Identifizieren von Sicherheitsfehlerberichten anhand von Berichtstiteln und verrauschten Daten
| Mayana Pereira | Scott Christiansen |
|---|---|
| CELA Data Science | Customer Security and Trust |
| Microsoft | Microsoft |
Exposee: Das Erkennen von sicherheitsrelevanten Fehlerberichten ist ein wichtiger Schritt im Lebenszyklus der Softwareentwicklung. Bei überwachten, auf maschinellem Lernen basierenden Ansätzen wird normalerweise angenommen, dass ganze Fehlerberichte zu Trainingszwecken verfügbar und die Labels rauschfrei sind. Nach dem aktuellen Kenntnisstand der Autoren ist dies die erste Studie, die zeigt, dass sich Labels für sicherheitsrelevante Fehlerberichte selbst dann vorhersagen lassen, wenn nur der Titel verfügbar ist und die Labels verrauscht sind.
Schlagwörter: maschinelles Lernen, Fehllabeling, Rauschen, sicherheitsrelevante Fehlerberichte, Fehlerrepositorys
I. EINFÜHRUNG
Das Erkennen von sicherheitsrelevanten Problemen bei gemeldeten Fehlern ist eine der dringendsten Aufgaben von Softwareentwicklungsteams, da solche Probleme schnelle Fixes erfordern, um Complianceanforderungen zu erfüllen und die Integrität von Software und Kundendaten sicherzustellen.
Auf maschinellem Lernen und künstlicher Intelligenz basierende Tools versprechen eine schnellere, flexiblere und korrektere Softwareentwicklung. Mehrere Forscher haben versucht, mithilfe von maschinellem Lernen Sicherheitsfehler zu erkennen [2], [7], [8], [18]. In zuvor veröffentlichten Studien wurde davon ausgegangen, dass der gesamte Fehlerbericht für das Trainieren und Bewerten eines Machine Learning-Modells verfügbar ist. Dies ist jedoch nicht unbedingt der Fall. Es gibt Situationen, in denen nicht der gesamte Fehlerbericht verfügbar gemacht werden kann. Fehlerberichte können z. B. Kennwörter, personenbezogene Informationen oder andere Arten von vertraulichen Daten enthalten. Mit ebendieser Situation sieht sich Microsoft derzeit konfrontiert. Daher ist es wichtig zu untersuchen, wie gut die Erkennung von sicherheitsrelevanten Fehlern mit weniger Informationen funktioniert, z. B., wenn nur der Titel des Fehlerberichts verfügbar ist.
Außerdem enthalten Fehlerrepositorys häufig falsch gelabelte Einträge [7]: z. B. nicht sicherheitsrelevante Fehlerberichte, die als sicherheitsrelevant klassifiziert sind, und umgekehrt. Es gibt mehrere Gründe für falsche Labels. Sie reichen von fehlenden Sicherheitskenntnissen des Entwicklungsteams bis hin zur Unschärfe mancher Probleme. Nicht sicherheitsrelevante Fehler können beispielsweise indirekt ausgenutzt werden, um ein Sicherheitsrisiko zu verursachen. Dies ist ein schwerwiegendes Problem, da Sicherheitsexperten die Fehlerdatenbank auf kostspielige und zeitaufwändige Weise manuell überprüfen müssen, wenn sicherheitsrelevante Fehlerberichte falsch gelabelt sind. Daher ist es von höchster Wichtigkeit zu verstehen, wie sich Rauschen auf verschiedene Klassifizierer auswirkt und wie robust (oder anfällig) verschiedene Machine-Learning-Techniken (ML) sind, wenn Datasets unterschiedliche Arten von Rauschen aufweisen. Dieses Problem muss gelöst werden, damit die automatische Klassifizierung in der Softwareentwicklung eingesetzt werden kann.
Frühere Untersuchungen haben die These aufgestellt, dass Fehlerrepositorys intrinsisch verrauscht sind und dass das Rauschen negative Auswirkungen auf die Leistung der ML-Klassifizierer [7] haben kann. Es fehlte jedoch eine systematische und quantitative Studie, die der Frage nachgeht, wie verschiedene Rauschpegel und Arten von Rauschen die Leistung von verschiedenen Algorithmen für das überwachte maschinellen Lernen im Zusammenhang mit der Erkennung von sicherheitsrelevanten Fehlerberichten beeinträchtigen.
Diese Studie zeigt, dass sich Fehlerberichte selbst dann klassifizieren lassen, wenn nur der Titel für das Training und die Bewertung verfügbar sind. Nach dem aktuellen Kenntnisstand der Autoren ist dies die erste Studie, die sich dieser Fragestellung widmet. Darüber hinaus wird hiermit die erste systematische Studie zu den Auswirkungen von Rauschen auf die Klassifizierung von Fehlerberichten präsentiert. Diese Studie vergleicht die Robustheit von drei ML-Techniken (logistische Regression, Naive Bayes und AdaBoost) gegenüber klassenunabhängigem Rauschen.
Obwohl einige analytische Modelle die allgemeinen Auswirkungen von Rauschen auf einige einfache Klassifizierer erfassen [5], [6], erlauben sie keine genauen Rückschlüsse auf die Genauigkeit und gelten nur für eine bestimmte ML-Technik. Eine genaue Analyse der Auswirkungen von Rauschen in ML-Modellen erfolgt in der Regel mithilfe von Berechnungsexperimenten. Solche Analysen wurden für verschiedene Szenarios durchgeführt: von Softwaremessungsdaten [4] bis zur Klassifizierung von Satellitenbildern [13] und medizinischen Daten [12]. Dennoch lassen sich die Ergebnisse aufgrund des zugrunde liegenden Klassifizierungsproblems und der hohen Abhängigkeit von der Art des Datasets nicht auf das in dieser Studie untersuchte Problem übertragen. Nach dem aktuellen Kenntnisstand der Autoren wurden bisher keine dedizierten Forschungsarbeiten zu den Auswirkungen von verrauschten Datasets auf die Klassifizierung von sicherheitsrelevanten Fehlerberichten veröffentlicht.
FORSCHUNGSBEITRÄGE DIESER STUDIE:
Die Klassifizierer für die Erkennung von sicherheitsrelevanten Fehlerberichten wurden ausschließlich anhand von Berichtstiteln trainiert. Nach dem aktuellen Kenntnisstand der Autoren ist dies die erste Studie, die diesen Ansatz wählt. In früheren Arbeiten wurde entweder der gesamte Fehlerbericht verwendet, oder der Fehlerbericht wurde durch komplementäre Features ergänzt. Die ausschließlich auf Titeln basierende Klassifizierung von Fehlern ist besonders wichtig, wenn Fehlerberichte aus Datenschutzgründen nicht vollständig verfügbar gemacht werden können. Es ist beispielsweise hinlänglich bekannt, dass Fehlerberichte Kennwörter und andere vertrauliche Daten enthalten können.
Dies ist ebenfalls die erste systematische Studie zur Toleranz gegenüber Labelrauschen, die verschiedene ML-Modelle aufweisen, sowie zu den Techniken für die automatische Klassifizierung von sicherheitsrelevanten Fehlerberichten. Diese Studie vergleicht die Robustheit von drei verschiedenen ML-Techniken (logistische Regression, Naive Bayes und AdaBoost) gegenüber klassenabhängigem und klassenunabhängigem Rauschen.
Der Rest der Arbeit wird wie folgt dargestellt: In Abschnitt II stellen wir einige der früheren Arbeiten in der Literatur vor. In Abschnitt III werden das Dataset und die Vorverarbeitung der Daten beschrieben. Die Methodik wird in Abschnitt IV erläutert. Abschnitt V analysiert die Ergebnisse der Experimente. In Abschnitt VI werden die Schlussfolgerungen und der Ausblick auf zukünftige Forschungsarbeiten vorgestellt.
II. VORANGEHENDE FORSCHUNG
AUF MASCHINELLEM LERNEN BASIERENDE ANWENDUNGEN FÜR FEHLERREPOSITORYS
Es gibt umfangreiche Literatur zu dem Versuch, Textmining, Natural Language Processing und maschinelles Lernen auf Fehlerrepositorys anzuwenden, um mühsame Aufgaben wie die Erkennung von Sicherheitsfehlern [2], [7], [8], [18] und doppelten Fehlern [3] sowie die Fehlertriage [1], [11] zu automatisieren. Idealerweise löst die Verbindung aus maschinellem Lernen und Natural Language Processing gewisse Probleme. Sie kann potenziell die manuelle Arbeit verringern, die zum Kuratieren von Fehlerdatenbanken erforderlich ist, die für diese Aufgaben erforderliche Zeit verkürzen und die Zuverlässigkeit der Ergebnisse erhöhen.
Gegick et al. (2010) [7] schlagen ein Modell der natürlichen Sprache vor, um die Klassifizierung von sicherheitsrelevanten Fehlerberichten auf Grundlage der Fehlerbeschreibung zu automatisieren. Die Autoren extrahieren Vokabular aus allen Fehlerbeschreibungen im Trainingsdataset und teilen es manuell in drei Wortlisten ein: relevante Wörter, Stoppwörter (gängige Wörter, die für die Klassifizierung irrelevant erscheinen) und Synonyme. Sie vergleichen die Leistung eines Klassifizierers für Sicherheitsfehler, der mit allen von den Sicherheitstechnikern ausgewerteten Daten trainiert wurde, mit einem Klassifizierer, der mit Daten trainiert wurde, die von den Fehlermeldern gelabelt wurden. Obwohl das Modell deutlich effektiver ist, wenn die Trainingsdaten von Sicherheitstechnikern geprüft wurden, basiert das vorgeschlagene Modell auf einem manuell abgeleiteten Vokabular. Es bedarf also menschlicher Kuratierung. Zudem wird nicht analysiert, wie sich unterschiedliche Rauschpegel auf das Modell auswirken, wie unterschiedliche Klassifizierer auf Rauschen reagieren und ob das Rauschen in beiden Klassen die Leistung beeinträchtigt.
Zou et. al [18] nutzen mehrere Arten von Informationen, die in einem Fehlerbericht enthalten sind, die die nicht-textuellen Felder eines Fehlerberichts (Metafunktionen, z. B. Zeit, Schweregrad und Priorität) und den Textinhalt eines Fehlerberichts umfassen (Textmerkmale, d. h. der Text in Zusammenfassungsfeldern). Anhand dieser Features wird ein Modell erstellt, das sicherheitsrelevante Fehlerberichte automatisch mithilfe von Natural Language Processing und maschinellem Lernen erkennt. Goseva-Popstojanova und Tyo (2018) [8] führen eine ähnliche Analyse durch. Sie vergleichen jedoch zusätzlich die Leistung von Techniken für das überwachte und das nicht überwachte maschinelle Lernen und erforschen, wie viele Daten zum Trainieren ihrer Modelle erforderlich sind.
Behl et al. (2014) [2] untersuchen ebenfalls die unterschiedlichen ML-Techniken, mit denen sich Fehler anhand ihrer Beschreibungen als sicherheitsrelevante oder nicht sicherheitsrelevante Fehlerberichte klassifizieren lassen. Sie schlagen eine Pipeline für die Datenverarbeitung und das Modelltraining vor, die auf dem Tf-idf-Algorithmus basiert. Des Weiteren vergleichen sie die vorgeschlagene Pipeline mit einem Bag-of-Words-Modell, das den Naive-Bayes-Klassifizierer verwendet. Wijayasekara et al. (2014) [16] verwendeten auch Textminingtechniken, um den Featurevektor eines jeden Fehlerberichts anhand von häufig vorkommenden Wörtern zu generieren, um Fehler mit versteckten Auswirkungen (Hidden Impact Bugs, HIBs) zu erkennen. Yang et al. (2016) [17] konnten laut eigener Aussage Fehlerberichte mit großen Auswirkungen (z. B. sicherheitsrelevante Fehlerberichte) mithilfe der Vorkommenshäufigkeit (Term Frequency, TF) und dem Naive-Bayes-Klassifizierer erkennen. Lamkanfi et al. (2010) [9] schlagen ein Modell vor, mit dem sich der Schweregrad eines Fehlers vorhersagen lässt.
LABELRAUSCHEN
Das Problem von Datasets mit Labelrauschen ist bereits ausführlich untersucht worden. Frénay und Verleysen (2014) [6] schlagen eine Taxonomie für Labelrauschen vor, um unterschiedliche Typen von verrauschten Labels zu unterscheiden. Die Autoren definieren drei verschiedene Arten von Rauschen: 1) Labelrauschen, das unabhängig von der wahren Klasse und den Werten der Instanzfeatures auftritt, 2) Labelrauschen, das ausschließlich vom wahren Label abhängt, und 3) Labelrauschen, bei dem die Wahrscheinlichkeit von falschen Labels auch von den Featurewerten abhängt. In der vorliegenden Arbeit werden die ersten beiden Arten von Rauschen untersucht. Theoretisch mindert Labelrauschen in der Regel die Leistung eines Modells [10]. Es gibt jedoch gewisse Ausnahmefälle [14]. Robuste Methoden verarbeiten Labelrauschen im Allgemeinen, indem Übereinpassung vermieden wird [15]. Rauscheffekte bei der Klassifizierung wurden bereits in vielen Bereichen untersucht, z. B. bei der Klassifizierung von Satellitenbildern [13], der Klassifizierung von Softwarequalität [4] und der Klassifizierung von medizinische Domänen [12]. Nach dem aktuellen Kenntnisstand der Autoren gibt es keine veröffentlichten Arbeiten, die die genaue Quantifizierung der Auswirkungen von verrauschten Labels bei der Klassifizierung von sicherheitsrelevanten Fehlerberichten untersuchen. In diesem Szenario wurde die genaue Beziehung zwischen Rauschpegel, Rauscharten und Leistungsbeeinträchtigung noch nicht nachgewiesen. Außerdem ist es interessant zu untersuchen, wie sich unterschiedliche Klassifizierer bei Rauschen verhalten. Allgemein sind den Autoren keinerlei Arbeiten bekannt, die systematisch die Auswirkungen von verrauschten Datasets auf die Leistung verschiedener ML-Algorithmen im Zusammenhang mit Softwarefehlerberichten studieren.
III. BESCHREIBUNG DES DATASETS
Das verwendete Dataset besteht aus 1.073.149 Fehlertiteln. Dies entspricht 552.073 sicherheitsrelevanten und 521.076 nicht sicherheitsrelevanten Fehlerberichten. Die Daten wurden in den Jahren 2015, 2016, 2017 und 2018 von verschiedenen Teams bei Microsoft erhoben. Die Labels wurden entweder durch signaturbasierte Fehlerüberprüfungssysteme oder durch Mitarbeiter vergeben. Die Fehlertitel in unserem Dataset sind sehr kurze Texte mit ungefähr 10 Wörtern und enthalten eine Übersicht über das Problem.
A. Vorverarbeitung der Daten: Jeder Fehlertitel wird anhand seiner leeren Leerzeichen analysiert, woraus sich eine Liste von Tokens ergibt. Jede Tokenliste wird wie folgt verarbeitet:
Alle Token, bei denen es sich um Dateipfade handelt, werden entfernt.
Tokens, die die folgenden Symbole enthalten, werden aufgeteilt: {, (, ), -, }, {, [, ], }
Stoppwörter, aus rein numerischen Zeichen bestehende Tokens und weniger als fünfmal im gesamten Korpus vorkommende Tokens werden entfernt.
IV. METHODIK
Das Training der ML-Modelle besteht aus zwei Hauptschritten: 1) die Codierung der Daten in Featurevektoren und 2) das Trainieren von Klassifizierern für das überwachte maschinelle Lernen.
A. Featurevektoren und Techniken für das maschinelle Lernen
Zunächst werden Daten wie bei Behl et al. (2014) [2] mithilfe des Tf-idf-Algorithmus in Featurevektoren codiert. Tf-idf ist eine Methode aus dem Information-Retrieval-Bereich, bei der die Vorkommenshäufigkeit (Term Frequency, TF) und deren inverse Dokumenthäufigkeit (Inverse Document Frequency, IDF) gewichtet werden. Jedes Wort oder jeder Begriff verfügt über einen TF- und einen IDF-Score. Der Tf-idf-Algorithmus weist einem Wort anhand der Häufigkeit, mit der es im Dokument vorkommt, eine Wichtigkeit zu. Wichtiger noch ist, dass der Algorithmus überprüft, wie relevant das Schlüsselwort in der gesamten Titelsammlung im Dataset ist. Im Rahmen dieser Studie wurden drei Klassifizierungsmethoden angewendet und verglichen: der Naive-Bayes-Klassifizierer, geboostete Entscheidungsstrukturen (AdaBoost) und die logistische Regression. Diese Verfahren wurden gewählt, da sie laut Fachliteratur bei der Erkennung von sicherheitsrelevanten Fehlerberichten anhand des gesamten Berichts bereits gute Ergebnisse erzielten. Diese Ergebnisse wurden in einer vorläufigen Untersuchung bestätigt, bei der diese drei Klassifizierer Support Vector Machines und das Random Forest-Verfahren deutlich überlegen waren. In den Experimenten für diese Studie wurden die Bibliothek „scikit-learn“ für die Codierung und das Modelltraining verwendet.
B. Arten von Rauschen
Das in dieser Arbeit untersuchte Rauschen ist das Rauschen in den Klassenlabels der Trainingsdaten. Tritt ein solches Rauschen auf, werden der Lernprozess und das daraus resultierende Modell durch falsch gelabelte Beispiele beeinträchtigt. Diese Studie analysiert die Auswirkungen verschiedener Rauschpegel, die auf die Klasseninformationen angewendet werden. Die verschiedenen Arten von Labelrauschen wurden in der Literatur bisher mithilfe verschiedener Terminologien diskutiert. Die vorliegende Studie analysiert die Auswirkungen von zwei verschiedenen Arten von Labelrauschen auf Klassifizierer: das klassenunabhängige Labelrauschen, das durch willkürliches Auswählen von Instanzen und das Umkehren der entsprechenden Labels („Label Flipping“) hervorgerufen wird, sowie das klassenabhängige Rauschen, bei dem Klassen eine unterschiedliche Verrauschungswahrscheinlichkeit aufweisen.
a) Klassenunabhängiges Rauschen: Klassenunabhängiges Rauschen bezieht sich auf das Rauschen, das unabhängig von der wahren Klasse der Instanzen auftritt. Bei dieser Art von Rauschen ist die Wahrscheinlichkeit von Fehllabeling pbr für alle Instanzen im Dataset identisch. Klassenunabhängiges Rauschen wird in die für diese Studie verwendeten Datasets eingeführt, indem jedes Label in den Datasets nach dem Zufallsprinzip mit der Wahrscheinlichkeit pbr umgekehrt wird.
a) Klassenabhängiges Rauschen: Klassenabhängiges Rauschen bezieht sich auf das Rauschen, das von der wahren Klasse der Instanzen abhängt. Bei dieser Art von Rauschen wird die Wahrscheinlichkeit von falschen Klassenlabels für sicherheitsrelevante Fehlerberichte als psbr bezeichnet, die Wahrscheinlichkeit von falschen Klassenlabels für nicht sicherheitsrelevante Fehlerberichte als pnsbr. Klassenabhängiges Rauschen wird in das in dieser Studie verwendeten Dataset eingeführt, indem jeder Eintrag in den Datasets, dessen echtes Label „sicherheitsrelevanter Fehlerbericht“ lautet, mit der Wahrscheinlichkeit psbr umgekehrt wird. Analog dazu wird das Klassenlabel von Instanzen von nicht sicherheitsrelevanten Fehlerberichten mit der Wahrscheinlichkeit pnsbr umgekehrt.
c) Einzelklassenrauschen: Einzelklassenrauschen ist ein Sonderfall von klassenabhängigem Rauschen, wobei pnsbr = 0 und psbr> 0 is. Beachten Sie, dass für klassenunabhängiges Rauschen psbr = pnsbr = pbr gilt.
C. Erzeugung von Rauschen
Die im Rahmen dieser Studie durchgeführten Experimente untersuchen die Auswirkungen verschiedener Arten von Rauschen und Rauschpegel beim Trainieren von Klassifizierern für sicherheitsrelevante Fehlerberichte. Für diese Experimente wurden 25 % des Datasets als Testdaten, 10 % als Validierungsdaten und 65 % als Trainingsdaten festgelegt.
Anschließend wird den Trainings- und Validierungsdatasets für verschiedene Pegel von pbr, psbr und pnsbr Rauschen hinzugefügt. An dem Testdataset wird nichts geändert. Die verwendeten unterschiedlichen Rauschpegel sind P = {0.05 × i|0 < i < 10}.
In Experimenten zum klassenunabhängigen Rauschen wird für pbr ∈ P wie folgt vorgegangen:
Generieren von Rauschen für Trainings- und Validierungsdatasets
Trainieren von logistischen Regressionsmodellen sowie Naive-Bayes- und AdaBoost-Modellen mithilfe des Trainingsdatasets (mit Rauschen), * Optimieren der Modelle mithilfe der Validierungsdatasets (mit Rauschen)
Testen der Modelle mithilfe des Testdatasets (ohne Rauschen)
In Experimenten zum klassenabhängigen Rauschen wird für psbr ∈ P und pnsbr ∈ P für alle Kombinationen von psbr und pnsbr wie folgt vorgegangen:
Generieren von Rauschen für Trainings- und Validierungsdatasets
Trainieren von logistischen Regressionsmodellen sowie Naive-Bayes- und AdaBoost-Modellen mithilfe des Trainingsdatasets (mit Rauschen)
Optimieren von Modellen mithilfe des Validierungsdatasets (mit Rauschen)
Testen der Modelle mithilfe des Testdatasets (ohne Rauschen)
V. ERGEBNISSE DER EXPERIMENTE
In diesem Abschnitt werden die Ergebnisse der Experimente analysiert, die gemäß der in Abschnitt IV beschriebenen Methodik durchgeführt wurden.
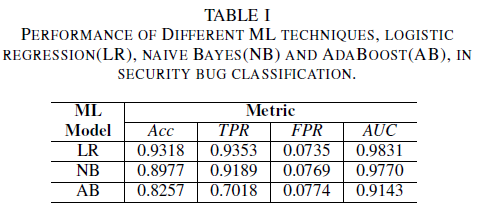
a) Modellleistung ohne Rauschen im Trainingsdatensatz: Einer der Beiträge dieses Papiers ist der Vorschlag eines Modells für maschinelles Lernen zur Identifizierung von Sicherheitsfehlern, indem nur der Titel des Fehlers als Daten für die Entscheidungsfindung Dies ermöglicht es, ML-Modelle selbst dann zu trainieren, wenn Entwicklungsteams die vollständigen Fehlerberichte nicht vollständig freigeben möchten, weil diese vertrauliche Daten enthalten. Verglichen wird die Leistung von drei ML-Modellen, die nur mit Fehlertiteln trainiert wurden.
Das logistische Regressionsmodell ist der effektivste Klassifizierer. Dieser Klassifizierer hat mit 0,9826 den höchsten AUC-Wert und einen Recall von 0,9353 bei einem FPR-Wert von 0,0735. Mit einem AUC-Wert von 0,9779 und einem Recall von 0,9189 für einen FPR von 0,0769 hat der Naive-Bayes-Klassifizierer geringfügig schlechtere Ergebnisse als die logistische Regression erzielt. Der AdaBoost-Klassifizierer schnitt im Vergleich zu den beiden zuvor genannten am schlechtesten ab. Er erzielt einen AUC-Wert von 0,9143 und einen Recall von 0,7018 bei einem FPR-Wert von 0,0774. Die Fläche unter der ROC-Kurve (AUC) ist eine gute Messgröße für den Leistungsvergleich mehrerer Modelle, da sie die Beziehung zwischen TPR und FPR in einem einzigen Wert zusammenfasst. In der folgenden, komparative Analyse werden nur die AUC-Werte untersucht.
A. Klassenrauschen: einzelne Klasse
Gegeben sei ein Szenario, in dem alle Fehler automatisch der Klasse „Nicht sicherheitsrelevante Fehlerberichte“ zugeordnet werden. Fehler werden nur dann in die Klasse der sicherheitsrelevanten Fehlerberichte eingeordnet, wenn das Repository von einem Sicherheitsexperten überprüft wird. Dieses Szenario wird in der experimentellen Einzelklassenumgebung dargestellt, in der wir davon ausgehen, dass pnsbr = 0 und 0 < psbr< 0,5 ist.
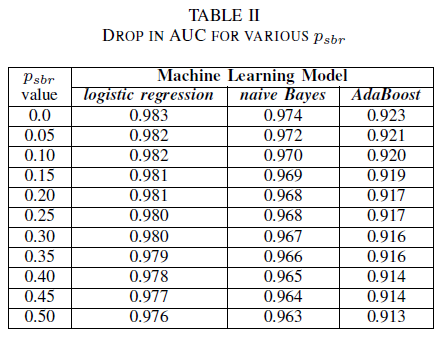
Aus Tabelle II geht hervor, dass die Auswirkungen auf den AUC-Wert bei allen drei Klassifizierern sehr gering sind. Der AUC-ROC-Wert eines Modells, das mit psbr = 0 trainiert wurde, unterscheidet sich bei der logistischen Regression um 0,003, beim Naive-Bayes-Klassifizierer um 0,006 und beim AdaBoost-Klassifizierer um 0,006 von dem AUC-ROC-Wert eines Modells, in dem psbr = 0,25 ist. Bei psbr = 0,50 weicht der für die einzelnen Modelle gemessene AUC-Wert bei der logistischen Regression um 0,007, beim Naive-Bayes-Klassifizierer um 0,011 und beim AdaBoost-Klassifizierer um 0,010 von dem Modell ab, das mit psbr = 0 trainiert wurde. Auf der logistischen Regression basierende Klassifizierer, bei denen sich das Rauschen im Trainingsdataset auf eine einzelne Klasse beschränkt, weisen die geringsten Abweichungen bei der AUC-Metrik auf. Dies bedeutet, dass sie im Vergleich zu Naive-Bayes- und AdaBoost-Klassifizierern ein robusteres Verhalten zeigen.
B. Klassenrauschen: klassenunabhängig
In diesem Experiment wurde die Leistung der drei Klassifizierer für den Fall verglichen, dass das Trainingsdataset durch klassenunabhängiges Rauschen beschädigt wurde. Der AUC-Wert wird für jedes Modell gemessen, das mit unterschiedlichen pbr-Werten trainiert wurde.
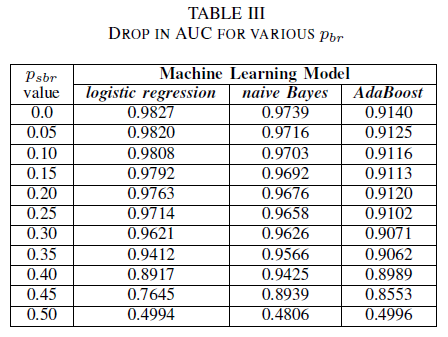
Tabelle III zeigt, dass der AUC-ROC-Wert bei jeder Zunahme von Rauschen im Experiment sinkt. Der AUC-ROC-Wert, der für ein mit nicht verrauschten Daten trainiertes Modell gemessen wird, weicht bei der logistischen Regression um 0,011, beim Naive-Bayes-Klassifizierer um 0,008 und beim AdaBoost-Klassifizierer um 0,0038 von dem AUC-ROC-Wert eines Modells ab, das mit klassenunabhängigem Rauschen und pbr = 0,25 trainiert wurde. Tabelle III zeigt, dass der AUC-Wert der Naive-Bayes- und AdaBoost-Klassifizierer nicht signifikant durch Labelrauschen beeinträchtigt wird, wenn der Rauschpegel geringer als 40 % ist. Der AUC-Wert des auf der logistischen Regression basierenden Klassifizierers sinkt jedoch bereits bei einem Rauschpegel von mehr als 30 %.
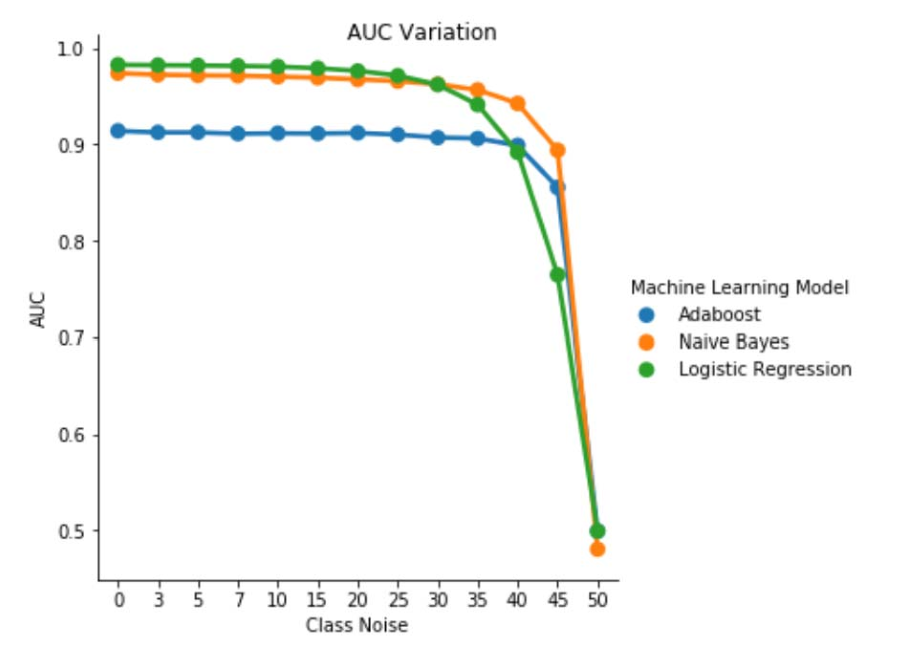
Abb. 1 Schwankung des AUC-ROC-Werts bei klassenunabhängigem Rauschen. Bei einem Rauschpegel von pbr = 0,5 verhält sich der Klassifizierer willkürlich (d. h. AUC ≈ 0,5). Das Experiment hat jedoch ergeben, dass der auf der logistischen Regression basierende Lerner bei den niedrigeren Rauschpegeln (pbr ≤ 0,30) eine bessere Leistung als die anderen beiden Modelle aufweist. Bei 0,35 ≤ pbr ≤ 0,45 zeigt hingegen der Naive-Bayes-Klassifizierer bessere AUC-ROC-Metriken.
C. Klassenrauschen: klassenabhängig
In der letzten Reihe von Experimenten betrachten wir ein Szenario, in dem verschiedene Klassen unterschiedliche Rauschpegel enthalten, d. h. psbr ≠ pnsbr. psbr und pnsbr werden im Trainingsdatatset systematisch und unabhängig voneinander um 0,05 erhöht, um die Änderungen im Verhalten der drei Klassifizierer zu messen.
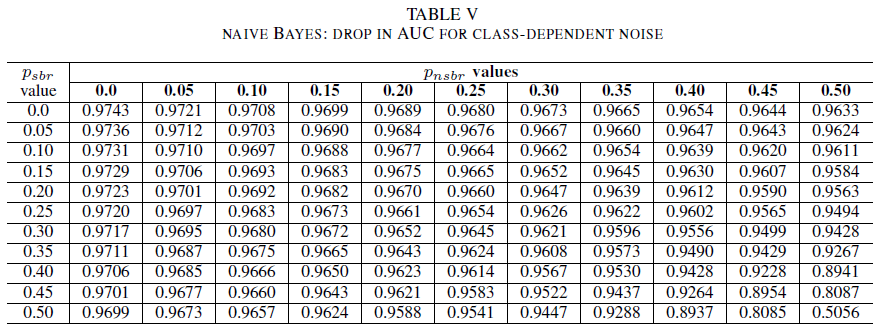
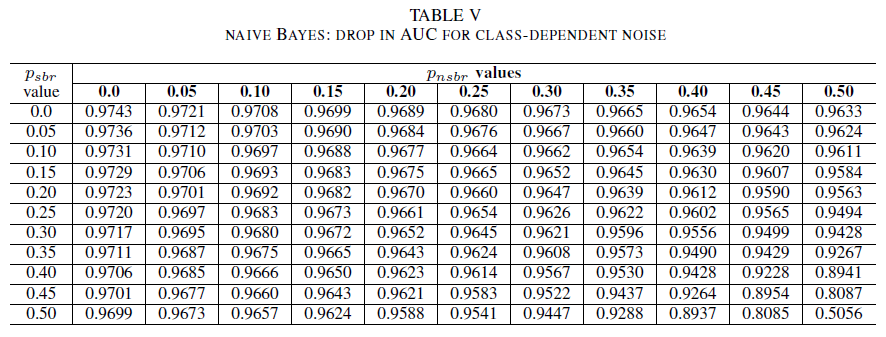
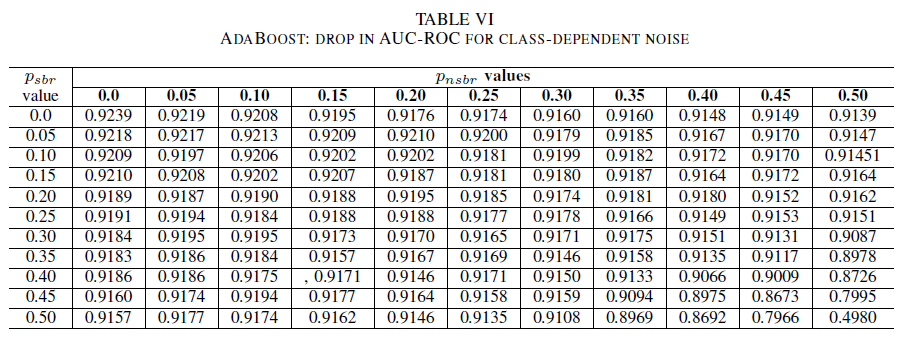
Die Tabellen IV (logistische Regression), V (Naive Bayes) und VI (AdaBoost) zeigen die Schwankungen der AUC-Werte, wenn das Rauschen in den einzelnen Klassen auf einen bestimmten Pegel erhöht wird. Alle Klassifizierer zeigen Schwankungen der AUC-Metrik, wenn beide Klassen Rauschpegel von mehr als 30 % aufweisen. Der Naive-Bayes-Klassifizierer verhält sich hier am robustesten. Die Schwankungen des AUC-Werts sind sehr gering, selbst wenn 50 % der Labels in der positiven Klasse umgekehrt werden. Dies setzt jedoch voraus, dass der Anteil an verrauschten Labels in der negativen Klasse 30 % oder weniger beträgt. In diesem Fall beträgt die Abnahme des AUC-Werts 0,03. Hier zeigte der AdaBoost-Klassifizierer das robusteste Verhalten von allen drei Modellen. Eine signifikante Änderung im AUC-Wert tritt in beiden Klassen nur bei Rauschpegeln über 45 % auf. In diesem Fall bricht die AUC-Metrik um mehr als 0,02 ein.
D: Über residuales Rauschen im ursprünglichen Dataset
Das dieser Studie zugrunde liegende Dataset wurde von signaturbasierten automatisierten Systemen und von Fachexperten gelabelt. Alle Fehlerberichte wurden außerdem überprüft und von Fachexperten geschlossen. Daher ist zu erwarten, dass der Rauschpegel im ursprünglichen Dataset minimal ausfällt und nicht statistisch signifikant ist. Residuales Rauschen macht die Ergebnisse dieser Studie nicht ungültig. Nehmen wir zur Veranschaulichung tatsächlich an, dass der Originaldatensatz durch ein klassenunabhängiges Rauschen gleich 0 < p < 1/2 unabhängig und identisch verteilt (i.i.d) für jeden Eintrag verfälscht wird.
Wird zusätzlich zum ursprünglichen Rauschen ein klassenunabhängiges Rauschen mit einer unabhängig, identisch verteilten Wahrscheinlichkeit pbr angenommen, ergibt dies ein Rauschen pro Eintrag von p∗ = p(1 − pbr )+(1 − p)pbr. Für 0 < p,pbr< 1/2 gilt, dass das tatsächliche Rauschen pro Label p∗ strikt größer ist als das Rauschen, das wir künstlich zum Datensatzbr hinzufügen . Folglich wäre die Leistung der in dieser Studie untersuchten Klassifizierer sogar besser, wenn sie von vornherein mit einem vollständig rauschfreien Dataset (p = 0) trainiert worden wären. Zusammenfassend kann gesagt werden, dass das Vorhandensein von residualem Rauschen im ursprünglichen Dataset bedeutet, dass die Resilienz der untersuchten Klassifizierer gegen Rauschen höher ausfällt, als die hier dargestellten Ergebnisse andeuten. Hinzu kommt, dass wenn das residuale Rauschen im Dataset statistisch relevant wäre, der AUC-Wert der Klassifizierer bei einem Rauschpegel, der streng kleiner als 0,5 ist, ebenfalls bei 0,5 läge (zufällige Schätzung). Ein solches Verhalten konnten in den Ergebnissen dieser Studie jedoch nicht beobachtet werden.
VI. SCHLUSSFOLGERUNGEN UND ZUKÜNFTIGE FORSCHUNG
Diese Studie leistet einen zweifachen Beitrag.
Erstens wurde die Durchführbarkeit der Klassifizierung von sicherheitsrelevanten Fehlerberichten demonstriert, die ausschließlich auf den Titeln der Fehlerberichte basiert. Dies ist besonders relevant in Szenarios, in denen aufgrund von Datenschutzbeschränkungen nicht der gesamte Fehlerbericht verfügbar ist. Im Falle von Microsoft enthalten Fehlerberichte z. B. vertrauliche Informationen wie Kennwörter und kryptografische Schlüssel und waren daher nicht für das Training der Klassifizierer verfügbar. Die Ergebnisse dieser Studie belegen, dass sicherheitsrelevante Fehlerberichte selbst dann mit hoher Genauigkeit erkannt werden können, wenn nur Berichtstitel verfügbar sind. Das Klassifizierungsmodell, das eine Kombination aus dem Tf-idf-Algorithmus und der logistischen Regression verwendet, weist einen AUC-Wert von 0,9831 auf.
Zweitens wurden die Auswirkungen von falsch gelabelten Trainings- und Validierungsdaten analysiert. Drei im maschinellen Lernen gängige Klassifizierungstechniken (Naive Bayes, logistische Regression und AdaBoost) wurden im Hinblick auf ihre Robustheit gegenüber unterschiedlichen Arten von Rauschen und Rauschpegeln verglichen. Alle drei Klassifizierer sind robust gegenüber Einzelklassenrauschen. Rauschen in den Trainingsdaten hat keine signifikanten Auswirkungen auf den resultierenden Klassifizierer. Die Abnahme des AUC-Werts ist bei einem Rauschpegel von 50 % sehr gering (0,01). Bei Rauschen, das in beiden Klassen vorhanden und klassenunabhängig ist, weisen das Naive-Bayes- und das AdaBoost-Modell deutliche Schwankungen im AUC-Wert auf, wenn sie mit einem Dataset trainiert werden, dessen Rauschpegel mehr als 40 % beträgt.
Zuletzt ist festzustellen, dass sich das klassenabhängige Rauschen nur dann erheblich auf den AUC-Wert auswirkt, wenn der Rauschpegel in beiden Klassen höher als 35 % ist. Der AdaBoost-Klassifizierer zeigte hier die größte Robustheit. Die Schwankungen des AUC-Werts sind sehr gering, selbst wenn 50 % der Labels in der positiven Klasse verrauscht sind. Dies setzt jedoch voraus, dass der Anteil an verrauschten Labels in der negativen Klasse 45 % oder weniger beträgt. In diesem Fall sinkt der AUC-Wert um weniger als 0,03. Nach dem aktuellen Kenntnisstand der Autoren ist dies erste systematische Studie zu den Auswirkungen von verrauschten Datasets auf die Erkennung von sicherheitsrelevanten Fehlerberichten.
FORSCHUNGSAUSBLICK
Dies ist eine systematische Untersuchung der Auswirkungen von Rauschen auf die Leistung von ML-Klassifizierern, mit denen sich Sicherheitsfehler erkennen lassen. Diese Arbeit bietet mehrere interessante Anknüpfungspunkte. Dies sind nur einige denkbare Beispiele für Forschungsgegenstände: 1) die Auswirkungen von verrauschten Datasets bei der Feststellung des Schweregrads von Sicherheitsfehlern, 2) die Auswirkungen des Klassenungleichgewichts auf die Resilienz der trainierten Modelle gegenüber Rauschen und 3) die Auswirkungen von Rauschen, das böswillig in ein Dataset eingefügt wird.
REFERENCES
[1] John Anvik, Lyndon Hiew und Gail C. Murphy. Who should fix this bug? In: Proceedings of the 28th international conference on Software engineering, S. 361–370. ACM, 2006.
[2] Diksha Behl, Sahil Handa, and Anuja Arora. A bug mining tool to identify and analyze security bugs using naive bayes and tf-idf. In: Optimization, Reliability, and Information Technology (ICROIT), 2014 International Conference on, S. 294–299. IEEE, 2014.
[3] Nicolas Bettenburg, Rahul Premraj, Thomas Zimmermann und Sunghun Kim. Duplicate bug reports considered harmful really? In Software maintenance, 2008. ICSM 2008. IEEE international conference on, pages 337–345. IEEE, 2008.
[4] Andres Folleco, Taghi M. Khoshgoftaar, Jason Van Hulse und Lofton Bullard. Identifying learners robust to low quality data. In Software maintenance, 2008. IRI 2008. IEEE international conference on, Seiten 190–195. IEEE, 2008.
[5] Benoît Frénay. Uncertainty and label noise in machine learning. PhD-Arbeit, Katholische Universität Löwen, Louvain-la-Neuve, Belgien, 2013.
[6] Benoît Frénay und Michel Verleysen. Classification in the presence of label noise: a survey. IEEE transactions on neural networks and learning systems, 25(5):845–869, 2014.
[7] Michael Gegick, Pete Rotella und Tao Xie. Identifizieren von Sicherheitsfehlerberichten mittels Text Mining: Eine industrielle Fallstudie. In: Mining software repositories (MSR), 2010 7th IEEE working conference on, S. 11–20. IEEE, 2010.
[8] Katerina Goseva-Popstojanova und Jacob Tyo. Identification of security related bug reports via text mining using supervised and unsupervised classification. In: 2018 IEEE International Conference on Software Quality, Reliability and Security (QRS), S. 344–355, 2018.
[9] Ahmed Lamkanfi, Serge Demeyer, Emanuel Giger und Bart Goethals. Predicting the severity of a reported bug. In: Mining Software Repositories (MSR), 2010 7th IEEE Working Conference on, S. 1–10. IEEE, 2010.
[10] Naresh Manwani und P. S. Sastry. Noise tolerance under risk minimization. IEEE transactions on cybernetics, 43(3):1146–1151, 2013.
[11] G. Murphy und D. Cubranic. Automatic bug triage using text categorization. In: Proceedings of the Sixteenth International Conference on Software Engineering & Knowledge Engineering. Citeseer, 2004.
[12] Mykola Pechenizkiy, Alexey Tsymbal, Seppo Puuronen und Oleksandr Pechenizkiy. Klassenrauschen und überwachtes Lernen in medizinischen Bereichen: Die Wirkung der Merkmalsextraktion. In: null, S. 708–713. IEEE, 2006.
[13] Charlotte Pelletier, Silvia Valero, Jordi Inglada, Nicolas Champion, Claire Marais Sicre und Gerard Dedieu. Effect of training class label noise on classification performances for land cover mapping with satellite image time series. Remote Sensing, 9(2):173, 2017.
[14] P. S. Sastry, G. D. Nagendra und Naresh Manwani. A team of continuousaction learning automata for noise-tolerant learning of half-spaces. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 40(1):19–28, 2010.
[15] Choh-Man Teng. A comparison of noise handling techniques. In: FLAIRS Conference, S. 269–273, 2001.
[16] Dumidu Wijayasekara, Milos Manic und Miles McQueen. Vulnerability identification and classification via text mining bug databases. In Industrial Electronics Society, IECON 2014-40th Annual Conference of the IEEE, Seiten 3612–3618. IEEE, 2014.
[17] Xinli Yang, David Lo, Qiao Huang, Xin Xia und Jianling Sun. Automated identification of high impact bug reports leveraging imbalanced learning strategies. In: Computer Software and Applications Conference (COMPSAC), 2016 IEEE 40th Annual, Band 1, S. 227–232. IEEE, 2016.
[18] Deqing Zou, Zhijun Deng, Zhen Li und Hai Jin. Automatically identifying security bug reports via multitype features analysis. In: Australasian Conference on Information Security and Privacy, S. 619–633. Springer, 2018.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für