Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Lernprogramm erfahren Sie, wie Sie ein beliebiges ONNX-basiertes Großsprachmodell (LLM) über die AI Dev Gallery ausführen– eine Open-Source-Windows-Anwendung (verfügbar in der Microsoft Store), die KI-unterstützte Beispiele zeigt.
Diese Schritte funktionieren für alle LLM im ONNX Runtime GenAI Format, einschließlich:
- Modelle, die von Hugging Face heruntergeladen wurden
- Mit dem Foundry Toolkit für Visual Studio Code-Konvertierungstool konvertierte Modelle aus anderen Frameworks
Schritt 1: Auswählen eines interaktiven Beispiels im AI Dev Gallery
Öffnen Sie die AI Dev Gallery App.
Navigieren Sie zur Registerkarte "Beispiele ", und wählen Sie ein Textbeispiel aus (z. B. "Text generieren" oder "Chat").
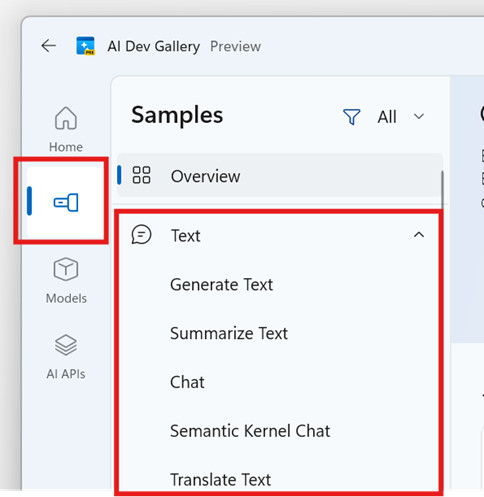
Klicken Sie auf die Schaltfläche " Modellauswahl ", um die verfügbaren Modelle für dieses Beispiel anzuzeigen.
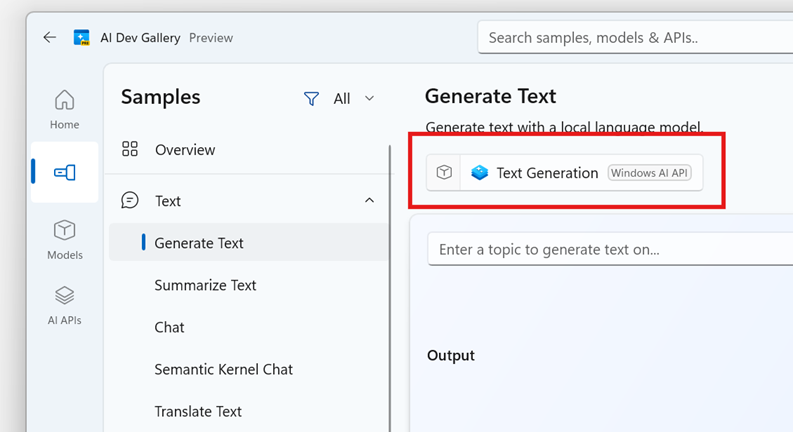
Wählen Sie die Registerkarte "Benutzerdefinierte Modelle " aus, um Ihre eigene ONNX LLM einzubringen.
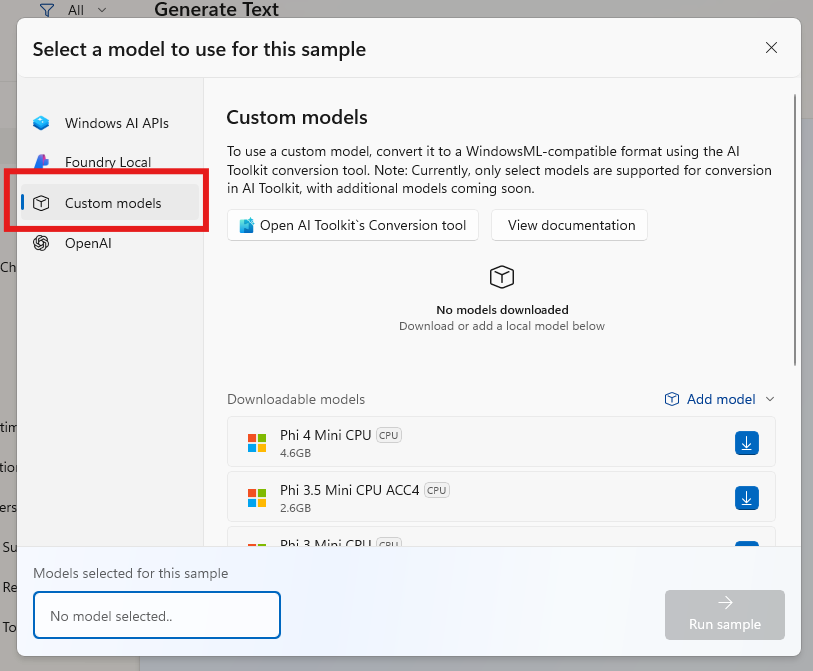
Schritt 2: Abrufen oder Konvertieren eines ONNX LLM-Modells
Um ein Modell im AI Dev GalleryFormat zu verwenden, muss es im ONNX Runtime GenAI Format vorliegen. Sie haben folgende Möglichkeiten:
Laden Sie ein vorkonvertiertes Modell herunter:
Durchsuchen Sie Modelle in Hugging Face ONNX Models, oder
Gehen Sie in AI Dev Gallery "Modell hinzufügen" → "Hugging Face durchsuchen"
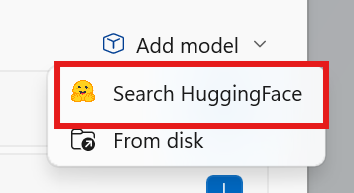
Konvertieren Sie Ihr eigenes Modell:
- Klicken Sie auf Open Foundry Toolkits Konvertierungstool in der Modellauswahl, die die Erweiterung Foundry Toolkit in Visual Studio Code startet.
- Wenn Sie es nicht installiert haben, suchen Sie im VS Code Extensions Marketplace nach "Foundry Toolkit".
- Verwenden Sie das Foundry Toolkit für Visual Studio Code, um ein unterstütztes Modell in ONNX Runtime GenAI Format zu konvertieren.
- Klicken Sie auf Open Foundry Toolkits Konvertierungstool in der Modellauswahl, die die Erweiterung Foundry Toolkit in Visual Studio Code startet.
Derzeit unterstützte Modelle für die Konvertierung:
- DeepSeek R1 Distill Qwen 1.5B
- Phi 3.5 Mini-Anweisung
- Qwen 2.5-1.5B Instruct
- Llama 3.2 1B-Anweisung
Hinweis
Die Konvertierung des Foundry Toolkits befindet sich in der Vorschau-Version und unterstützt derzeit ausschließlich die oben aufgeführten Modelle.
Schritt 3: Verwenden des ONNX-Modells im AI Dev Gallery
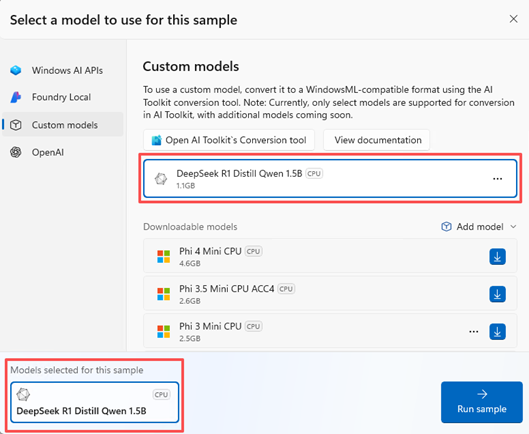
Sobald Sie ein Modell im ONNX Runtime GenAI Format haben, kehren Sie zum AI Dev GalleryModellauswahlfenster zurück.
Klicken Sie auf "Modell hinzufügen" → Von Datenträger , und geben Sie den Pfad zu Ihrem ONNX-Modell an.
Hinweis
Wenn Sie das Konvertierungstool des Foundry Toolkits verwendet haben, sollte der konvertierte Modellpfad diesem Format entsprechen:
c:/{workspace}/{model_project}/history/{workflow}/model/model.onnxNachdem Sie hinzugefügt haben, können Sie nun Ihr Modell auswählen und mit den interaktiven Beispielen verwenden.
Klicken Sie optional auf "Quellcode anzeigen" in der App, um den Code anzuzeigen, der das Modell ausführt.
Unterstützte Beispiele in der AI Dev Gallery
Diese ONNX-LLMs können mit den folgenden Beispielen im AI Dev Gallery verwendet werden.
Text
- Text generieren
- Zusammenfassen von Text
- Chat
- Semantischer Kernel-Chat
- Grammatikprüfung
- Paraphrasentext
- Analysieren der Textstimmung
- Inhaltsmoderation
- Benutzerdefinierte Parameter
- Retrieval Augmented Generation (RAG)
Intelligente Steuerelemente
- Smart TextBox
Code
- Code generieren
- Erläutern von Code
Nächste Schritte
Nachdem Sie nun Ihre ONNX LLM AI Dev Gallery ausprobiert haben, können Sie den gleichen Ansatz in Ihrer eigenen App integrieren.
Funktionsweise des Beispiels
- Die AI Dev Gallery Beispiele verwenden
OnnxRuntimeGenAIChatClient(aus dem ONNX Runtime GenAI SDK) zum Umschließen Ihres ONNX-Modells. - Dieser Client wird in die
Microsoft.Extensions.AIAbstraktionen (IChatClient,ChatMessageusw.) eingebunden, damit Sie auf natürliche Weise mit Prompts und Antworten auf hoher Ebene arbeiten können. - Innerhalb der Factory (
OnnxRuntimeGenAIChatClientFactory) stellt die App sicher, dass Windows ML (WinML) Ausführungsanbieter registriert sind und das ONNX-Modell mit der besten verfügbaren Hardwarebeschleunigung (CPU, GPU oder NPU) ausführt.
Beispiel aus dem Beispiel:
// Register WinML execution providers (under the hood)
var catalog = Microsoft.Windows.AI.MachineLearning.ExecutionProviderCatalog.GetDefault();
await catalog.EnsureAndRegisterCertifiedAsync();
// Create a chat client for your ONNX model
chatClient = await OnnxRuntimeGenAIChatClientFactory.CreateAsync(
@"C:\path\to\your\onnx\model",
new LlmPromptTemplate
{
System = "<|system|>\n{{CONTENT}}<|end|>\n",
User = "<|user|>\n{{CONTENT}}<|end|>\n",
Assistant = "<|assistant|>\n{{CONTENT}}<|end|>\n",
Stop = [ "<|system|>", "<|user|>", "<|assistant|>", "<|end|>"]
});
// Stream responses into your UI
await foreach (var part in chatClient.GetStreamingResponseAsync(messages, null, cts.Token))
{
OutputTextBlock.Text += part;
}
Weitere Informationen zum Integrieren von ONNX-Modellen in Windows Anwendungen finden Sie unter:
Siehe auch
- Herunterladen AI Dev Gallery
- ONNX-Modelle auf Hugging Face
- Foundry Toolkit für Visual Studio Code
- AI Dev Gallery GitHub-Repository