Ausführen eines Beispiel-Notebooks unter Verwendung von Spark
Gilt für: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
Dieses Tutorial veranschaulicht, wie Sie in Azure Data Studio ein Notebook für einen SQL Server 2019-Big Data-Cluster laden und ausführen. Dies ermöglicht es Data Scientists und Datentechnikern, Python-, R- oder Scala-Code für den Cluster auszuführen.
Tipp
Wenn Sie möchten, können Sie ein Skript für die Befehle in diesem Tutorial herunterladen und ausführen. Anweisungen finden Sie in den Spark-Beispielen auf GitHub.
Voraussetzungen
- Big-Data-Tools
- kubectl
- Azure Data Studio
- Erweiterung von SQL Server 2019
- Laden von Beispieldaten in einen Big Data-Cluster von SQL Server
Herunterladen der Notebook-Beispieldatei
Verwenden Sie die folgenden Anweisungen, um die Notebook-Beispieldatei spark-sql.ipynb in Azure Data Studio zu laden.
Öffnen Sie eine bash-Eingabeaufforderung (Linux) oder Windows PowerShell.
Navigieren Sie zu dem Verzeichnis, in das Sie die Notebook-Beispieldatei herunterladen möchten.
Führen Sie den folgenden curl-Befehl aus, um die Notebook-Datei von GitHub herunterzuladen:
curl https://raw.githubusercontent.com/Microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/data-loading/transform-csv-files.ipynb -o transform-csv-files.ipynb
Öffnen des Notebooks
In den folgenden Schritte ist gezeigt, wie Sie die Notebook-Datei in Azure Data Studio öffnen:
Stellen Sie in Azure Data Studio eine Verbindung mit der Masterinstanz Ihres Big-Data-Clusters her. Weitere Informationen finden Sie unter Herstellen einer Verbindung mit einem Big-Data-Cluster.
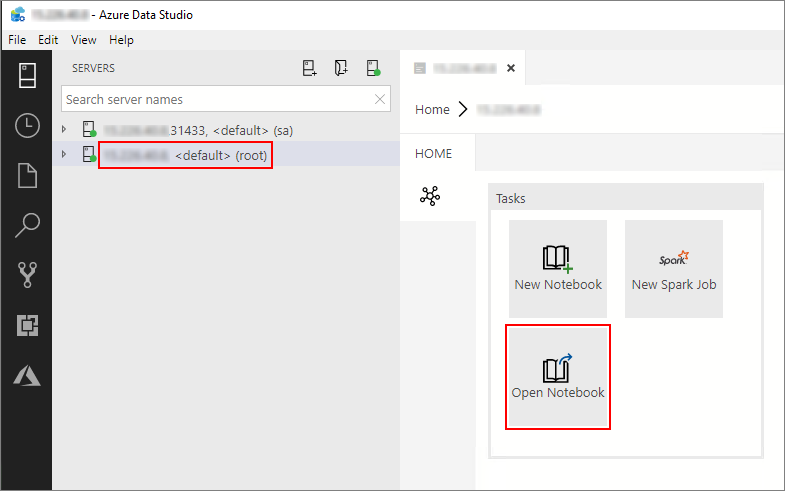
Doppelklicken Sie im Fenster Server auf die HDFS/Spark-Gatewayverbindung. Wählen Sie dann Notebook öffnen aus.
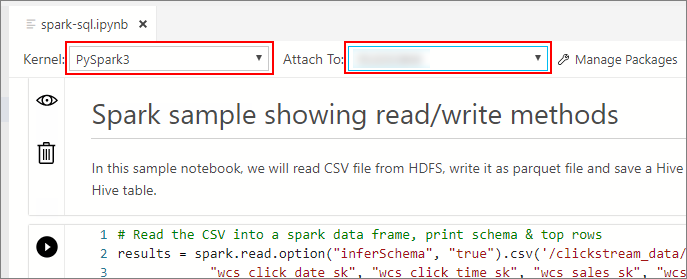
Warten Sie, bis die Felder für den Kernel und den Zielkontext (Anfügen an) ausgefüllt sind. Legen Sie den Kernel auf PySpark3 fest, und legen Sie Anfügen an auf die IP-Adresse des Endpunkts Ihres Big Data-Clusters fest.
Wichtig
In Azure Data Studio definieren alle Spark-Notebooktypen (Scala Spark, PySpark und SparkR) bei der ersten Zellenausführung konventionell einige wichtige Variablen im Zusammenhang mit Spark-Sitzungen. Dabei handelt es sich um die Variablen spark, sc und sqlContext. Wenn Sie Logik aus Notebooks für die Batchübermittlung kopieren (z. B. in eine Python-Datei, die mit azdata bdc spark batch create ausgeführt werden soll), stellen Sie sicher, dass die Variablen entsprechend definiert sind.
Ausführen der Notebookzellen
Sie können jede Notebookzelle ausführen, indem Sie auf das Symbol für Ausführen klicken, das sich links neben der Zelle befindet. Die Ergebnisse werden im Notebook angezeigt, nachdem das Ausführen der Zelle abgeschlossen ist.

Führen Sie nacheinander jede der Zellen im Beispielnotebook aus. Weitere Informationen zur Verwendung von Notebooks mit Big Data-Cluster für SQL Server finden Sie in den folgenden Quellen:
- Verwenden von Notebooks
- How to manage notebooks in Azure Data Studio (Vorgehensweise: Verwalten von Notebooks in Azure Data Studio)
Nächste Schritte
Erfahren Sie mehr über Notebooks: