Automatische Aggregationen
Automatische Aggregationen verwenden maschinelles Lernen (ML) auf dem neuesten Stand, um DirectQuery-Semantikmodelle kontinuierlich zu optimieren, damit eine maximale Berichtsabfrageleistung erreicht wird. Automatische Aggregationen bauen auf der vorhandenen Infrastruktur für benutzerdefinierte Aggregationen auf, die zuerst im Zusammenhang mit zusammengesetzten Modellen für Power BI eingeführt wurde. Im Gegensatz zu benutzerdefinierten Aggregationen sind zur Konfiguration und Verwaltung automatischer Aggregationen keine umfassenden Kenntnisse in Datenmodellierung und Abfrageoptimierung erforderlich. Automatische Aggregationen sind sowohl selbsttrainierend als auch selbstoptimierend. Mit ihnen können Modellbesitzer aller Qualifikationsstufen die Abfrageleistung verbessern und so selbst für sehr große Semantikmodelle schnellere Berichtsvisualisierungen erzielen.
Automatische Aggregationen bieten diese Vorteile:
- Berichtsvisualisierungen erfolgen schneller: Ein optimaler Prozentsatz der Berichtsabfragen wird von einem automatisch verwalteten In-Memory-Aggregationscache anstelle von Back-End-Datenquellensystemen zurückgegeben. Ausreißerabfragen, die nicht vom In-Memory-Cache zurückgegeben werden, werden mithilfe von DirectQuery direkt an die Datenquelle übergeben.
- Ausgeglichene Architektur: Im Vergleich zum reinen DirectQuery-Modus werden die meisten Abfrageergebnisse von der Power BI-Abfrage-Engine und dem In-Memory-Aggregationscache zurückgegeben. Die Abfrageverarbeitungslast auf Datenquellensystemen zu Spitzenzeiten der Berichterstellung kann erheblich reduziert werden, was eine höhere Skalierbarkeit im Datenquellen-Back-End mit sich bringt.
- Einfache Einrichtung: Semantikmodellbesitzer können das Training automatischer Aggregationen aktivieren und Aktualisierungen für das Semantikmodell planen. Mit dem ersten Training und der ersten Aktualisierung beginnen automatische Aggregationen damit, ein Aggregationsframework und optimale Aggregationen zu erstellen. Das System stimmt sich im Lauf der Zeit automatisch selbst ab.
- Feinabstimmung: Mit einer einfachen und intuitiven Benutzeroberfläche in den Modelleinstellungen können Sie die Leistungssteigerungen abschätzen, die sich ergeben, wenn ein anderer Prozentsatz der Abfragen aus dem In-Memory-Cache für Aggregationen zurückgegeben wird, und Anpassungen vornehmen, um noch größere Vorteile zu erzielen. Mithilfe eines einfachen Schiebeleisten-Steuerelements können Sie die Feinabstimmung Ihrer Umgebung komfortabel vornehmen.
Anforderungen
Unterstützte Pläne
Automatische Aggregationen werden für Power BI Premium nach Kapazität-, Premium-Einzelelbenutzerlizenzen- und Power BI Embedded-Modellen unterstützt.
Unterstützte Datenquellen
Automatische Aggregationen werden für die folgenden Datenquellen unterstützt:
- Azure SQL-Datenbank
- Azure Synapse Dedicated SQL-Pool
- SQL Server 2019 oder höher
- Google BigQuery
- Snowflake
- Databricks
- Amazon Redshift
Unterstützte Modi
Automatische Aggregationen werden für Modelle im DirectQuery-Modus unterstützt. Modelle mit zusammengesetzten Modellen, die sowohl Importtabellen als auch DirectQuery-Verbindungen beinhalten, werden unterstützt. Automatische Aggregationen werden nur für die DirectQuery-Verbindung unterstützt.
Berechtigungen
Zum Aktivieren und Konfigurieren automatischer Aggregationen müssen Sie der Besitzer des Modells sein. Arbeitsbereichsadministratoren können als Besitzer übernehmen, um Einstellungen für automatische Aggregationen zu konfigurieren.
Konfigurieren automatischer Aggregationen
Automatische Aggregationen werden in den Modelleinstellungen konfiguriert. Die Konfiguration ist einfach: Aktivieren Sie das automatische Training der Aggregationen, und planen Sie eine oder mehrere Aktualisierungen. Bevor Sie jedoch automatische Aggregationen für Ihr Modell konfigurieren, lesen Sie diesen Artikel unbedingt vollständig durch. Er vermittelt ein gutes Verständnis der Funktionsweise von automatischen Aggregationen und kann Sie bei der Entscheidung unterstützen, ob automatische Aggregationen in Ihrer Umgebung sinnvoll sind. Wenn Sie für Schritt-für-Schritt-Anweisungen zum Aktivieren des Trainings automatischer Aggregationen, Konfigurieren eines Aktualisierungszeitplans und Optimieren ihrer Umgebung bereit sind, finden Sie weitere Informationen unter Konfigurieren von automatischen Aggregationen.
Vorteile
Bei DirectQuery werden DAX-Abfragen (Data Analysys Expressions, Datenanalyseausdrücke) jedes Mal, wenn ein Modellbenutzer einen Bericht öffnet oder mit einer Berichtsvisualisierung interagiert, an die Abfrage-Engine und dann in Form von SQL-Abfragen an die Back-End-Datenquelle übergeben. Die Datenquelle muss die Ergebnisse für jede Abfrage berechnen und zurückgeben. Im Vergleich zu Modellen im Importmodus, die im Arbeitsspeicher gespeichert sind, können DirectQuery-Roundtrips von Datenquellen zeit- und prozessintensiv sein, was oftmals zu langen Abfrageantwortzeiten in Berichtsvisualisierungen führt.
