Interpretieren von Modellergebnissen im Azure Machine Learning Studio (Classic)
GILT FÜR:  Machine Learning Studio (klassisch)
Machine Learning Studio (klassisch)  Azure Machine Learning
Azure Machine Learning
Wichtig
Der Support für Machine Learning Studio (klassisch) endet am 31. August 2024. Es wird empfohlen, bis zu diesem Datum auf Azure Machine Learning umzustellen.
Ab dem 1. Dezember 2021 können Sie keine neuen Ressourcen in Machine Learning Studio (klassisch) mehr erstellen. Bis zum 31. August 2024 können Sie die vorhandenen Ressourcen in Machine Learning Studio (klassisch) weiterhin verwenden.
Die Dokumentation zu ML Studio (klassisch) wird nicht mehr fortgeführt und kann künftig nicht mehr aktualisiert werden.
In diesem Artikel werden das Visualisieren und Interpretieren der Vorhersageergebnisse im Azure Machine Learning Studio (Classic) erläutert. Nachdem Sie ein Modell trainiert und darauf basierend Vorhersagen erstellt (das Modell ausgewertet) haben, müssen Sie das Vorhersageergebnis verstehen und interpretieren.
Es gibt vier Hauptarten von Machine Learning-Modellen im Azure Machine Learning Studio (Classic):
- Klassifizierung
- Clustering
- Regression
- Empfehlungssysteme
Folgende Module werden am Anfang dieser Modelle für die Vorhersage verwendet:
- Score Model ist ein Modul für Klassifizierung und Regression.
- Assign to Clusters ist ein Modul für das Clustering.
- Score Matchbox Recommender ist ein Modul für Empfehlungssysteme.
Erfahren Sie, wie Sie Parameter zur Optimierung von Algorithmen in Machine Learning Studio (Classic) auswählen.
Informationen zum Auswerten Ihrer Modelle finden Sie unter Auswerten der Modellleistung in Azure Machine Learning Studio (Classic).
Wenn Sie mit ML Studio (Classic) noch nicht vertraut sind, erfahren Sie hier, wie Sie ein einfaches Experiment erstellen.
Klassifizierung
Es gibt zwei Unterkategorien von Klassifizierungsproblemen:
- Probleme mit nur zwei Klassen (Zwei-Klassen- oder binäre Klassifizierung)
- Probleme mit mehr als zwei Klassen (Klassifizierung mit mehreren Klassen)
Das Azure Machine Learning Studio (Classic) bietet unterschiedliche Module für den Umgang mit den einzelnen Klassifizierungstypen, die Methoden zur Interpretation der Vorhersageergebnisse sind aber ähnlich.
Klassifizierung mit zwei Klassen
Beispielexperiment
Ein Beispiel für ein Zwei-Klassen-Klassifizierungsproblem ist die Klassifizierung der Schwertlilien. Schwertlilien sollen gemäß ihrer Features klassifiziert werden. Das im Azure Machine Learning Studio (Classic) bereitgestellte Iris-Dataset ist eine Teilmenge des beliebten Iris-Datasets und enthält nur Instanzen von zwei Blumenarten (Klasse 0 und 1). Es gibt vier Features für jede Blume (Länge und Breite des Kelchblatts sowie Länge und Breite des Kronblatts).

Abbildung 1. Experiment mit Schwertlilien für ein Klassifizierungsproblem mit zwei Klassen
Es wurde ein Experiment ausgeführt, um dieses Problem zu beheben, wie in Abbildung 1 dargestellt. Ein zweiklassiges Modell mit gewichtetem Entscheidungsbaum wurde trainiert und bewertet. Jetzt können Sie die Vorhersageergebnisse aus dem Modul Score Model grafisch darstellen, indem Sie auf den Ausgabeport des Moduls Score Model und dann auf Visualisieren klicken.

Hierdurch werden die Bewertungsergebnisse angezeigt, wie in Abbildung 2 dargestellt.

Abbildung 2. Visualisieren des Bewertungsmodellergebnisses bei der Zwei-Klassen-Klassifizierung
Ergebnisinterpretation
Es gibt in der Ergebnistabelle sechs Spalten. Die vier linken Spalten sind die vier Features. Die zwei rechten Spalten, „Scored Labels“ und „Scored Probabilities“, beinhalten die Vorhersageergebnisse. Die Spalte „Scored Probabilities“ zeigt die Wahrscheinlichkeit, dass eine Blume zur positiven Klasse (Klasse 1) gehört. Z.B. bedeutet die erste Zahl in der Spalte (0,028571), dass eine Wahrscheinlichkeit von 0,028571 besteht, dass die erste Blume der Klasse 1 angehört. Die Spalte "Scored Labels" zeigt die vorhergesagte Klasse für jede Blume. Dies basiert auf der Spalte "Scored Probabilities". Wenn die ausgewertete Wahrscheinlichkeit einer Blume größer als 0,5 ist, wird sie als Klasse 1 vorhergesagt. Andernfalls wird sie als Klasse 0 vorhergesagt.
Webdienstveröffentlichung
Sobald Sie die Vorhersageergebnisse verstanden und als solide eingestuft haben, kann das Experiment als Webdienst veröffentlicht werden, damit es in verschiedenen Anwendungen bereitgestellt und aufgerufen werden kann, um Klassenvorhersagen zu allen neuen Schwertlilien abzurufen. Informationen zum Ändern eines Schulungsexperiments in ein Bewertungsexperiment und zur Veröffentlichung als Webdienst finden Sie im Lernprogramm 3: Bereitstellen des Kreditrisikomodells. Dieses Verfahren liefert Ihnen ein Bewertungsexperiment wie in Abbildung 3 dargestellt.

Abbildung 3. Experiment zur Bewertung von Schwertlilien in Verbindung mit einem Zwei-Klassen-Klassifizierungsproblem
Jetzt müssen Sie die Eingabe und Ausgabe für den Webdienst festlegen. Die Eingabe erfolgt über den rechten Eingangsport von Score Model, also die Eingabe der Schwertlilienmerkmale. Die Wahl der Ausgabe hängt davon ab, ob Sie an der vorhergesagten Klasse (ausgewerteter Bezeichner), der ausgewerteten Wahrscheinlichkeit oder an beiden Werten interessiert sind. In diesem Beispiel wird vorausgesetzt, dass Sie an beiden Werten interessiert sind. Um die gewünschten Ausgabespalten auszuwählen, müssen Sie das Modul Select Columns in Data set verwenden. Klicken Sie auf Select Columns in Data set, dann auf Launch column selector (Spaltenauswahl starten), und wählen Sie Scored Labels (Bewertete Bezeichnungen) und Scored Probabilities (Bewertete Wahrscheinlichkeiten) aus. Nach dem Festlegen des Ausgangsports für Select Columns in Data set und dem erneuten Ausführen sollten Sie das Bewertungsexperiment als Webdienst veröffentlichen können, indem Sie auf WEBDIENST VERÖFFENTLICHEN klicken. Das letzte Experiment sieht aus wie in Abbildung 4.
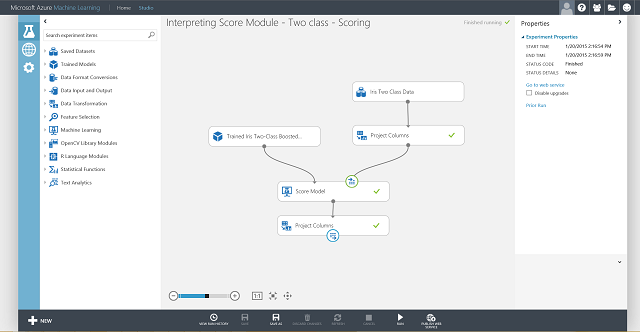
Abbildung 4. Letztes Bewertungsexperiment mit einer Schwertlilie für ein Klassifizierungsproblem mit zwei Klassen
Nach Ausführung des Webdiensts und Eingabe einiger Featurewerte einer Testinstanz werden zwei Zahlen als Ergebnis zurückgegeben. Die erste Zahl ist der ausgewertete Bezeichner, die zweite ist die ausgewertete Wahrscheinlichkeit. Diese Blume wird mit einer Wahrscheinlichkeit von 0,9655 als Klasse 1 vorhergesagt.


Abbildung 5. Webdienstergebnis der Schwertlilienklassifizierung mit zwei Klassen
Klassifizierung mit mehreren Klassen
Beispielexperiment
In diesem Experiment führen Sie als Beispiel der Klassifizierung mit mehreren Klassen eine Buchstabenerkennung durch. Die Klassifizierung versucht, einen bestimmten Buchstaben (Klasse) anhand von Handschriftattributwerten vorherzusagen, die aus handschriftlichen Bildern extrahiert werden.

In den Trainingsdaten gibt es 16 Features, die aus handschriftlichen Bildern extrahiert wurden. Die 26 Buchstaben bilden die 26 Klassen. Abbildung 6 zeigt ein Experiment zum Trainieren eines Klassifizierungsmodells mit mehreren Klassen zur Buchstabenerkennung und Vorhersagen auf Basis der gleichen Featuregruppe bei einem Testdataset.

Abbildung 6. Experiment zum Problem der Buchstabenerkennung bei Klassifizierung mit mehreren Klassen
Visualisieren Sie die Ergebnisse aus dem Modul Score Model, indem Sie auf den Ausgabeport des Moduls Score Model und dann auf Visualisieren klicken. Der Inhalt sollte dem in Abbildung 7 ähneln.

Abbildung 7. Visualisieren der Bewertungsmodellergebnisse bei der Klassifizierung mit mehreren Klassen
Ergebnisinterpretation
Die linken 16 Spalten stellen die Featurewerte des Testsatzes dar. Die Spalten mit den Namen „Scored Probabilities for Class 'XX'“ entsprechen der Spalte „Scored Probabilities“ bei zwei Klassen. Sie zeigen die Wahrscheinlichkeit, dass der entsprechende Eintrag in einer bestimmten Klasse liegt. Beim ersten Eintrag liegt beispielsweise die Wahrscheinlichkeit für ein „A“ bei 0,003571, die Wahrscheinlichkeit für ein „B“ bei 0,000451 usw. Die letzte Spalte („Scored Labels“) entspricht „Scored Labels“ bei zwei Klassen. Die Klasse mit der größten ausgewerteten Wahrscheinlichkeit wird als die vorhergesagte Klasse des entsprechenden Eintrags ausgewählt. Beispielsweise ist „F“ der ausgewertete Bezeichner für den ersten Eintrag, da die Wahrscheinlichkeit für ein „F“ am größten ist (0,916995).
Webdienstveröffentlichung
Sie können auch die bewertete Bezeichnung für jeden Eintrag und die Wahrscheinlichkeit der bewerteten Bezeichnung abrufen. Die grundlegende Logik ist, die größte Wahrscheinlichkeit unter allen ausgewerteten Wahrscheinlichkeiten zu finden. Zu diesem Zweck müssen Sie das Modul Execute R Script verwenden. Der R-Code ist in Abbildung 8 dargestellt, das Ergebnis des Experiments in Abbildung 9.

Abbildung 8. R-Code für das Extrahieren von „Scored Labels“ und der zugehörigen Wahrscheinlichkeiten der Bezeichner

Abbildung 9. Endgültiges Bewertungsexperiment zur Buchstabenerkennung bei einem Klassifizierungsproblem mit mehreren Klassen
Wenn Sie nach dem Veröffentlichen und Ausführen des Webdiensts einige Featurewerte eingeben, entspricht das ausgegebene Ergebnis Abbildung 10. Dieser handschriftliche Buchstabe mit den extrahierten 16 Features wird mit einer Wahrscheinlichkeit von 0,9715 als „T“ vorhergesagt.


Abbildung 10. Webdienstergebnis der Klassifizierung mit mehreren Klassen
Regression
Regressionsprobleme unterscheiden sich von Klassifizierungsproblemen. Bei einem Klassifizierungsproblem versuchen Sie, diskrete Klassen vorherzusagen, zum Beispiel die Klasse, der eine Schwertlilie angehört. Aber wie Sie im folgenden Beispiel eines Regressionsproblems sehen, versuchen Sie, eine kontinuierliche Variable wie etwa den Preis eines Autos vorherzusagen.
Beispielexperiment
Verwenden Sie die Automobilpreisvorhersage als Beispiel für Regression. Der Preis für ein Auto soll auf Basis seiner Features einschließlich Marke, Treibstofftyp, Karosserietyp und Antriebsart vorhergesagt werden. Das Experiment ist in Abbildung 11 dargestellt.

Abbildung 11. Regressionsproblemexperiment mit Automobilpreis
Eine Visualisierung des Moduls Score Model liefert das in Abbildung 12 gezeigte Ergebnis.

Abbildung 12. Bewertungsergebnis für das Problem der Automobilpreisvorhersage
Ergebnisinterpretation
In diesem Bewertungsergebnis ist „Scored Labels“ die Ergebnisspalte. Die Zahlen sind der vorhergesagte Preis für jedes Auto.
Webdienstveröffentlichung
Sie können das Regressionsexperiment wie im Fall der Klassifizierung mit zwei Klassen in einem Webdienst veröffentlichen und für die Vorhersage von Autopreisen verwenden.

Abbildung 13. Bewertungsexperiment zum Automobilpreis-Regressionsproblem
Wenn der Webdienst ausgeführt wird, wird das in Abbildung 14 gezeigte Ergebnis zurückgegeben. Der vorhergesagte Preis für dieses Auto ist 15.085,52 $.


Abbildung 14: Webdienstergebnis zum Automobilpreis-Regressionsproblem
Clustering
Beispielexperiment
Verwenden Sie das Iris-Dataset erneut, um ein Clusteringexperiment zu erstellen. Hier filtern Sie die Klassenbezeichner aus dem Dataset heraus, sodass es nur Features enthält und für das Clustering verwendet werden kann. Legen Sie in diesem Iris-Anwendungsfall die Anzahl der Cluster während des Trainingsprozesses auf 2 fest, d.h. die Blumen sollen in zwei Klassen zusammengefasst werden. Das Experiment ist in Abbildung 15 dargestellt.

Abbildung 15: Experiment zum Iris-Clusteringproblem
Das Clustering unterscheidet sich von der Klassifizierung dahingehend, dass das Trainingsdataset nicht selbst über Ground-Truth-Bezeichner verfügt. Das Clustering gruppiert die Instanzen des Trainingsdatasets in verschiedenen Clustern. Während des Trainingsprozesses versieht das Modell die Einträge mit Bezeichnern, indem es die Unterschiede zwischen deren Features lernt. Danach kann das trainierte Modell weiter zum Klassifizieren von zukünftigen Einträge verwendet werden. Zwei Teile des Ergebnisses sind in einem Clusteringproblem relevant. Der erste Teil besteht im Bezeichnen des Trainingsdatasets und der zweite im Klassifizieren eines neuen Datasets mit dem trainierten Modell.
Der erste Teil des Ergebnisses kann durch Klicken auf den linken Ausgabeport des Moduls Train Clustering Model und anschließendes Klicken auf Visualisieren visualisiert werden. Die Visualisierung wird in Abbildung 16 dargestellt.

Abbildung 16: Visualisieren des Clusteringergebnisses für das Trainingsdataset
Das Ergebnis des zweiten Teils, das Clustering neuer Einträge mit dem trainierten Clusteringmodell, ist in Abbildung 17 dargestellt.

Abbildung 17: Visualisieren des Clusteringergebnisses in einem neuen Dataset
Ergebnisinterpretation
Obwohl die Ergebnisse der beiden Teile aus verschiedenen Experimentphasen stammen, sehen sie gleich aus und werden auf die gleiche Weise interpretiert. Die ersten vier Spalten sind Features. Die letzte Spalte, „Assignments“, ist das Vorhersageergebnis. Die Einträge, denen die gleiche Zahl zugewiesen wurde, werden als im gleichen Cluster befindlich vorhergesagt, d.h. beide weisen in bestimmter Form Ähnlichkeiten auf (in diesem Experiment wurde die standardmäßige euklidische Abstandsmetrik verwendet). Da als Anzahl der Cluster 2 angegeben wurde, werden die Einträge in Zuweisungen entweder mit 0 oder 1 bezeichnet.
Webdienstveröffentlichung
Sie können das Clusteringexperiment wie im Fall der Klassifizierung mit zwei Klassen in einem Webdienst veröffentlichen und für Clusteringvorhersagen verwenden.

Abbildung 18: Bewertungsexperiment zum Iris-Clusteringproblem
Abbildung 19 zeigt das nach dem Ausführen des Webdiensts zurückgegebene Ergebnis. Für diese Blume wird der Cluster 0 vorhergesagt.


Abbildung 19: Webdienstergebnis der Schwertlilienklassifizierung mit zwei Klassen
Empfehlungssystem
Beispielexperiment
Für Empfehlungssysteme verwenden Sie das Restaurantempfehlungsproblem als Beispiel: Kunden werden Restaurants auf Grundlage ihres Bewertungsverlaufs empfohlen. Die Eingabedaten besteht aus drei Teilen:
- Restaurantbewertungen von Kunden
- Kundenfeaturedaten
- Daten zu Restaurantmerkmalen
Mit dem Modul Train Matchbox Recommender im Azure Machine Learning Studio (Classic) können Sie verschiedene Aufgaben durchführen:
- Vorhersagen von Bewertungen für einen bestimmten Benutzer und ein bestimmtes Element
- Empfehlen von Elementen für einen bestimmten Benutzer
- Suchen von Benutzern, die im Zusammenhang mit einem bestimmten Benutzer stehen
- Suchen von Elementen, die im Zusammenhang mit einem bestimmten Element stehen
Im Menü Recommender prediction kind können Sie zwischen vier Optionen wählen. Hier werden alle vier Szenarien erläutert.

Ein typisches Experiment für Empfehlungssysteme im Azure Machine Learning Studio (Classic) sieht wie in Abbildung 20 aus. Ausführliche Informationen zur Verwendung dieser Empfehlungssystemmodule finden Sie in der Hilfe zu Train Matchbox Recommender und Score Matchbox Recommender.

Abbildung 20: Empfehlungssystemexperiment
Ergebnisinterpretation
Vorhersagen von Bewertungen für einen bestimmten Benutzer und ein bestimmtes Element
Durch Auswahl von Rating Prediction im Menü Recommender prediction kind wird das Empfehlungssystem aufgefordert, die Bewertung für einen bestimmten Benutzer und ein bestimmtes Element vorauszusagen. Die Visualisierung der Ausgabe von Score Matchbox Recommender sieht wie in Abbildung 21 aus.

Abbildung 21: Visualisieren des Bewertungsergebnisses des Empfehlungssystems – „Rating Prediction“
Die ersten beiden Spalten sind die Benutzer-Element-Paare, die durch die eingegebenen Daten bereitgestellt werden. Die dritte Spalte ist die vorhergesagte Bewertung eines Benutzers für ein bestimmtes Element. In der ersten Zeile wird zum Beispiel vorhergesagt, dass Kunde U1048 das Restaurant 135026 mit 2 bewertet.
Empfehlen von Elementen für einen bestimmten Benutzer
Bei Auswahl von Item Recommendation im Menü Recommender prediction kind empfiehlt das System Elemente für einen bestimmten Benutzer. Der letzte Parameter, den Sie in diesem Szenario auswählen müssen, ist Recommended item selection. Die Option From Rated Items (for model evaluation) wird in erster Linie für die Auswertung von Modellen während des Trainings verwendet. Wählen Sie für diese Vorhersagephase From All Itemsaus. Die Visualisierung der Ausgabe von Score Matchbox Recommender sieht wie in Abbildung 22 aus.

