmelden (Single Sign-On, SSO) und gespeicherte Anmeldeinformationen.

Einmaliges Anmelden (Single Sign-On, SSO)
Mit SSO verwenden API-Clients ihre eigenen Anmeldeinformationen für den Zugriff auf Datenquellen. Der authentifizierte API-Benutzer muss über Berechtigungen für die API und die zugrunde liegende Datenquelle verfügen.
Verwenden Sie SSO, wenn:
- Verfügbarmachen von Fabric-Datenquellen (Lakehouses, Warehouses, SQL Analytics-Endpunkte)
- Sie möchten, dass Benutzer auf Daten basierend auf ihren individuellen Berechtigungen zugreifen können.
- Sie benötigen Sicherheitsrichtlinien auf Zeilenebene oder andere Datenzugriffsrichtlinien, um pro Benutzer anzuwenden
Berechtigungsanforderungen:
- API-Benutzer benötigen Execute-Berechtigungen für die GraphQL-API (Ausführen von Abfragen und Mutationen)
- API-Benutzer benötigen Lese- oder Schreibberechtigungen für die Datenquelle.
- Alternativ können Sie Benutzer als Arbeitsbereichsmitglieder mit der Rolle "Mitwirkender " hinzufügen, in der sich sowohl API als auch Datenquelle befinden.
Verhalten beim automatischen Binden in Bereitstellungspipelines: Wenn Sie eine API mithilfe von SSO aus dem Quellarbeitsbereich (z. B. Dev) im Zielarbeitsbereich bereitstellen (z. B. Test):
- Die Datenquelle und die GraphQL-API werden beide im Zielarbeitsbereich bereitgestellt.
- Die API im Zielarbeitsbereich wird automatisch an die kopie der lokalen Datenquelle im Zielarbeitsbereich gebunden.
- Jede Umgebung (Dev, Test, Production) verwendet eine eigene Datenquelleninstanz.
Hinweis
Es gibt spezifische Einschränkungen bei der Verwendung von SSO mit SQL Analytics-Endpunkten. Details finden Sie unter "Aktuelle Einschränkungen ".
Gespeicherte Anmeldeinformationen
Bei gespeicherten Anmeldeinformationen authentifiziert sich eine einzelne freigegebene Anmeldeinformation zwischen der API und Datenquellen. API-Benutzer benötigen nur Zugriff auf die API selbst, nicht auf die zugrunde liegenden Datenquellen.
Verwenden Sie gespeicherte Anmeldeinformationen, wenn:
- Verfügbarmachen von Azure-Datenquellen (Azure SQL-Datenbank, externe Datenbanken)
- Sie möchten eine vereinfachte Berechtigungsverwaltung (Benutzer benötigen nur API-Zugriff)
- Alle API-Benutzer sollten auf dieselben Daten mit denselben Berechtigungen zugreifen.
- Sie benötigen konsistente Anmeldeinformationen für alle API-Anforderungen
Berechtigungsanforderungen:
- API-Benutzer benötigen nur Execute-Berechtigungen für die GraphQL-API (Ausführen von Abfragen und Mutationen)
- Die gespeicherten Anmeldeinformationen selbst müssen über entsprechende Berechtigungen für die Datenquelle verfügen.
- Entwickler, die die API bereitstellen, müssen Zugriff auf die gespeicherten Anmeldeinformationen haben.
Verhalten beim automatischen Binden in Bereitstellungspipelines: Wenn Sie eine API mithilfe gespeicherter Anmeldeinformationen aus dem Quellarbeitsbereich (Dev) im Zielarbeitsbereich (Test) bereitstellen:
- Die Datenquelle wird im Zielarbeitsbereich bereitgestellt.
- Die API im Zielarbeitsbereich bleibt mit der Datenquelle im Quellarbeitsbereich (Dev) verbunden.
- Die automatische Bindung tritt nicht auf – die bereitgestellte API verwendet weiterhin die gespeicherten Anmeldeinformationen, die auf die ursprüngliche Datenquelle verweisen.
- Sie müssen Verbindungen manuell neu konfigurieren oder neue gespeicherte Anmeldeinformationen in jeder Zielumgebung erstellen.
