Übermitteln von Spark-Aufträgen auf Big Data-Cluster für SQL Server in Azure Data Studio
Gilt für: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
Eines der Hauptszenarios für Big Data-Cluster besteht darin, dass Spark-Aufträge für SQL Server an diese übermittelt werden können. Mit dem Feature zum Übermitteln von Spark-Aufträgen können Sie lokale JAR- oder PY-Dateien mit Verweisen auf Big Data-Cluster für SQL Server 2019 übermitteln. Außerdem können Sie JAR- oder PY-Dateien ausführen, die sich bereits auf dem HDFS-Dateisystem befinden.
Voraussetzungen
Big Data-Tools für SQL Server 2019:
- Azure Data Studio
- Erweiterung von SQL Server 2019
- kubectl
Öffnen des Dialogfelds zum Übermitteln von Spark-Aufträgen
Es gibt mehrere Möglichkeiten zum Öffnen des Dialogfelds zum Übermitteln von Spark-Aufträgen. Zu den Möglichkeiten zählen das Dashboard, das Kontextmenü im Objekt-Explorer und die Befehlspalette.
Klicken Sie zum Öffnen des Dialogfelds zum Übermitteln von Spark-Aufträgen im Dashboard auf Neuer Spark-Auftrag.
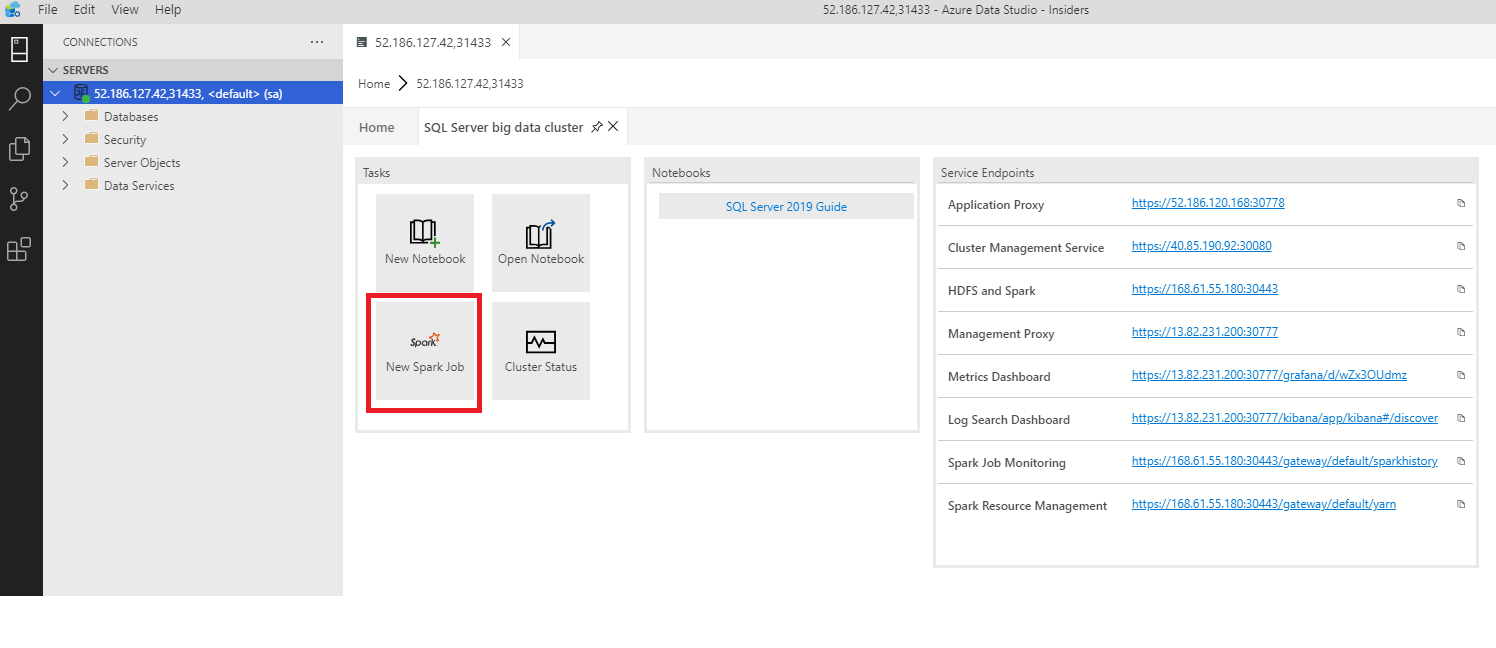
Klicken Sie alternativ im Objekt-Explorer mit der rechten Maustaste auf den Cluster, und wählen Sie im Kontextmenü Spark-Auftrag übermitteln aus.
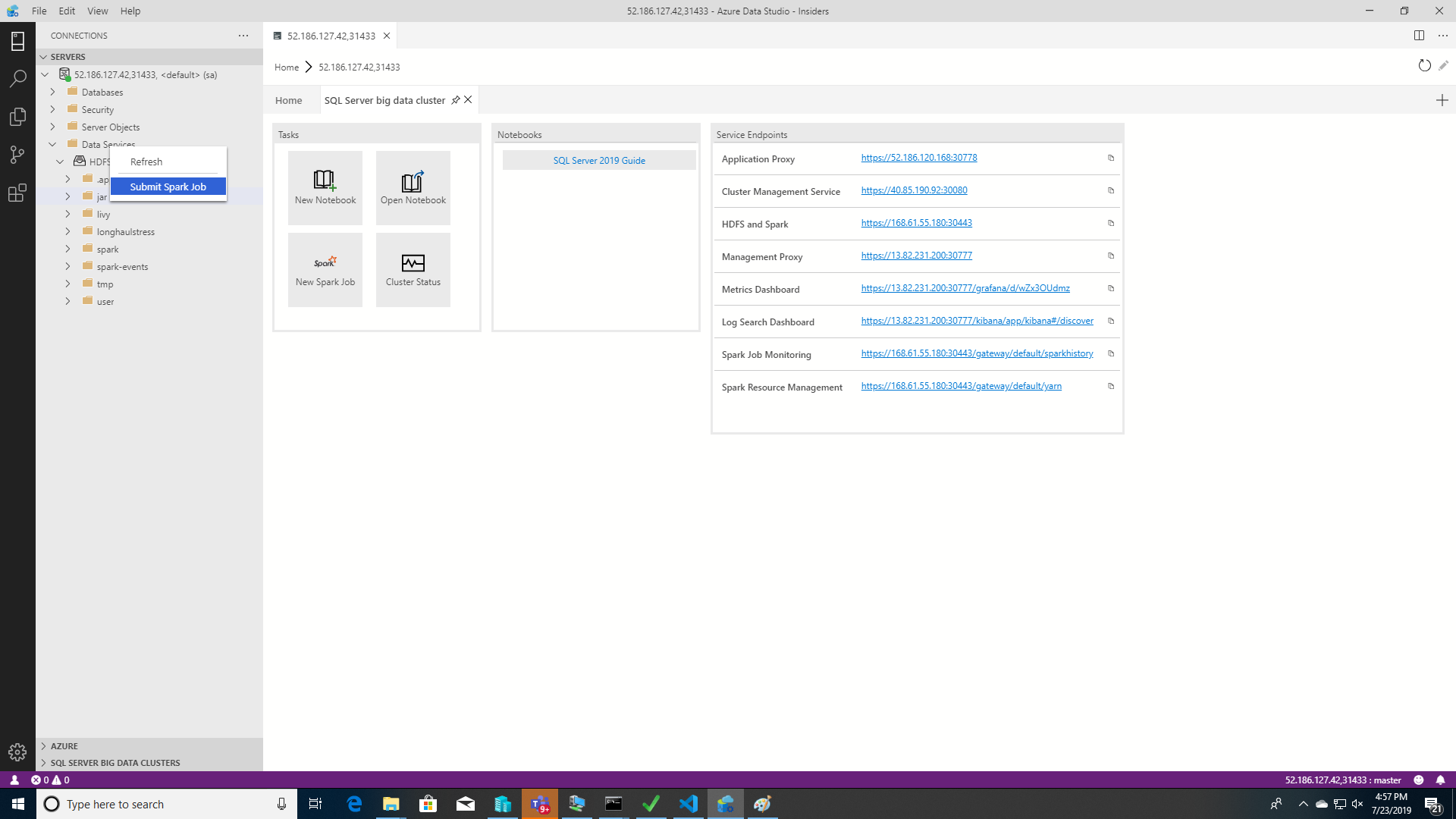
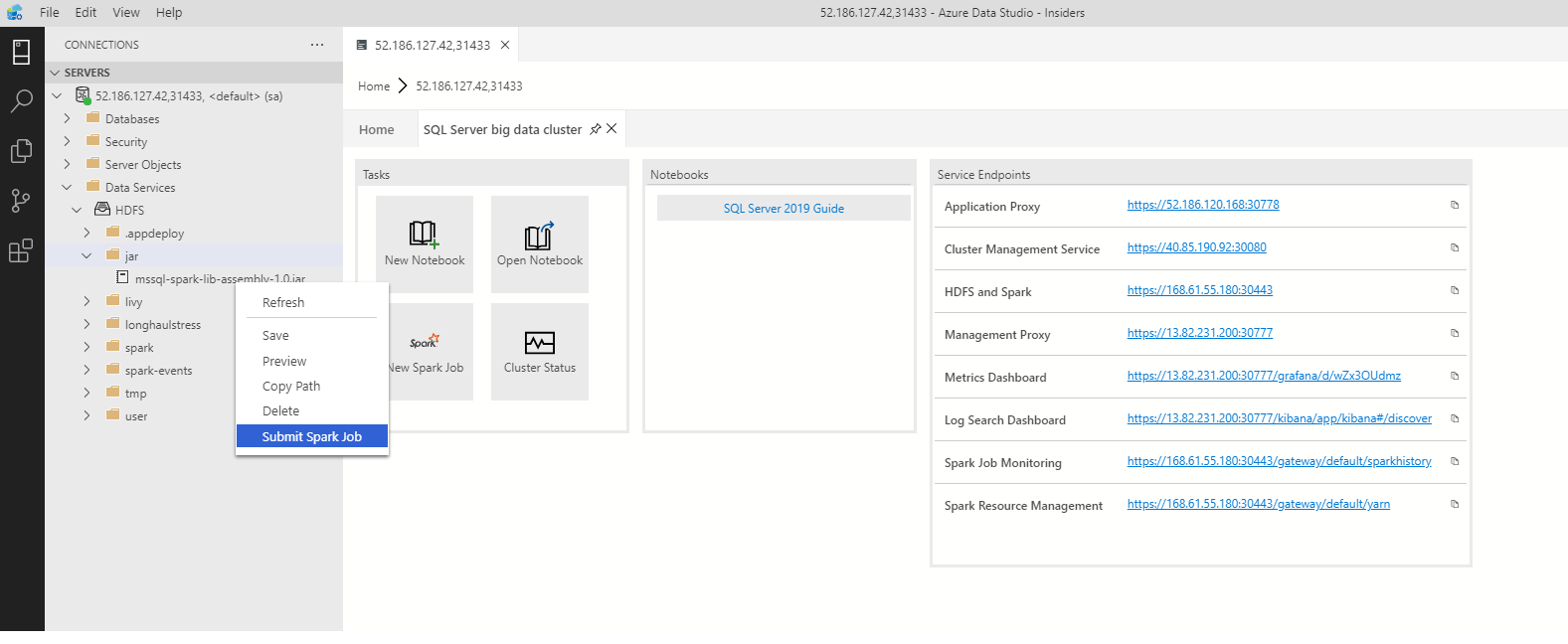
Um das Dialogfeld zum Übermitteln von Spark-Aufträgen vorab mit den JAR/PY-Feldern zu füllen, klicken Sie mit der rechten Maustaste im Objekt-Explorer auf eine JAR/PY-Datei, und wählen Sie im Kontextmenü Spark-Auftrag übermitteln aus.
Verwenden Sie Spark-Auftrag übermitteln aus der Befehlspalette, indem Sie STRG+UMSCHALTTASTE+P (unter Windows) oder BEFEHLSTASTE+UMSCHALTTASTE+P (unter Mac) drücken.

Übermitteln von Spark-Aufträgen
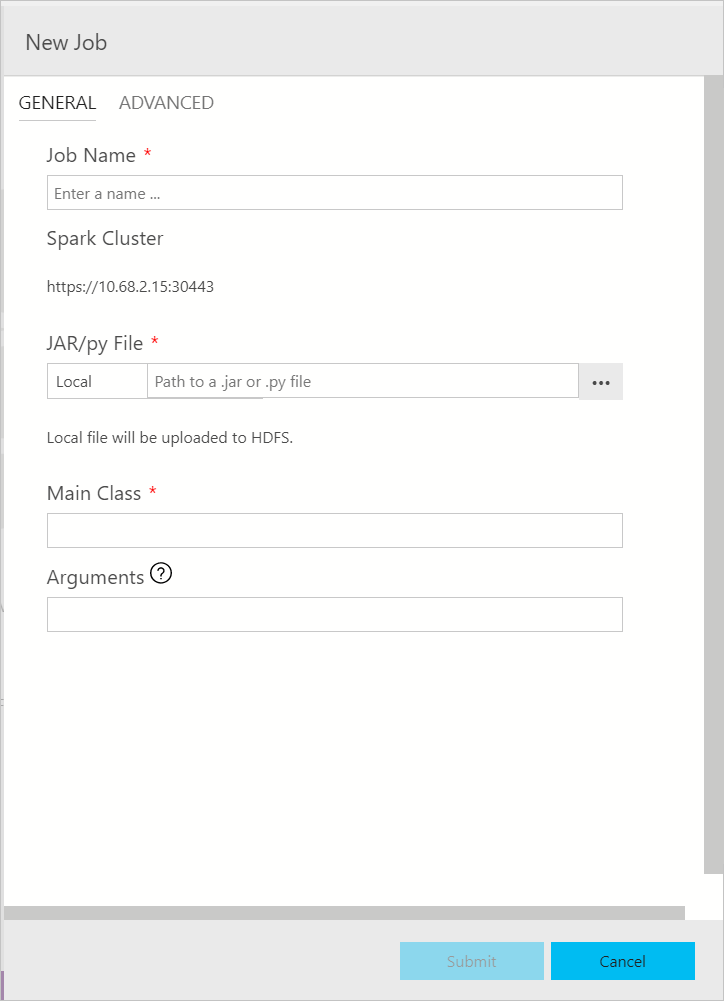
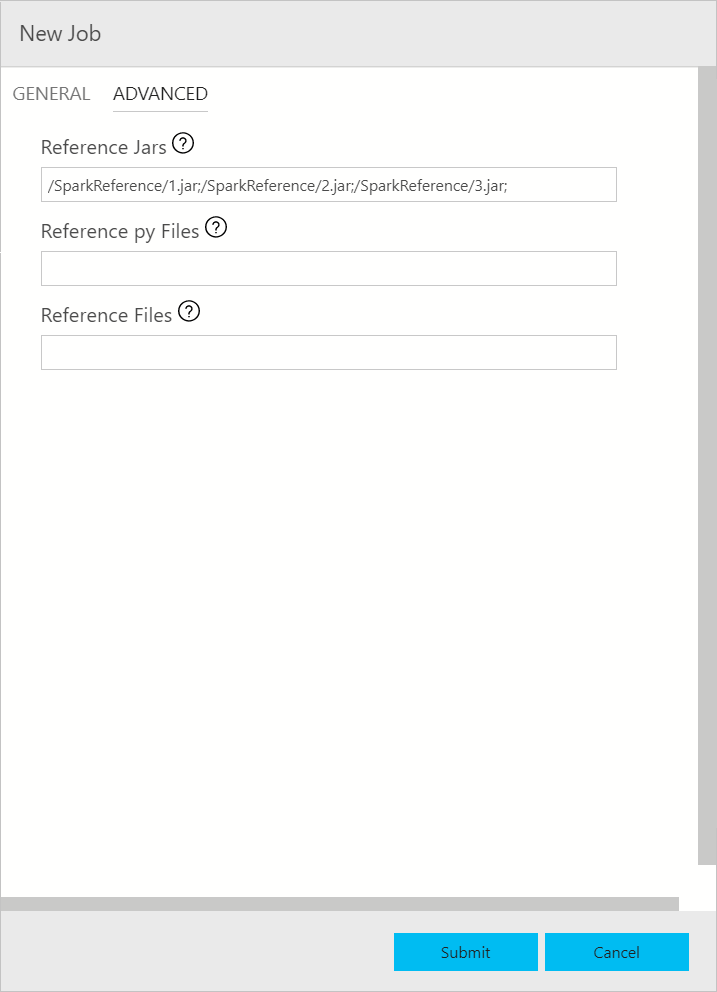
Das Dialogfeld für die Übermittlung von Spark-Aufträgen wird wie folgt angezeigt. Geben Sie den Auftragsnamen, den JAR/PY-Dateipfad, die Hauptklasse und andere Felder ein. Die JAR/PY-Dateiquelle kann lokal sein oder sich im HDFS befinden. Wenn der Spark-Auftrag JAR-, PY- oder weitere Referenzdateien aufweist, klicken Sie auf die Registerkarte ERWEITERT, und geben Sie die entsprechenden Dateipfade ein. Klicken Sie zum Übermitteln des Spark-Auftrags auf Übermitteln.
Überwachen der Übermittlung von Spark-Aufträgen
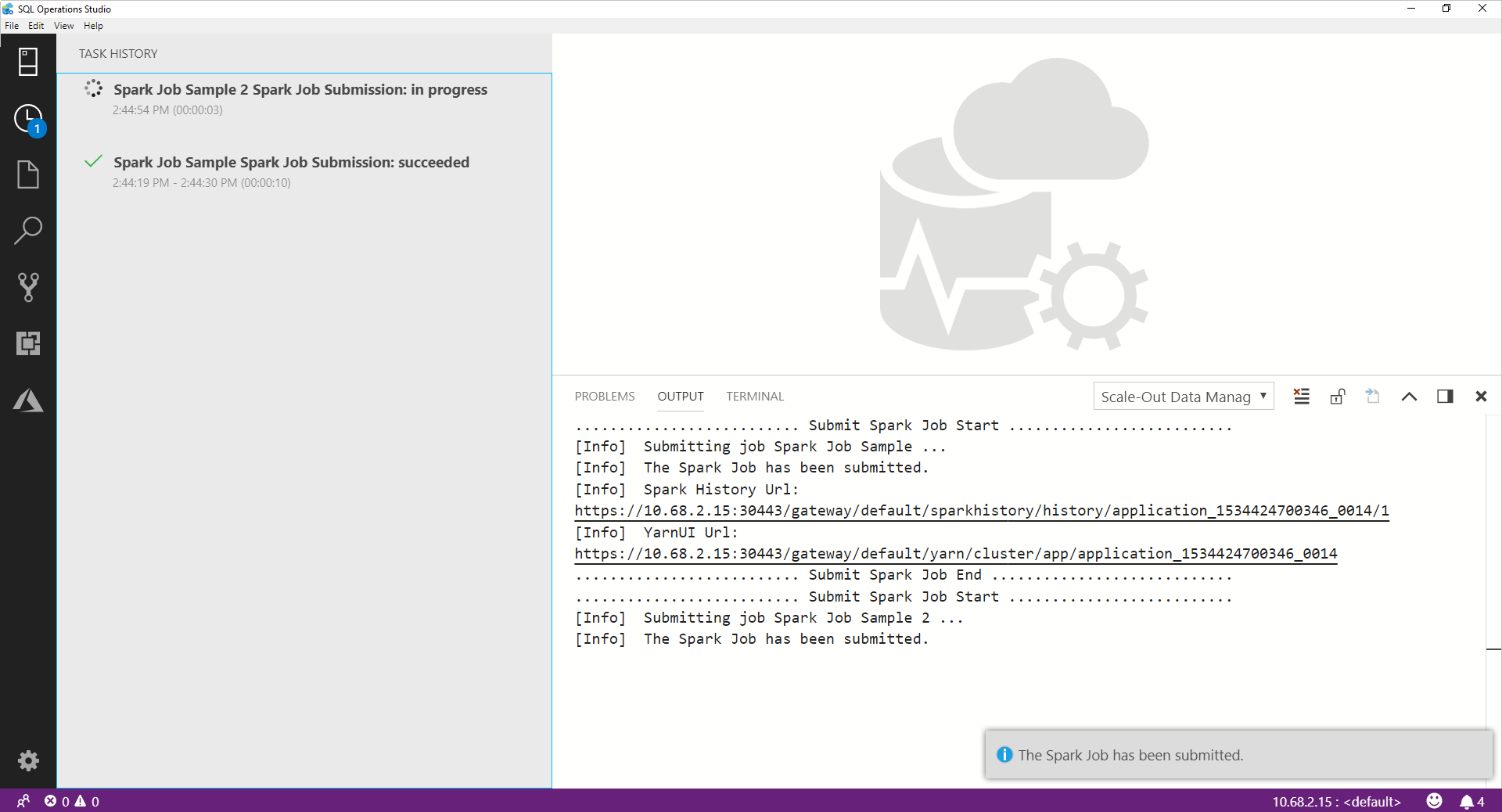
Nachdem der Spark-Auftrag übermittelt wurde, werden die Informationen zur Übermittlung und zum Ausführungsstatus des Spark-Auftrags im „Aufgabenverlauf“ auf der linken Seite angezeigt. Details zum Fortschritt und zu Protokollen werden ebenfalls im Fenster AUSGABE unten angezeigt.
Wenn der Spark-Auftrag ausgeführt wird, werden der Bereich Aufgabenverlauf und das Fenster AUSGABE mit dem Fortschritt aktualisiert.
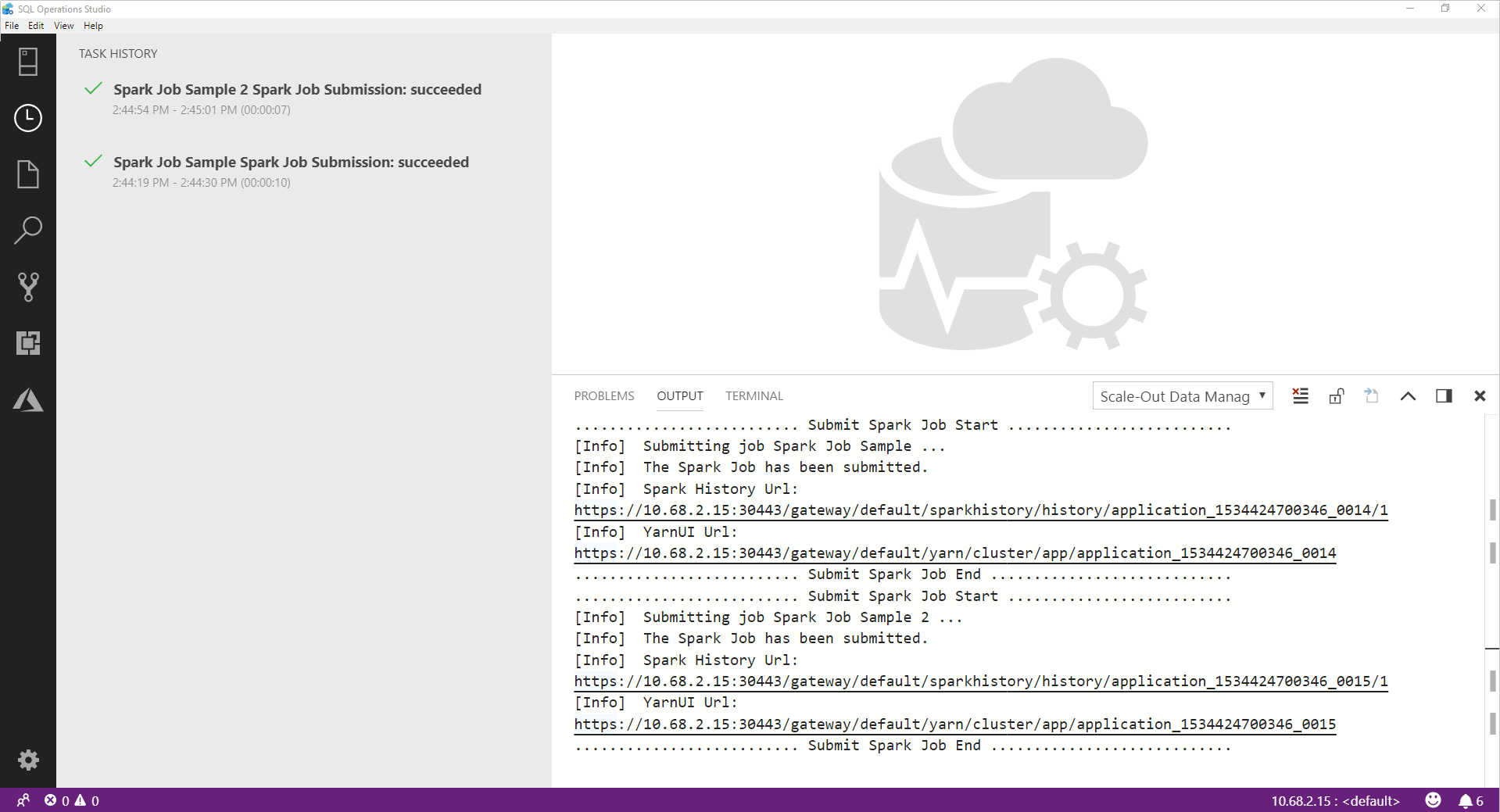
Nachdem der Spark-Auftrag erfolgreich abgeschlossen wurde, werden die Links zur Spark- und Yarn-Benutzeroberfläche im Fenster AUSGABE angezeigt. Klicken Sie auf die Links, um weitere Informationen zu erhalten.
Nächste Schritte
Weitere Informationen zu SQL Server-Big Data-Clustern und zugehörigen Szenarien finden Sie unter Einführung in Big Data-Cluster für SQL Server.