Verwenden einer auf Big Data-Cluster für SQL Server bereitgestellten App mithilfe eines RESTful-Webdiensts
Gilt für: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
In diesem Artikel wird beschrieben, wie Sie mithilfe eines RESTful-Webdiensts eine auf einem Big Data-Cluster für SQL Server bereitgestellte App verwenden.
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
Voraussetzungen
- Big Data-Cluster für SQL Server
- Azure Data CLI (
azdata) - Eine App, die entweder mithilfe von azdata oder der App-Bereitstellungserweiterung bereitgestellt wird
Hinweis
Wenn die YAML-Spezifikationsdatei der Anwendung einen Zeitplan vorgibt, wird die Anwendung über einen Cron-Auftrag ausgelöst. Wenn Ihr Big Data-Cluster in OpenShift bereitgestellt wird, sind zusätzliche Funktionen erforderlich,um den Cron-Auftrag zu starten. Weitere Informationen finden Sie in den Sicherheitshinweisen zu OpenShift.
Funktionen
Nachdem Sie eine Anwendung auf Ihrer Instanz von SQL Server 2019: Big Data-Cluster bereitgestellt haben, können Sie mithilfe eines RESTful-Webdiensts auf diese Anwendung zugreifen und sie verwenden. Dadurch kann diese App aus anderen Anwendungen oder Diensten (z. B. einer mobile App oder Website) integriert werden. In der folgenden Tabelle werden die Befehle zur Anwendungsbereitstellung beschrieben, die Sie mit azdata verwenden können, um Informationen zum RESTful-Webdienst Ihrer App abzurufen.
| Get-Help | BESCHREIBUNG |
|---|---|
azdata app describe |
Beschreiben einer Anwendung. |
Mit dem Parameter --help können Sie wie im folgenden Beispiel Hilfe erhalten:
azdata app describe --help
In den folgenden Abschnitten wird beschrieben, wie Sie einen Endpunkt für eine Anwendung abrufen und wie Sie den RESTful-Webdienst zur Anwendungsintegration verwenden.
Abrufen des Endpunkts
Big Data-Cluster bieten Endpunkte, auf die Sie über einen RESTful-Webdienst zugreifen können, um diese Anwendung zu verwenden. Der Hauptzweck besteht darin, die Interaktion mit anderen webbasierten oder mobilen Anwendungen zu vereinfachen und proaktivere Funktionen für diese Microservicearchitektur zu bieten. Der Befehl azdata app describe stellt Informationen zur App bereit, darunter auch den Endpunkt in Ihrem Cluster. Dieser wird in der Regel von einem App-Entwickler dazu verwendet, eine App mithilfe des Swagger-Clients zu erstellen und mithilfe des Webdiensts RESTful mit der App zu interagieren.
Beschreiben Sie Ihre App, indem Sie einen Befehl wie den folgenden ausführen:
azdata app describe --name add-app --version v1
{
"input_param_defs": [
{
"name": "x",
"type": "int"
},
{
"name": "y",
"type": "int"
}
],
"links": {
"app": "https://10.1.1.3:30080/app/addpy/v1",
"swagger": "https://10.1.1.3:30080/app/addpy/v1/swagger.json"
},
"name": "add-app",
"output_param_defs": [
{
"name": "result",
"type": "int"
}
],
"state": "Ready",
"version": "v1"
}
Notieren Sie sich die IP-Adresse (10.1.1.3 in diesem Beispiel) und die Portnummer (30080) aus der Ausgabe.
Sie können diese Informationen auch abrufen, indem Sie auf dem Server in Azure Data Studio mit der rechten Maustaste auf „Verwalten“ klicken. Dort werden die Endpunkte der aufgeführten Dienste angezeigt.
Generieren eines JWT-Zugriffstokens
Um auf den RESTful-Webdienst für die von Ihnen bereitgestellte App zugreifen zu können, müssen Sie zunächst ein JWT-Zugriffstoken generieren. Die URL für das Zugriffstoken hängt von der Version des Big Data-Clusters ab.
| Version | URL |
|---|---|
| GDR1 | https://[IP]:[PORT]/docs/swagger.json |
| Kumulatives Update 1 und höher | https://[IP]:[PORT]/api/v1/swagger.json |
Basierend auf der Ausgabe des vorherigen Beispiels, der CU4-Version, der IP-Adresse des Controllers (10.1.1.3 im Beispiel) und der Portnummer (30080), ergibt sich die folgende URL:
https://10.1.1.3 :30080/api/v1/swagger.json
Versionsinformationen finden Sie im Releaseverlauf.
Öffnen Sie die entsprechende URL in Ihrem Browser, und verwenden Sie dabei die IP-Adresse und den Port, die Sie zuvor mithilfe des Befehls describe abgerufen haben. Melden Sie sich mit denselben Anmeldeinformationen an, die Sie für azdata login verwendet haben.
Fügen Sie den Inhalt von swagger.json in den Swagger-Editor ein, um festzustellen, welche Methoden verfügbar sind:
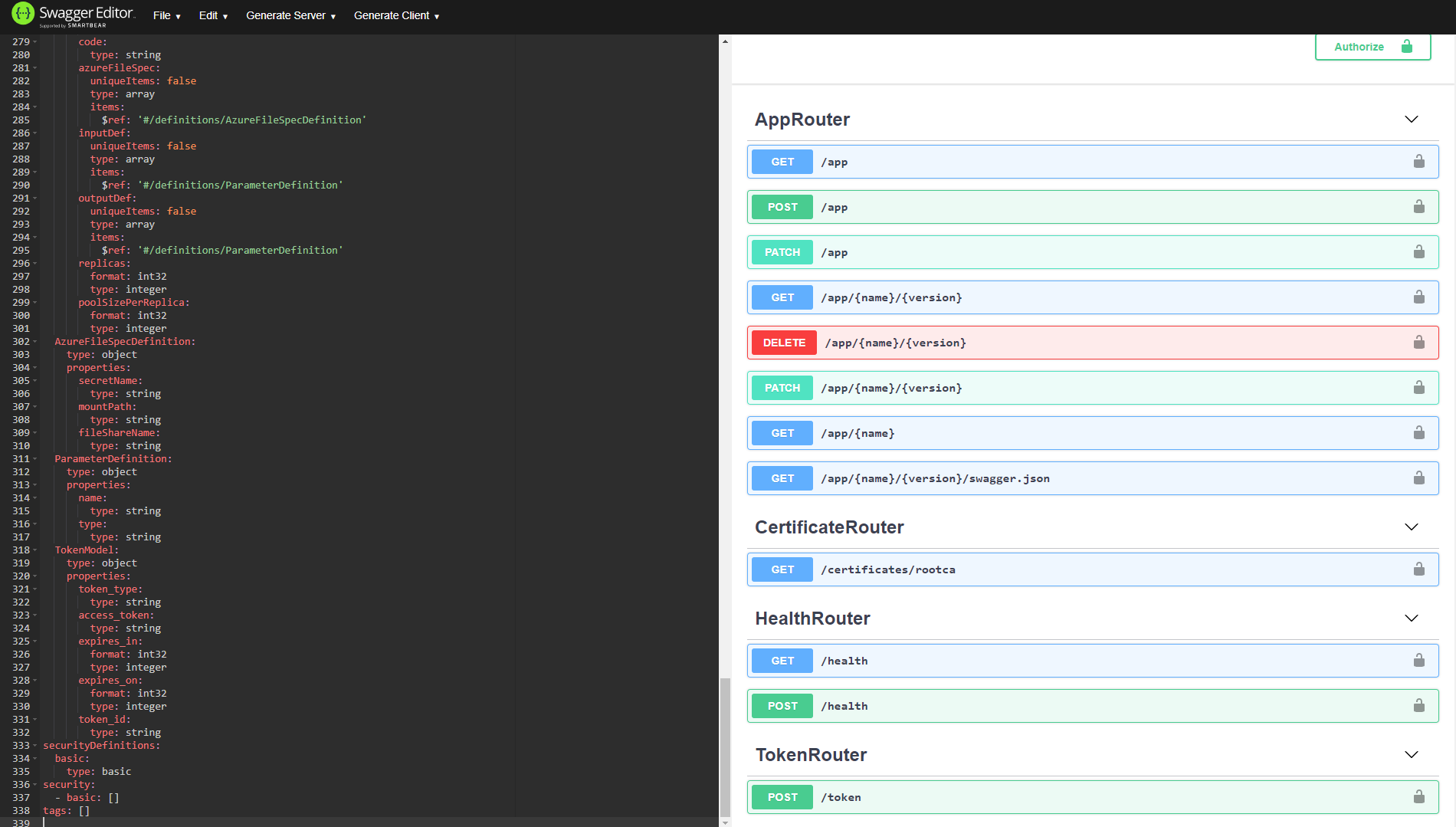
Hinweis: app ist die GET-Methode, und zum Abrufen von token wird die POST-Methode verwendet. Da für die App-Authentifizierung JWT-Token verwendet werden, müssen Sie mithilfe Ihres bevorzugten Tools ein Token abrufen, um einen POST-Aufruf für die token-Methode auszuführen. Unter Verwendung desselben Beispiels sieht die URL zum Abrufen des JWT-Tokens wie folgt aus:
https://10.1.1.3 :30080/api/v1/token
Als Ausgabe für diese Anforderung erhalten Sie ein JWT-access_token, das Sie für den Aufruf der URL zum Ausführen der App benötigen.
Ausführen der App mithilfe des RESTful-Webdiensts
Es gibt mehrere Möglichkeiten, eine App in SQL Server-Big Data-Cluster zu nutzen, beispielsweise über den Befehl „azdata app run“.
Sie können die URL für das Element swagger öffnen, das beim Ausführen von azdata app describe --name [appname] --version [version] in Ihrem Browser zurückgegeben wurde und ähnlich wie https://[IP]:[PORT]/app/[appname]/[version]/swagger.json sein sollte.
Hinweis
Sie müssen sich mit denselben Anmeldeinformationen anmelden, die Sie für azdata login verwendet haben. Unter Verwendung desselben Beispiels sieht der Befehl wie folgt aus:
azdata app describe --name add-app --version v1
Nächste Schritte
Lesen Sie Überwachen von Anwendungen in Big Data-Clustern, um weitere Informationen zu erhalten. Weitere Beispiele finden Sie außerdem unter den Beispielen zur App-Bereitstellung.
Weitere Informationen zu Big Data-Cluster für SQL Server finden Sie unter Was sind SQL Server 2019: Big Data-Cluster?.