Bedrohungsmodellierung für KI/ML-Systeme und Abhängigkeiten
Von Andrew Marshall, Jugal Parikh, Emre Kiciman und Ram Shankar Siva Kumar
Unser besonderer Dank geht an Raul Rojas und den AETHER Security Engineering Workstream.
November 2019
Dieser Artikel wurde von der AETHER Engineering Practices for AI Working Group ausgearbeitet und ergänzt vorhandene SDL-Bedrohungsmodellpraktiken durch neue Anleitungen zur Enumeration und Minderung von Bedrohungen, die spezifisch für KI und maschinelles Lernen (ML) spezifisch sind. Er versteht sich als Referenz bei Sicherheitsdesignprüfungen für Folgendes:
Produkte/Dienste, die mit KI/ML-basierten Diensten interagieren bzw. diese als Abhängigkeiten haben
Produkte/Dienste, die mit KI/ML in ihrem Kern erstellt werden
Die traditionelle Abwehr von Sicherheitsbedrohungen ist wichtiger als je zuvor. Die vom Security Development Lifecycle (SDL) vorgelegten Anforderungen sind unverzichtbar, um eine Grundlage für Produktsicherheit herzustellen, auf der dieser Leitfaden aufbaut. Wenn traditionelle Sicherheitsbedrohungen nicht adressiert werden, fördert dies in diesem Artikel behandelte KI/ML-spezifische Angriffe sowohl im Software- als auch im physischen Bereich, und es müssen Kompromisse in tieferen Ebenen des Softwarestapels eingegangen werden. Eine Einführung zu den neuen Sicherheitsbedrohungen in diesem Bereich finden Sie unter Sichern der Zukunft von KI/ML bei Microsoft.
Die Skillsets von Sicherheitstechnikern und Datenanalysten überschneiden sich in der Regel nicht. Diese Anleitung ermöglicht es beiden Bereichen, diese neuen Bedrohungen und Risikominderungen strukturiert zu diskutieren, ohne dass Sicherheitstechniker zu Datenanalysten werden müssen (oder umgekehrt).
Dieser Artikel ist in zwei Abschnitte unterteilt:
- Im Mittelpunkt von „Wichtige neue Überlegungen zur Bedrohungsmodellierung“ stehen neue Denkansätze und Fragen, die bei der Bedrohungsmodellierung von KI/ML-Systemen von Relevanz sind. Diesen Abschnitt sollten sowohl Datenanalysten als auch Sicherheitstechniker durcharbeiten; er kann ihnen als Leitfaden für die Erörterung von Bedrohungsmodellen und die Priorisierung von Risikominderungsmaßnahmen dienen.
- In „KI/ML-spezifische Bedrohungen und entsprechende Risikominderungen“ werden konkrete Angriffe sowie derzeit gängige spezifische Maßnahmen zur Risikominderung erläutert, mit denen Microsoft-Produkte und -Dienste vor diesen Bedrohungen geschützt werden können. Dieser Abschnitt richtet sich hauptsächlich an Datenanalysten, die im Ergebnis des Prozesses der Bedrohungsmodellierung/Sicherheitsüberprüfung ggf. bestimmte Risikominderungen für Bedrohungen implementieren müssen.
Dieser Leitfaden basiert auf einer Taxonomie für gegnerische Bedrohungen durch maschinelles Lernen, die von Ram Shankar Siva Kumar, David O’Brien, Kendra Albert, Salome Viljoen und Jeffrey Snover mit dem Titel „Fehlermodi beim maschinellen Lernen" herstellen. Anleitungen zum Vorfallmanagement zur Einstufung von Sicherheitsbedrohungen, die in diesem Dokument detailliert beschrieben werden, finden Sie in SDL Bug Bar für AI/ML-Bedrohungen. Bei all diesen Dokumenten handelt es sich um lebendige Dokumente, die sich im Laufe der Zeit mit der Bedrohungslandschaft weiterentwickeln.
Wichtige neue Überlegungen bei der Bedrohungsmodellierung: Ändern der Art und Weise, wie Sie Vertrauensgrenzen betrachten
Gehen Sie von der Beschädigung und dem Poisoning der Daten aus, die von Ihnen oder dem Datenanbieter trainiert werden. Erfahren Sie, wie Sie anomale und schädliche Dateneingaben erkennen, wie Sie zwischen diesen unterscheiden und die Daten wiederherstellen können.
Zusammenfassung
Das Trainieren von Datenspeichern und der Systeme, in denen sie gehostet werden, gehört zur Bedrohungsmodellierung. Die gegenwärtig größte Sicherheitsbedrohung beim maschinellen Lernen ist das Datenpoisoning, da standardmäßige Erkennung und Risikominderungen in diesem Bereich fehlen und nicht vertrauenswürdige/nicht kuratierte öffentliche Datasets als Quelle für Trainingsdaten genutzt werden. Das Verfolgen der Herkunft und der Abstammung Ihrer Daten ist unverzichtbar, um ihre Vertrauenswürdigkeit sicherzustellen und einen „Garbage In, Garbage Out“-Trainingszyklus zu vermeiden.
Fragen, die in einer Sicherheitsüberprüfung gestellt werden müssen
Wie erkennen Sie Poisoning oder Manipulation Ihrer Daten?
– Anhand welcher Telemetrie erkennen Sie eine Qualitätsbeeinträchtigung Ihrer Trainingsdaten?
Trainieren Sie Daten anhand der Eingaben von Benutzern?
– Welche Art der Eingabeüberprüfung/-bereinigung nehmen Sie an diesen Inhalten vor?
– Ist die Struktur dieser Daten ähnlich wie in Datasheets for Datasets (Datenblätter für Datasets) dokumentiert?
Wenn Sie anhand von Online-Datenspeichern trainieren, welche Maßnahmen ergreifen Sie, um die Sicherheit der Verbindung zwischen Ihrem Modell und den Daten zu gewährleisten?
– Besteht die Möglichkeit, Consumer über die Beschädigung ihrer Feeds zu benachrichtigen?
– Sind sie überhaupt dazu in der Lage?
Wie vertraulich sind die Daten, anhand derer trainiert wird?
– Werden sie katalogisiert, und wird das Hinzufügen/Aktualisieren/Löschen von Dateneingaben gesteuert?
Gibt Ihr Modell vertrauliche Daten aus?
– Wurden diese Daten mit Genehmigung seitens der Quelle erlangt?
Gibt das Modell nur Ergebnisse aus, die zum Erreichen seines Ziels erforderlich sind?
Gibt Ihr Modell Roh-Zuverlässigkeitsbewertungen oder eine sonstige direkte Ausgabe zurück, die aufgezeichnet und dupliziert werden können?
Welche Auswirkungen hat die Wiederherstellung Ihrer Trainingsdaten nach einem Angriff oder einer Invertierung des Modells?
Fällt die Zuverlässigkeit der Modellausgabe plötzlich ab, können Sie die Gründe und Ursachen dafür sowie die Daten ermitteln, welche dafür verantwortlich sind?
Haben Sie eine wohlgeformte Eingabe für das Modell definiert? Welche Maßnahmen ergreifen Sie, um sicherzustellen, dass Eingaben diesem Format entsprechen, und was tun Sie, wenn dies nicht der Fall ist?
Wenn die Ausgaben falsch sind, jedoch keine zu meldenden Fehler bewirken – wie stellen Sie dies fest?
Wissen Sie, ob Ihre Trainingsalgorithmen auf mathematischer Ebene resilient gegenüber feindseligen Eingaben (Adversarial Inputs) sind?
Wie stellen Sie Ihre Trainingsdaten nach einer feindseligen Kontamination wieder her?
– Können Sie konträre Inhalte isolieren/unter Quarantäne stellen und betroffene Modelle neu trainieren?
– Können Sie ein Rollback/eine Wiederherstellung des Modells auf eine frühere Version ausführen, um es neu zu trainieren?
Nutzen Sie vertiefendes Lernen für nicht kuratierte öffentliche Inhalte?
Beginnen Sie, über die Herkunft Ihrer Daten nachzudenken. Wenn Sie ein Problem feststellen, können Sie es bis zu seiner Einführung in das Dataset zurückverfolgen? Wenn dies nicht der Fall ist, ist das ein Problem?
Bringen Sie in Erfahrung, woher Ihre Trainingsdaten stammen und ermitteln Sie statistische Normen, um Anomalien zu erkennen.
– Welche Elemente Ihrer Trainingsdaten sind anfällig gegenüber äußeren Einflüssen?
– Wer kann zu den Datasets beitragen, anhand der Sie trainieren?
– Wie würden Sie Ihre Quellen von Trainingsdaten angreifen, um einem Konkurrenten zu schaden?
Entsprechende Bedrohungen und Risikominderungen in diesem Artikel
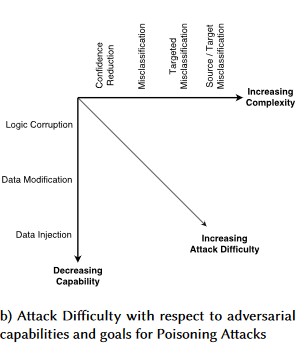
Feindselige Störung (alle Varianten)
Datenpoisoning (alle Varianten)
Beispiele für Angriffe
Erzwingen, dass gutartige E-Mails als Spam klassifiziert werden oder dass ein bösartiges Beispiel nicht erkannt wird
Von Angreifern erstellte Eingaben, welche die Zuverlässigkeit der korrekten Klassifizierung reduzieren, insbesondere in Szenarien mit schwerwiegenden Folgen
Angreifer injizieren willkürlich Stördatenverkehr in die klassifizierten Daten, um die Wahrscheinlichkeit der künftigen korrekten Klassifizierung zu verringern, wodurch die Wirksamkeit des Modells beeinträchtigt wird
Kontamination von Trainingsdaten um die Fehlklassifizierung ausgewählter Datenpunkte zu erzwingen, wodurch ein System bestimmte Aktionen ergreift oder unterdrückt
Identifizieren von Aktionen, die Ihre Modelle oder Produkte/Dienste zum Nachteil Ihrer Kunden ausführen könnten (sowohl online als auch physisch)
Zusammenfassung
Falls keine Risikominderung oder Abwehr erfolgt, können sich Angriffe auf KI/ML-Systeme auf die physische Umgebung ausdehnen. Alle Szenarien, über die Benutzer psychisch oder physisch beeinträchtigt werden können, stellen ein schwerwiegendes Risiko für Ihre Produkte und Dienste dar. Dies gilt auch für alle vertraulichen Daten zu ihren Kunden, die für Trainings- und Designentscheidungen genutzt werden, die an diesen privaten Datenpunkten abgeschöpft werden können.
Fragen, die in einer Sicherheitsüberprüfung gestellt werden müssen
Trainieren Sie mit Beispielen für feindselige Angriffe? Welche Auswirkung haben Sie auf die Ausgabe Ihres Modells in der physischen Umgebung?
Wie wirkt sich Trolling auf Ihre Produkte/Dienste aus? Wie können Sie es erkennen und darauf reagieren?
Was wäre nötig, um Ihr Modell zur Ausgabe eines Ergebnisses zu veranlassen, aufgrund dessen ihr Dienst fälschlicherweise legitimen Benutzern den Zugriff verwehrt?
Welche Folgen hätte es, wenn Ihr Modell kopiert oder gestohlen wird?
Kann Ihr Modell so ausgenutzt werden, dass die Mitgliedschaft einer bestimmten Person hergeleitet werden kann – insbesondere die Mitgliedschaft in einer bestimmten Gruppe, oder einfach in den Trainingsdaten?
Kann ein Angreifer eine Ruf- oder PR-Schädigung Ihres Produkts bewirken, indem er es zwingt, bestimmte Aktionen auszuführen?
Wie behandeln Sie ordnungsgemäß formatierte, jedoch offensichtlich verzerrte Daten, beispielsweise von Trollen?
Können Möglichkeiten der Interaktion oder Abfrage Ihres Modells so ausgenutzt werden, dass Trainingsdaten oder Modellfunktionen offengelegt werden?
Entsprechende Bedrohungen und Risikominderungen in diesem Artikel
Rückschließen auf Mitgliedschaft
Invertieren des Modells
Entwendung des Modells
Beispiele für Angriffe
Rekonstruieren und Extrahieren von Trainingsdaten durch wiederholtes Abfragen des Modells, um Ergebnisse mit maximaler Zuverlässigkeit zu erzielen
Duplizieren des kompletten Modells durch umfassenden Abgleich von Abfragen/Antworten
Abfragen des Modells auf eine Weise, die offenlegt, dass ein bestimmtes Element privater Daten in den Trainingssatz eingeschlossen wurde
Veranlassen eines selbstfahrenden Fahrzeugs, Stoppschilder/Verkehrsampeln zu ignorieren
Interaktive Bots, die für das Trolling gutartiger Benutzer manipuliert sind
Identifizieren aller Quellen von KI/ML-Abhängigkeiten sowie Front-End-Darstellungsebenen in Ihrer Daten-/Modelllieferkette
Zusammenfassung
Viele Angriffe in KI und Machine Learning beginnen mit dem legitimen Zugriff auf APIs, welche für das Senden von Abfragen an ein Modell bereitgestellt werden. Aufgrund der vielfältigen Datenquellen und der umfassenden Benutzererfahrungen, die hier zum Tragen kommen, stellt der authentifizierte, jedoch „unangemessene“ (hier besteht eine Grauzone) Zugriff Dritter auf Ihre Modelle ein Risiko dar, wegen der Fähigkeit, als Darstellungsebene über einem von Microsoft bereitgestellten Dienst zu fungieren.
Fragen, die in einer Sicherheitsüberprüfung gestellt werden müssen
Welche Kunden und Partner werden für den Zugriff auf Ihr Modell oder Ihre Dienst-APIs authentifiziert?
– Können Sie als Darstellungsebene über Ihrem Dienst auftreten?
– Können Sie deren Zugriff im Fall einer Gefährdung umgehend widerrufen?
– Wie lautet Ihre Wiederherstellungsstrategie bei einer bösartigen Nutzung Ihres Dienstes oder von dessen Abhängigkeiten?
Können Dritte eine Fassade um Ihr Modell aufbauen, um es zu anderen Zwecken zu nutzen und Microsoft oder den Kunden von Microsoft Schaden zuzufügen?
Stellen Ihnen Kunden Trainingsdaten direkt zur Verfügung?
– Wie sichern Sie diese Daten?
– Was, wenn diese bösartig sind und auf Ihren Dienst abzielen?
Wie sehen hier falsch-positive Vorfälle aus? Welche Folgen hat ein falsch-negativer Vorfall?
Können Sie die Abweichungen von Richtig positiv- und Falsch positiv-Bewertungen über mehrere Modelle hinweg nachverfolgen und messen?
Welche Art von Telemetrie nutzen Sie, um gegenüber Ihren Kunden die Vertrauenswürdigkeit Ihrer Modellausgaben nachzuweisen?
Ermitteln Sie alle Abhängigkeiten von Dritten in Ihrer ML/Trainingsdaten-Lieferkette – nicht nur Open-Source-Software, sondern auch Datenanbieter
– Warum verlassen Sie sich auf diese, und wie können Sie ihre Vertrauenswürdigkeit überprüfen?
Verwenden Sie vorgefertigte Modelle von Dritten, oder übermitteln Sie Trainingsdaten an MLaaS-Drittanbieter?
Inventarisieren Sie neue Meldungen über Angriffe auf vergleichbare Produkte oder Dienste. Angesichts des Umstands, dass viele KI/ML-Bedrohungen auf andere Modelltypen übertragen, welche Auswirkung haben derartige Angriffe auf Ihre eigenen Produkte?
Entsprechende Bedrohungen und Risikominderungen in diesem Artikel
Neural Net-Neuprogrammierung
Beispiele für feindselige Angriffe in der physischen Welt
Bösartige ML-Anbieter, die Trainingsdaten rekonstruieren
Angriffe auf die ML-Lieferkette
Hintertürangriff auf ein Modell
Beschädigte ML-spezifische Abhängigkeiten
Beispiele für Angriffe
Ein bösartiger MLaaS-Anbieter infiziert mit einer bestimmten Umgehung einen Ihr Modell mit einem Trojaner
Ein bösartiger Kunde findet eine Schwachstelle in einer von Ihnen verwendeten gängigen OSS-Abhängigkeit und lädt eine eigens erstellte Trainingsdaten-Nutzlast hoch, um Ihren Dienst zu beschädigen
Ein skrupelloser Partner verwendet Gesichtserkennungs-APIs und erstellt eine Darstellungsschicht für Ihren Dienst, um Deep Fakes zu erzeugen.
KI/ML-spezifische Bedrohungen und entsprechende Risikominderungen
#1: Widersprüchliche Störung
Beschreibung
Bei Angriffen, die auf Störungen abzielen, ändert der Angreifer heimlich die Abfrage, um eine gewünschte Antwort von einem in der Produktion bereitgestellten Modell zu erhalten[1]. Dabei handelt es sich um eine Verletzung der Modelleingabeintegrität, die zu Fuzzingangriffen führt, deren Endergebnis nicht unbedingt eine Zugriffsverletzung oder ein Produktionsausfall ist, wobei aber die Klassifizierungsleistung des Modells beeinträchtigt wird. Dies kann sich auch durch Trolle manifestieren, die bestimmte Zielwörter so verwenden, dass sie von der KI blockiert werden, sodass der Dienst letztendlich legitimen Benutzern den Zugriff verweigert, deren Name mit einem „gesperrten“ Wort übereinstimmt.
 [24]
[24]
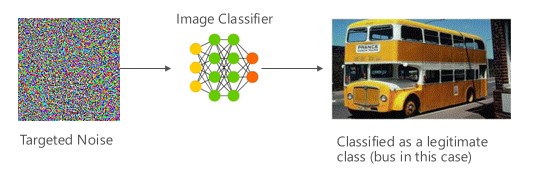
Variante #1a: Gezielte Fehlklassifizierung
In diesem Fall generieren Angreifer ein Beispiel, das sich nicht in der Eingabeklasse der Zielklassifizierung befindet, jedoch vom Modell als die betreffende Eingabeklasse klassifiziert wird. Das Beispiel für einen feindseligen Angriff kann in der menschlichen Wahrnehmung wie willkürliche Störungen wirken, aber Angreifer erlangen so eine gewisse Kenntnis des ML-Zielsystems, um zielgerichtete Störungen („White Noise“) zu generieren, bei denen bestimmte Aspekte des Zielmodells ausgenutzt werden. Der Angreifer sendet ein Eingabebeispiel, welches nicht legitim ist, aber vom Zielsystem als legitime Klasse klassifiziert wird.
Beispiele
 [6]
[6]
Gegenmaßnahmen
Stärkung der gegnerischen Robustheit durch durch gegnerisches Training induziertes Modellvertrauen [19]: Die Autoren schlagen Highly Confident Near Neighbor (HCNN) vor, ein Framework, das Konfidenzinformationen und die Suche nach dem nächsten Nachbarn kombiniert, um die gegnerische Robustheit eines Basismodells zu stärken. Dies kann helfen, zwischen richtigen und falschen Modellvorhersagen in der Umgebung eines Punkts zu unterscheiden, der aus der zugrunde liegenden Trainingsverteilung entnommen wurde.
Attributionsgesteuerte Kausalanalyse [20]: Die Autoren untersuchen den Zusammenhang zwischen der Widerstandsfähigkeit gegenüber kontradiktorischen Störungen und der attributionsbasierten Erklärung individueller Entscheidungen, die durch Modelle des maschinellen Lernens generiert werden. Sie melden, dass feindselige Eingaben im Zuordnungsraum nicht robust sind, d. h., das Maskieren einiger Merkmale mit starker Zuordnung führt bei den Beispielen für feindselige Angriffe zu einer Unentschiedenheit des ML-Modells in Bezug auf Änderungen. Im Gegensatz dazu sind natürliche Eingaben im Zuordnungsraum robust.
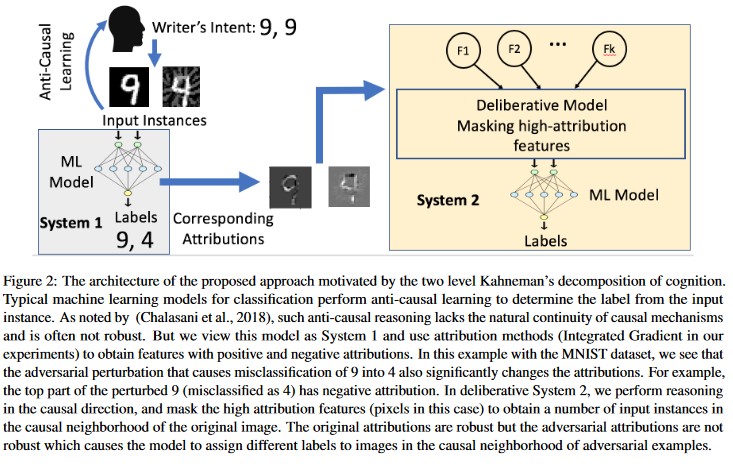 [20]
[20]
Diese Ansätze können ML-Modelle resilienter gegenüber feindseligen Angriffen machen, da zum Täuschen dieses zweischichtigen kognitiven Systems nicht nur das ursprüngliche Modell angegriffen, sondern auch sichergestellt werden muss, dass die für das Beispiel für einen feindseligen Angriff generierte Zuordnung den ursprünglichen Beispielen ähneln muss. Beide Systeme müssen gleichzeitig kompromittiert werden, damit ein feindseliger Angriff erfolgreich ist.
Traditionelle Parallelen
Remote-Rechteerweiterungen, da der Angreifer nun die Kontrolle über Ihr Modell übernommen hat
Severity
Kritisch
Variante Nr. 1b: Quell-/Ziel-Fehlklassifizierung
Diese äußert sich durch den Versuch eines Angreifers, ein Modell zu veranlassen, die von ihm gewünschte Bezeichnung für eine bestimmte Eingabe zurückzugeben. Dadurch wird ein Modell in der Regel gezwungen, ein Falsch-positive- oder Falsch-negativ-Ergebnis zurückzugeben. Schließlich folgt die subtile Übernahme der Klassifizierungsgenauigkeit des Modells, wodurch ein Angreifer nach Belieben bestimmte Umgehungen einführen kann.
Dieser Angriff kann sich sehr nachteilig auf die Klassifizierungsgenauigkeit auswirken, er ist aber u. U. sehr zeitaufwendig. Ein Angreifer muss nicht nur die Quelldaten so manipulieren, dass sie nicht mehr ordnungsgemäß gekennzeichnet sind, sondern sie müssen auch konkret mit der gewünschten gefälschten Bezeichnung gekennzeichnet sein. Derartige Angriffe umfassen häufig mehrere Schritte/Versuche, um eine Fehlklassifizierung zu erzwingen [3]. Wenn das Modell anfällig in Bezug auf die Übertragung von Lernangriffen ist, die eine gezielte Fehlklassifizierung erzwingen, gibt es möglicherweise keinen erkennbaren Datenverkehrs-Footprint des Angreifers, da die Probingangriffe online erfolgen können.
Beispiele
Erzwingen, dass gutartige E-Mails als Spam klassifiziert werden oder dass ein bösartiges Beispiel nicht erkannt wird. Diese werden auch als Modellumgehungs- oder Mimikry-Angriffe bezeichnet.
Gegenmaßnahmen
Aktionen zur reaktiven/defensiven Erkennung
- Implementieren eines Schwellenwerts für die minimale Zeit zwischen Aufrufen der API, welche Klassifizierungsergebnisse liefern. Dadurch werden mehrstufige Angriffstests verlangsamt, da sich die insgesamt benötigte Zeit verlängert, um eine erfolgreiche Störung zu finden.
Proaktive/Schutzmaßnahmen
Feature-Denoising zur Verbesserung der gegnerischen Robustheit [22]: Die Autoren entwickeln eine neue Netzwerkarchitektur, die die gegnerische Robustheit durch Feature-Denoising erhöht. Konkret enthalten die Netzwerke Blöcke, die die Features mit nicht-lokalen Mitteln oder sonstigen Filtern entrauschen; es erfolgt ein End-to-End-Training aller Netzwerke. In Kombination mit Training in Bezug auf feindselige Angriffe verbessern die Featureentrauschungs-Netzwerke erheblich die heutige Robustheit gegenüber feindseligen Angriffen, sowohl in Bezug auf White-Box- als auch auf Black-Box-Angriffe.
Gegnerisches Training und Regularisierung: Trainieren Sie mit bekannten gegnerischen Beispielen, um Widerstandsfähigkeit und Robustheit gegenüber böswilligen Eingaben aufzubauen. Dies kann als eine Form von Regularisierung angesehen werden, bei dem die Norm von Eingabeverläufen sanktioniert wird und die Vorhersagefunktion der Klassifizierung glättet (während sich die Eingabespanne weitet). Dies schließt korrekte Klassifizierungen mit niedrigeren Zuverlässigkeitsbewertungen ein.
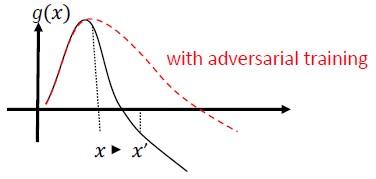
Investieren Sie in die Entwicklung monotoner Klassifizierungen mit Auswahl monotoner Features. Dadurch wird sichergestellt, dass der Angreifer nicht in der Lage ist, die Klassifizierung durch einfaches Auffüllen von Features aus der negativen Klasse zu umgehen [13].
Mit Feature Squeezing [18] können DNN-Modelle gehärtet werden, indem Beispiele für feindselige Angriffe erkannt werden. Dadurch wird der für einen Angreifer verfügbare Suchraum reduziert, indem Beispiele zusammengeführt werden, die vielen verschiedenen Feature-Vektoren im ursprünglichen Raum in einem einzigen Beispiel entsprechen. Durch Vergleichen der Vorhersage eines DNN-Modells in der ursprünglichen Eingabe mit der in der Squeezing-Eingabe kann das Feature Squeezing dazu beitragen, Beispiele für feindselige Angriffe zu erkennen. Wenn das ursprüngliche Beispiel und das Squeezing-Beispiel stark unterschiedliche Ausgaben aus dem Modell liefern, handelt es sich wahrscheinlich um eine feindselige Eingabe. Durch das Messen der Unstimmigkeit zwischen Vorhersagen und das Auswählen eines Schwellenwerts kann das System die korrekte Vorhersage für legitime Beispiele ausgeben, und feindselige Eingaben werden zurückgewiesen.

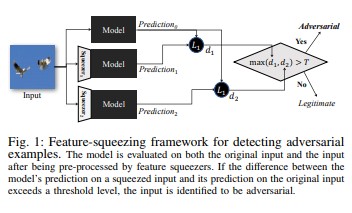 [18]
[18]Zertifizierte Verteidigung gegen kontradiktorische Beispiele [22]: Die Autoren schlagen eine Methode vor, die auf einer semi-definiten Entspannung basiert und ein Zertifikat ausgibt, dass für ein bestimmtes Netzwerk und eine Testeingabe kein Angriff dazu führen kann, dass der Fehler einen bestimmten Wert überschreitet. Da dieses Zertifikat zudem unterscheidbar ist, wird es von den Autoren gemeinsam mit den Netzwerkparametern optimiert, wodurch ein adaptiver Regularisierer erhalten wird, der Robustheit gegenüber sämtlichen Angriffen bietet.
Antwortaktionen
- Ausgeben von Warnungen zu Klassifizierungsergebnissen mit hoher Varianz zwischen Klassifizierern, insbesondere wenn diese auf einen Einzelbenutzer oder eine kleine Benutzergruppe zurückzuführen sind.
Traditionelle Parallelen
Remote-Rechteerweiterungen
Severity
Kritisch
Variante Nr. 1c: Zufällige Fehlklassifizierung
Dies ist eine spezielle Variante, bei der die Zielklassifizierung des Angreifers in beliebiger Weise von der legitimen Quellklassifizierung abweicht. Der Angriff beinhaltet generell die zufällige Injektion von Stördatenverkehr in die klassifizierten Quelldaten, um die Wahrscheinlichkeit einer richtigen Klassifizierung für die Zukunft zu verringern [3].
Beispiele
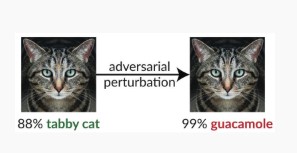
Gegenmaßnahmen
Wie bei Variante 1a.
Traditionelle Parallelen
Nicht beständiger Denial-of-Service (DoS)
Severity
Wichtig
Variante Nr. 1d: Vertrauensminderung
Ein Angreifer kann Eingaben erstellen, welche die Zuverlässigkeit der korrekten Klassifizierung reduzieren, insbesondere in Szenarien mit schwerwiegenden Folgen. Dabei kann u. a. eine große Anzahl von Falsch-positiv-Ergebnissen anfallen, sodass Administratoren oder Überwachungssysteme mit falschen Warnungen anstelle von legitimen Warnungen überschwemmt werden [3].
Beispiele

Gegenmaßnahmen
- Zusätzlich zu den in Variante 1a behandelten Maßnahmen kann die Ereignisdrosselung eingesetzt werden, um die Menge an Warnungen aus einer einzigen Quelle zu reduzieren.
Traditionelle Parallelen
Nicht beständiger Denial-of-Service (DoS)
Severity
Wichtig
#2a Gezielte Datenvergiftung
Beschreibung
Das Ziel des Angreifers besteht im Kontaminieren des in der Trainingsphase generierten Computermodells, sodass Vorhersagen für neue Daten in der Testphase modifiziert werden [1]. Bei zielgerichteten Poisoningangriffen streben Angreifer eine Fehlklassifizierung bestimmter Beispiele an, um zu bewirken, dass bestimmte Aktionen ausgeführt oder unterlassen werden.
Beispiele
Das Übermitteln von AV-Software als Malware, um ihre Fehlklassifizierung als bösartig zu bewirken, so dass die AV-Zielsoftware in Clientsystemen nicht mehr verwendet werden kann.
Gegenmaßnahmen
Definieren Sie Anomaliesensoren, um die Datenverteilung täglich zu untersuchen und Warnungen bei Abweichungen auszugeben.
– Messen Sie täglich Abweichungen in Trainingsdaten, Telemetriedaten für Schiefe/Drift
Eingabevalidierung, sowohl Bereinigung als auch Integritätsprüfung
Poisoninginjektionen von externen Trainingsbeispielen. Es gibt zwei grundlegende Strategien zur Bekämpfung dieser Bedrohung:
– Datenbereinigung/-validierung: Entfernen von Poisoningbeispielen aus Trainingsdaten – Bagging für die Bekämpfung von Poisoning [14]
– RONI-Schutz (Reject-on-Negative-Impact) [15]
-Robustes Lernen: Wählen Sie Lernalgorithmen aus, die bei Vorhandensein von Vergiftungsproben robust sind.
-Ein solcher Ansatz wird in [21] beschrieben, wo Autoren das Problem der Datenvergiftung in zwei Schritten angehen: 1) Einführung einer neuartigen robusten Matrixfaktorisierungsmethode zur Wiederherstellung des wahren Unterraums und 2) neuartige robuste Hauptkomponentenregression zur Bereinigung gegnerischer Instanzen basierend auf der in Schritt (1) wiederhergestellten Basis. Sie beschreiben die erforderlichen und ausreichenden Bedingungen für die erfolgreiche Rekonstruktion des wahren Subraums und präsentieren eine Grenze für den erwarteten Vorhersageverlust in Bezug auf die grundlegende Wahrheit.
Traditionelle Parallelen
Trojanerinfizierter Host, bei dem der Angreifer im Netzwerk verbleibt. Trainings- oder Konfigurationsdaten werden kompromittiert und bei der Modellerstellung erfasst/als vertrauenswürdig eingestuft.
Severity
Kritisch
#2b Willkürliche Datenvergiftung
Beschreibung
Ziel ist die Zerstörung der Qualität/Integrität des angegriffenen Datasets. Viele Datasets sind öffentlich, nicht vertrauenswürdig oder nicht kuratiert. Dies schafft zusätzliche Probleme rund um die Fähigkeit, derartige Verletzungen der Datenintegrität überhaupt zu bemerken. Das Training mit unwissentlich kompromittierten Daten schafft eine Garbage-In/Garbage Out-Situation. Nach der Erkennung muss mit einer Selektierung das Ausmaß der kompromittierten Daten bestimmt, und die Daten müssen in die Quarantäne verschoben/neu trainiert werden.
Beispiele
Ein Unternehmen liest Daten zu Erdöl-Futures von einer bekannten und vertrauenswürdigen Website aus, um seine Modelle zu trainieren. Die Website des Datenanbieters wird nachfolgend durch einen Angriff mit Einschleusung von SQL-Befehlen kompromittiert. Der Angreifer kann ein Poisoning des Datasets nach Belieben ausführen, und das trainierte Modell geht nicht davon aus, dass die Daten verfälscht sind.
Gegenmaßnahmen
Wie bei Variante 2a.
Traditionelle Parallelen
Authentifizierter Denial-of-Service-Angriff gegen eine hochwertige Ressource
Severity
Wichtig
#3 Modellinversionsangriffe
Beschreibung
Die in Modellen für maschinelles Lernen verwendeten privaten Funktionen können wiederhergestellt werden [1]. Dies schließt auch die Rekonstruktion privater Trainingsdaten ein, auf die der Angreifer keinen Zugriff hat. In der Biometrie-Community auch als Hill-Climbing-Angriffe bezeichnet [16, 17]. Dies wird erreicht durch Bestimmen der Eingabe, bei der die zurückgegebene Konfidenz maximiert wird, entsprechend der Klassifizierung für das Ziel [4].
Beispiele
 [4]
[4]
Gegenmaßnahmen
Bei Schnittstellen mit Modellen, welche anhand von vertraulichen Daten trainiert werden, ist eine strikte Zugriffssteuerung erforderlich.
Vom Modell zugelassene Ratenlimits für Abfragen
Implementieren Sie Gates zwischen Benutzern/Aufrufern und dem tatsächlichen Modell, indem Sie die Eingabevalidierung für alle eingereichten Abfragen ausführen, sodass alles zurückgewiesen wird, das nicht der Modelldefinition für korrekte Eingaben entspricht und nur die Menge an Informationen zurückgegeben wird, die für ihre Nützlichkeit mindestens erforderlich ist.
Traditionelle Parallelen
Zielgerichtete, verdeckte Veröffentlichung von Informationen
Severity
Wird laut SDL-Standardfehlerleiste als Wichtig eingestuft, beim Extrahieren vertraulicher oder personenbezogener Daten würde jedoch eine Hochstufung auf Kritisch erfolgen.
#4 Angriff auf Mitgliedschaftsinferenz
Beschreibung
Der Angreifer kann bestimmen, ob ein bestimmter Datensatz zum Trainingsdataset des Modells gehörte oder nicht [1]. Forscher konnten anhand der Merkmale (z. B. Alter, Geschlecht, Krankenhaus) den wichtigsten Eingriff eines Patienten vorhersagen (z. B. die Operation, der sich der Patient unterzogen hat) [1].
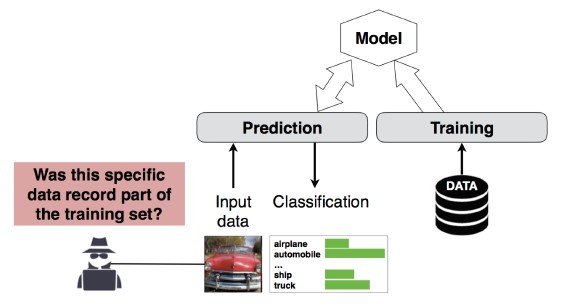 [12]
[12]
Gegenmaßnahmen
Forschungsberichte, die die Machbarkeit eines solchen Angriffs nachweisen, deuten darauf hin, dass Differential Privacy [4, 9] eine effektive Risikominderung darstellt. Dies ist noch ein relativ junges Feld bei Microsoft, und AETHER Security Engineering empfiehlt, Fachkenntnisse anhand von entsprechenden Forschungsaktivitäten zu gewinnen. Bei solchen Forschungsarbeiten müssen Differential Privacy-Funktionen ausgeführt werden, und ihre praktische Wirksamkeit bei der Risikominderung ist zu bewerten. Anschließend sind Möglichkeiten zu entwickeln, wie diese Verteidigungsmaßnahmen in unseren Onlinedienstplattformen transparent geerbt werden können, ähnlich wie Ihnen die Kompilierung von Code in Visual Studio standardmäßige Sicherheitsmaßnahmen liefert, die für Entwickler und Benutzer transparent sind.
In gewissem Maß können Neuronendropout und Modellstapelung effektive Risikominderungen darstellen. Die Nutzung des Neuronendropouts vergrößert nicht nur die Resilienz eines neuronalen Netzes gegenüber diesem Angriff, sondern steigert auch die Modellleistung [4].
Traditionelle Parallelen
Datenschutz. Rückschlüsse werden zur Einbindung eines Datenpunkts in den Trainingsdatensatz gezogen, die Trainingsdaten selbst werden jedoch nicht offengelegt.
Severity
Dies ist ein Datenschutzproblem und kein Sicherheitsproblem. Es wird im Leitfaden zur Bedrohungsmodellierung angesprochen, da diese Bereiche einander überschneiden, jede Antwort hier wäre jedoch auf den Datenschutz und nicht auf die Sicherheit ausgerichtet.
#5 Modeldiebstahl
Beschreibung
Die Angreifer erstellen das zugrunde liegende Modell neu, indem sie es legitim abfragen. Der Funktionsumfang des neuen Modells ist mit dem des zugrunde liegenden Modells identisch [1]. Sobald das Modell neu erstellt wurde, kann es invertiert werden, um Featureinformationen zu rekonstruieren oder Rückschlüsse auf Trainingsdaten zu ziehen.
Lösen von Gleichungen: Für ein Modell, das über API-Ausgaben Klassenwahrscheinlichkeiten zurückgibt, kann ein Angreifer Abfragen erstellen, mit denen unbekannte Variablen in einem Modell bestimmt werden.
Pathfinding: Ein Angriff, der API-Besonderheiten ausnutzt, um die von einem Baum bei der Klassifizierung einer Eingabe getroffenen „Entscheidungen“ zu extrahieren [7].
Übertragbarkeitsangriffe: Ein Angreifer kann ein lokales Modell trainieren (u. a. durch Senden von Vorhersageabfragen an das Zielmodell) und damit Beispiele für feindselige Angriffe erstellen, die an das Zielmodell übertragen werden [8]. Wenn das Modell extrahiert und als anfällig gegenüber einer Form von feindseliger Eingabe befunden wird, können neue Angriffe gegen Ihr Produktionsmodell von dem Angreifer komplett offline entwickelt werden, der eine Kopie Ihres Modells extrahiert hat.
Beispiele
In Settings, in denen ein ML-Modell feindseliges Verhalten erkennen soll (wie Erkennung von Spam, Klassifizierung von Schadsoftware und Bestimmung von Netzwerkanomalien), kann die Modellextrahierung Umgehungsangriffe ermöglichen [7].
Gegenmaßnahmen
Proaktive/Schutzmaßnahmen
Minimieren oder Verbergen der in Vorhersage-APIs zurückgegebenen Details bei gleichzeitiger Erhaltung ihrer Nützlichkeit für „ehrliche“ Anwendungen [7].
Definieren einer wohlgeformten Abfrage für Modelleingaben und ausschließliche Rückgabe von Ergebnissen als Antwort auf vollständige, wohlgeformte Eingaben, die diesem Format entsprechen.
Zurückgeben gerundeter Confidence-Werte. Die meisten legitimen Aufrufer benötigen keine Genauigkeitswerte mit mehreren Dezimalstellen.
Traditionelle Parallelen
Nicht authentifizierte, schreibgeschützte Manipulation von Systemdaten, gezielte Veröffentlichung hochwertiger Informationen?
Severity
Wichtig in sicherheitsrelevanten Modellen, andernfalls Mittel
#6 Neuprogrammierung neuronaler Netze
Beschreibung
Mit einer eigens erstellten Abfrage eines Angreifers können ML-Systeme für eine Aufgabe neu programmiert werden, die von der ursprünglichen Absicht ihres Erstellers abweicht [1].
Beispiele
Schwache Zugriffssteuerungen in einer Gesichtserkennungs-API ermöglichen Dritten die Identitätsvortäuschung in Apps, welche Microsoft-Kunden schädigen kann, z. B. mit einem Deepfake-Generator.
Gegenmaßnahmen
Starke gegenseitige Client<->Server-Authentifizierung und Zugriffskontrolle auf Modellschnittstellen
Entfernen der problematischen Konten.
Identifizieren und Erzwingen einer Vereinbarung zum Servicelevel für Ihre APIs. Bestimmen Sie die akzeptable Dauer der Behebung eines Problems nach seiner Meldung, und stellen Sie sicher, dass das Problem auch nach Ablauf der SLA nicht mehr reproduziert wird.
Traditionelle Parallelen
Dies ist ein Missbrauchsszenario. Sie eröffnen hier wahrscheinlich keinen Sicherheitsvorfall, sondern deaktivieren einfach das Konto des Angreifers.
Severity
Wichtig bis Kritisch
#7 Widersprüchliches Beispiel im physikalischen Bereich (Bits->Atome)
Beschreibung
Ein gegnerisches Beispiel ist eine Eingabe/Anfrage einer böswilligen Entität, die ausschließlich mit dem Ziel gesendet wird, das maschinelle Lernsystem in die Irre zu führen [1]
Beispiele
Solche Beispiele können sich in der physischen Umgebung manifestieren. So kann beispielsweise ein selbstfahrendes Fahrzeug mit einer bestimmten einem Verkehrsschild zugewiesenen Farbe (der feindseligen Eingabe) veranlasst werden, ein Stoppschild zu überfahren, da dieses vom Bilderkennungssystem nicht mehr als solches angesehen wird.
Traditionelle Parallelen
Rechteerweiterungen, Remotecodeausführung
Gegenmaßnahmen
Derartige Angriffe manifestieren sich, weil Probleme in der ML-Ebene (Daten- und Algorithmusebene unter der KI-gesteuerten Entscheidungsfindung) nicht behoben wurden. Wie bei jeder anderen Software *oder* jedem anderen physischen System kann die Schicht unter dem Ziel immer über herkömmliche Vektoren angegriffen werden. Daher sind traditionelle Sicherheitspraktiken wichtiger als je zuvor, insbesondere bei der Ebene der nicht behobenen Sicherheitsrisiken (Daten-/Algorithmusebene), die zwischen der KI und herkömmlicher Software verwendet wird.
Severity
Kritisch
#8 Schädliche ML-Anbieter, die Trainingsdaten wiederherstellen können
Beschreibung
Ein bösartiger Anbieter legt einen Hintertüralgorithmus vor, in dem die privaten Trainingsdaten rekonstruiert werden. Allein anhand des Modells konnten Gesichter und Texte rekonstruiert werden.
Traditionelle Parallelen
Zielgerichtete Veröffentlichung von Informationen
Gegenmaßnahmen
Forschungsberichte, die die Machbarkeit eines solchen Angriffs nachweisen, deuten darauf hin, dass homomorphe Verschlüsselung eine effektive Risikominderung darstellt. Dies ist ein Bereich, mit dem sich Microsoft derzeit wenig befasst, und AETHER Security Engineering empfiehlt, Fachkenntnisse anhand von entsprechenden Forschungsaktivitäten zu gewinnen. Bei derartigen Forschungen müssen Prinzipien der homomorphen Verschlüsselung umfassend untersucht werden, und ihre praktische Wirksamkeit als Entschärfung angesichts bösartiger ML-as-a-Service-Anbieter muss nachgewiesen werden.
Severity
Wichtig bei personenbezogenen Daten, andernfalls Mittel
#9 Angriff auf die ML-Lieferkette
Beschreibung
Aufgrund der großen Ressourcen (Daten + Berechnung), die zum Trainieren von Algorithmen erforderlich sind, besteht die derzeitige Praxis darin, von großen Unternehmen trainierte Modelle wiederzuverwenden und sie für die jeweilige Aufgabe leicht zu modifizieren (z. B. ResNet ist ein beliebtes Bilderkennungsmodell von Microsoft). Diese Modelle werden in einem sogenannten Model Zoo kuratiert (Caffe hostet gängige Bilderkennungsmodelle). Bei einem solchen Angriff greift der Gegner die in Caffe gehosteten Modelle an und kontaminiert damit die Daten für alle. [1]
Traditionelle Parallelen
Kompromittierung von nicht sicherheitsrelevanten Abhängigkeiten von Drittanbietern
App Store, in dem unwissentlich Schadsoftware gehostet wird
Gegenmaßnahmen
Minimieren Sie bei Daten und Modellen Abhängigkeiten von Drittanbietern, soweit dies möglich ist.
Integrieren Sie diese Abhängigkeiten in Ihren Prozess der Bedrohungsmodellierung.
Nutzen Sie strenge Authentifizierung, Zugriffssteuerung und Verschlüsselung zwischen Ihren Systemen und Systemen von Drittanbietern.
Severity
Kritisch
#10 Maschinelles Lernen durch die Hintertür
Beschreibung
Der Trainingsprozess wird an einen bösartigen Dritten ausgelagert, der Trainingsdaten manipuliert und ein trojanerinfiziertes Modell bereitstellt, das zielgerichtete Fehlklassifizierungen erzwingt – so wird beispielsweise ein bestimmter Virus als nicht bösartig klassifiziert [1]. Dies ist ein Risiko in Szenarien mit ML-as-a-Service-Modellgenerierung.
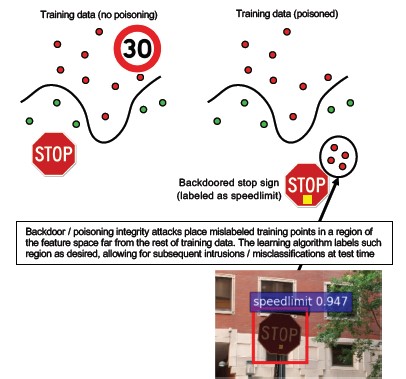 [12]
[12]
Traditionelle Parallelen
Kompromittierung von sicherheitsrelevanten Abhängigkeiten von Drittanbietern
Kompromittierter Softwareupdate-Mechanismus
Kompromittierung einer Zertifizierungsstelle
Gegenmaßnahmen
Aktionen zur reaktiven/defensiven Erkennung
- Bei Erkennen dieser Bedrohung ist der Schaden bereits angerichtet. Daher sind das Modell und alle vom bösartigen Anbieter bereitgestellten Trainingsdaten nicht vertrauenswürdig.
Proaktive/Schutzmaßnahmen
Trainieren Sie alle sensiblen Modelle intern.
Katalogisieren Sie Trainingsdaten oder stellen Sie mit strengen Sicherheitspraktiken sicher, dass sie von einem vertrauenswürdigen Drittanbieter stammen.
Erstellen Sie ein Bedrohungsmodell der Interaktion zwischen dem MLaaS-Anbieter und Ihrem eigenen System.
Antwortaktionen
- Wie bei der Kompromittierung externer Abhängigkeiten
Severity
Kritisch
#11 Softwareabhängigkeiten des ML-Systems ausnutzen
Beschreibung
Bei diesem Angriff werden die Algorithmen vom Angreifer NICHT manipuliert. Stattdessen werden Softwareschwachstellen wie Pufferüberläufe oder websiteübergreifendes Skripting ausgenutzt [1]. Es ist immer noch einfacher, Softwareebenen unterhalb der KI/ML-Ebene zu kompromittieren, als die Lernebene direkt anzugreifen. Daher sind im Security Development Lifecycle erläuterte herkömmliche Praktiken zur Entschärfung von Sicherheitsbedrohungen unverzichtbar.
Traditionelle Parallelen
Kompromittierte Open Source-Softwareabhängigkeit
Anfälligkeit von Webservern (XSS, CSRF, Fehler bei der API-Eingabeüberprüfung)
Gegenmaßnahmen
Sorgen Sie gemeinsam mit Ihrem Sicherheitsteam dafür, dass die entsprechenden bewährten Methoden aus Security Development Lifecycle/Operational Security Assurance befolgt werden.
Severity
Variabel; bis zu Kritisch, je nach Art des traditionellen Softwaresicherheitsrisikos.
Quellenangaben
[1] Fehlermodi beim maschinellen Lernen, Ram Shankar Siva Kumar, David O’Brien, Kendra Albert, Salome Viljoen und Jeffrey Snover, https://learn.microsoft.com/security/failure-modes-in-machine-learning
[2] AETHER Security Engineering Workstream, Data Provenance/Lineage v-team
[3] Kontroverse Beispiele im Deep Learning: Charakterisierung und Divergenz, Wei, et al. https://arxiv.org/pdf/1807.00051.pdf
[4] ML-Leaks: Modell- und datenunabhängige Mitgliedschaftsinferenzangriffe und -verteidigungen auf Modellen des maschinellen Lernens, Salem et al. https://arxiv.org/pdf/1806.01246v2.pdf
[5] M. Fredrikson, S. Jha und T. Ristenpart, „Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures“ (Modellherleitungsangriffe unter Ausnutzung von Confidence-Informationen und einfache Gegenmaßnahmen), in Bericht der 2015 ACM SIGSAC Conference on Computer and Communications Security (CCS).
[6] Nicolas Papernot und Patrick McDaniel: Adversarial Examples in Machine Learning (Beispiele für feindselige Angriffe in Machine Learning), AIWTB 2017
[7] Stealing Machine Learning Models via Prediction APIs (Stehlen von ML-Modellen über Vorhersage-APIs), Florian Tramèr, École Polytechnique Fédérale de Lausanne (EPFL); Fan Zhang, Cornell University; Ari Juels, Cornell Tech; Michael K. Reiter, The University of North Carolina at Chapel Hill; Thomas Ristenpart, Cornell Tech
[8] The Space of Transferable Adversarial Examples (Raum für übertragbare Beispiele für feindselige Angriffe), Florian Tramèr , Nicolas Papernot, Ian Goodfellow, Dan Boneh und Patrick McDaniel
[9] Understanding Membership Inferences on Well-Generalized Learning Models (Grundlegendes zur Rückschlüssen auf Mitgliedschaften in gut verallgemeinerten Lernmodellen), Yunhui Long1 , Vincent Bindschaedler1 , Lei Wang2 , Diyue Bu2 , Xiaofeng Wang2 , Haixu Tang2 , Carl A. Gunter1 und Kai Chen3,4
[10] Simon-Gabriel et al., Adversarial vulnerability of neural networks increases with input dimension (Anfälligkeit neuronaler Netze gegenüber feindseligen Angriffen steigt mit Eingabedimension), ArXiv 2018;
[11] Lyu et al., A unified gradient regularization family for adversarial examples (Vereinheitlichte Familie der stufenweisen Abgrenzung für Beispiele für feindselige Angriffe), ICDM 2015
[12] Wild Patterns: Zehn Jahre nach dem Aufstieg des kontradiktorischen maschinellen Lernens – NeCS 2019 Battista Biggioa, Fabio Roli
[13] Adversarially Robust Malware Detection UsingMonotonic Classification (Gegenüber feindseligen Angriffen robuste Schadsoftwareerkennung mit monotoner Klassifizierung), Inigo Incer et al.
[14] Battista Biggio, Igino Corona, Giorgio Fumera, Giorgio Giacinto und Fabio Roli. Bagging Classifiers for Fighting Poisoning Attacks in Adversarial Classification Tasks (Bagging-Klassifizierungen zur Bekämpfung von Poisoningangriffen in Aufgaben zur Klassifizierung feindseliger Angriffe)
[15] Eine verbesserte Ablehnung der Verteidigung gegen negative Auswirkungen Hongjiang Li und Patrick P.K. Chan
[16] Adler. Vulnerabilities in biometric encryption systems. (Sicherheitsrisiken in biometrischen Verschlüsselungssystemen.) 5th International Conference. AVBPA, 2005
[17] Galbally, McCool, Fierrez, Marcel, Ortega-Garcia. On the vulnerability of face verification systems to hill-climbing attacks. (Zur Anfälligkeit von Gesichtsüberprüfungssystemen gegenüber Hill-Climbing-Angriffen), Patt. Rec., 2010
[18] Weilin Xu, David Evans, Yanjun Qi. Feature Squeezing: Erkennung gegnerischer Beispiele in tiefen neuronalen Netzen. 2018 Network and Distributed System Security Symposium. 18. bis 21. Februar.
[19] Reinforcing Adversarial Robustness using Model Confidence Induced by Adversarial Training (Stärken der Robustheit gegen feindselige Angriffe mit höherer Modell-Confidence durch Training in Bezug auf feindselige Angriffe), Xi Wu, Uyeong Jang, Jiefeng Chen, Lingjiao Chen, Somesh Jha
[20] Attribution-driven Causal Analysis for Detection of Adversarial Examples (Zuordnungsgesteuerte Ursachenanalyse für Erkennung von Beispielen für feindselige Angriffe), Susmit Jha, Sunny Raj, Steven Fernandes, Sumit Kumar Jha, Somesh Jha, Gunjan Verma, Brian Jalaian, Ananthram Swami
[21] Robust Linear Regression Against Training Data Poisoning (Robuste lineare Regression gegen Poisoning von Trainingsdaten), Chang Liu et al.
[22] Feature Denoising for Improving Adversarial Robustness (Entrauschen von Features zum Verbessern der Robustheit gegenüber feindseligen Angriffen), Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille, Kaiming He
[23] Certified Defenses against Adversarial Examples (Zertifizierte Verteidigungsmöglichkeiten gegen Beispiele für feindselige Angriffe), Aditi Raghunathan, Jacob Steinhardt, Percy Liang
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für