Abbildung 22: Visualisieren des Bewertungsergebnisses des Empfehlungssystems – Elementempfehlung
Die erste der sechs Spalten stellt die angegebenen Benutzer-IDs dar, für die Elemente empfohlen werden sollen, gemäß Bereitstellung durch die Eingabedaten. Die übrigen fünf Spalten stellen die dem Benutzer empfohlenen Elemente dar, in absteigender Reihenfolge gemäß Relevanz. In der ersten Zeile ist das am häufigsten empfohlene Restaurant für den Kunden U1048 beispielsweise 134986, gefolgt von 135018, 134975, 135021 und 132862.
Suchen von Benutzern, die im Zusammenhang mit einem bestimmten Benutzer stehen
Bei Auswahl von Related Users unter Recommender prediction kind sucht das Empfehlungssystem zu einem bestimmten Benutzer in Beziehung stehende Benutzer. Diese verwandten Benutzer sind Benutzer mit ähnlichen Präferenzen. Der letzte Parameter, den Sie in diesem Szenario auswählen müssen, ist Related user selection. Die Option From Users That Rated Items (for model evaluation) wird in erster Linie für die Auswertung von Modellen während des Trainings verwendet. Wählen Sie für diese Vorhersagephase From All Users aus. Die Visualisierung der Ausgabe von Score Matchbox Recommender sieht wie in Abbildung 23 aus.

Abbildung 23: Visualisieren der Bewertungsergebnisse des Empfehlungssystems – verwandte Benutzer
Die erste von sechs Spalten zeigt die angegebenen Benutzer-IDs an, die erforderlich sind, um verwandte Benutzer zu suchen, gemäß Bereitstellung durch die Eingabedaten. Die übrigen fünf Spalten stellen die vorhergesagten verwandten Benutzer des Benutzers dar, in absteigender Reihenfolge gemäß Relevanz. So ist beispielsweise in der ersten Zeile der wichtigste Kunde für den Kunden U1048 der Kunde U1051, gefolgt von U1066, U1044, U1017 und U1072.
Suchen von Elementen, die im Zusammenhang mit einem bestimmten Element stehen
Bei Auswahl von Related Items unter Recommender prediction kind sucht das Empfehlungssystem zugehörige Elemente zu einem bestimmten Element. Verwandte Elemente sind die Elemente, für die es am wahrscheinlichsten ist, dass sie dem gleichen Benutzer gefallen. Der letzte Parameter, den Sie in diesem Szenario auswählen müssen, ist Related item selection. Die Option From Rated Items (for model evaluation) wird in erster Linie für die Auswertung von Modellen während des Trainings verwendet. Wählen Sie From All Items für diese Vorhersagephase aus. Die Visualisierung der Ausgabe von Score Matchbox Recommender sieht wie in Abbildung 24 aus.

Abbildung 24: Visualisieren der Bewertungsergebnisse des Empfehlungssystems – verwandte Elemente
Die erste von sechs Spalten stellt die angegebenen Element-IDs dar, die erforderlich sind, um verwandte Elemente zu suchen, gemäß Bereitstellung durch die Eingabedaten. Die übrigen fünf Spalten stellen die vorhergesagten verwandten Elemente des Elements in absteigender Reihenfolge gemäß Relevanz dar. In der ersten Zeile ist das Element mit der höchsten Relevanz für das Element 135026 beispielsweise 135074, gefolgt von 135035, 132875, 135055 und 134992.
Webdienstveröffentlichung
Der Prozess der Veröffentlichung dieser Experimente als Webdienste zum Vorhersagen ist für jedes der vier Szenarien ähnlich. Hier wird als Beispiel das zweite Szenario verwendet (Empfehlen von Elementen für einen bestimmten Benutzer). Sie können das gleiche Verfahren für die anderen drei Möglichkeiten nutzen.
Speichern Sie das trainierte Empfehlungssystem als ein trainiertes Modell, und filtern Sie die Eingabedaten für eine einzelne Benutzer-ID-Spalte wie erforderlich. Dann können Sie das Experiment wie in Abbildung 25 einbinden und als Webdienst veröffentlichen.

Abbildung 25: Bewertungsexperiment zum Restaurantempfehlungsproblem
Wenn der Webdienst ausgeführt wird, wird das in Abbildung 26 gezeigte Ergebnis zurückgegeben. Die fünf empfohlenen Restaurants für Benutzer U1048 sind 134986, 135018, 134975, 135021 und 132862.


Abbildung 26: Webdienstergebnis für das Restaurantempfehlungsproblem