Debuggen und Diagnostizieren von Spark-Anwendungen in Big Data-Cluster für SQL Server in Spark History Server
Gilt für: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
Dieser Artikel enthält Anleitungen zur Verwendung der erweiterten Version von Spark History Server zum Debuggen und Diagnostizieren von Spark-Anwendungen in Big-Data-Clustern für SQL Server. Diese Debug- und Diagnosefunktionen sind in den Spark History Server integriert und werden von Microsoft unterstützt. Die Erweiterung umfasst die Registerkarten „Data“ (Daten), „Graph“ (Diagramm) und „Diagnosis“ (Diagnose). Auf der Registerkarte „Data“ (Daten) können Benutzer die Eingabe- und Ausgabedaten des Spark-Auftrags überprüfen. Auf der Registerkarte „Graph“ (Diagramm) können Benutzer den Datenfluss überprüfen und das Auftragsdiagramm wiedergeben. Auf der Registerkarte „Diagnosis“ (Diagnose) findet der Benutzer Informationen zur Datenschiefe, Zeitabweichung und eine Analyse zur Executorauslastung.
Zugreifen auf Spark History Server
Die Benutzeroberfläche der Open-Source-Version von Spark History Server wird mit Informationen wie auftragsspezifischen Daten und einer interaktiven Visualisierung des Auftragsdiagramms und von Datenflüssen für Big-Data-Cluster erweitert.
Öffnen der Webbenutzeroberfläche von Spark History Server über eine URL
Öffnen Sie Spark History Server, indem Sie die folgende URL aufrufen. Ersetzen Sie dabei <Ipaddress> und <Port> durch genaue Informationen zu den Big-Data-Clustern. Bei Clustern, die vor SQL Server 2019 CU 5 mit Einrichtung eines Big Data-Clusters in einer Standardauthentifizierung (Benutzername/Kennwort) bereitgestellt wurden, müssen Sie root-Benutzerangaben machen, wenn Sie bei der Anmeldung bei Gatewayendpunkten (Knox) dazu aufgefordert werden. Weitere Informationen finden Sie unter Verwenden eines Python-Skripts zum Bereitstellen eines Big-Data-Clusters für SQL Server in Azure Kubernetes Service (AKS) Beginnend mit SQL Server 2019 (15.x) CU 5 verwenden alle Endpunkte einschließlich Gateway AZDATA_USERNAME und AZDATA_PASSWORD, wenn Sie einen neuen Cluster mit Standardauthentifizierung bereitstellen. Endpunkte auf Clustern, die ein Upgrade auf CU 5 erhalten, verwenden weiterhin root als Nutzername für die Verbindung mit dem Gatewayendpunkt. Diese Änderung gilt nicht für Bereitstellungen, die die Active Directory-Authentifizierung verwenden. Weitere Informationen finden Sie unter Anmeldeinformationen für den Zugriff auf Dienste über den Gatewayendpunkt in den Versionshinweisen.
https://<Ipaddress>:<Port>/gateway/default/sparkhistory
Die Webbenutzeroberfläche von Spark History Server sieht wie folgt aus:
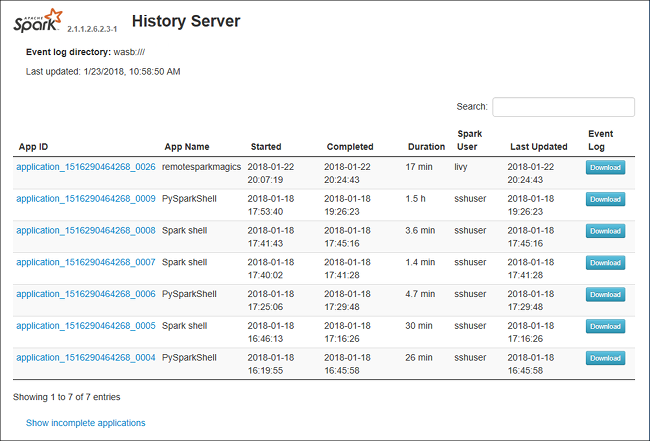
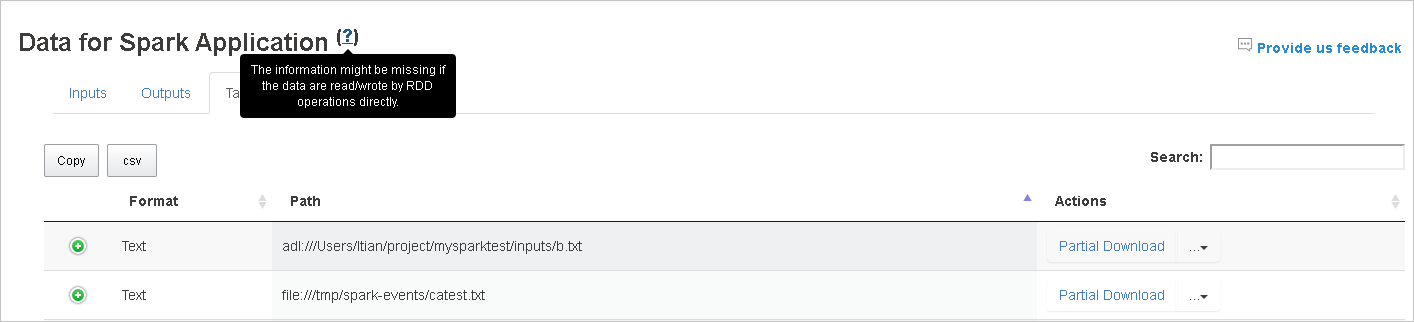
Die Registerkarte „Data“ (Daten) in Spark History Server
Wählen Sie die Auftrags-ID aus, und klicken Sie im Toolmenü auf Data (Daten), um die Datenansicht aufzurufen.
Überprüfen Sie die Registerkarten Inputs (Eingaben), Outputs (Ausgaben) und Table Operations (Tabellenvorgänge) einzeln.
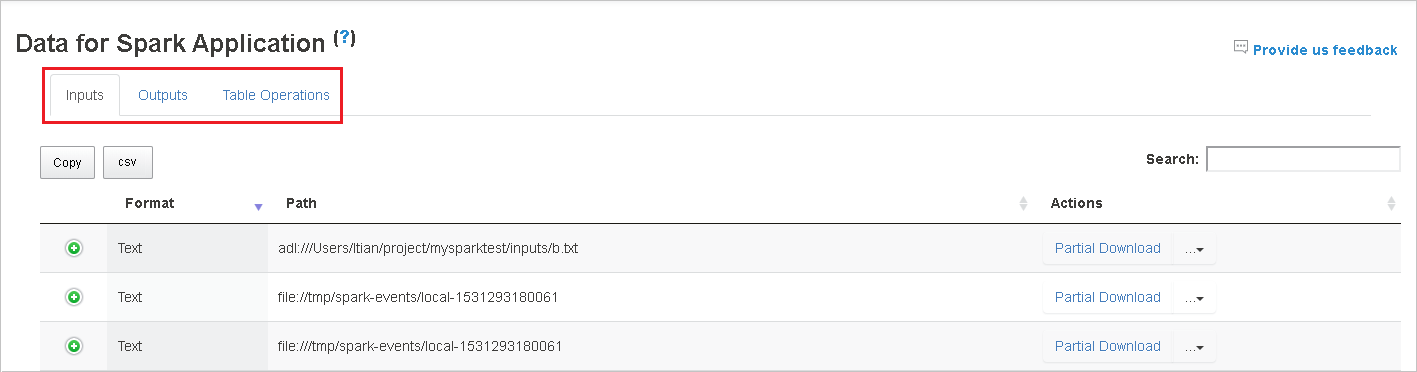
Kopieren Sie alle Zeilen, indem Sie auf die Schaltfläche Copy (Kopieren) klicken.
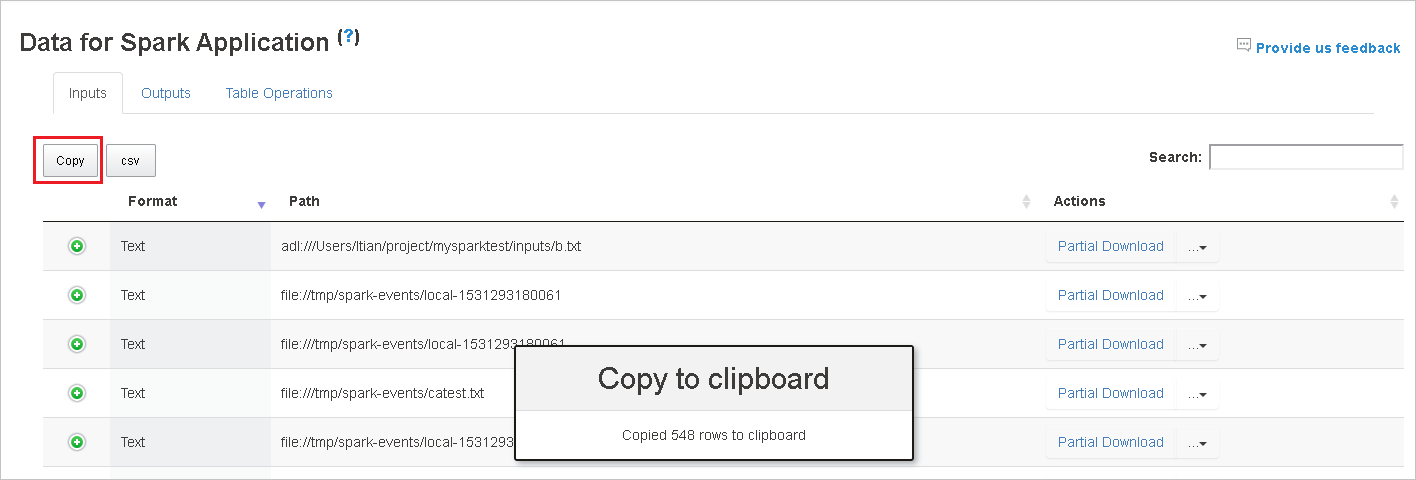
Speichern Sie alle Daten in einer CSV-Datei, indem Sie auf die Schaltfläche csv klicken.
Wenn Sie Suchbegriffe in das Feld Search (Suchen) eingeben, werden die Suchergebnisse sofort angezeigt.
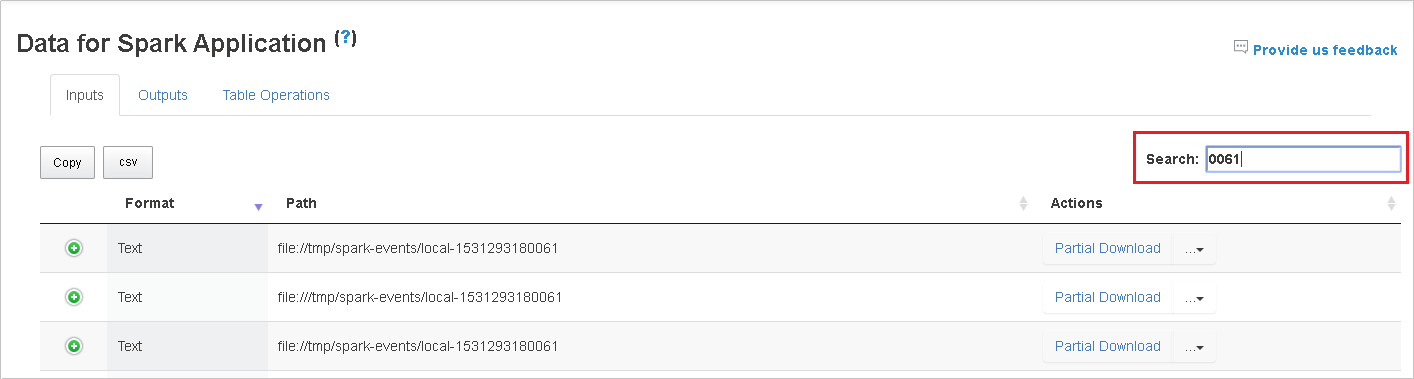
Klicken Sie erst auf den Spaltenheader, um die Tabelle zu sortieren, und dann auf das Pluszeichen, um eine Zeile zu erweitern und weitere Details anzuzeigen, oder auf das Minuszeichen, um eine Zeile zuzuklappen.
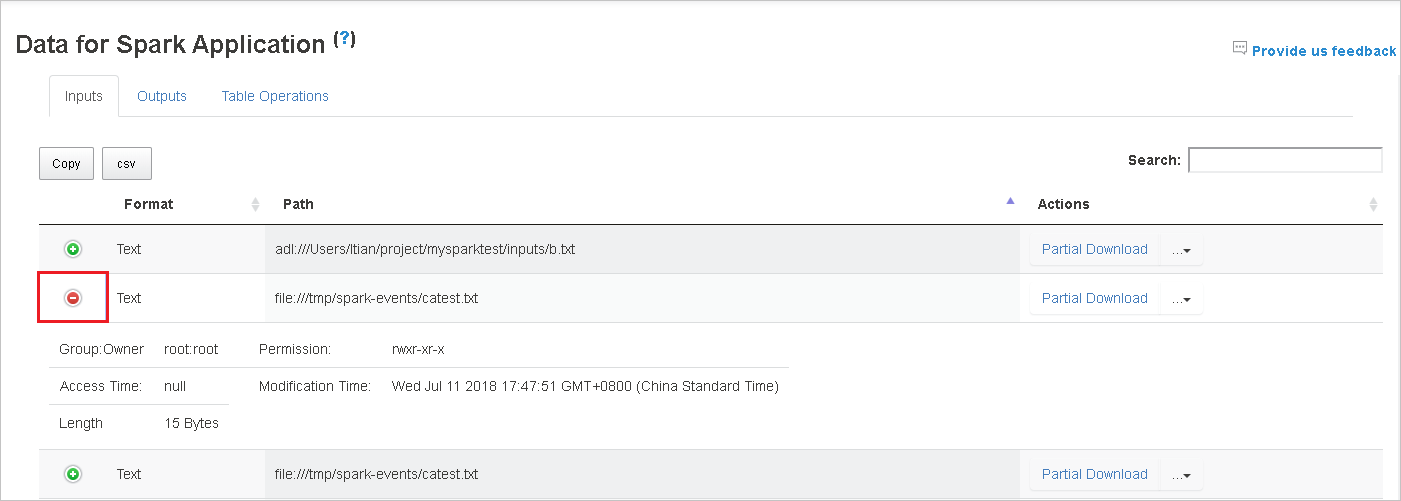
Wenn Sie eine Datei herunterladen möchten, klicken Sie auf der rechten Seite auf die Schaltfläche Partial Download (Unvollständiger Download). Dann wird die ausgewählte Datei heruntergeladen und lokal gespeichert. Wenn die Datei nicht mehr vorhanden ist, wird eine neue Registerkarte geöffnet, auf der die Fehlermeldungen angezeigt werden.
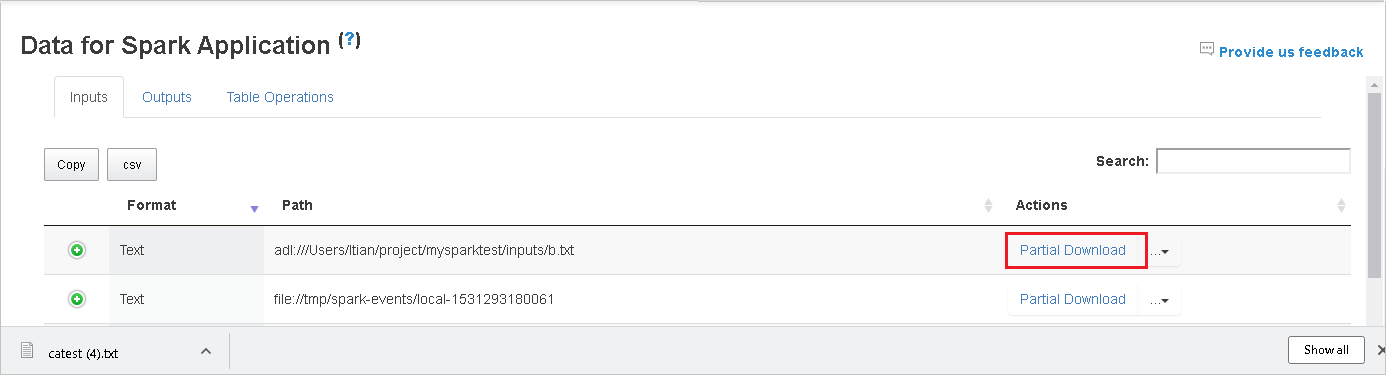
Kopieren Sie den vollständigen oder den relativen Pfad, indem Sie entsprechend auf die Optionen Copy Full Path (Vollständigen Pfad kopieren) oder Copy Relative Path (Relativen Pfad kopieren) klicken, die über das Downloadmenü verfügbar sind. Wenn Sie bei Azure Data Lake Storage-Dateien die Option Open in Azure Storage Explorer (Im Azure Storage-Explorer öffnen) auswählen, wird der Azure Storage-Explorer geöffnet. Sie werden dann bei der Anmeldung zum genauen Ordner weitergeleitet.
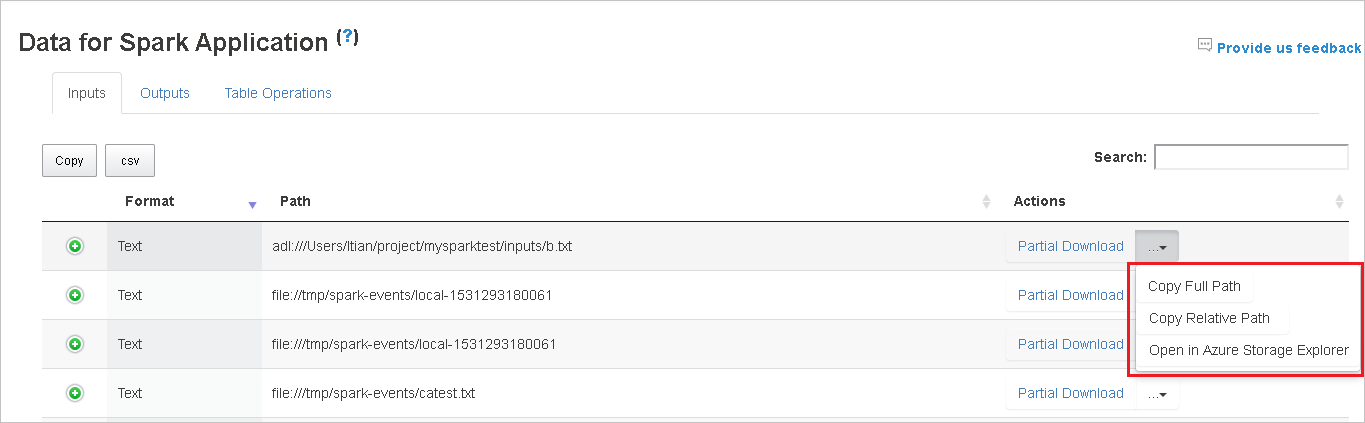
Klicken Sie auf die Zahl unterhalb der Tabelle, um zwischen den einzelnen Seiten zu navigieren, wenn mehr Zeilen vorhanden sind als auf eine Seite passen.

Zeigen Sie mit der Maus auf das Fragezeichen neben „Data“ (Daten), um die QuickInfo anzuzeigen, oder klicken Sie auf das Fragezeichen, um weitere Informationen zu erhalten.
Senden Sie Feedback zu Problemen, indem Sie auf Provide us feedback (Feedback übermitteln) klicken.
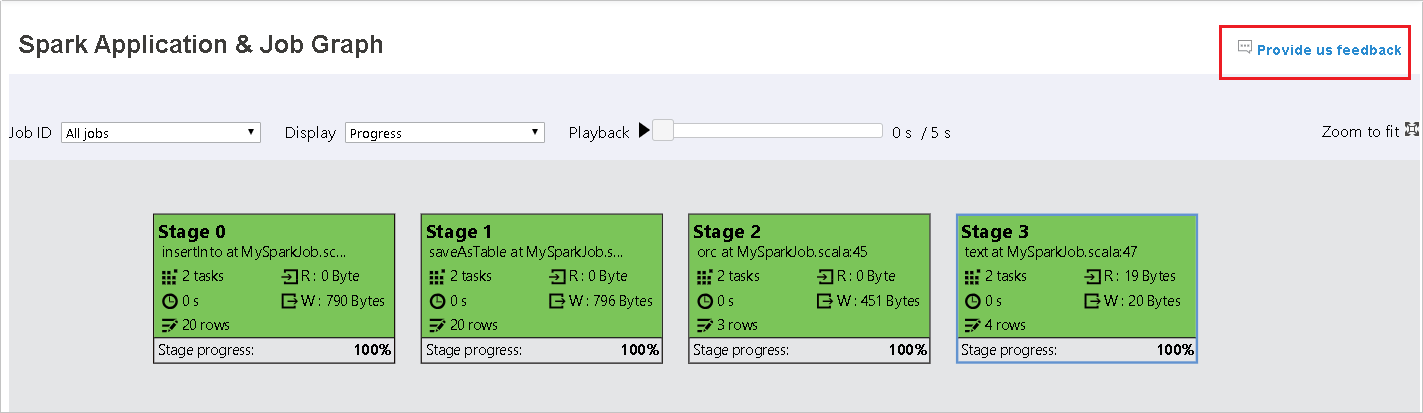
Die Registerkarte „Graph“ (Diagramm) in Spark History Server
Wählen Sie die Auftrags-ID aus, und klicken Sie im Menü des Tools auf Graph (Diagramm), um die Ansicht des Auftragsdiagramms aufzurufen.
Im daraufhin erstellten Auftragsdiagramm erhalten Sie eine Übersicht über Ihren Auftrag.
Standardmäßig werden alle Aufträge angezeigt. Diese können nach Job ID (Auftrags-ID) gefiltert werden.
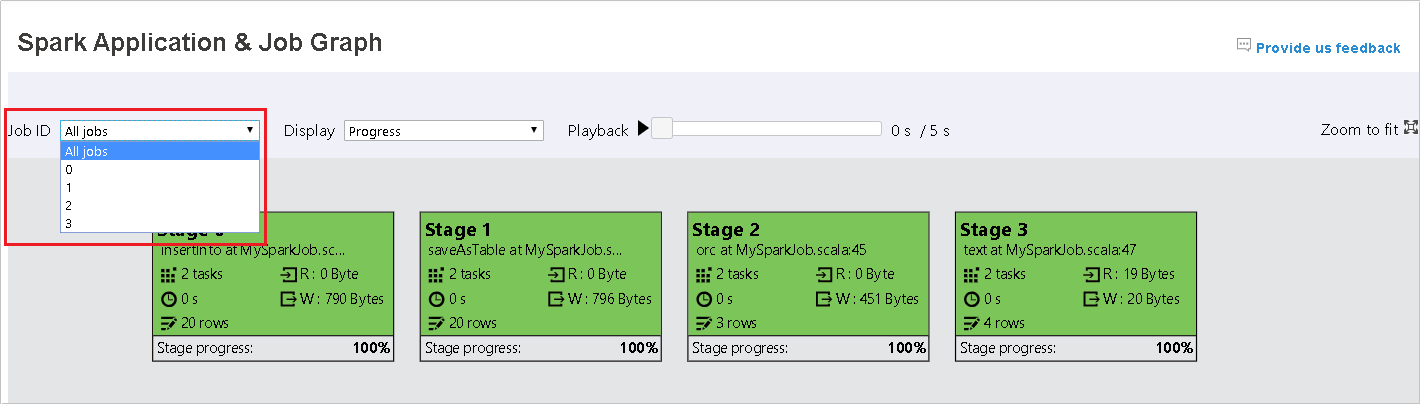
Progress (Status) wird als Standardwert belassen. Der Benutzer kann den Datenfluss überprüfen, indem er Read (Lesen) oder Written (Geschrieben) in der Dropdown-Liste von Display (Anzeigen) auswählt.
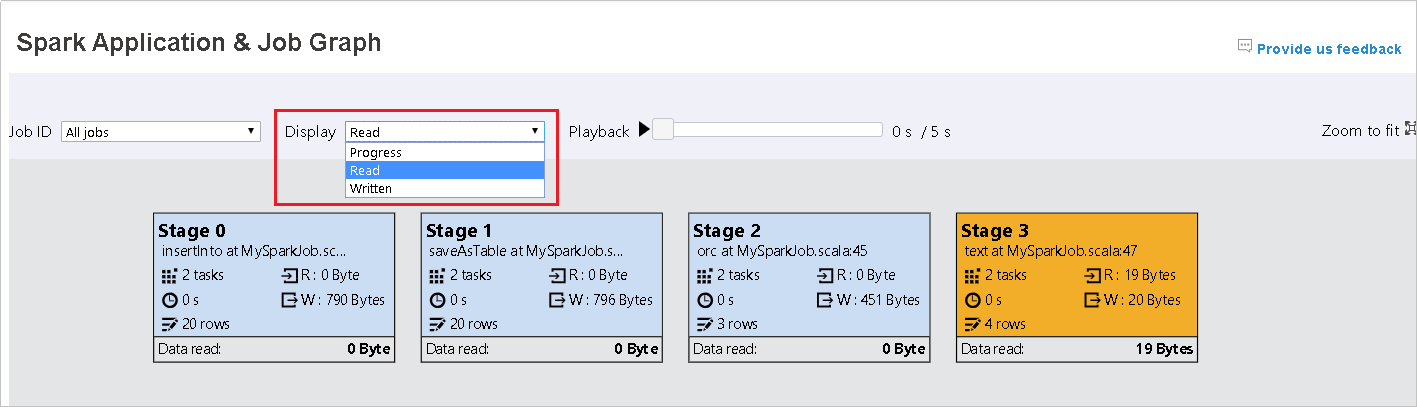
Wärmebild der Diagrammknotenanzeige in Farbe

Sie können den Auftrag wiedergeben, indem Sie auf die Schaltfläche Playback (Wiedergabe) klicken, und jederzeit wieder anhalten, indem Sie auf „Stop“ (Beenden) klicken. Die Auftragsanzeige in Farbe zur Darstellung verschiedener Statusangaben bei der Wiedergabe:
- Grün für erfolgreiche Aufträge, die abgeschlossen wurden.
- Orange bei Auftragsinstanzen, die nicht erfolgreich waren, aber das Endergebnis des Auftrags nicht beeinträchtigen. Diese Aufträge enthielten doppelte oder wiederholte Instanzen, werden später aber möglicherweise erfolgreich ausgeführt.
- Blau für Aufträge, die gerade ausgeführt werden.
- Weiß für Aufträge, deren Ausführung noch ansteht oder bei denen eine Phase übersprungen wurde.
- Rot für fehlgeschlagene Aufträge.
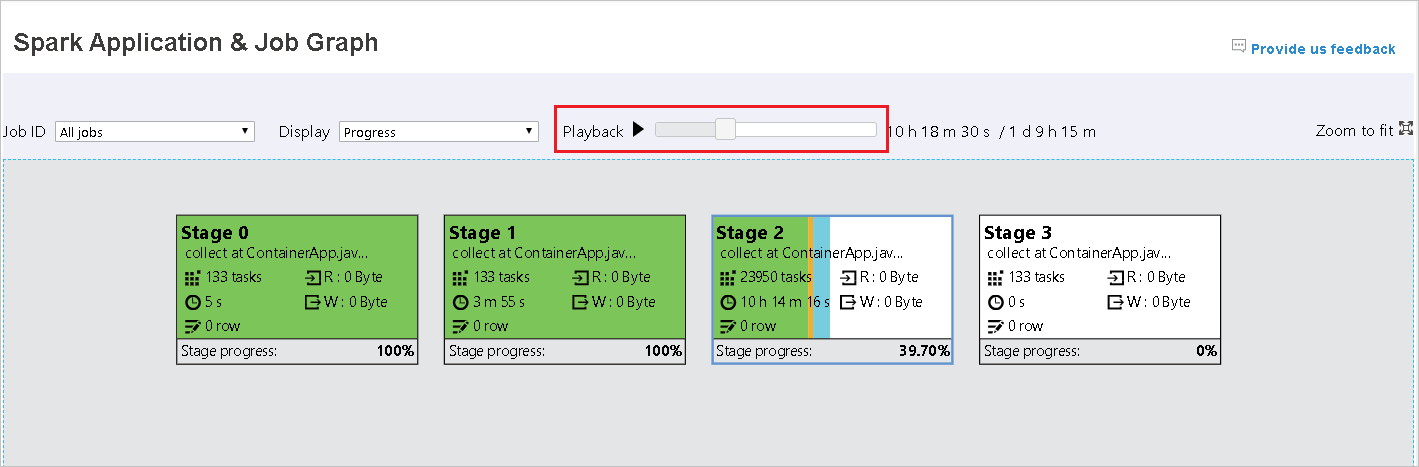
Übersprungene Phasen werden in weiß angezeigt.

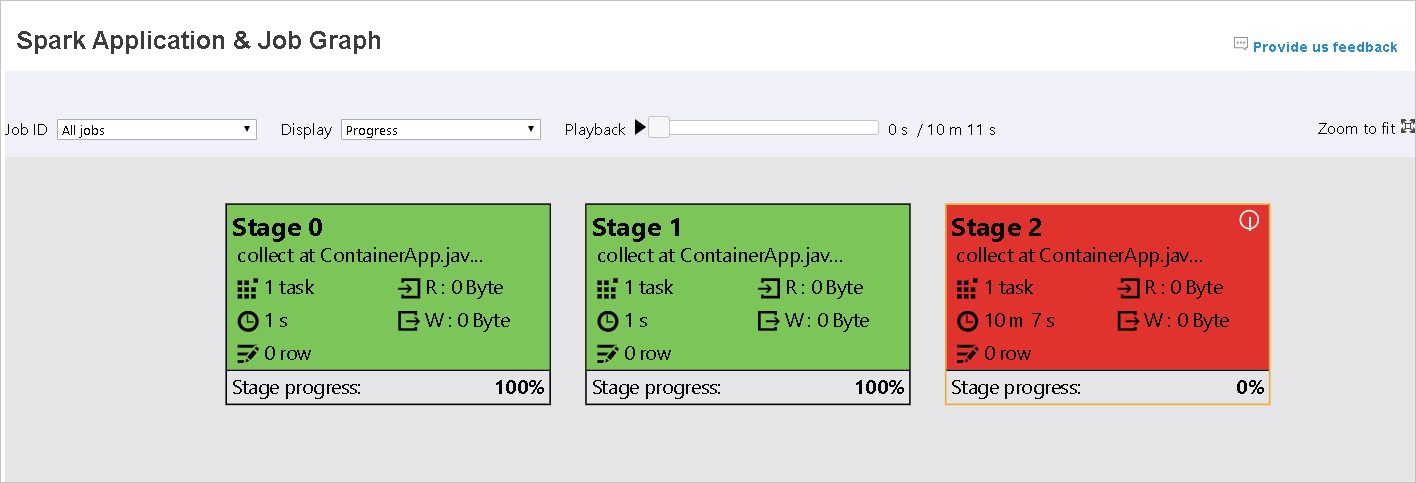
Hinweis
Jeder Auftrag darf wiedergegeben werden. Die Wiedergabe von unvollständigen Aufträgen wird allerdings nicht unterstützt.