Wenn sie für ein DirectQuery-Modell aktiviert sind, können automatische Aggregationen die Leistung von Berichtsabfragen durch Vermeidung von Abfrageroundtrips zu Datenquellen steigern. Vorab aggregierte Abfrageergebnisse werden automatisch von einem In-Memory-Aggregationscache zurückgegeben, statt an die Datenquelle gesendet und von ihr zurückgegeben zu werden. Die Menge der vorab aggregierten Daten im In-Memory-Aggregationscache ist ein kleiner Bruchteil der Menge an Daten, die in Fakten- und Detailtabellen in der Datenquelle gespeichert sind. Das Ergebnis ist nicht nur eine bessere Leistung bei der Berichtsabfrage, sondern auch eine verringerte Last auf den Back-End-Datenquellensystemen. Bei automatischen Aggregationen wird nur ein kleiner Teil der Berichts- und Ad-hoc-Abfragen, für die Aggregationen erforderlich sind, die nicht im In-Memory-Cache enthalten sind, wie im reinen DirectQuery-Modus an die Back-End-Datenquelle übergeben.
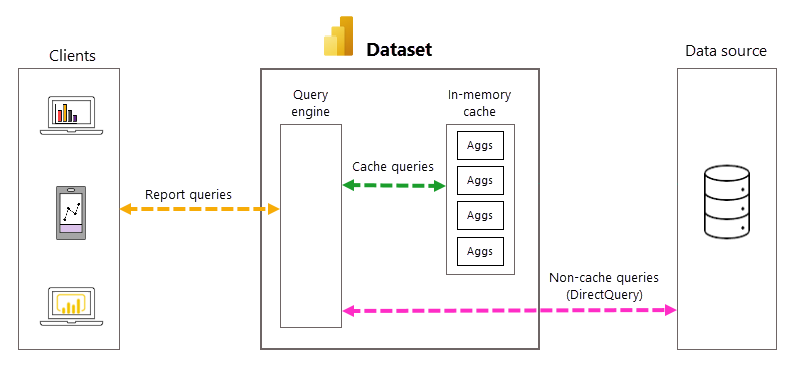
Verwaltung von automatischen Abfragen und Aggregationen
Zwar entfällt mit automatischen Aggregationen die Notwendigkeit, benutzerdefinierte Aggregationstabellen zu erstellen, und die Implementierung einer vorab aggregierten Datenlösung wird erheblich vereinfacht, trotzdem ist eine tiefere Kenntnis der zugrunde liegenden Prozesse und Abhängigkeiten hilfreich, um zu verstehen, wie automatische Aggregationen funktionieren. Power BI verwendet bei Erstellung und Verwaltung automatischer Aggregationen die folgenden Mechanismen.
Abfrageprotokoll
Power BI verfolgt Modell- und Benutzerberichtsabfragen in einem Abfrageprotokoll nach. Für jedes Modell bewahrt Power BI die Abfrageprotokolldaten sieben Tage lang auf. Für Abfrageprotokolldaten wird jeden Tag ein Roll Forward ausgeführt. Das Abfrageprotokoll ist sicher und weder für Benutzer noch über den XMLA-Endpunkt sichtbar.
Trainingsvorgänge
Im Rahmen des ersten geplanten Modellaktualisierungsvorgangs für die von Ihnen gewählte Häufigkeit (Tag oder Woche) leitet Power BI zunächst einen Trainingsvorgang ein, der das Abfrageprotokoll auswertet, um sicherzustellen, dass sich Aggregationen im In-Memory-Aggregationscache an die wechselnden Abfragemuster anpassen. In-Memory-Aggregationstabellen werden erstellt, aktualisiert oder gelöscht, und besondere Abfragen werden an die Datenquelle gesendet, um die Aggregationen zu bestimmen, die in den Cache aufgenommen werden sollen. Berechnete Aggregationsdaten werden jedoch nicht während des Trainings in den In-Memory-Cache geladen, sondern während des anschließenden Aktualisierungsvorganges.
Wenn Sie z. B. eine tägliche Häufigkeit auswählen und Aktualisierungen um 4:00 Uhr, 9:00 Uhr, 14:00 Uhr und 19:00 Uhr planen, enthält nur die tägliche Aktualisierung um 4:00 Uhr sowohl einen Trainingsvorgang als auch einen Aktualisierungsvorgang. Die nachfolgenden geplanten Aktualisierungen für den betreffenden Tag um 9:00 Uhr, 14:00 Uhr und 19:00 Uhr sind reine Aktualisierungsvorgänge zur Aktualisierung der vorhandenen Aggregationen im Cache.
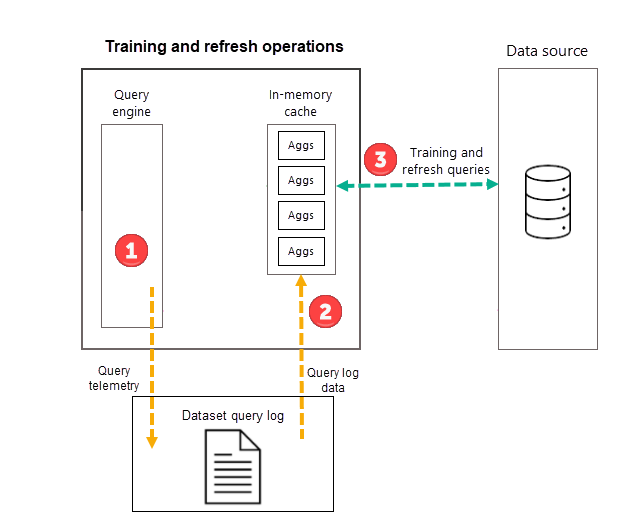
Zwar werten Trainingsvorgänge frühere Abfragen aus dem Abfrageprotokoll aus, die Ergebnisse sind aber hinreichend genau, um sicherzustellen, dass zukünftige Abfragen abgedeckt werden. Es gibt jedoch keine Gewissheit, dass zukünftige Abfragen vom In-Memory-Aggregationscache zurückgegeben werden, da sich diese neuen Abfragen von den aus dem Abfrageprotokoll abgeleiteten Abfragen unterscheiden können. Diese Abfragen, die nicht vom In-Memory-Aggregationscache zurückgegeben werden, werden mithilfe von DirectQuery an die Datenquelle übergeben. Je nach Häufigkeit und Rangfolge dieser neuen Abfragen können ihre Aggregationen mit dem nächsten Trainingsvorgang in den In-Memory-Aggregationscache aufgenommen werden.
Für den Trainingsvorgang gilt ein Zeitlimit von 60 Minuten. Wenn das Training nicht in der Lage ist, das gesamte Abfrageprotokoll innerhalb des Zeitlimits zu verarbeiten, wird eine Benachrichtigung im Aktualisierungsverlauf des Modells protokolliert und das Training wird beim nächsten Start fortgesetzt. Der Trainingszyklus ist abgeschlossen und ersetzt die vorhandenen automatischen Aggregationen, wenn das gesamte Abfrageprotokoll verarbeitet ist.
Aktualisierungsvorgänge
Wie bereits beschrieben, führt Power BI nach Abschluss des Trainingsvorgangs im Rahmen der ersten geplanten Aktualisierung für die von Ihnen gewählte Häufigkeit einen Aktualisierungsvorgang aus, der neue und aktualisierte Aggregationsdaten abfragt und in den In-Memory-Aggregationscache lädt sowie alle Aggregationen entfernt, deren Rang (nach Maßgabe des Trainingsalgorithmus) nicht mehr hoch genug ist. Alle nachfolgenden Aktualisierungen für die gewählte Häufigkeit „Tag“ oder „Woche“ sind reine Aktualisierungsvorgänge, die die Datenquelle abfragen, um vorhandene Aggregationsdaten im Cache zu aktualisieren. Gemäß unseres vorigen Beispiels sind die geplanten Aktualisierungen für diesen Tag um 9:00 Uhr, 14:00 Uhr und 19:00 Uhr reine Aktualisierungsvorgänge.
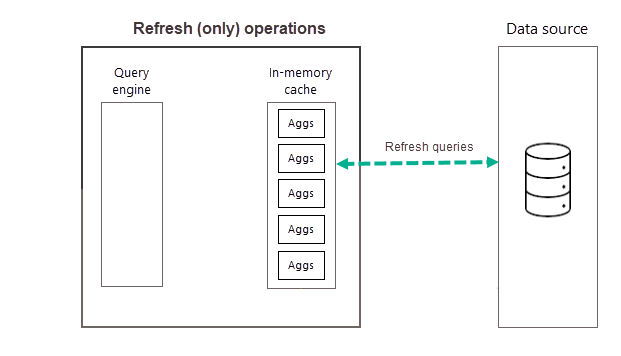
Mithilfe geplanter regelmäßiger Aktualisierungen während des Tages (oder der Woche) wird sichergestellt, dass die Aggregationsdaten im Cache bezogen auf die Daten in der Back-End-Datenquelle eine bessere Aktualität aufweisen. Über die Modell-Einstellungen können Sie bis zu 48 Aktualisierungen pro Tag planen, um sicherzustellen, dass Berichtsabfragen, die vom Aggregationscache zurückgegeben werden, Ergebnisse auf der Grundlage der neuesten aus der Back-End-Datenquelle aktualisierten Daten erhalten.
Achtung
Trainings- und Aktualisierungsvorgänge sind sowohl für den Power BI-Dienst als auch für die Datenquellensysteme prozess- und ressourcenintensiv. Wird der Prozentsatz an Abfragen heraufgesetzt, die Aggregationen verwenden, müssen in Trainings- und Aktualisierungsvorgängen mehr Aggregationen bei Datenquellen abgefragt und berechnet werden, wodurch die Wahrscheinlichkeit steigt, dass Systemressourcen übermäßig genutzt werden und Timeouts auftreten. Weitere Informationen finden Sie unter Feinabstimmung.
Training nach Bedarf
Wie bereits erwähnt, kann es vorkommen, dass ein Trainingszyklus nicht innerhalb der Zeitgrenzen eines einzelnen Datenaktualisierungszyklus abgeschlossen wird. Wenn Sie nicht bis zum nächsten geplanten Aktualisierungszyklus warten möchten, der ein Training einbezieht, können Sie auch ein Training für automatische Aggregationen bei Bedarf auslösen, indem Sie in den Modelleinstellungen Jetzt trainieren und aktualisieren auswählen. Wenn Sie Jetzt trainieren und aktualisieren verwenden, wird sowohl ein Training als auch ein Aktualisierungsvorgang ausgelöst. Überprüfen Sie den Aktualisierungsverlauf des Modells, um festzustellen, ob der aktuelle Vorgang abgeschlossen ist, bevor Sie bei Bedarf einen weiteren Trainings- und Aktualisierungsvorgang ausführen.
Verlauf aktualisieren
Jeder Aktualisierungsvorgang wird im Aktualisierungsverlauf des Modells aufgezeichnet. Hier werden wichtige Informationen zu jeder Aktualisierung angezeigt, darunter die Menge des Arbeitsspeichers, der für Aggregationen im Cache für den konfigurierten Abfrageprozentsatz genutzt wird. Wählen Sie zum Anzeigen des Aktualisierungsverlaufs auf der Seite „Einstellungen“ des Modells Verlauf aktualisieren aus. Wenn Sie einen noch etwas tieferen Drilldown ausführen möchten, wählen Sie Details anzeigen aus.
