Virtualisieren von CSV-Daten aus einem Speicherpool (Big Data-Cluster)
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
Big Data-Cluster in SQL Server können Daten aus CSV-Dateien in HDFS virtualisieren. Dieser Prozess ermöglicht es, dass die Daten am ursprünglichen Speicherort verbleiben und dennoch wie jede andere Tabelle von einer SQL Server-Instanz abgefragt werden können. Für dieses Feature werden PolyBase-Connectors verwendet. Der Bedarf für ETL-Prozesse wird dabei minimiert. Weitere Informationen zur Datenvirtualisierung finden Sie unter Einführung in die Datenvirtualisierung mit PolyBase.
Voraussetzungen
Auswählen oder Hochladen einer CSV-Datei zur Datenvirtualisierung
Stellen Sie in Azure Data Studio (ADS) eine Verbindung mit der SQL Server-Masterinstanz Ihres Big Data-Clusters her. Sobald die Verbindung hergestellt wurde, erweitern Sie die HDFS-Elemente im Objekt-Explorer, um nach den CSV-Dateien zu suchen, deren Daten Sie virtualisieren möchten.
Erstellen Sie für dieses Tutorial ein Verzeichnis namens Daten.
- Klicken Sie mit der rechten Maustaste auf das Kontextmenü des HDFS-Stammverzeichnisses.
- Wählen Sie Neues Verzeichnis aus.
- Benennen Sie das neue Verzeichnis mit Daten.
Laden Sie Beispieldaten hoch. Für eine einfache exemplarische Vorgehensweise können Sie eine Beispieldatei mit CSV-Daten verwenden. Für diesen Artikel werden Daten über die Gründe von Flugverspätungen des Verkehrsministeriums der Vereinigten Staaten verwendet. Laden Sie die Rohdaten herunter, und extrahieren Sie die Daten auf Ihrem Computer. Benennen Sie die Datei mit airline_delay_causes.csv.
So laden Sie die Beispieldatei nach dem Extrahieren hoch:
- Klicken Sie in Azure Data Studio mit der rechten Maustaste auf das Verzeichnis, das Sie neu erstellt haben.
- Wählen Sie Upload files (Dateien hochladen) aus.
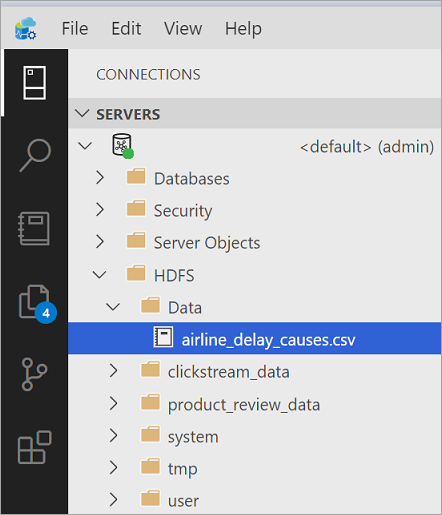
Azure Data Studio lädt die Dateien in HDFS in den Big Data-Cluster hoch.
Erstellen der externen Speicherpooldatenquelle in Ihrer Zieldatenbank
Die externe Speicherpooldatenquelle wird in einer Datenbank nicht standardmäßig in Ihrem Big Data-Cluster erstellt. Bevor Sie die externe Tabelle erstellen können, müssen Sie die externe Standarddatenquelle SqlStoragePool in Ihrer Zieldatenbank mit der folgenden Transact-SQL-Abfrage erstellen. Stellen Sie sicher, dass Sie zunächst den Kontext der Abfrage gemäß Ihrer Zieldatenbank ändern.
-- Create the default storage pool source for SQL Big Data Cluster
IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlStoragePool')
CREATE EXTERNAL DATA SOURCE SqlStoragePool
WITH (LOCATION = 'sqlhdfs://controller-svc/default');
Erstellen der externen Tabelle
Klicken Sie in ADS mit der rechten Maustaste auf die CSV-Datei, und wählen Sie im Kontextmenü Create External Table From CSV File (Externe Tabelle aus CSV-Datei erstellen) aus. Sie können externe Tabellen auch aus CSV-Dateien aus einem Verzeichnis in HDFS erstellen, wenn die Daten im Verzeichnis dem gleichen Schema folgen. Dies würde die Virtualisierung der Daten auf einer Verzeichnisebene ermöglichen, ohne einzelne Dateien verarbeiten und ein zusammengefügtes Ergebnis der kombinierten Daten abrufen zu müssen. Azure Data Studio führt Sie durch die Schritte zum Erstellen der externen Tabelle.
Geben Sie die Datenbank, die Datenquelle, einen Tabellennamen, das Schema und den Namen für das externe Dateiformat der Tabelle an.
Klicken Sie auf Weiter.
Datenvorschau
Azure Data Studio zeigt eine Vorschau der importierten Daten.
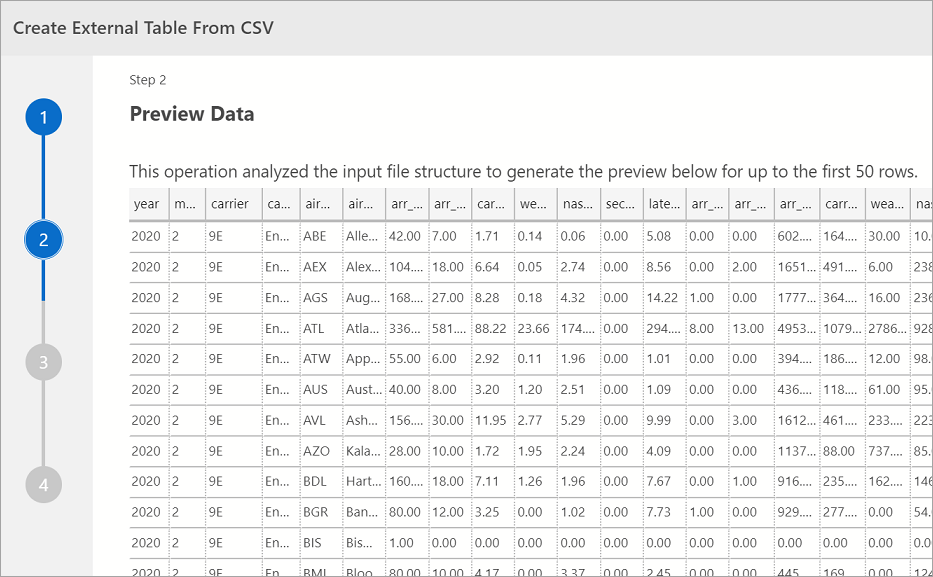
Wählen Sie Weiter aus, um fortzufahren, sobald Sie die Vorschau überprüft haben.
Bearbeiten von Spalten
Im daraufhin angezeigten Fenster können Sie die Spalten der externen Tabelle, die erstellt werden soll, bearbeiten. Sie können Spaltennamen ändern, den Datentyp ändern und Zeilen mit NULL-Werten zulassen.
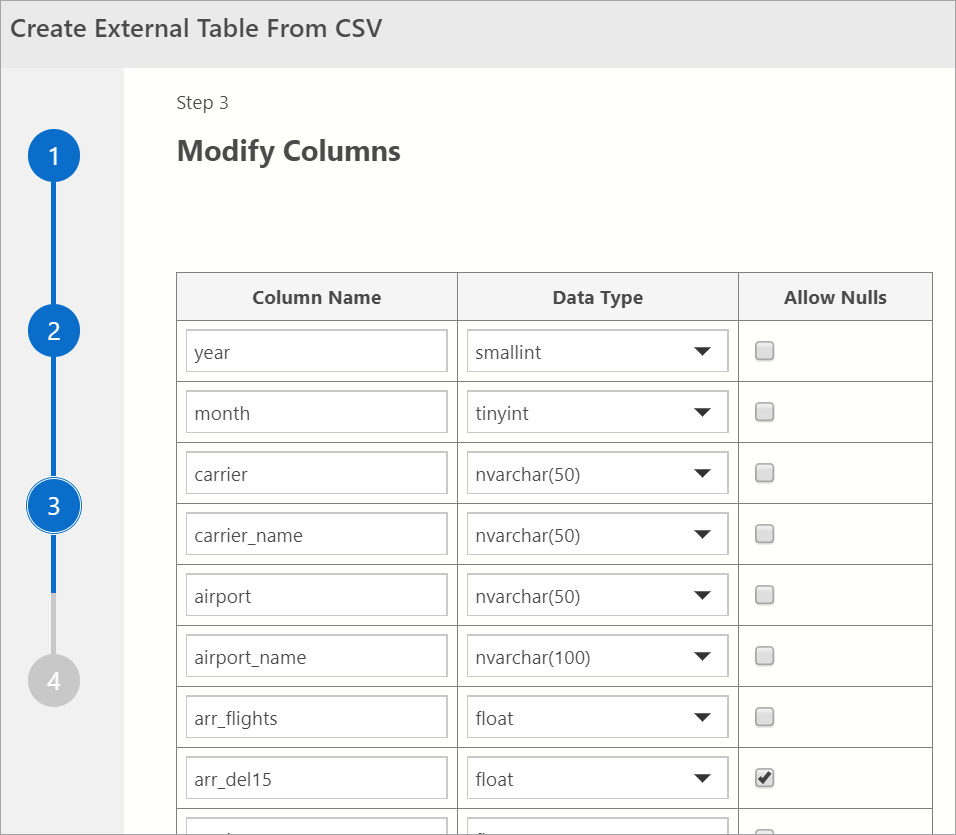
Wählen Sie Weiter aus, wenn Sie die Zielspalten überprüft haben.
Zusammenfassung
Dieser Schritt bietet eine Zusammenfassung Ihrer Auswahl. Der SQL Server-Name, der Name der Datenbank, der Name der Tabelle, das Tabellenschema und weitere Informationen zur externen Tabelle werden angezeigt. Bei diesem Schritt haben Sie die Möglichkeit, ein Skript zu generieren oder eine Tabelle zu erstellen. Skript generieren erstellt ein Skript in T-SQL, um die externe Datenquelle zu erstellen. Tabelle erstellen erstellt die externe Datenquelle.
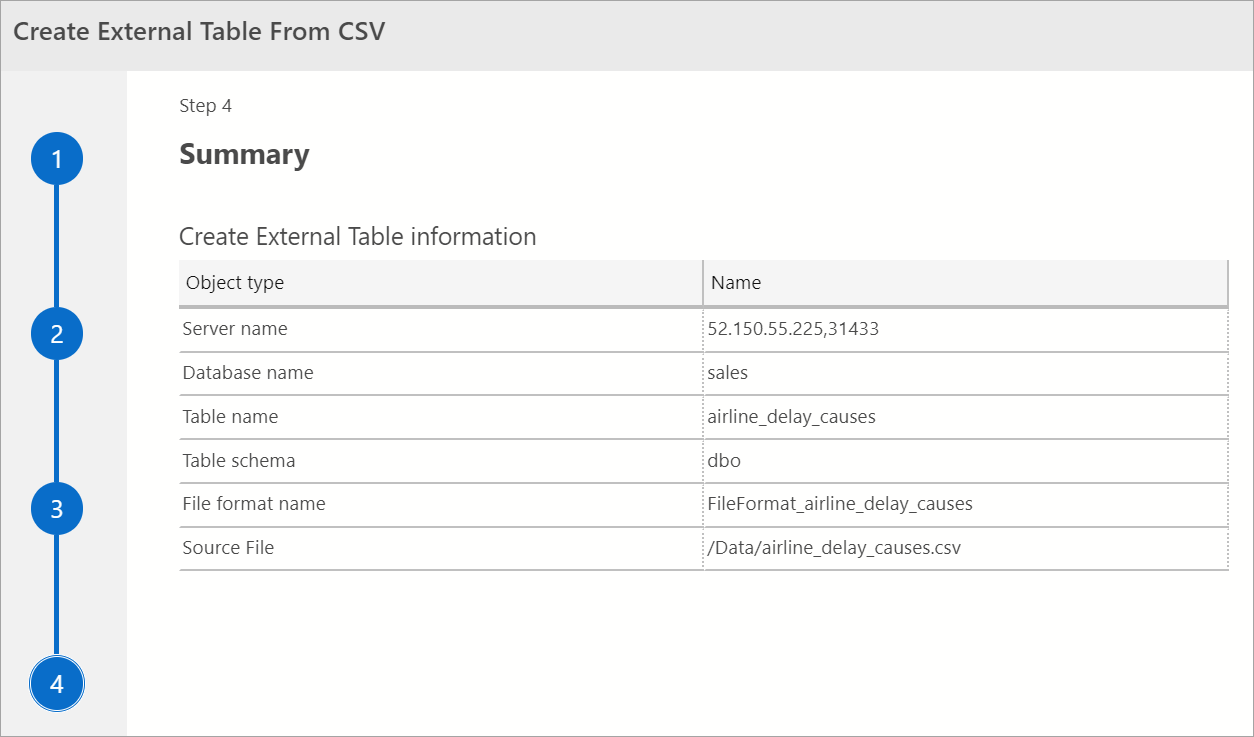
Wenn Sie Tabelle erstellen auswählen, erstellt SQL Server die externe Tabelle in der Zieldatenbank.
Wenn Sie Skript generieren auswählen, erstellt Ihre Azure Data Studio-Instanz die T-SQL-Abfrage für das Erstellen der externen Tabelle.
Sobald die Tabelle erstellt wurde, kann sie direkt mithilfe von T-SQL über die SQL Server-Instanz abgefragt werden.
Nächste Schritte
Weitere Informationen zu SQL Server-Big Data-Clustern und zugehörigen Szenarien finden Sie unter Einführung in Big Data-Cluster für SQL Server.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für