Von Bedeutung
Nachdem Sie eine Authentifizierungsmethode für Ihre API ausgewählt haben, gilt sie für alle Datenquellen, die dieser API hinzugefügt wurden. Sie können SSO und gespeicherte Anmeldeinformationen in derselben API nicht kombinieren.
Arbeitsbereichübergreifende Verbindungen
Wenn Ihre API im Quellarbeitsbereich (Dev) eine Verbindung mit einer Datenquelle in einem anderen Arbeitsbereich herstellt, bleibt die bereitgestellte API im Zielarbeitsbereich (Test) unabhängig von der Authentifizierungsmethode mit dieser externen Datenquelle verbunden. Die automatische Bindung funktioniert nur, wenn sich sowohl die API als auch die Datenquelle im gleichen Quellarbeitsbereich befinden.
Das folgende Diagramm veranschaulicht diese Bereitstellungsszenarien:

Weitere Informationen zum Einrichten dieser Authentifizierungsmethoden beim Erstellen ihrer API finden Sie unter Herstellen einer Verbindung mit einer Datenquelle.
API für die GraphQL-Git-Integration
Die Fabric-API für GraphQL unterstützt die Git-Integration, sodass Sie Ihre GraphQL-APIs als Code in Ihrem Versionssteuerungssystem verwalten können. Diese Integration bietet Versionsverlauf, Zusammenarbeit über Branches und Pull-Anfragen, die Fähigkeit, Änderungen zurückzusetzen, sowie einen vollständigen Audit-Trail der API-Änderungen. Indem Sie Ihre GraphQL-API-Konfiguration als Infrastruktur als Code (IaC) behandeln, können Sie bewährte Methoden für die Softwareentwicklung auf Ihre Datenzugriffsebene anwenden.
Die Git-Integration ist für Folgendes unerlässlich:
- Versionssteuerung: Nachverfolgen aller Änderungen an Ihrem GraphQL-Schema, Datenquellenverbindungen und Beziehungen im Laufe der Zeit
- Zusammenarbeit: Arbeiten mit Teammitgliedern mithilfe von Verzweigungen, Pullanforderungen und Codeüberprüfungen
- Rollbackfunktion: Zurücksetzen auf vorherige API-Konfigurationen, wenn Probleme auftreten
- Umgebungsförderung: Verwenden Von Git als Wahrheitsquelle für die Bereitstellung von APIs in allen Umgebungen
Verbinden Ihres Arbeitsbereichs mit Git
So aktivieren Sie die Git-Integration für Ihre GraphQL-APIs:
- Öffnen von Arbeitsbereichseinstellungen für den Arbeitsbereich, der Ihre API für GraphQL enthält
- Konfigurieren der Git-Verbindung mit Ihrem Repository (Azure DevOps, GitHub oder anderer Git-Anbieter)
- Nach der Verbindung werden alle Arbeitsbereichselemente, einschließlich APIs für GraphQL, im Quellcodeverwaltungsbereich angezeigt.
Ausführliche Anweisungen zum Einrichten finden Sie unter "Erste Schritte mit der Git-Integration".

Commit und Synchronisieren Ihrer GraphQL-APIs
Nachdem Sie eine Verbindung mit Git hergestellt haben, können Sie Ihre API für GraphQL-Konfigurationen in das Repository übernehmen. Jeder Commit erstellt eine Momentaufnahme Ihrer API-Definition, einschließlich:
- GraphQL-Schemadefinitionen
- Datenquellenverbindungen und Authentifizierungseinstellungen
- Beziehungskonfigurationen
- Abfrage- und Mutationsdefinitionen
Nach dem Commit werden Ihre GraphQL-APIs in Ihrem Git-Repository mit einer strukturierten Ordnerhierarchie angezeigt. Ab diesem Zeitpunkt können Sie standardmäßige Git-Workflows nutzen, wie das Erstellen von Pull Requests, das Verwalten von Branches und die Zusammenarbeit mit Ihrem Team durch Code-Reviews. Weitere Informationen zum Arbeiten mit Verzweigungen finden Sie unter "Verzweigungen verwalten".
GraphQL-API-Darstellung in Git
Jede API für GraphQL-Element wird in Git mit einer klar definierten Ordnerstruktur gespeichert, die alle Aspekte Ihrer API-Konfiguration darstellt:

Die API-Definitionsdateien enthalten alle Metadaten, die erforderlich sind, um Ihre GraphQL-API in einem beliebigen Fabric-Arbeitsbereich neu zu erstellen. Dazu gehören Schemadefinitionen, Datenquellenzuordnungen und Konfigurationseinstellungen. Wenn Sie von Git zurück zu einem Fabric-Arbeitsbereich synchronisieren, verwendet das System diese Definitionsdateien, um Ihre API genau wie beim Commit wiederherzustellen:

Arbeiten mit API-Definitionsdateien:
Das Definitionsformat der GraphQL-API folgt den Infrastructure as Code (IaC)-Standards von Fabric. Sie können diese Dateien direkt in Ihrem Git-Repository anzeigen und bearbeiten, die meisten Änderungen sollten jedoch über das Fabric-Portal vorgenommen werden, um die Schemagültigkeit sicherzustellen. Die Definitionsdateien sind besonders nützlich für:
- Codeüberprüfungen: Teammitglieder können API-Änderungen in Pullanforderungen überprüfen
- Dokumentation: Die Dateien dienen als Dokumentation Ihrer API-Struktur
- Automatisierung: CI/CD-Pipelines können diese Dateien lesen, um API-Konfigurationen zu verstehen
- Notfallwiederherstellung: Vollständige API-Definitionen werden in der Versionssteuerung beibehalten.
Ausführliche Informationen zum GraphQL-API-Definitionsformat, zur Syntax und zu Beispielen finden Sie in der Dokumentation zu Fabric-Steuerelementebenen-APIs:
API für GraphQL in der Bereitstellungspipeline
Mit Bereitstellungspipelines können Sie Ihre API für GraphQL-Konfigurationen in allen Umgebungen (in der Regel Entwicklung, Test und Produktion) bewerben. Wenn Sie eine API für GraphQL über eine Pipeline bereitstellen, werden nur die API-Metadaten kopiert – einschließlich Schemadefinitionen, Datenquellenverbindungen und Beziehungskonfigurationen. Die tatsächlichen Daten verbleiben in den verbundenen Datenquellen und werden während der Bereitstellung nicht kopiert.
Wichtige Überlegungen zur Bereitstellung:
Verstehen Sie vor der Bereitstellung, wie sich Authentifizierungsmethoden und Arbeitsbereichsorganisation auf Ihre Bereitstellung auswirken:
- APIs mit single Sign-On (SSO) können automatisch an lokale Datenquellen im Zielarbeitsbereich gebunden werden (wenn die Datenquelle auch aus demselben Quellarbeitsbereich bereitgestellt wurde)
- APIs mit gespeicherten Anmeldeinformationen werden nicht automatisch gebunden und bleiben mit der Datenquelle des Quellarbeitsbereichs verbunden.
- Arbeitsbereichübergreifende Datenquellen werden unabhängig von der Authentifizierungsmethode niemals automatisch gebunden
Ein umfassendes Verständnis des Bereitstellungsprozesses finden Sie unter Grundlegendes zum Bereitstellungsprozess.
Bereitstellen Ihrer API für GraphQL
So stellen Sie Ihre API für GraphQL mithilfe von Bereitstellungspipelines bereit:
Erstellen Sie eine neue Bereitstellungspipeline, oder öffnen Sie eine vorhandene. Ausführliche Anweisungen finden Sie unter "Erste Schritte mit Bereitstellungspipelines".
Weisen Sie arbeitsbereiche den Pipelinephasen (Entwicklung, Test, Produktion) basierend auf Ihrer Bereitstellungsstrategie zu. Jede Phase sollte über einen dedizierten Arbeitsbereich verfügen.
Überprüfen und Vergleichen von Elementen zwischen Phasen Die Pipeline zeigt an, welche APIs für GraphQL sich geändert haben, angegeben durch die Elementanzahl in den hervorgehobenen Bereichen. Dieser Vergleich hilft Ihnen zu verstehen, was von der Bereitstellung betroffen ist.
