Anmerkung
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen, dich anzumelden oder die Verzeichnisse zu wechseln.
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen , die Verzeichnisse zu wechseln.
Gilt für:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Die Big Data Cluster von Microsoft SQL Server 2019 werden eingestellt. Der Support für SQL Server 2019 Big Data Cluster endete am 28. Februar 2025. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und den Big Data-Optionen auf der Microsoft SQL Server-Plattform.
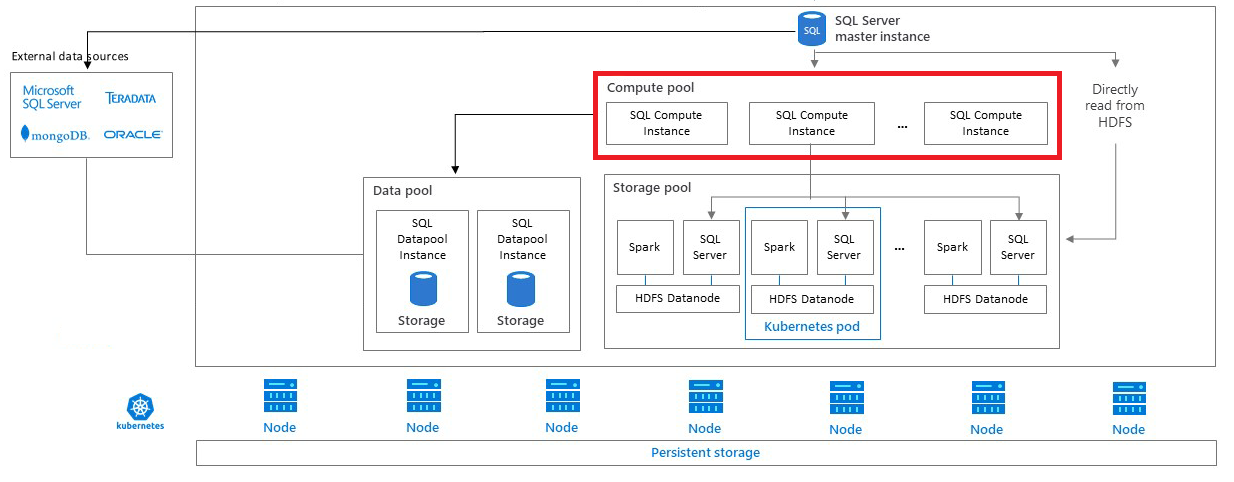
In diesem Artikel ist die Rolle beschrieben, die SQL Server-Computepools in einem Big Data-Cluster für SQL Server spielen. Computepools stellen horizontal skalierbare Computeressourcen für einen SQL Server-Big Data-Cluster bereit. Sie werden verwendet, um Berechnungsarbeit oder Zwischenresultsets aus der SQL Server-Masterinstanz auszulagern. In den folgenden Abschnitten werden die Architektur, die Funktionen und die Nutzungsszenarios eines Computepools beschrieben.
Dieses fünfminütige Video enthält eine Einführung in Computepools:
Computepoolarchitektur
Ein Computepool besteht aus mindestens einem Compute-Pod, der in Kubernetes ausgeführt wird. Das automatisierte Erstellen und Verwalten dieser Pods wird von der SQL Server-Masterinstanz koordiniert. Jeder Pod enthält eine Reihe von Basisdiensten und eine Instanz der SQL Server-Datenbank-Engine.
Scale-out groups
Ein Computepool kann als PolyBase-Erweiterungsgruppe für verteilte Abfragen über verschiedene externe Datenquellen fungieren, etwa SQL Server, Oracle, MongoDB, Teradata und HDFS. Durch Verwenden von Computepods in Kubernetes kann in einem SQL Server-Big Data-Cluster das Erstellen und Konfigurieren von Computepods für PolyBase-Erweiterungsgruppen automatisiert werden.
Computepoolszenarien
In den folgenden Szenarien werden Computepools verwendet:
Wenn bei der Masterinstanz eingereichte Abfragen Tabellen verwenden, die sich im Speicherpool befinden.
Wenn bei der Masterinstanz eingereichte Abfragen Tabellen verwenden, die sich im Datenpool befinden und Roundrobin-Verteilung verwenden.
Wenn bei der Masterinstanz eingereichte Abfragen partitionierte Tabellen mit externen Datenquellen in SQL Server, Oracle, MongoDB oder Teradata verwenden. Für dieses Szenario muss der Abfragehinweis OPTION (FORCE SCALEOUTEXECUTION) aktiviert sein.
Wenn bei der Masterinstanz eingereichte Abfragen Tabellen verwenden, die sich im HDFS-Tiering befinden.
In den folgenden Szenarien werden keine Computepools verwendet:
Wenn bei der Masterinstanz eingereichte Abfragen Tabellen verwenden, die sich in einem externen Hadoop HDFS-Cluster befinden.
Wenn bei der Masterinstanz eingereichte Abfragen Tabellen verwenden, die sich in Azure Blob Storage befinden.
Wenn bei der Masterinstanz eingereichte Abfragen nicht partitionierte Tabellen mit externen Datenquellen in SQL Server, Oracle, MongoDB oder Teradata verwenden.
Wenn der Abfragehinweis OPTION (DISABLE SCALEOUTEXECUTION) aktiviert ist.
Wenn bei der Masterinstanz eingereichte Abfragen sich auf Datenbanken beziehen, die sich auf der Masterinstanz befinden.
Next steps
Weitere Informationen zu Big Data-Cluster für SQL Server finden Sie in den folgenden Ressourcen: