Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server 2016 (13.x)
SQL Server 2016 (13.x) ![]() SQL Server 2017 (14.x)
SQL Server 2017 (14.x) ![]() SQL Server 2019 (15.x) unter Linux
SQL Server 2019 (15.x) unter Linux
Die Integration von Python ist ab SQL Server 2017 verfügbar, wenn Sie bei der Installation von SQL Server-Machine Learning Services (datenbankintern) das Kontrollkästchen für Python aktiviert haben.
Hinweis
Derzeit gilt dieser Artikel nur für SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) und SQL Server 2019 (15.x) für Linux.
Installieren Sie revoscalepy von Microsoft und andere Python-Bibliotheken in Ihrer Entwicklungsarbeitsstation, um Python-Lösungen für SQL Server zu entwickeln und bereitzustellen. Mit der revoscalepy-Bibliothek, die sich auch auf der SQL Server-Remoteinstanz befindet, lassen sich Computinganforderungen zwischen beiden Systemen koordinieren.
In diesem Artikel erfahren Sie, wie Sie eine Python-Entwicklungsarbeitsstation so konfigurieren, dass Sie mit einer SQL Server-Remoteinstanz interagieren können, die für die Integration von Machine Learning und Python aktiviert ist. Nachdem Sie die in diesem Artikel beschriebenen Schritte ausgeführt haben, verfügen Sie über dieselben Python-Bibliotheken wie in SQL Server. Außerdem erfahren Sie, wie Sie Berechnungen von einer lokalen Python-Sitzung an eine Python-Remotesitzung in SQL Server übertragen.
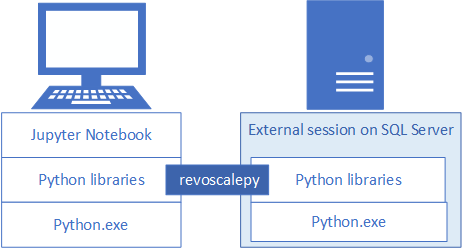
Verwenden Sie zur Überprüfung der Installation wie in diesem Artikel beschrieben die integrierte Anwendung Jupyter Notebook, oder verknüpfen Sie die Bibliotheken mit PyCharm oder einer anderen IDE, die Sie normalerweise verwenden.
Tipp
Eine Veranschaulichung dieser Schritte finden Sie im Video Remoteausführung von R und Python in SQL Server mit Jupyter Notebook.
Häufig verwendete Tools
Unabhängig davon, ob Sie ein Python-Entwickler sind, der zum ersten Mal mit SQL arbeitet, oder ein SQL-Entwickler, der noch keine Erfahrung mit Python und datenbankinternen Analysen besitzt: Sie benötigen sowohl ein Python-Entwicklungstool als auch einen T-SQL-Abfrage-Editor wie z. B. SQL Server Management Studio (SSMS), um alle Funktionen der datenbankinternen Analysen nutzen zu können.
Für die Python-Entwicklung können Sie Jupyter Notebook-Instanzen verwenden, die in der von SQL Server installierten Anaconda-Distribution gebündelt sind. In diesem Artikel wird beschrieben, wie Sie Jupyter Notebook starten, um Python-Code lokal und remote in SQL Server ausführen zu können.
Bei SSMS handelt es sich um einen separaten Download, der zum Erstellen und Ausführen von gespeicherten Prozeduren in SQL Server nützlich ist, einschließlich derjenigen, die Python-Code enthalten. Sie können nahezu jeden Python-Code, den Sie in Jupyter Notebook schreiben, in eine gespeicherte Prozedur einbetten. Informationen zu SSMS und eingebettetem Python-Code finden Sie in weiteren Schnellstartanleitungen.
Schritt 1: Installieren von Python-Paketen
Auf lokalen Arbeitsstationen müssen dieselben Python-Paketversionen wie in SQL Server installiert sein, einschließlich der Anaconda-Basisversion 4.2.0 mit der Python-Verteilung 3.5.2 und Microsoft-spezifischen Paketen.
Mit einem Installationsskript werden dem Python-Client drei Microsoft-spezifische Bibliotheken hinzugefügt. Das Skript installiert:
- revoscalepy, das zum Definieren von Datenquellenobjekten und dem Computekontext dient.
- microsoftml, das Machine Learning-Algorithmen bereitstellt.
- azureml, das für Operationalisierungsaufgaben im Kontext eigenständiger Server vorgesehen und für datenbankinterne Analysen nur von begrenztem Nutzen ist.
Laden Sie ein Installationsskript herunter. Wählen Sie auf der entsprechenden folgenden GitHub-Seite die Option Rohdatei herunterladen aus.
Install-PyForMLS.ps1 installiert Version 9.2.1 der Microsoft Python-Pakete. Diese Version entspricht einer Standardinstanz von SQL Server.
Install-PyForMLS.ps1 installiert Version 9.3 der Microsoft Python-Pakete.
Öffnen Sie ein PowerShell-Fenster mit erweiterten Administratorberechtigungen (indem Sie mit der rechten Maustaste auf Als Administrator ausführen klicken).
Wechseln Sie zu dem Ordner, in den Sie das Installationsprogramm heruntergeladen haben, und führen Sie das Skript aus. Fügen Sie das Befehlszeilenargument
-InstallFolderhinzu, um einen Ordner für die Speicherung der Bibliotheken anzugeben. Zum Beispiel:cd {{download-directory}} .\Install-PyForMLS.ps1 -InstallFolder "C:\path-to-python-for-mls"
Wenn Sie keinen Installationsordner angeben, lautet der Standardpfad %ProgramFiles%\Microsoft\PyForMLS.
Die Installation nimmt einige Zeit in Anspruch. Im PowerShell-Fenster können Sie den Fortschritt überwachen. Nach Abschluss des Setups verfügen Sie über alle Pakete.
Tipp
Allgemeine Informationen zur Ausführung von Python-Programmen unter Windows finden Sie unter Häufig gestellte Fragen zu Python unter Windows.
Schritt 2: Suchen nach ausführbaren Dateien
Listen Sie in PowerShell den Inhalt des Installationsordners auf, um sicherzugehen, dass die Datei „Python.exe“, Skripts und andere Pakete installiert sind.
Geben Sie
cd \ein, um zum Stammlaufwerk zu wechseln. Geben Sie anschließend den Pfad ein, den Sie im vorherigen Schritt für-InstallFolderangegeben haben. Wenn Sie diesen Parameter bei der Installation ausgelassen haben, lautet der Standardpfadcd %ProgramFiles%\Microsoft\PyForMLS.Geben Sie
dir *.exeein, um die ausführbaren Dateien aufzulisten. Es sollten die Dateien python.exe, pythonw.exe und uninstall-anaconda.exe angezeigt werden.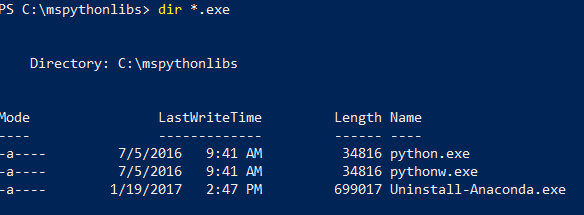
Achten Sie bei Systemen mit mehreren Python-Versionen darauf, diese spezielle Python.exe-Datei zu verwenden, wenn Sie revoscalepy und andere Microsoft-Pakete laden möchten.
Hinweis
Die PATH-Umgebungsvariable auf Ihrem Computer wird durch das Installationsskript nicht geändert. Das bedeutet, dass der neue Python-Interpreter und die soeben installierten Module nicht automatisch für andere Tools, die Sie ggf. verwenden, verfügbar sind. Informationen zur Verknüpfung des Python-Interpreters und der Bibliotheken mit anderen Tools finden Sie im Abschnitt Installieren einer IDE.
Schritt 3: Öffnen von Jupyter Notebook
Anaconda enthält Jupyter Notebook. Erstellen Sie als Nächstes ein Notebook, und führen Sie Python-Code aus, der die soeben installierten Bibliotheken enthält.
Öffnen Sie in der PowerShell-Eingabeaufforderung im Verzeichnis
%ProgramFiles%\Microsoft\PyForMLSim Ordner „Skripts“ die Jupyter Notebook-Anwendung:.\Scripts\jupyter-notebookEin Notebook sollte in Ihrem Standardbrowser unter
https://localhost:8889/treegeöffnet werden.Alternativ dazu können Sie Jupyter Notebook auch starten, indem Sie auf die Datei jupyter-notebook.exe doppelklicken.
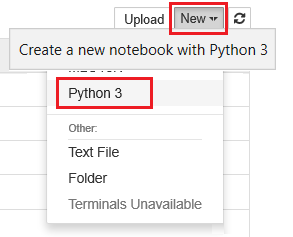
Wählen Sie Neu und dann Python 3 aus.
Geben Sie
import revoscalepyein, und führen Sie den Befehl aus, um eine der Microsoft-spezifischen Bibliotheken zu laden.Geben Sie
print(revoscalepy.__version__)ein, und führen Sie den Befehl aus, um die Versionsinformationen zurückzugeben. Es sollte Version 9.2.1 oder 9.3.0 angezeigt werden. Beide Versionen können mit revoscalepy auf dem Server verwendet werden.Geben Sie eine komplexere Reihe von Anweisungen ein. In diesem Beispiel werden Zusammenfassungsstatistiken mithilfe von rx_summary über ein lokales Dataset generiert. Andere Funktionen rufen den Speicherort der Beispieldaten ab und erstellen ein Datenquellenobjekt für eine lokale XDF-Datei.
import os from revoscalepy import rx_summary from revoscalepy import RxXdfData from revoscalepy import RxOptions sample_data_path = RxOptions.get_option("sampleDataDir") print(sample_data_path) ds = RxXdfData(os.path.join(sample_data_path, "AirlineDemoSmall.xdf")) summary = rx_summary("ArrDelay+DayOfWeek", ds) print(summary)
Im folgenden Screenshot wird in gekürzter Form die Eingabe und ein Teil der Ausgabe angezeigt.

Schritt 4: Anfordern von SQL-Berechtigungen
Wenn Sie eine Verbindung mit einer SQL Server-Instanz herstellen möchten, um Skripts auszuführen und Daten hochzuladen, benötigen Sie einen gültigen Anmeldenamen auf dem Datenbankserver. Sie können entweder einen SQL-Anmeldenamen oder die integrierte Windows-Authentifizierung verwenden. Im Allgemeinen wird die Verwendung der integrierten Windows-Authentifizierung empfohlen. Für einige Szenarios ist die Verwendung des SQL-Anmeldenamens jedoch einfacher, insbesondere wenn Ihr Skript Verbindungszeichenfolgen zu externen Daten enthält.
Das zum Ausführen von Code verwendete Konto muss mindestens über eine Berechtigung zum Lesen der Datenbanken verfügen, mit denen Sie arbeiten. Zudem ist die spezielle Berechtigung „EXECUTE ANY EXTERNAL SCRIPT“ erforderlich. Die meisten Entwickler benötigen auch Berechtigungen zum Erstellen von gespeicherten Prozeduren und zum Schreiben von Daten in Tabellen, die Trainingsdaten oder bewertete Daten enthalten.
Bitten Sie den Datenbankadministrator, in der Datenbank, in der Sie Python verwenden, die folgenden Berechtigungen für Ihr Konto zu konfigurieren:
- EXECUTE ANY EXTERNAL SCRIPT zum Ausführen von Python auf dem Server
- db_datareader zum Ausführen der Abfragen, die zum Trainieren des Modells verwendet werden
- db_datawriter zum Schreiben von Trainingsdaten oder bewerteten Daten
- db_owner zum Erstellen von Objekten wie z. B. gespeicherte Prozeduren, Tabellen und Funktionen. db_owner ist auch zum Erstellen von Beispiel- und Testdatenbanken erforderlich.
Sind für Ihren Code Pakete erforderlich, die nicht standardmäßig mit SQL Server installiert werden, vereinbaren Sie mit dem Datenbankadministrator, dass die Pakete mit der Instanz installiert werden. SQL Server ist eine gesicherte Umgebung, in der es Einschränkungen hinsichtlich der Installation von Paketen gibt. Die Ad-hoc-Installation von Paketen als Teil des Codes wird nicht empfohlen, selbst wenn Sie über die entsprechende Berechtigung verfügen. Bedenken Sie vor der Installation neuer Pakete in der Serverbibliothek die jeweiligen Sicherheitsrisiken.
Schritt 5: Erstellen von Testdaten
Wenn Sie über Berechtigungen zum Erstellen einer Datenbank auf dem Remoteserver verfügen, können Sie mit dem folgenden Code eine IRIS-Demodatenbank erstellen, die für die restlichen Schritte in diesem Artikel verwendet wird.
5.1: Remoteerstellung der Datenbank „irissql“
from mssql_python import connect
# creating a new db to load Iris sample in
new_db_name = "irissql"
connection_string = "Server=localhost;Database={0};Trusted_Connection=Yes;"
# you can also swap Trusted_Connection for UID={your username};PWD={your password}
conn = connect(connection_string.format("master"))
conn.setautocommit(True)
conn.cursor().execute("IF EXISTS(SELECT * FROM sys.databases WHERE [name] = '{0}') DROP DATABASE {0}".format(new_db_name))
conn.cursor().execute("CREATE DATABASE " + new_db_name)
conn.close()
print("Database created")
5.2: Importieren eines IRIS-Beispiels aus SkLearn
from sklearn import datasets
import pandas as pd
# SkLearn has the Iris sample dataset built in to the package
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
5.3: Verwenden von revoscalepy-APIs zum Erstellen einer Tabelle und zum Laden der IRIS-Daten
from revoscalepy import RxSqlServerData, rx_data_step
# Example of using RX APIs to load data into SQL table. You can also do this with mssql-python
table_ref = RxSqlServerData(connection_string=connection_string.format(new_db_name), table="iris_data")
rx_data_step(input_data = df, output_file = table_ref, overwrite = True)
print("New Table Created: Iris")
print("Sklearn Iris sample loaded into Iris table")
Schritt 6: Testen der Remoteverbindung
Stellen Sie vor der Ausführung dieses Schritts sicher, dass Sie über Berechtigungen für die SQL Server-Instanz sowie über eine Verbindungszeichenfolge zur IRIS-Beispieldatenbank verfügen. Ist die Datenbank nicht vorhanden, doch Sie verfügen über ausreichende Berechtigungen, können Sie eine Datenbank mithilfe dieser Inlineanweisungen erstellen.
Ersetzen Sie die Verbindungszeichenfolge durch gültige Werte. Im Beispielcode wird hierfür "Server=localhost;Database=irissql;Trusted_Connection=Yes;" verwendet. Mit Ihrem Code sollten Sie jedoch einen Remoteserver (möglicherweise mit einem Instanznamen) und eine Anmeldeinformationsoption angeben, die dem Anmeldenamen für eine Datenbank entspricht.
6-1: Definieren einer Funktion
Mit dem folgenden Code wird eine Funktion definiert, die Sie in einem späteren Schritt an SQL Server senden. Bei der Ausführung werden Daten und Bibliotheken (revoscalepy, pandas, matplotlib) auf dem Remoteserver verwendet, um Punktdiagramme des IRIS-Datasets zu erstellen. Der Datenstrom der PNG-Datei wird an Jupyter Notebook zurückgegeben und im Browser gerendert.
def send_this_func_to_sql():
from revoscalepy import RxSqlServerData, rx_import
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import io
# remember the scope of the variables in this func are within our SQL Server Python Runtime
connection_string = "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;"
# specify a query and load into pandas dataframe df
sql_query = RxSqlServerData(connection_string=connection_string, sql_query = "select * from iris_data")
df = rx_import(sql_query)
scatter_matrix(df)
# return bytestream of image created by scatter_matrix
buf = io.BytesIO()
plt.savefig(buf, format="png")
buf.seek(0)
return buf.getvalue()
6-2: Senden der Funktion an SQL Server
Erstellen Sie in diesem Beispiel den Remotecomputekontext, und senden Sie die Ausführung der Funktion mit rx_exec an SQL Server. Die Funktion rx_exec ist nützlich, da sie einen Computekontext als Argument akzeptiert. Funktionen, die remote ausgeführt werden sollen, müssen über ein Computekontextargument verfügen. Einige Funktionen, wie rx_lin_mod, unterstützen dieses Argument direkt. Für Vorgänge, auf die das nicht zutrifft, können Sie mit rx_exec Ihren Code in einem Remotecomputekontext bereitstellen.
In diesem Beispiel müssen keine Rohdaten von SQL Server zu Jupyter Notebook übertragen werden. Alle Berechnungen werden innerhalb der IRIS-Datenbank durchgeführt, und nur die Bilddatei wird an den Client zurückgegeben.
from IPython import display
import matplotlib.pyplot as plt
from revoscalepy import RxInSqlServer, rx_exec
# create a remote compute context with connection to SQL Server
sql_compute_context = RxInSqlServer(connection_string=connection_string.format(new_db_name))
# use rx_exec to send the function execution to SQL Server
image = rx_exec(send_this_func_to_sql, compute_context=sql_compute_context)[0]
# only an image was returned to my jupyter client. All data remained secure and was manipulated in my db.
display.Image(data=image)
Der folgende Screenshot zeigt die Eingabe sowie die Ausgabe als Punktdiagramm:

Schritt 7: Starten von Python mit Tools
Da Entwickler häufig mehrere Python-Versionen verwenden, wird Python beim Setup nicht der PATH-Umgebung hinzugefügt. Wenn Sie die ausführbare Python-Datei und die beim Setup installierten Bibliotheken verwenden möchten, verknüpfen Sie Ihre IDE im Pfad, der auch revoscalepy und microsoftml enthält, mit der Datei Python.exe.
Befehlszeile
Wenn Sie Python.exe über %ProgramFiles%\Microsoft\PyForMLS (oder einen anderen Pfad, den Sie für die Installation der Python-Clientbibliothek angegeben haben) ausführen, haben Sie Zugriff auf die vollständige Anaconda-Distribution sowie die Microsoft Python-Module revoscalepy und microsoftml.
- Wechseln Sie zu
%ProgramFiles%\Microsoft\PyForMLS, und führen Sie Python.exe aus. - Öffnen Sie die interaktive Hilfe:
help(). - Geben Sie in die Eingabeaufforderung der Hilfe den Namen eines Moduls ein:
help> revoscalepy. Es werden Name, Paketinhalt, Version und Dateispeicherort zurückgegeben. - Geben Sie in der Eingabeaufforderung von help> die Version und die Paketinformationen zurück:
revoscalepy. Drücken Sie mehrmals die EINGABETASTE, um die Hilfe zu beenden. - Importieren Sie ein Modul:
import revoscalepy.
Jupyter Notebook
In diesem Artikel wird zur Veranschaulichung von Funktionsaufrufen von revoscalepy die integrierte Anwendung Jupyter Notebook verwendet. Wenn Sie mit diesem Tool noch nicht vertraut sind, erfahren Sie im folgenden Screenshot, wie die Elemente für eine reibungslose Funktion miteinander verbunden sind.
Der übergeordnete Ordner %ProgramFiles%\Microsoft\PyForMLS enthält Anaconda sowie die Microsoft-Pakete. Anaconda beinhaltet Jupyter Notebook im Ordner „Skripts“, und die ausführbaren Python-Dateien sind automatisch bei Jupyter Notebook registriert. Unter „Sitepakete“ gespeicherte Pakete können in ein Notebook importiert werden, einschließlich der drei Microsoft-Pakete für Data Science und Machine Learning.
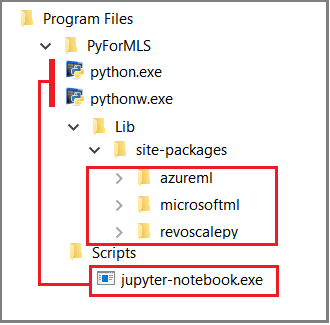
Wenn Sie eine andere IDE verwenden, müssen Sie die ausführbaren Python-Dateien und Funktionsbibliotheken mit dem entsprechenden Tool verknüpfen. Die folgenden Abschnitte enthalten Anweisungen für häufig verwendete Tools.
Visual Studio
Wenn Sie Python in Visual Studio verwenden, erstellen Sie mit den folgenden Konfigurationsoptionen eine Python-Umgebung, die die Microsoft Python-Pakete umfasst.
| Konfigurationseinstellung | Wert |
|---|---|
| Präfixpfad | %ProgramFiles%\Microsoft\PyForMLS |
| Interpreterpfad | %ProgramFiles%\Microsoft\PyForMLS\python.exe |
| Fenstermodus-Interpreter | %ProgramFiles%\Microsoft\PyForMLS\pythonw.exe |
Informationen zur Konfiguration einer Python-Umgebung finden Sie unter Erstellen und Verwalten von Python-Umgebungen in Visual Studio.
PyCharm
Legen Sie den Interpreter in PyCharm auf die ausführbare Python-Datei fest.
Wählen Sie in einem neuen Projekt unter „Einstellungen“ die Option Lokale Datei hinzufügen aus.
Geben Sie
%ProgramFiles%\Microsoft\PyForMLS\ein.
Nun können Sie die Module revoscalepy, microsoftml oder azureml importieren. Sie können auch ein interaktives Fenster öffnen, indem Sie auf Tools>Python-Konsole klicken.