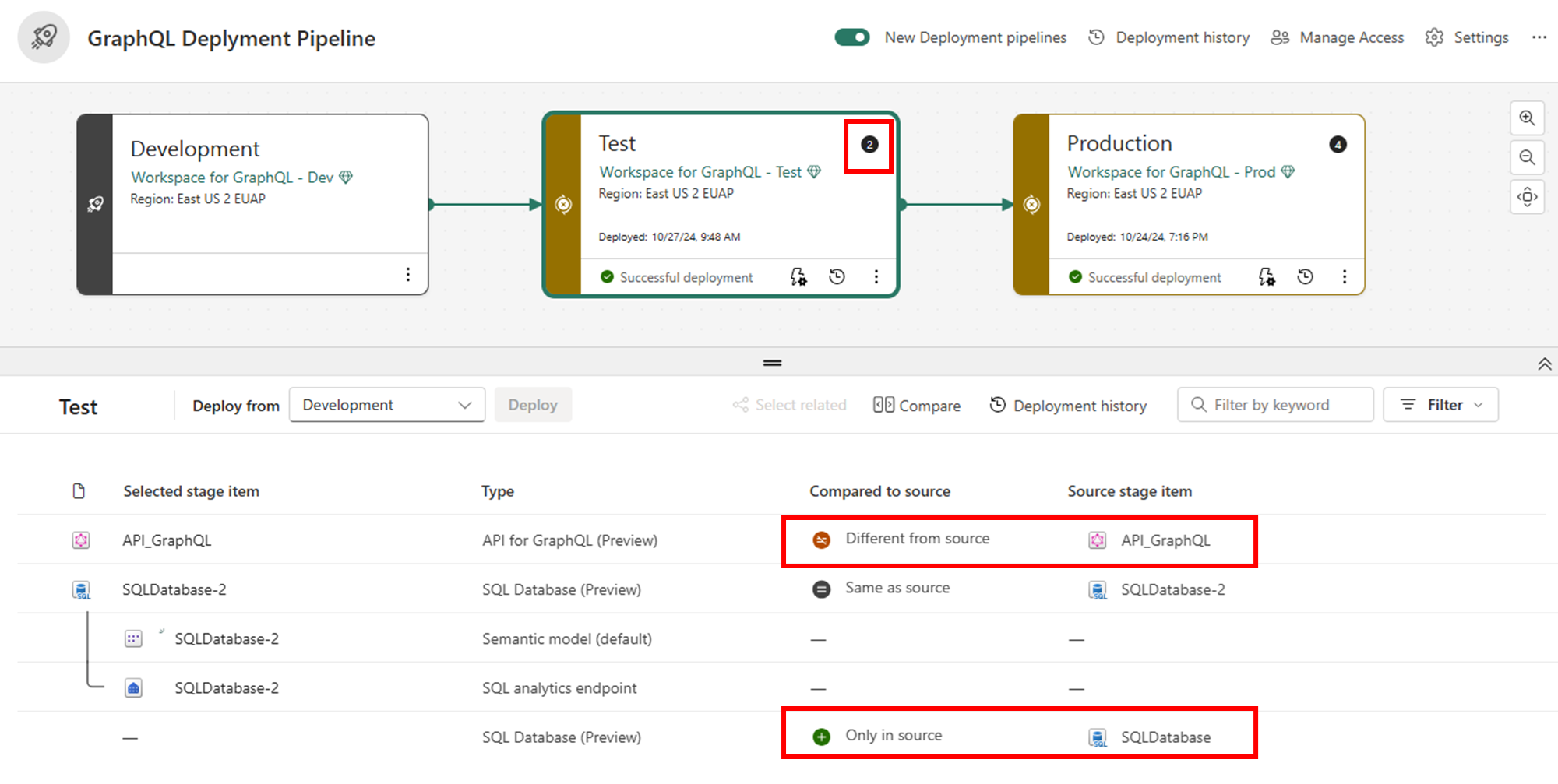
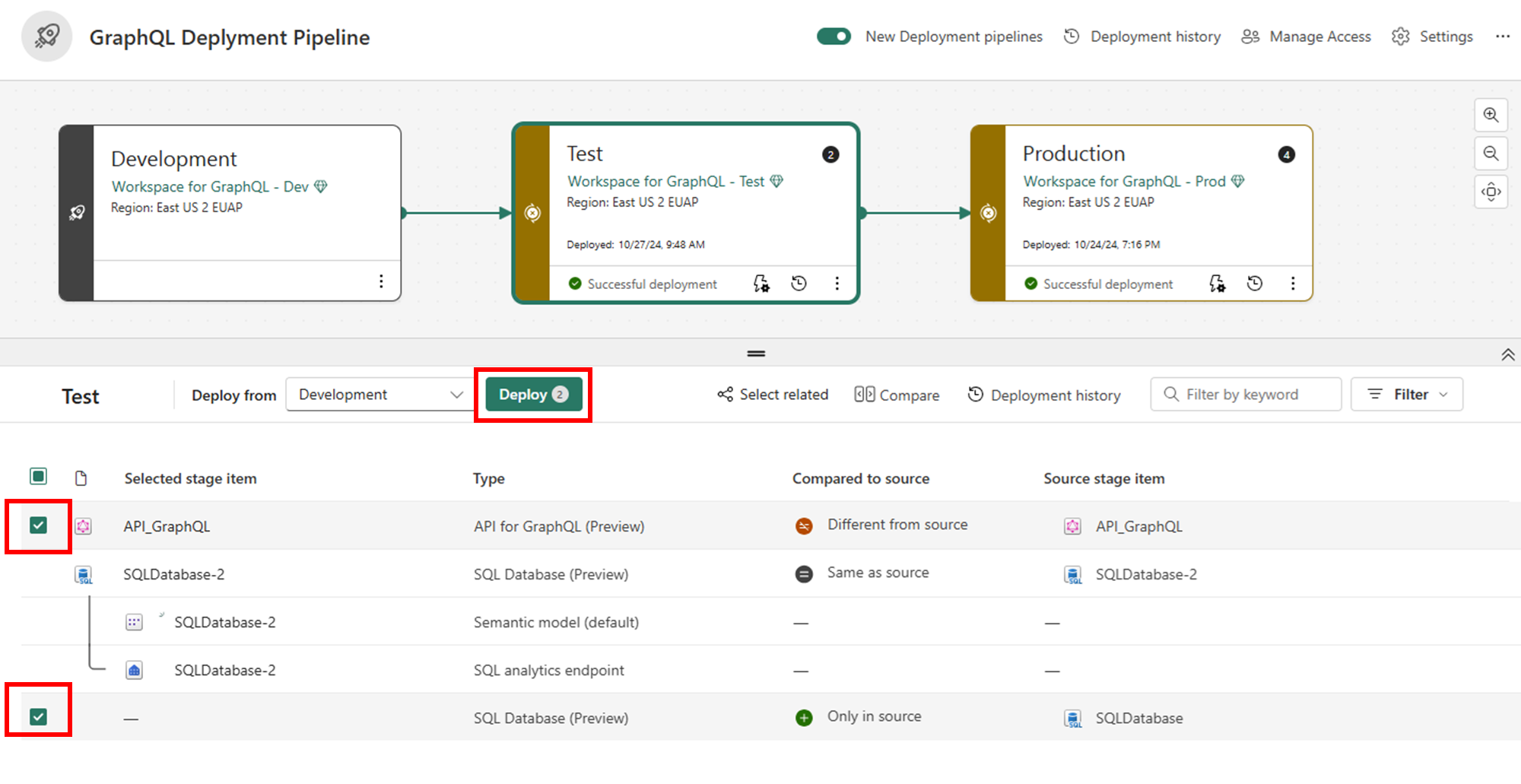
Wählen Sie die APIs für GraphQL und alle verwandten Elemente (z. B. verbundene Datenquellen) aus, die Sie bereitstellen möchten. Wählen Sie dann "Bereitstellen" aus, um sie in die nächste Phase zu verschieben.
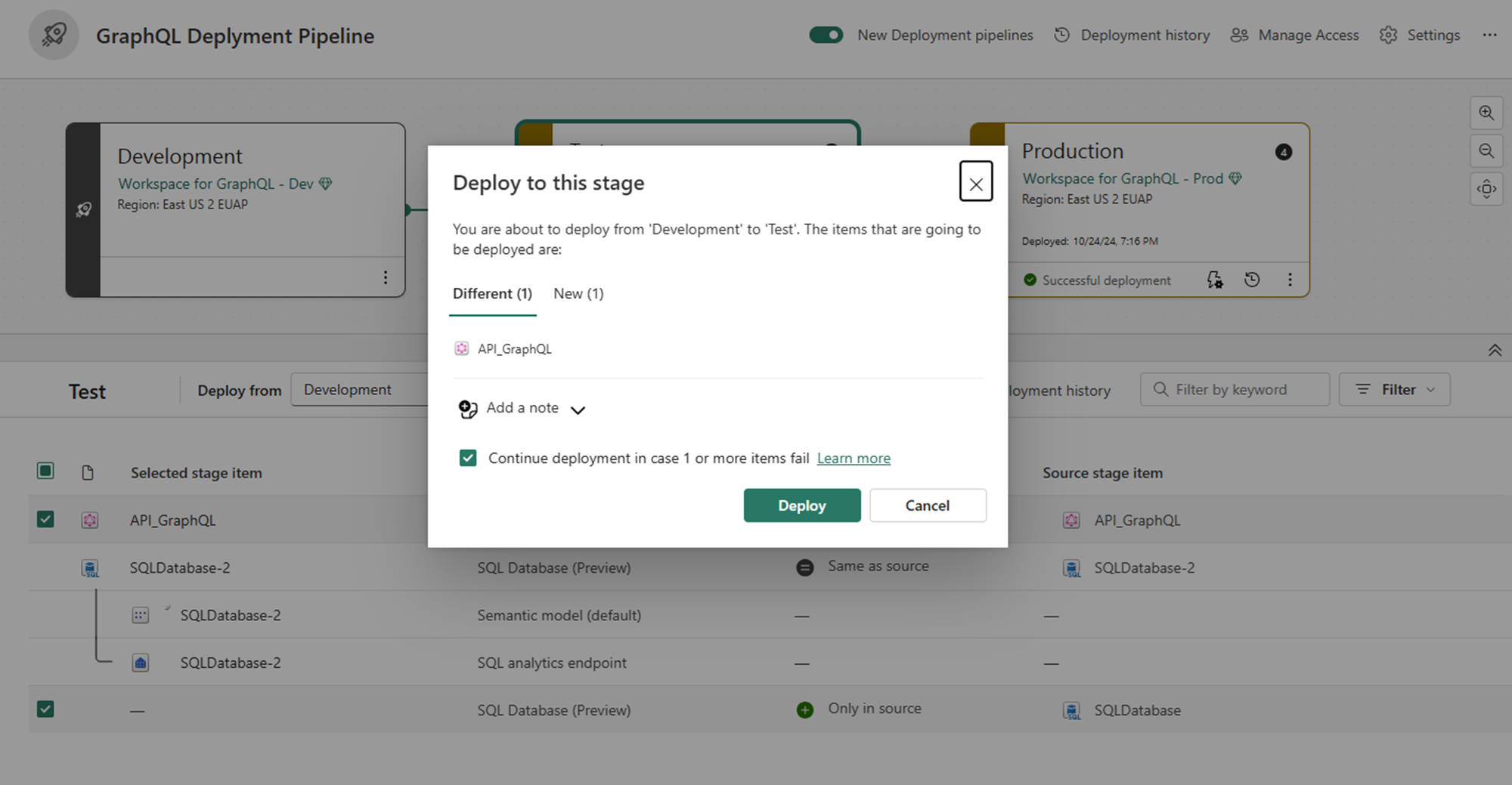
Überprüfen Sie das Bestätigungsdialogfeld für die Bereitstellung, in dem alle Elemente angezeigt werden, die bereitgestellt werden sollen. Wählen Sie "Bereitstellen" aus, um fortzufahren.



Aktuelle Einschränkungen
Bei der Bereitstellung von APIs für GraphQL über Bereitstellungspipelines weist die automatische Bindung die folgenden Einschränkungen auf:
Untergeordnete Elemente: Die automatische Bindung funktioniert nicht, wenn die API eine Verbindung mit einem SQL Analytics-Endpunkt herstellt, der ein untergeordnetes Element einer übergeordneten Datenquelle ist (z. B. ein Lakehouse). Die bereitgestellte API bleibt mit dem Endpunkt des Quellarbeitsbereichs verbunden.
Gespeicherte Anmeldeinformationen: APIs mit der Authentifizierungsmethode "Gespeicherte Anmeldeinformationen" unterstützen keine automatische Bindung. Die API bleibt nach der Bereitstellung mit der Datenquelle des Quellarbeitsbereichs verbunden.
Ausführliche Informationen zu Authentifizierungsmethoden und dem automatischen Bindungsverhalten finden Sie unter Datenquellenauthentifizierungsmethoden.