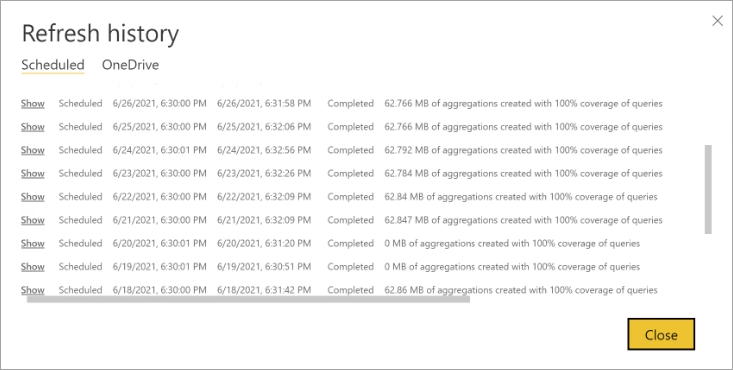
Durch regelmäßiges Überprüfen des Aktualisierungsverlaufs können Sie sicherstellen, dass ihre geplanten Aktualisierungsvorgänge innerhalb eines akzeptablen Zeitraums abgeschlossen werden. Achten Sie darauf, dass Aktualisierungsvorgänge vor dem Beginn der nächsten geplanten Aktualisierung erfolgreich abgeschlossen werden.
Trainings- und Aktualisierungsfehler
Zwar führt Power BI Trainings- und Aktualisierungsvorgänge im Rahmen der ersten geplanten Aktualisierung für die gewählte tägliche oder wöchentliche Häufigkeit aus, diese Vorgänge sind aber als separate Transaktionen implementiert. Wenn ein Trainingsvorgang das Abfrageprotokoll innerhalb seiner Zeitgrenzen nicht vollständig verarbeiten kann, fährt Power BI damit fort, die vorhandenen Aggregationen (und regulären Tabellen in einem zusammengesetzten Modell) zu aktualisieren, indem es den vorherigen Trainingszustand verwendet. In diesem Fall zeigt der Aktualisierungsverlauf an, dass die Aktualisierung erfolgreich war und das Training mit der Verarbeitung des Abfrageprotokolls fortgesetzt wird, wenn das Training das nächste Mal startet. Die Abfrageleistung könnte weniger optimiert sein, wenn sich die Abfragemuster der Clientberichte ändern und die Aggregationen noch nicht angepasst wurden, aber das erreichte Leistungsniveau sollte immer noch weitaus besser sein als ein reines DirectQuery-Modell ohne Aggregationen.
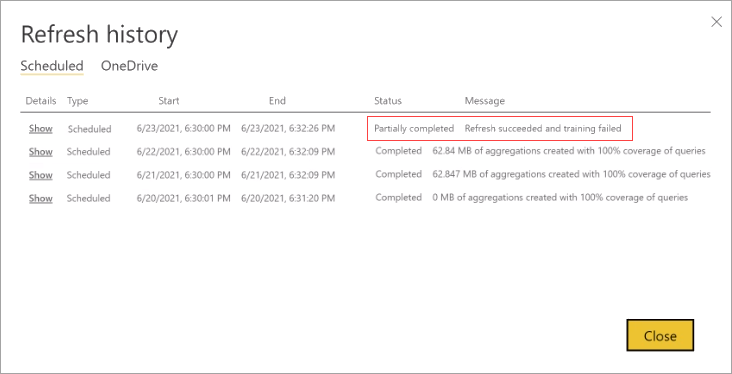
Wenn ein Trainingsvorgang zu viele Zyklen benötigt, um die Verarbeitung des Abfrageprotokolls abzuschließen, sollten Sie den Prozentsatz der Abfragen, die den In-Memory-Aggregationscache verwenden, in den Modelleinstellungen reduzieren. Dadurch verringert sich die Anzahl der im Cache erstellten Aggregationen, lässt aber mehr Zeit für den Abschluss von Trainings- und Aktualisierungsvorgängen. Weitere Informationen finden Sie unter Feinabstimmung.
Wenn das Training erfolgreich ist, bei der Aktualisierung jedoch Fehler auftreten, wird die gesamte Aktualisierung als Fehler markiert, da das Ergebnis ein nicht verfügbarer In-Memory-Aggregationscache ist.
Beim Planen der Aktualisierung können Sie festlegen, dass Sie bei Aktualisierungsfehlern E-Mail-Benachrichtigungen erhalten.
Benutzerdefinierte und automatische Aggregationen
Benutzerdefinierte Aggregationen in Power BI können manuell auf der Grundlage verborgener aggregierter Tabellen im Modell konfiguriert werden. Das Konfigurieren benutzerdefinierter Aggregationen ist oftmals komplex und erfordert einen höheren Kenntnisgrad in den Bereichen Datenmodellierung und Abfrageoptimierung. Demgegenüber entfällt bei automatischen Aggregationen als Teil eines KI-gestützten Systems diese Komplexität. Im Gegensatz zu benutzerdefinierten Aggregationen, die statisch bleiben, verwaltet Power BI Abfrageprotokolle kontinuierlich und bestimmt aus diesen Protokollen Abfragemuster, ausgehend von Machine Learning-Algorithmen zur Vorhersagemodellierung. Vorab aggregierte Daten werden auf der Grundlage der Abfragemusteranalyse berechnet und im Arbeitsspeicher gespeichert. Mit automatischen Aggregationen sind Modelle sowohl selbsttrainierend als auch selbstoptimierend. Wenn sich Abfragemuster für Clientberichte ändern, passen sich automatische Aggregationen an; dabei werden besonders häufig verwendete Aggregationen priorisiert und zwischengespeichert.
Da automatische Aggregationen auf der vorhandenen Infrastruktur für benutzerdefinierte Aggregationen aufbauen, ist es möglich, im gleichen Modell sowohl benutzerdefinierte als auch automatische Aggregationen zu verwenden. Erfahrene Datenmodellierer können Aggregationen für Tabellen mithilfe der Modi DirectQuery, Import (mit oder ohne inkrementelle Aktualisierung) oder dualer Speichermodus definieren und zugleich die Vorteile von stärker automatisierten Aggregationen für Abfragen über DirectQuery-Verbindungen nutzen, für die die benutzerdefinierten Aggregationstabellen nicht in Anspruch genommen werden. Diese Flexibilität ermöglicht ausgeglichene Architekturen mit verringerten Abfragelasten zur Vermeidung von Leistungsengpässen.