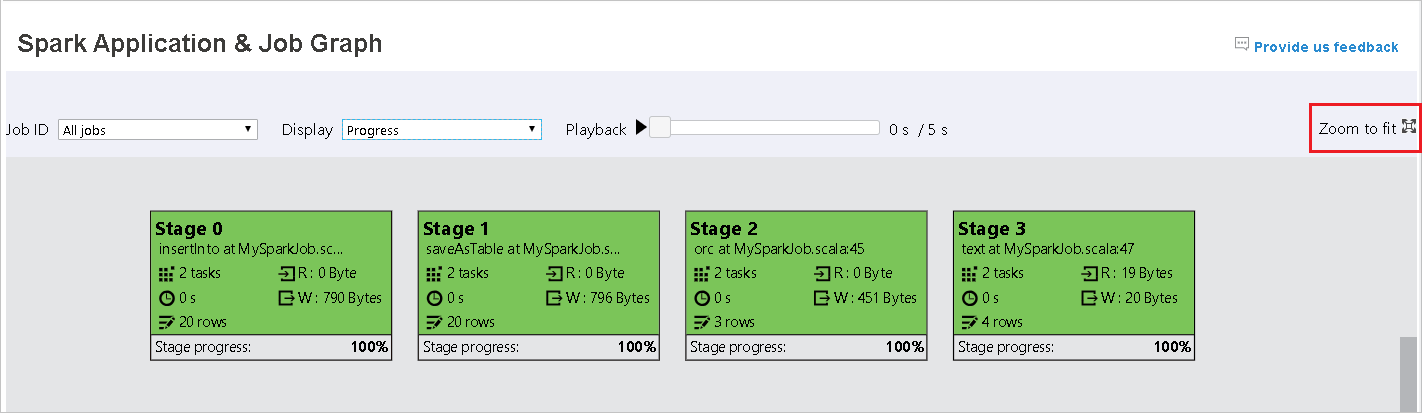
Scrollen Sie mit der Maus, um das Auftragsdiagramm zu vergrößern bzw. zu verkleinern, oder klicken Sie auf Zoom to fit (Mit Zoom anpassen), um es an die Bildschirmgröße anzupassen.
Zeigen Sie mit der Maus auf den Diagrammknoten, um bei fehlgeschlagenen Aufträgen die QuickInfo anzuzeigen, und klicken Sie auf eine Phase, um die Seite zu dieser Phase zu öffnen.
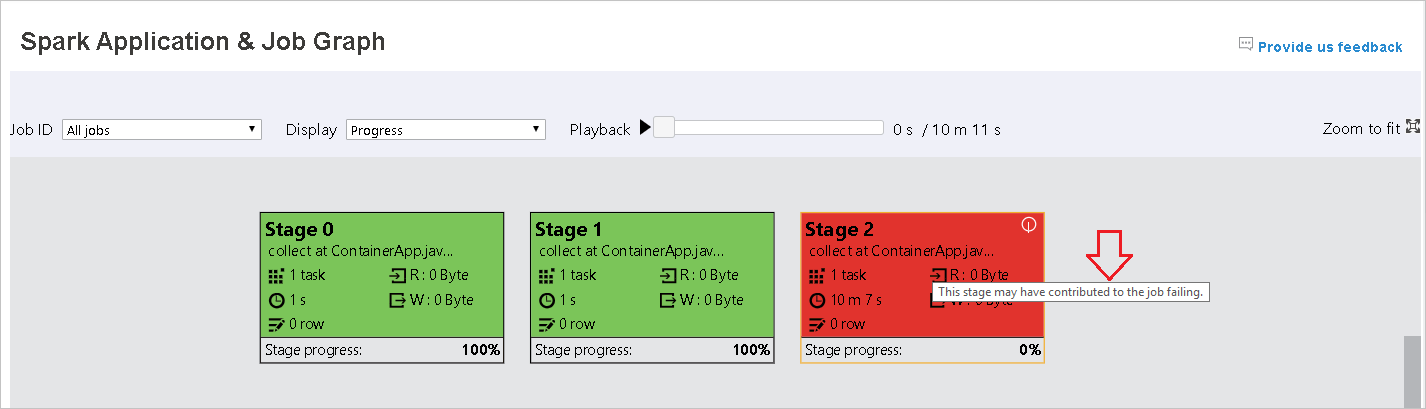
Auf der Registerkarte „Job graph“ (Auftragsdiagramm) werden QuickInfos und kleine Symbole angezeigt, wenn es Aufträge gibt, die die folgenden Bedingungen erfüllen:
- Datenschiefe: Lesegröße der Daten> durchschnittliche Lesegröße der Daten aller Aufträge innerhalb dieser Phase × 2 und Lesegröße der Daten > 10 MB
- Zeitabweichung: Ausführungszeit > durchschnittliche Ausführungszeit aller Aufgaben in dieser Phase × 2 und Ausführungszeit > 2 Minuten
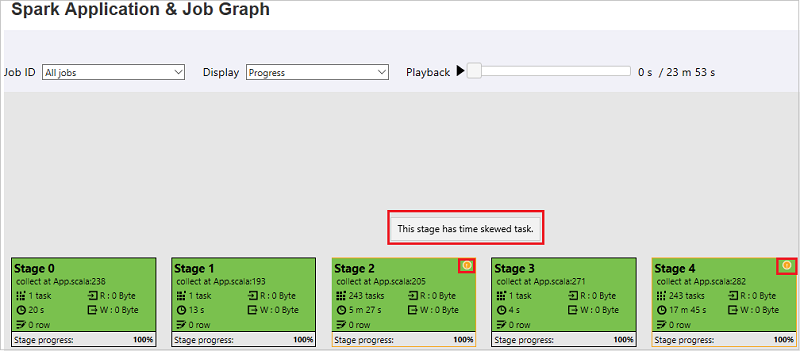
Der Auftragsdiagrammknoten zeigt die folgenden Informationen zu den einzelnen Phasen an:
- ID
- Name oder Beschreibung
- Anzahl der Aufträge insgesamt
- Daten lesen: die Summe der Eingabegröße und Lesegröße der Zufallswiedergabe
- Daten schreiben: die Summe der Ausgabegröße und der Schreibgröße der Zufallswiedergabe
- Ausführungszeit: die Zeit zwischen der Startzeit des ersten Versuchs und der Endzeit des letzten Versuchs
- Zeilenanzahl: die Summe der Eingabe und Ausgabedatensätze sowie die Datensätze der zufälligen Lese- und Schreibvorgänge
- Status
Hinweis
Standardmäßig zeigt der Auftragsdiagrammknoten Informationen zum letzten Versuch der einzelnen Phasen an (mit Ausnahme der Phase „Ausführungszeit“), während der Wiedergabediagrammknoten Informationen zu jedem Versuch bereitstellt.
Hinweis
Für die Datengröße des Lese-und Schreibvorgangs wird 1 MB = 1000 KB = 1000 × 1000 Bytes verwendet.
Senden Sie Feedback zu Problemen, indem Sie auf Provide us feedback (Feedback übermitteln) klicken.
Die Registerkarte „Diagnosis“ (Diagnose) in Spark History Server
Wählen Sie die Auftrags-ID aus, und klicken Sie im Toolmenü auf Diagnosis (Diagnose), um die Ansicht der Auftragsdiagnose aufzurufen. Die Registerkarte „Diagnosis“ (Diagnose) umfasst die folgenden weiteren Registerkarten: Data Skew (Datenschiefe), Time Skew (Zeitabweichung) und Executor Usage Analysis (Analyse zur Executorauslastung).
Überprüfen Sie die Datenschiefe, Zeitabweichung und Executor-Nutzungsanalyse, indem Sie die entsprechenden Registerkarten auswählen.
Datenschiefe
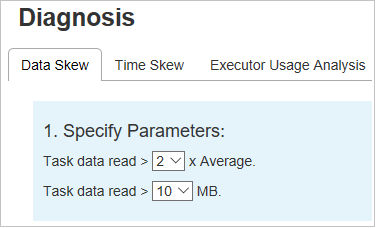
Klicken Sie auf die Registerkarte Data Skew (Datenschiefe). Dann werden basierend auf den angegebenen Parametern die entsprechenden schiefen Aufträge angezeigt.
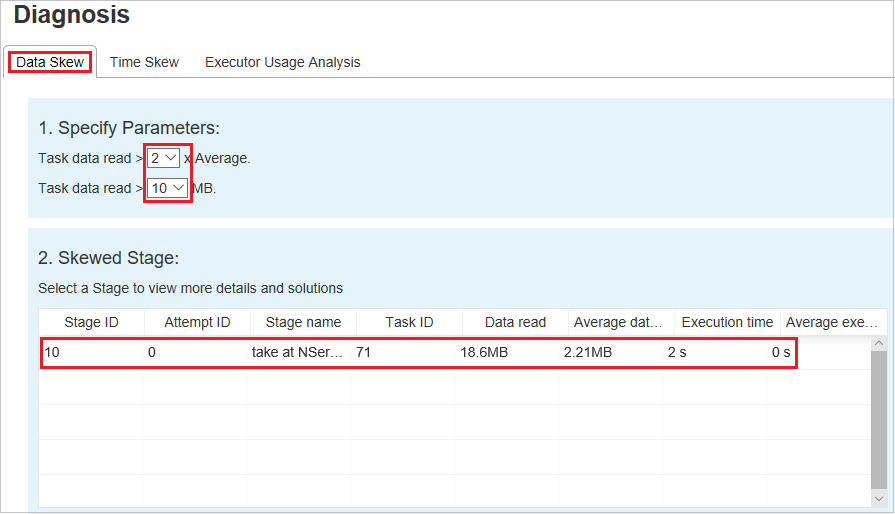
Parameter festlegen: Im ersten Abschnitt werden die Parameter angezeigt, die zum Erkennen von Datenschiefe verwendet werden. Es gilt die folgende Regel: Task-Datenlesevorgänge > 3 durchschnittliche Task-Datenlesevorgänge und Task-Datenlesevorgänge > 10 MB. Wenn Sie eine eigene Regel für Aufträge mit Datenschiefe definieren möchten, können Sie Ihre Parameter und die Skewed Stage (Phase mit Datenschiefe) auswählen. Dann wird der Abschnitt Skew Chart (Diagramm zur Datenschiefe) entsprechend aktualisiert.
Schiefe Phase: Im zweiten Abschnitt werden die Phasen angezeigt, die Aufgaben mit Abweichungen entsprechend den oben angegebenen Kriterien enthalten. Wenn in einer Stufe mehr als ein schiefer Auftrag vorhanden ist, werden in der Tabelle mit den schiefen Aufträgen nur die schiefsten Aufträge angezeigt (z. B. der größte Datensatz für die Datenschiefe).
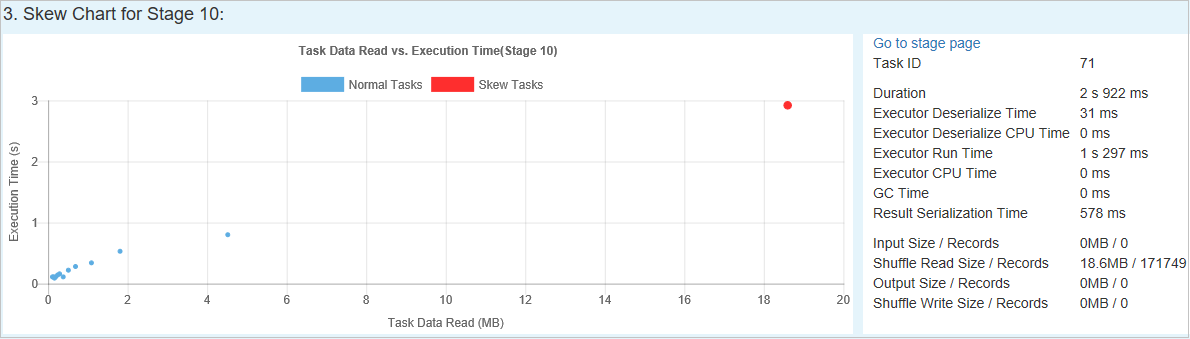
Skew Chart (Diagramm zur Datenschiefe): Wenn eine Zeile in der Tabelle zu den Phasen mit Datenschiefe ausgewählt ist, werden im Diagramm zur Datenschiefe basierend auf den gelesenen Daten und der Ausführungszeit weitere Details zur Auftragsverteilung angezeigt. Die schiefen Aufträge sind rot und die normalen Aufträge sind blau markiert. Aus Leistungsgründen werden im Diagramm nur bis zu 100 Beispielaufträge angezeigt. Die Auftragsdetails werden im unteren Bereich auf der rechten Seite angezeigt.
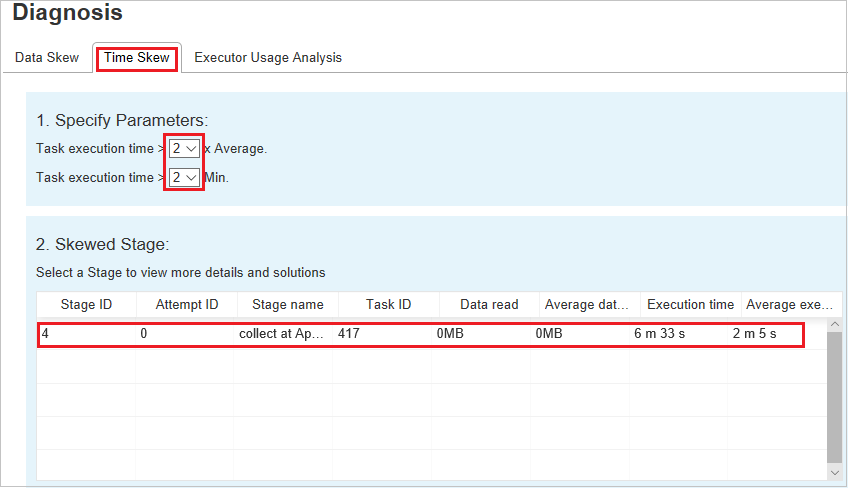
Zeitabweichung
Auf der Registerkarte Time Skew (Zeitabweichung) werden schiefe Aufträge basierend auf ihrer Ausführungszeit angezeigt.
Parameter festlegen: Im ersten Abschnitt werden die Parameter angezeigt, die zum Erkennen der Zeitabweichung verwendet werden. Die Standardkriterien zum Erkennen von Zeitabweichungen sind: Ausführungszeit der Aufgabe > 3-mal durchschnittliche Ausführungszeit und Ausführungszeit der Aufgabe > 30 Sekunden. Sie können die Parameter Ihren Anforderungen entsprechend anpassen. Unter Skewed Stage (Phase mit Datenschiefe) und Skew Chart (Diagramm zur Datenschiefe) werden wie auf der obenstehenden Registerkarte Data Skew (Datenschiefe) die Informationen zu den einzelnen Phasen und Aufträgen angezeigt.
Klicken Sie auf Time Skew (Zeitabweichung). Dann werden im Abschnitt Skewed Stage (Phase mit Datenschiefe) entsprechend den im Abschnitt Specify Parameters (Parameter angeben) festgelegten Parametern die gefilterten Ergebnisse angezeigt. Klicken Sie im Abschnitt Skewed Stage (Phase mit Datenschiefe) auf ein Element. Dann wird in Abschnitt 3 ein Entwurf des entsprechenden Diagramms angezeigt, und die Auftragsdetails finden Sie im unteren Bereich auf der rechten Seite.
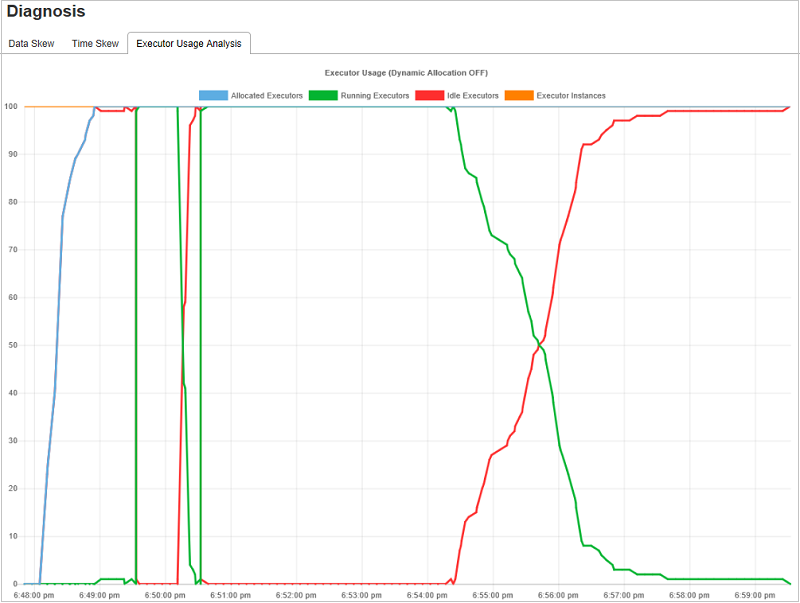
Analyse zur Executorauslastung
Im Diagramm zur Executorauslastung wird die tatsächliche Executorzuweisung und der Ausführungsstatus der Spark-Auftrags angezeigt.
Klicken Sie auf Executor Usage Analysis (Analyse zur Executorauslastung). Dann werden die folgenden vier Kurven zur Executorauslastung angezeigt: Allocated Executors (Zugewiesene Executors), Running Executors (Ausgeführte Executors), Idle Executors (Excutors im Leerlauf) und Max Executor Instances (Höchstanzahl der Executorinstanzen). Durch jedes Ereignis, bei dem Executors hinzugefügt oder entfernt werden, wird die Anzahl der zugewiesenen Executors erhöht bzw. verringert. Sie können sich auf der Registerkarte „Jobs“ (Aufträge) den Ereignisverlauf ansehen, falls Sie sich für weitere Vergleiche interessieren.
Klicken Sie auf das Farbsymbol, um den entsprechenden Inhalt in allen Entwürfen auszuwählen oder zu deaktivieren.
Spark-/Yarn-Protokolle
Die Protokolle für Spark und Yarn finden Sie neben dem Spark History Server auch hier:
- Spark-Ereignisprotokolle: hdfs:///system/spark-events
- Yarn-Protokolle: hdfs:///tmp/logs/root/logs-tfile
Hinweis: Für beide Protokolle gilt ein Standardaufbewahrungszeitraum von 7 Tagen. Informationen zum Ändern des Aufbewahrungszeitraums finden Sie auf der Seite Konfigurieren von Apache Spark und Apache Hadoop in Big Data-Clustern. Der Speicherort kann nicht geändert werden.
Bekannte Probleme
Folgende Probleme sind für Spark History Server bekannt:
Derzeit funktioniert dieses Tool nur für Spark 3.1-Cluster (CU13+) und Spark 2.4 (CU12-).
Eingabe- und Ausgabedaten werden unter Verwendung von RDD nicht auf der Registerkarte „Data“ (Daten) angezeigt.
Nächste Schritte
- Erste Schritte mit Big-Data-Clustern von SQL Server
- Konfigurieren von Spark-Einstellungen
- Konfigurieren von Spark-Einstellungen
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für