Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Die Big Data Cluster von Microsoft SQL Server 2019 werden eingestellt. Der Support für SQL Server 2019 Big Data Cluster endete am 28. Februar 2025. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und den Big Data-Optionen auf der Microsoft SQL Server-Plattform.
Da SQL Server-Big Data-Cluster bei Kubernetes als containerisierte Anwendungen eingesetzt werden und Funktionen wie zustandsbehaftete Mengen und persistente Speicherung verwenden, verfügt diese Infrastruktur über integrierte Integritätsüberwachungs-, Fehlererkennungs- und Failovermechanismen, die Clusterkomponenten nutzen, um die Dienstintegrität zu erhalten. Für eine höhere Zuverlässigkeit können Sie auch die SQL Server-Masterinstanz und/oder HDFS-Namensknoten und gemeinsame Spark-Dienste konfigurieren, um sie mit zusätzlichen Replikaten in einer hochverfügbaren Konfiguration bereitzustellen. Überwachung, Fehlererkennung und automatisches Failover werden von dem Verwaltungsdienst für Big Data-Cluster verwaltet, der auch als Steuerungsdienst bezeichnet wird. Dieser Dienst wird ohne Benutzereingriff bereitgestellt – vom Einrichten der Verfügbarkeitsgruppe, Konfigurieren von Endpunkten für die Datenbankspiegelung, Hinzufügen von Datenbanken zur Verfügbarkeitsgruppe bis hin zur Failover- und Upgradekoordination.
Die folgende Abbildung zeigt, wie eine Verfügbarkeitsgruppe in einem Big Data-Cluster in SQL Server bereitgestellt wird:
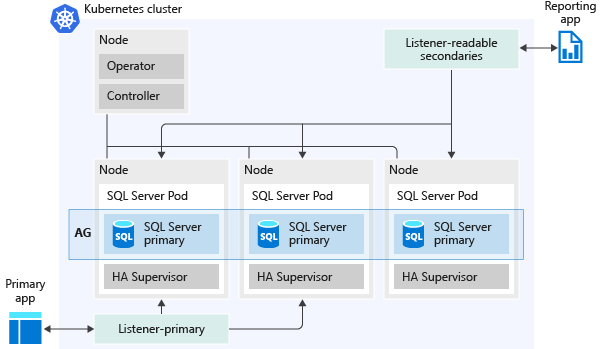
Dies sind einige der Möglichkeiten, die Ihnen Verfügbarkeitsgruppen bieten:
Wenn die Hochverfügbarkeitseinstellungen in der Konfigurationsdatei für die Bereitstellung angegeben sind, wird eine einzige Verfügbarkeitsgruppe mit dem Namen
containedagerstellt. Standardmäßig gibt es fürcontainedagdrei Replikate, einschließlich des primären Replikats. Alle CRUD-Vorgänge für die Verfügbarkeitsgruppe werden intern verwaltet – auch die Erstellung der Verfügbarkeitsgruppe oder die Verknüpfung von Replikaten mit der erstellten Verfügbarkeitsgruppe. Zusätzliche Verfügbarkeitsgruppen können in der SQL Server-Masterinstanz in einem Big Data-Cluster nicht erstellt werden.Alle Datenbanken werden automatisch zur Verfügbarkeitsgruppe hinzugefügt, einschließlich aller Benutzer- und Systemdatenbanken wie
masterundmsdb. Diese Funktion bietet eine Einzelsystemansicht zu den Replikaten der Verfügbarkeitsgruppen. Weitere Modelldatenbanken,model_replicatedmasterundmodel_msdb, werden für das Seeding des replizierten Teils der Systemdatenbanken verwendet. Zusätzlich zu diesen Datenbanken sehen Sie die Datenbankencontainedag_masterundcontainedag_msdb, wenn Sie sich direkt mit der Instanz verbinden. Diecontainedag-Datenbanken repräsentieren die Elementemasterundmsdbinnerhalb der Verfügbarkeitsgruppe.Important
Datenbanken, die infolge eines Workflows wie dem Anfügen einer Datenbank auf der Instanz erstellt werden, werden der Verfügbarkeitsgruppe nicht automatisch hinzugefügt. Administratoren von Big Data-Clustern in SQL Server müssen dies manuell durchführen. Informationen zum Aktivieren eines temporären Endpunkts für die Masterdatenbank der SQL Server-Instanz finden Sie unter Verbinden zur SQL Server-Instanz. Vor dem Release von SQL Server 2019 CU2 haben Datenbanken, die durch eine RESTORE-Anweisung erstellt wurden, dasselbe Verhalten aufgewiesen. Außerdem mussten Datenbanken manuell zur enthaltenen Verfügbarkeitsgruppe hinzugefügt werden.
PolyBase-Konfigurationsdatenbanken sind nicht in der Verfügbarkeitsgruppe enthalten, da sie für jedes Replikat spezifische Metadaten auf Instanzebene enthalten.
Ein externer Endpunkt wird automatisch für die Verbindung mit Datenbanken innerhalb der Verfügbarkeitsgruppe bereitgestellt. Der Endpunkt
master-svc-externalübernimmt die Rolle des Listeners der Verfügbarkeitsgruppe.Ein zweiter externer Endpunkt ist für schreibgeschützte Verbindungen zu den sekundären Replikaten vorgesehen, um die Workloads bei Lesevorgängen aufzuskalieren.
Deploy
So stellen Sie einen SQL Server-Master in einer Verfügbarkeitsgruppe bereit:
- Aktivieren Sie das
hadr-Feature. - Geben Sie die Anzahl der Replikate für die Verfügbarkeitsgruppe an (mindestens 3).
- Konfigurieren Sie die Details des zweiten externen Endpunkts, der für Verbindungen mit den schreibgeschützten sekundären Replikaten erstellt wurde.
Sie können entweder die integrierten aks-dev-test-ha- oder kubeadm-prod-Konfigurationsprofile verwenden, um die Big Data-Cluster anzupassen. Diese Profile enthalten die Einstellungen, die für Ressourcen erforderlich sind, für die Sie zusätzliche Hochverfügbarkeit konfigurieren können. Im Folgenden finden Sie beispielsweise einen Abschnitt in der bdc.json-Konfigurationsdatei, der für das Aktivieren von Verfügbarkeitsgruppen für eine SQL Server-Masterinstanz relevant ist.
{
...
"spec": {
"type": "Master",
"replicas": 3,
"endpoints": [
{
"name": "Master",
"serviceType": "LoadBalancer",
"port": 31433
},
{
"name": "MasterSecondary",
"serviceType": "LoadBalancer",
"port": 31436
}
],
"settings": {
"sql": {
"hadr.enabled": "true"
}
}
}
...
}
In den nächsten Schritten wird ein Beispiel dazu beschrieben, wie Sie die Konfiguration für Ihre Big Data-Clusterbereitstellung ausgehend von dem aks-dev-test-ha-Profil anpassen. Bei einer Bereitstellung in einem kubeadm-Cluster sind die Schritte ähnlich, aber stellen Sie sicher, dass Sie NodePort als serviceType im Abschnitt endpoints verwenden.
Klonen des Zielprofils
azdata bdc config init --source aks-dev-test-ha --target custom-aks-haOptional können Sie bei Bedarf Änderungen am benutzerdefinierten Profil vornehmen.
Beginnen Sie die Clusterbereitstellung mit dem oben erstellten Clusterkonfigurationsprofil.
azdata bdc create --config-profile custom-aks-ha --accept-eula yes
Verbinden mit SQL Server-Datenbanken in der Verfügbarkeitsgruppe
Abhängig von der Art der Workload, die Sie für den SQL Server-Master ausführen möchten, können Sie sich entweder mit dem primären Replikat für Lese- bzw. Schreibworkloads oder mit den Datenbanken in den sekundären Replikaten für schreibgeschützte Workloads verbinden. Hier ist eine Übersicht über die verschiedenen Verbindungstypen:
Verbinden mit Datenbanken im primären Replikat
Verwenden Sie für Verbindungen mit dem primären Replikat den Endpunkt sql-server-master. Dieser Endpunkt ist auch der Listener für die Verfügbarkeitsgruppe. Bei Verwendung dieses Endpunkts stehen alle Verbindungen im Kontext von Datenbanken innerhalb der Verfügbarkeitsgruppe. Eine Standardverbindung mit diesem Endpunkt führt beispielsweise dazu, dass eine Verbindung mit der master-Datenbank innerhalb der Verfügbarkeitsgruppe und nicht mit der master-Datenbank der SQL Server-Instanz hergestellt wird. Führen Sie diesen Befehl aus, um nach dem Endpunkt zu suchen:
azdata bdc endpoint list -e sql-server-master -o table
Description Endpoint Name Protocol
------------------------------------ ------------------- ----------------- ----------
SQL Server Master Instance Front-End 11.11.111.111,11111 sql-server-master tds
Note
Failoverereignisse können während der Ausführung einer verteilten Abfrage auftreten, die auf Daten aus Remotedatenquellen wie einem HDFS oder Datenpool zugreift. Es ist eine bewährte Methode, Anwendungen so zu konzipieren, dass sie über eine Wiederholungslogik für den Fall von Verbindungsabbrüchen durch Failover verfügen.
Verbinden mit Datenbanken in den sekundären Replikaten
Für schreibgeschützte Verbindungen mit Datenbanken in sekundären Replikaten verwenden Sie den Endpunkt sql-server-master-readonly. Dieser Endpunkt verhält sich wie ein Lastenausgleich über alle sekundären Replikate hinweg. Bei Verwendung dieses Endpunkts stehen alle Verbindungen im Kontext von Datenbanken innerhalb der Verfügbarkeitsgruppe. Eine Standardverbindung mit diesem Endpunkt führt beispielsweise dazu, dass eine Verbindung mit der master-Datenbank innerhalb der Verfügbarkeitsgruppe und nicht mit der master-Datenbank der SQL Server-Instanz hergestellt wird.
azdata bdc endpoint list -e sql-server-master-readonly -o table
Description Endpoint Name Protocol
--------------------------------------------- ------------------ -------------------------- ----------
SQL Server Master Readable Secondary Replicas 11.11.111.11,11111 sql-server-master-readonly tds
Verbinden mit einer SQL Server-Instanz
Für bestimmte Vorgänge, wie das Festlegen von Konfigurationen auf Serverebene oder das manuelle Hinzufügen einer Datenbank zur Verfügbarkeitsgruppe, müssen Sie eine Verbindung mit der SQL Server-Instanz herstellen. Vor SQL Server 2019 CU2 erforderten Vorgänge wie sp_configure, RESTORE DATABASE oder alle Verfügbarkeitsgruppen-DDLs diese Art von Verbindung. Standardmäßig enthält ein Big Data-Cluster keinen Endpunkt, der eine Instanzverbindung ermöglicht, und Sie müssen diesen Endpunkt manuell verfügbar machen.
Important
Der für SQL Server-Instanzverbindungen verfügbar gemachte Endpunkt unterstützt nur die SQL-Authentifizierung, selbst in Clustern, in denen Active Directory aktiviert ist. Standardmäßig ist bei einer Big Data-Clusterbereitstellung die sa-Anmeldung deaktiviert und eine neue sysadmin-Anmeldung wird basierend auf den Werten bereitgestellt, die zum Zeitpunkt der Bereitstellung für AZDATA_USERNAME und AZDATA_PASSWORD Umgebungsvariablen bereitgestellt werden.
Important
Die enthaltene Verfügbarkeitsgruppen-DDL wird in BDC ausschließlich selbst verwaltet. Jeder Versuch eines (externen Benutzers), die zugehörige Verfügbarkeit oder den Datenbankspiegelungsendpunkt abzulegen, wird nicht unterstützt und kann zu einem nicht wiederherstellbaren BDC-Zustand führen.
Das folgende Beispiel zeigt, wie Sie diesen Endpunkt verfügbar machen und dann die Datenbank, die mit einem Wiederherstellungsworkflow erstellt wurde, zur Verfügbarkeitsgruppe hinzufügen können. Es gelten ähnliche Anweisungen zum Einrichten einer Verbindung mit der SQL Server-Masterinstanz, wenn Sie Serverkonfigurationen mit sp_configure ändern möchten.
Note
Ab SQL Server 2019 CU2 werden Datenbanken, die aufgrund eines Wiederherstellungsworkflows erstellt wurden, automatisch zur enthaltenen Verfügbarkeitsgruppe hinzugefügt.
Bestimmen Sie den Pod, der das primäre Replikat hostet, indem Sie eine Verbindung mit dem
sql-server-master-Endpunkt herstellen und Folgendes ausführen:SELECT @@SERVERNAMEMachen Sie den externen Endpunkt verfügbar, indem Sie einen neuen Kubernetes-Dienst erstellen.
Führen Sie für einen
kubeadm-Cluster den folgenden Befehl aus. Ersetzen SiepodNamedurch den Namen des im vorherigen Schritt zurückgegebenen Servers,serviceNamedurch den bevorzugten Namen für den erstellten Kubernetes-Dienst undnamespaceName* durch den Namen Ihres Big Data-Clusters.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortFühren Sie für einen AKS-Cluster den gleichen Befehl aus, mit dem Unterschied, dass der Typ des erstellten Diensts dabei
LoadBalancerist. For example:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerNachfolgend finden Sie ein Beispiel für diesen Befehl, der für AKS ausgeführt wird, wobei
master-0der Pod ist, der das primäre Replikat hostet:kubectl -n mssql-cluster expose pod master-0 --port=1533 --name=master-sql-0 --type=LoadBalancerRufen Sie die IP-Adresse des erstellten Kubernetes-Diensts ab:
kubectl get services -n <namespaceName>
Important
Als bewährte Methode sollten Sie den oben erstellten Kubernetes-Dienst löschen, indem Sie diesen Befehl ausführen:
kubectl delete svc master-sql-0 -n mssql-cluster
Fügen Sie die Datenbank der Verfügbarkeitsgruppe hinzu.
Damit die Datenbank der Verfügbarkeitsgruppe hinzugefügt werden kann, muss Sie im vollständigen Wiederherstellungsmodell ausgeführt werden, und es muss eine Protokollsicherung durchgeführt werden. Verwenden der IP-Adresse des oben erstellten Kubernetes-Diensts, und herstellen einer Verbindung mit der SQL Server-Instanz. Dann wie unten gezeigt die TSQL-Anweisungen ausführen.
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>Im folgenden Beispiel wird die Datenbank
saleshinzugefügt, die auf der Instanz wiederhergestellt wurde:ALTER DATABASE sales SET RECOVERY FULL; BACKUP DATABASE sales TO DISK='/var/opt/mssql/data/sales.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE sales
Known limitations
Bekannte Probleme und Einschränkungen bei eigenständigen Verfügbarkeitsgruppen für SQL Server-Masterinstanzen in einem Big Data-Cluster sind:
- Die Konfiguration für Hochverfügbarkeit muss erstellt werden, sobald ein Big Data-Cluster bereitgestellt wird. Nach der Bereitstellung kann die Konfiguration für Hochverfügbarkeit mit Verfügbarkeitsgruppen nicht mehr aktiviert werden. Zurzeit ist nur die Konfiguration für Replikate mit synchronem Commit aktiviert.
Warning
Wenn Sie den Synchronisierungsmodus auf einen asynchronen Commit für eines der Replikate im Quorumcommit aktualisieren, führt dies zu einer ungültigen Konfiguration für Hochverfügbarkeit. Das Ausführen in dieser Konfiguration ist mit einem Datenverlustrisiko verbunden, da bei Fehlerereignissen, die das primäre Replikat betreffen, kein automatisches Failover ausgelöst wird und der Benutzer beim Auslösen eines manuellen Failovers das Datenverlustrisiko akzeptieren muss.
- Sie müssen sicherstellen, dass die erforderlichen Zertifikate sowohl in der SQL Server-Masterinstanz als auch in der enthaltenen Verfügbarkeitsgruppen-Masterinstanz wiederhergestellt werden, um eine TDE-fähige Datenbank erfolgreich über eine Sicherung wiederherzustellen, die auf einem anderen Server erstellt wurde. Hier finden Sie ein Beispiel zur Sicherung und Wiederherstellung der Zertifikate.
- Für bestimmte Vorgänge wie das Ausführen von Serverkonfigurationseinstellungen mit
sp_configureist eine Verbindung mit dermaster-Datenbank der SQL Server-Instanz erforderlich, nicht mit der Verfügbarkeitsgruppemaster. Der entsprechende primäre Endpunkt kann nicht verwendet werden. Befolgen Sie die Anweisungen, um einen Endpunkt verfügbar zu machen, eine Verbindung mit der SQL Server-Instanz herzustellen undsp_configureauszuführen. Sie können die SQL-Authentifizierung nur verwenden, wenn Sie den Endpunkt manuell verfügbar machen, um eine Verbindung mit dermaster-Datenbank der SQL Server-Instanz herzustellen. - Obwohl die enthaltene msdb-Datenbank in der Verfügbarkeitsgruppe enthalten ist und die SQL-Agent-Aufträge darin repliziert werden, werden die Aufträge nur auf dem primären Replikat nach Zeitplan ausgeführt.
- Das Feature „Replikation“ wird für enthaltene Verfügbarkeitsgruppen nicht unterstützt. SQL Server-Instanzen, die Teil einer enthaltenen Verfügbarkeitsgruppe sind, können nicht als Verteiler oder Herausgeber fungieren, weder auf Instanzebene noch auf Ebene der enthaltenen Verfügbarkeitsgruppe.
- Das Hinzufügen von Dateigruppen beim Erstellen der Datenbank wird nicht unterstützt. Um dieses Problem zu umgehen, können Sie zuerst die Datenbank erstellen und dann eine ALTER DATABASE-Anweisung ausführen, um beliebige Dateigruppen hinzuzufügen.
- Datenbanken, die vor SQL Server 2019 CU2 aufgrund von anderen Workflows als
CREATE DATABASEundRESTORE DATABASE, z. B.CREATE DATABASE FROM SNAPSHOT, erstellt wurden, werden nicht automatisch zur Verfügbarkeitsgruppe hinzugefügt. Stellen Sie eine Verbindung mit der Instanz her, und fügen Sie die Datenbank manuell zur Verfügbarkeitsgruppe hinzu. - Service Broker und Datenbank-E-Mail werden derzeit auf Big Data-Clustern nicht unterstützt, die mit Hochverfügbarkeit bereitgestellt wurden.
Next steps
- Weitere Informationen zum Verwenden von Konfigurationsdateien in Big Data-Clusterbereitstellungen finden Sie unter Bereitstellen von Big Data-Cluster für SQL Server in Kubernetes.
- Weitere Informationen zum Verfügbarkeitsgruppen-Feature für SQL Server finden Sie unter Übersicht über Always On-Verfügbarkeitsgruppen (SQL Server).