Vom Trainingsalgorithmus für automatische Aggregationen im Arbeitsspeichercache erstellte Aggregationen werden als System-Aggregationen bezeichnet. Der Trainingsalgorithmus erstellt und löscht beim Analysieren von Berichterstellungsabfragen und Vornehmen von Anpassungen zum Aufrechterhalten der optimalen Aggregationen für das Modell nur diese System-Aggregationen. Bei einer Aktualisierung werden sowohl benutzerdefinierte als auch automatische Aggregationen aktualisiert. Nur die Aggregationen, die durch automatische Aggregationen erstellt und als vom System generierte Aggregationen gekennzeichnet wurden, sind in die automatische Aggregationsverarbeitung eingeschlossen.
Zwischenspeichern von Abfragen und automatische Aggregationen
Power BI Premium unterstützt zur Verwaltung von Abfrageergebnissen darüber hinaus das Zwischenspeichern von Abfragen in Power BI Premium/Embedded. Das Zwischenspeichern von Abfragen ist ein anderes Feature als automatische Aggregationen. Beim Zwischenspeichern von Abfragen verwendet Power BI Premium seinen lokalen Cachedienst zum Implementieren der Zwischenspeicherung, während automatische Aggregationen auf Modellebene implementiert werden. Beim Zwischenspeichern von Abfragen erfolgt durch den Dienst nur für das anfängliche Laden der Berichtsseite eine Zwischenspeicherung der Abfragen, daher wird die Abfrageleistung nicht verbessert, wenn Benutzer mit einem Bericht interagieren. Im Gegensatz dazu optimieren automatische Aggregationen die meisten Berichtsabfragen, indem aggregierte Abfrageergebnisse vorab zwischenspeichert werden, einschließlich der Abfragen, die bei der Interaktion von Benutzern mit Berichten generiert werden. Das Zwischenspeichern von Abfragen und die automatischen Aggregationen können für ein Modell beide aktiviert werden, das ist aber wahrscheinlich nicht erforderlich.
Einrichten und Verwenden von Log Analytics (Operations Management Suite) mit einer mehrinstanzenfähigen SaaS-App für SQL-Datenbank
Azure Log Analytics (LA) ist ein Dienst in Azure Monitor, der von Power BI zum Speichern von Aktivitätsprotokollen verwendet werden kann. Mit der Azure Monitor-Suite können Sie Telemetriedaten aus Azure und lokalen Umgebungen sammeln, analysieren und verarbeiten. Der Dienst bietet langfristigen Speicher, eine Ad-hoc-Abfrageoberfläche und API-Zugriff für Datenexporte und die Integration mit anderen Systemen. Weitere Informationen finden Sie unter Verwenden von Azure Log Analytics in Power BI.
Wenn Power BI mit einem Azure LA-Konto konfiguriert ist, wie unter Konfigurieren von Azure Log Analytics für Power BI beschrieben, können Sie die Erfolgsrate Ihrer automatischen Aggregationen analysieren. Unter anderem können Sie feststellen, ob Berichtsabfragen aus dem In-Memory-Cache beantwortet werden.
Wenn Sie diese Funktion nutzen möchten, laden Sie die PBIT-Vorlage herunter und verbinden sie mit Ihrem Log Analytics-Konto, wie in diesem Power BI-Blogbeitrag beschrieben. Im Bericht können Sie Daten auf drei verschiedenen Ebenen anzeigen: Zusammenfassungsansicht, DAX-Abfrageebenenansicht und SQL-Sicht auf Abfrageebene.
Die folgende Abbildung zeigt die Zusammenfassungsseite für alle Abfragen. Wie Sie sehen können, ist im markierten Diagramm der Prozentsatz aller Abfragen dargestellt, die mithilfe von Aggregationen beantwortet wurden, gegenüber den Abfragen, für die die Datenquelle verwendet werden musste.
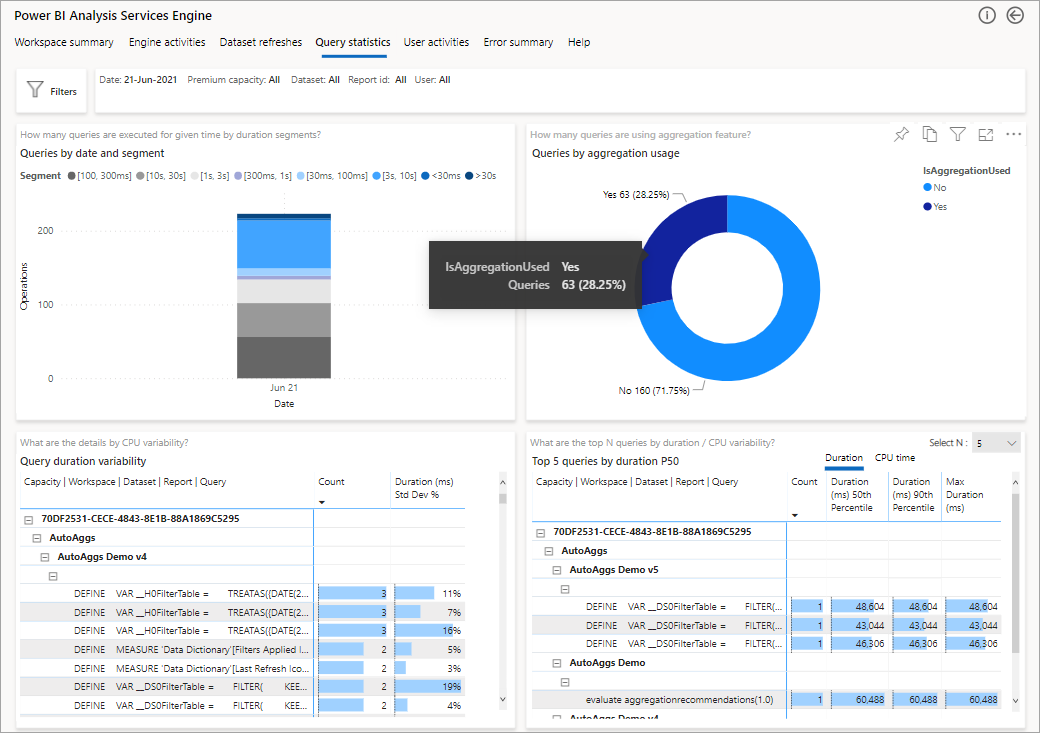
Der nächste Schritt zu einem tieferen Verständnis ist ein Blick auf die Verwendung von Aggregationen auf einer DAX-Abfrageebene. Klicken Sie mit der rechten Maustaste auf eine DAX-Abfrage in der Liste (unten links) >Drillthrough>Abfrageverlauf.
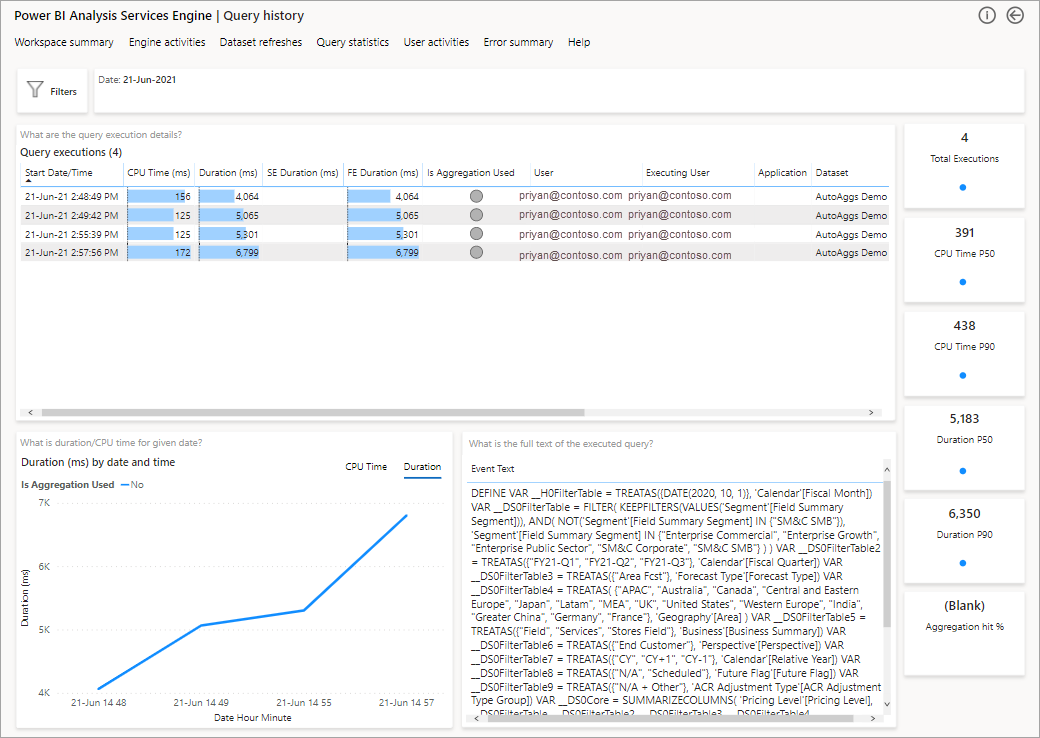
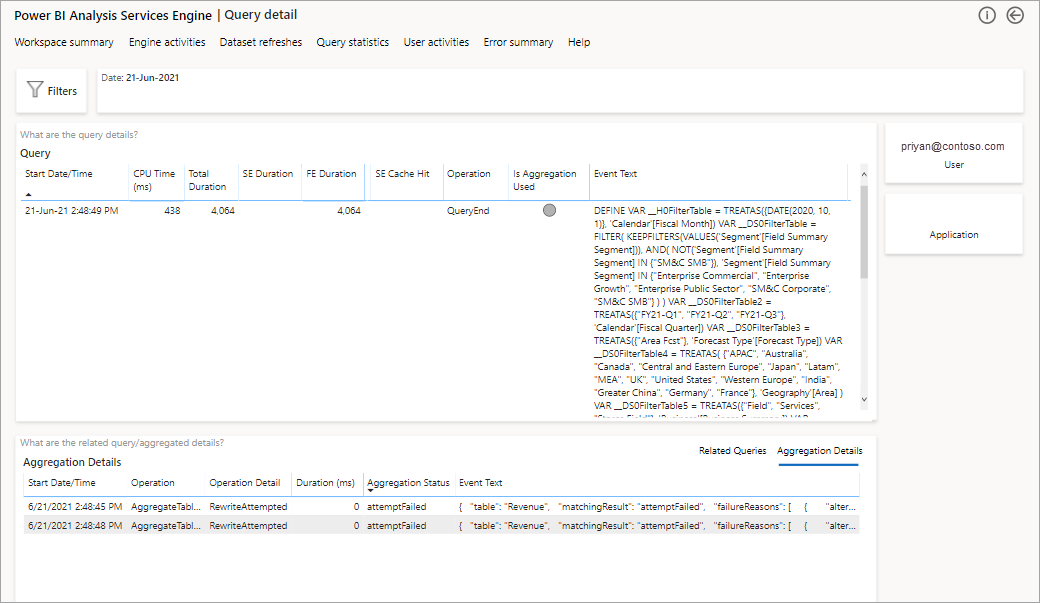
Dadurch erhalten Sie eine Liste aller relevanten Abfragen. Führen Sie einen Drillthrough zur nächsten Ebene aus, um weitere Aggregationsdetails anzuzeigen.
Anwendungslebenszyklusverwaltung
Von der Entwicklung zum Testen und vom Testen bis zur Produktion gelten für Modelle mit aktivierten automatischen Aggregationen besondere Anforderungen an ALM-Lösungen.
Bereitstellungspipelines
Mit Bereitstellungspipelines kann Power BI die Modelle mit ihrer Modellkonfiguration aus der aktuellen Phase in die Zielphase kopieren. Automatische Aggregationen müssen jedoch in der Zielphase zurückgesetzt werden, da die Einstellungen nicht aus der aktuellen in die Zielphase übertragen werden. Sie können Inhalte auch programmgesteuert bereitstellen, indem Sie die REST-APIs für Bereitstellungspipelines verwenden. Weitere Informationen zu diesem Vorgang finden Sie unter Automatisieren Ihrer Bereitstellungspipeline mit APIs und DevOps.
Benutzerdefinierte ALM-Lösungen
Wenn Sie eine benutzerdefinierte ALM-Lösung verwenden, die auf XMLA-Endpunkten basiert, denken Sie daran, dass Ihre Lösung möglicherweise in der Lage ist, als Teil der Modellmetadaten vom System generierte und vom Benutzer erstellte Aggregationstabellen zu kopieren. Sie müssen automatische Aggregationen jedoch nach jedem Bereitstellungsschritt manuell in der Zielphase aktivieren. Power BI behält die Konfiguration bei, wenn Sie ein vorhandenes Modell überschreiben.
Hinweis
Wenn Sie ein Modell als Teil einer Power BI Desktop-Datei (PBIX) hochladen oder erneut veröffentlichen, gehen vom System erstellte Aggregationstabellen verloren, da Power BI das vorhandene Modell durch alle seine Metadaten und Daten im Zielarbeitsbereich ersetzt.
Ändern eines Modells
Nach dem Ändern eines Modells mit automatischen Aggregationen, die über XMLA-Endpunkte aktiviert sind, z. B. beim Hinzufügen oder Entfernen von Tabellen, behält Power BI alle eventuell vorhandenen Aggregationen bei und entfernt Aggregationen, die nicht mehr benötigt werden oder relevant sind. Die Abfrageleistung kann bis zum Auslösen der nächsten Trainingsphase beeinträchtigt sein.
Metadatenelemente
Modelle mit aktivierten automatischen Aggregationen enthalten eindeutige vom System generierte Aggregationstabellen. Aggregationstabellen sind für Benutzer in Berichtstools nicht sichtbar. Sie sind über den XMLA-Endpunkt mithilfe von Tools mit den Analysis Services-Clientbibliotheken, Version 19.22.5 und höher, sichtbar. Wenn Sie mit Modellen mit aktivierten automatischen Aggregationen arbeiten, achten Sie darauf, Ihre Datenmodellierungs- und Verwaltungstools auf die neueste Version der Clientbibliotheken zu aktualisieren. Führen Sie für SQL Server Management Studio (SSMS) ein Upgrade auf die SSMS-Version 18.9.2 oder höher durch. Mit früheren Versionen von SSMS ist keine Enumeration von Tabellen und kein Outscripting dieser Modelle möglich.
Automatische Aggregationstabellen werden durch eine Tabelleneigenschaft SystemManaged identifiziert, die im TOM (Tabular Object Model, Tabellenobjektmodell) in den Analysis Services-Clientbibliotheken, Version 19.22.5 und höher, neu eingeführt wurde. Wie im folgenden Codeausschnitt gezeigt, wird die SystemManaged-Eigenschaft für automatische Aggregationstabellen auf true und für reguläre Tabellen auf false festgelegt.
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AnalysisServices.Tabular;
namespace AutoAggs
{
class Program
{
static void Main(string[] args)
{
string workspaceUri = "<Specify the URL of the workspace where your model resides>";
string datasetName = "<Specify the name of your dataset>";
Server sourceWorkspace = new Server();
sourceWorkspace.Connect(workspaceUri);
Database dataset = sourceWorkspace.Databases.GetByName(datasetName);
// Enumerate system-managed tables.
IEnumerable<Table> aggregationsTables = dataset.Model.Tables.Where(tbl => tbl.SystemManaged == true);
if (aggregationsTables.Any())
{
Console.WriteLine("The following auto aggs tables exist in this dataset:");
foreach (Table table in aggregationsTables)
{
Console.WriteLine($"\t{table.Name}");
}
}
else
{
Console.WriteLine($"This dataset has no auto aggs tables.");
}
Console.WriteLine("\n\rPress [Enter] to exit the sample app...");
Console.ReadLine();
}
}
}
Wenn Sie diesen Codeausschnitt ausführen, werden an der Konsole die derzeit im Modell enthaltenen automatischen Aggregationstabellen ausgegeben.
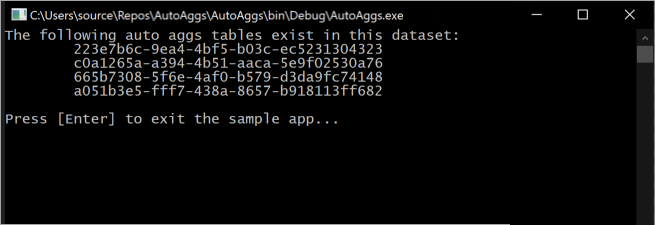
Beachten Sie, dass sich Aggregationstabellen ständig ändern, da die optimalen Aggregationen, die in den In-Memory-Aggregationscache aufgenommen werden sollen, durch Trainingsvorgänge bestimmt werden.
Wichtig
Power BI verwaltet die vom System generierten Tabellenobjekte für automatische Aggregationen vollständig. Löschen oder ändern Sie diese Tabellen nicht. Andernfalls kann es zu Leistungsbeeinträchtigungen kommen.
Power BI verwaltet die Modellkonfiguration außerhalb des Modells. Das Vorhandensein einer vom System verwalteten Aggregationstabelle in einem Modell bedeutet nicht zwangsläufig, dass das Modell tatsächlich für das Training automatischer Aggregationen aktiviert ist. Anders ausgedrückt: Wenn Sie ein Outscripting einer vollständigen Modelldefinition für ein Modell mit aktivierten automatischen Aggregationen durchführen und eine neue Kopie des Modells (mit einem anderen Namen/Arbeitsbereich oder einer anderen Kapazität) erstellen, ist das neue resultierende Dataset nicht für das Training automatischer Aggregationen aktiviert. Sie müssen das Training automatischer Aggregationen für das neue Modell in den Modelleinstellungen noch aktivieren.
Überlegungen und Einschränkungen
Berücksichtigen Sie beim Verwenden automatischer Aggregationen die folgenden Punkte:
- Aggregationen unterstützen keine dynamischen M-Abfrageparameter.
- Die SQL-Abfragen, die während der anfänglichen Trainingsphase generiert wurden, können eine erhebliche Last für das Data Warehouse generieren. Wenn das Training weiterhin unvollständig beendet wird und Sie auf der Data Warehouse-Seite überprüfen können, ob bei den Abfragen ein Timeout auftreten kann, sollten Sie Ihr Data Warehouse vorübergehend zentral hochskalieren, um den Trainingsbedarf zu erfüllen.
- Aggregationen, die im In-Memory-Aggregationscache gespeichert sind, werden möglicherweise nicht auf der Grundlage der neuesten Daten in der Datenquelle berechnet. Im Gegensatz zu reinen DirectQuery-Tabellen – in dieser Hinsicht eher regulären Importtabellen ähnlich –gibt es zwischen Updates der Datenquelle und den im In-Memory-Aggregationscache gespeicherten Daten eine Latenz. Zwar wird es immer ein gewisses Maß an Latenz geben, dieses kann aber durch einen effektiven Aktualisierungszeitplan verringert werden.
- Legen Sie zum weiteren Optimieren der Leistung für alle Dimensionstabellen den dualen Modus fest, und belassen Sie Faktentabellen im DirectQuery-Modus.
- Automatische Aggregationen stehen in Power BI Pro, Azure Analysis Services oder SQL Server Analysis Services nicht zur Verfügung.
- Power BI unterstützt kein Herunterladen von Modellen mit aktivierten automatischen Aggregationen. Wenn Sie eine Power BI Desktop(PBIX)-Datei in Power BI hochgeladen oder veröffentlicht und dann automatische Aggregationen aktiviert haben, können Sie die PBIX-Datei nicht mehr herunterladen. Achten Sie darauf, eine Kopie der PBIX-Datei lokal zu speichern.
- Automatische Aggregationen mit externen Tabellen in Azure Synapse Analytics werden nicht unterstützt. Sie können externe Tabellen in Synapse aufzählen, indem Sie die folgende SQL-Abfrage verwenden:
SELECT SCHEMA_NAME(schema_id) AS schema_name, name AS table_name FROM sys.external_tables. - Automatische Aggregationen sind nur für Modelle verfügbar, die erweiterte Metadaten verwenden. Wenn Sie automatische Aggregationen für ein älteres Modell aktivieren möchten, aktualisieren Sie das Modell zunächst auf erweiterte Metadaten. Weitere Informationen finden Sie unter Verwenden erweiterter Modellmetadaten.
- Aktivieren Sie keine automatischen Aggregationen, wenn die DirectQuery-Datenquelle für einmaliges Anmelden konfiguriert ist und dynamische Datenansichten oder Sicherheitssteuerelemente verwendet, um den Zugriff eines Benutzers auf die Daten einzuschränken. Automatische Aggregationen kennen diese Steuerelemente auf Datenquellenebene nicht – damit kann nicht sichergestellt werden, dass auf einer Pro-Benutzer-Basis korrekte Daten zur Verfügung gestellt werden. Das Training protokolliert im Aktualisierungsverlauf eine Warnung, dass es eine Datenquelle entdeckt hat, die für einmaliges Anmelden konfiguriert ist, und die Tabellen übersprungen hat, die diese Datenquelle verwenden. Wenn möglich, deaktivieren Sie das einmalige Anmelden für diese Datenquellen, um die optimierte Abfrageleistung, die automatische Aggregationen bieten können, voll auszuschöpfen.
- Aktivieren Sie keine automatischen Aggregationen, wenn das Modell nur Hybridtabellen enthält, um unnötigen Verarbeitungsaufwand zu vermeiden. Eine Hybridtabelle verwendet sowohl Importpartitionen als auch eine DirectQuery-Partition. Ein häufiges Szenario ist die inkrementelle Aktualisierung mit Echtzeitdaten, bei der eine DirectQuery-Partition Transaktionen aus der Datenquelle abruft, die nach der letzten Datenaktualisierung aufgetreten sind. Power BI importiert jedoch Aggregationen während der Aktualisierung. Automatische Aggregationen können keine Transaktionen enthalten, die nach der letzten Datenaktualisierung stattgefunden haben. Das Training protokolliert eine Warnung im Aktualisierungsverlauf, dass es Hybridtabellen erkannt und übersprungen hat.
- Berechnete Spalten werden für automatische Aggregationen nicht berücksichtigt. Wenn Sie eine berechnete Spalte im DirectQuery-Modus verwenden, etwa mithilfe der DAX-Funktion
COMBINEVALUES, um aus zwei DirectQuery-Tabellen eine auf mehreren Spalten basierende Beziehung zu erstellen, werden die entsprechenden Berichtsabfragen nicht im In-Memory-Aggregationscache gefunden. - Automatische Aggregationen sind nur im Power BI-Dienst verfügbar. Power BI Desktop erstellt keine vom System generierten Aggregationstabellen.
- Wenn Sie die Metadaten eines Modells mit aktivierten automatischen Aggregationen ändern, kann die Abfrageleistung bis zur Auslösung des nächsten Trainingsvorgangs beeinträchtigt sein. Als bewährte Methode sollten Sie die automatischen Aggregationen verwerfen, die Änderungen vornehmen und dann erneut trainieren.
- Ändern oder löschen Sie vom System generierte Aggregationstabellen nur, wenn Sie automatische Aggregationen deaktiviert haben und das Modell bereinigen. Die Verwaltung dieser Objekte liegt in der Zuständigkeit des Systems.
Community
Power BI verfügt über eine dynamische Community, in der MVPs, BI-Experten und Peers Fachwissen in Diskussionsgruppen, Videos, Blogs und mehr teilen. Wenn Sie mehr über automatische Aggregationen erfahren möchten, sollten Sie sich diese weiteren Ressourcen ansehen: