Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() Azure SQL-Datenbank
Azure SQL-Datenbank
Sie können eine vorhandene Datenbank in der Azure SQL-Datenbank mithilfe des Azure-Portals, der Azure CLI, PowerShell oder Transact-SQL in Hyperscale konvertieren.
Prerequisites
Um eine Datenbank zu konvertieren, die georeplikation verwendet oder Teil einer Failovergruppe in Hyperscale ist, beginnen Sie mit der Konvertierung des primären Replikats. Das geo-sekundäre Replikat wird automatisch konvertiert. Sie können eine georeplizierte Nicht-Hyperscale-Datenbank mithilfe von T-SQL, REST-API, PowerShell oder Azure CLI in Hyperscale konvertieren.
Direkte Konvertierung von der Standarddienstebene in Hyperscale wird nicht unterstützt. Um diese Konvertierung auszuführen, ändern Sie zuerst die Datenbank in eine andere Dienstebene als "Einfach" (z. B. "Allgemein"), und fahren Sie dann mit der Konvertierung in Hyperscale fort.
Sie können den Fortschritt der Konvertierung mit T-SQL überwachen. Um T-SQL-Befehle in Ihrer Azure SQL-Datenbank auszuführen, verwenden Sie SQL Server Management Studio (SSMS),die MSSQL-Erweiterung für Visual Studio Code, sqlcmd oder Ihr bevorzugtes T-SQL-Abfragetool.
Konvertierung einer Datenbank mit Georeplikaten
Wenn Sie eine Datenbank in einer Georeplikationsbeziehung konvertieren, behält der Konvertierungsprozess die Georeplikationsverknüpfung bei. Sowohl die primäre als auch die geo-sekundäre Datenbank werden zusammen in Hyperscale konvertiert.
- Die Konvertierung in Hyperscale muss gestartet werden, indem das primäre Georeplikat konvertiert wird. Beim Versuch, ein geo-sekundäres Replikat zu konvertieren, tritt ein Fehler auf: Ein geo-sekundäres Replikat "Datenbankname-Platzhalter" kann nicht in Hyperscale konvertiert werden. Um sowohl die primären als auch die geo-sekundären Replikate in Hyperscale zu konvertieren, wiederholen Sie den Vorgang für das primäre Replikat.
- Die Anzahl der geo-sekundären Replikate sollte auf eine reduziert werden, um den Konvertierungsprozess zu initiieren.
- Das Erstellen des Georeplikats eines Georeplikats (auch bekannt als „Verkettung von Georeplikaten“) wird in Hyperscale nicht unterstützt. Wenn eine verkettete Georeplikationskonfiguration vorhanden ist, muss sie entfernt werden, bevor die Konvertierung in Hyperscale gestartet wird.
- Ein geplantes Failover ist nicht möglich, während die Konvertierung der geo-primären Datenbank in Hyperscale ausgeführt wird. Ein erzwungenes Umschalten zu einem geosekundären Replikat ist möglich. Je nach Status der Konvertierung zum Zeitpunkt des erzwungenen Failovers kann der neue Primärserver der Georeplikation nach dem Failover jedoch entweder die Hyperscale-Dienstebene oder seine ursprüngliche Dienstebene verwenden.
- Wenn sich eine geo-primäre Datenbank in einem elastischen Pool befindet, kann sie im Rahmen der Konvertierung in einen vorhandenen elastischen Hyperscale-Pool verschoben oder eine eigenständige Hyperscale-Datenbank erstellt werden. Wenn sich eine geo-sekundäre Datenbank jedoch in einem elastischen Pool befindet, entfernt die Umstellung auf Hyperscale sie immer aus dem Pool. Sie können die geo-sekundäre Datenbank in einen hyperskalenlastischen Pool in einem separaten Schritt verschieben, sobald die Konvertierung abgeschlossen ist.
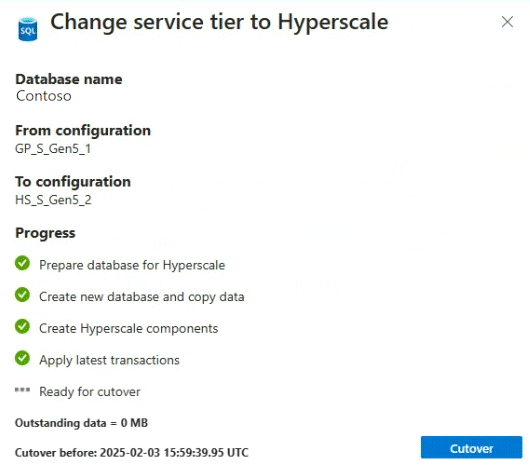
Cutover
Der Konvertierungsprozess ist in zwei Phasen unterteilt: die Konvertierung der Datenbank, die erfolgt, während die vorhandene Datenbank online ist, und dann eine Umstellung auf die neue Hyperscale-Datenbank.
Die Zeit zum Verschieben einer vorhandenen Datenbank zu Hyperscale umfasst die Zeit zum Kopieren der Daten und die Zeit zum Wiedergeben der Änderungen, die beim Kopieren von Daten in der Quelldatenbank vorgenommen wurden. Während die Datenkopiezeit ungefähr mit der Größe der Datenbank skaliert wird, kann die tatsächliche Kopiergeschwindigkeit aufgrund von Faktoren wie Netzwerkdurchsatz, E/A-Bandbreite, Speicherlatenz und vorübergehender Dienstlast variieren. Es wird empfohlen, während eines niedrigeren Schreibaktivitätszeitraums in Hyperscale zu konvertieren, sodass die Zeit für die Wiedergabe akkumulierter Änderungen kürzer ist. Es wird empfohlen, den nächsten Schritt manuell zu steuern.
Sie haben die Möglichkeit, auszuwählen, wann die Übernahme erfolgt – sobald die Datenbank bereit ist oder manuell zu einem Zeitpunkt Ihrer Wahl. Standardmäßig wird der Prozess zum Konvertieren in Hyperscale automatisch überschnitten.
- Wenn Sie sich für die manuelle Umschaltung zu einem Zeitpunkt Ihrer Wahl entscheiden, haben Sie 24 Stunden Zeit, um die manuelle Umschaltung zu starten, nachdem die Datenbank zur Umschaltung bereit ist. Sie können eine manuelle Übernahme über das Azure-Portal, die Azure-Befehlszeilenschnittstelle, PowerShell oder T-SQL initiieren.
Während des letzten Übernahmevorgangs auf Hyperscale erleben Ihre Anwendungen nur einen kurzen Zeitraum von Ausfallzeiten, in der Regel weniger als eine Minute.
Es gibt mehrere Phasen im Konvertierungsprozess, die im Azure-Portal (auf der Statusberichtsseite), über Azure CLI (az sql db op list), PowerShell (Get-AzSqlDatabaseActivity) oder mithilfe von T-SQL (sys.dm_operation_status) überwacht werden können.
Beim Konvertieren einer Datenbank aus den Dienstebenen Premium oder Business Critical in Hyperscale werden vorhandene Clientverbindungen in Phase 1 getrennt. Dies ähnelt der Trennung, die beim Skalieren der Datenbank zwischen Dienstebenen auftritt. Anwendungen sollten so konzipiert sein, dass vorübergehende Verbindungsunterbrechungen ordnungsgemäß verarbeitet werden, indem sie Wiederholungslogik implementieren, wie in der Retry-Logik für vorübergehende Fehler beschrieben.
Konvertieren einer Datenbank in Hyperscale
Um eine vorhandene Azure SQL-Datenbank in Hyperscale zu konvertieren, identifizieren Sie zuerst Ihr Zieldienstziel.
Ziehen Sie Ressourcengrenzen für einzelne Datenbanken zu Rate, wenn Sie nicht sicher sind, welches Dienstziel für Ihre Datenbank geeignet ist. In vielen Fällen können Sie ein Dienstziel mit derselben Anzahl von virtuellen Kernen und derselben Hardwaregeneration wie die ursprüngliche Datenbank auswählen. Bei Bedarf können Sie das Dienstziel später mit minimalen Ausfallzeiten ändern. Die Abrechnung für Hyperscale beginnt erst nach dem Cutover.
Wählen Sie die Registerkarte für Ihre bevorzugte Methode aus, um Ihre Datenbank zu konvertieren:
Mit dem Azure-Portal können Sie in Hyperscale konvertieren, indem Sie die Dienstebene für Ihre Datenbank ändern.

- Navigieren Sie zu der Datenbank, die Sie im Azure-Portal konvertieren möchten.
- Wählen Sie in der linken Navigationsleiste Compute und Speicher aus.
- Wählen Sie die Dropdownliste der Dienstebene aus , um die Optionen für Dienstebenen zu erweitern.
- Wenn Sie das kostenlose Angebot der Azure SQL-Datenbank verwendet haben, wählen Sie die Schaltfläche aus, um das Kostenlose Datenbankangebot zu entfernen. Dann wird die Dropdownliste der Dienstebene angezeigt.
- Wählen Sie Hyperscale aus der Dropdownliste aus.
- Überprüfen Sie die Computeebene , und wählen Sie "Bereitgestellt " oder "Serverlos" aus.
- Überprüfen Sie den Cutover-Modus, eine für die Konvertierung zu Hyperscale spezifische Auswahl.
- Die Umstellung erfolgt, nachdem die Datenbank explizit für die Konvertierung in Hyperscale vorbereitet wurde.
Der Übernahmemodus bestimmt, wann die Verbindung mit der vorhandenen Azure SQL-Datenbank für die Konvertierung in Hyperscale vorübergehend unterbrochen wird:
- Die automatische Umschaltung führt die Umschaltung aus, sobald die Hyperscale-Datenbank bereitgestellt ist.
- Manuelle Umschaltung ermöglicht es Ihnen, die Umschaltung zu einem Zeitpunkt Ihrer Wahl im Azure-Portal zu initiieren. Diese Option ist am nützlichsten, um den Wechsel so zu planen, dass es nur zu minimalen Geschäftsunterbrechungen kommt.
- Die Umstellung erfolgt, nachdem die Datenbank explizit für die Konvertierung in Hyperscale vorbereitet wurde.
Der Übernahmemodus bestimmt, wann die Verbindung mit der vorhandenen Azure SQL-Datenbank für die Konvertierung in Hyperscale vorübergehend unterbrochen wird:
- Überprüfen Sie die aufgeführte Hardwarekonfiguration . Wählen Sie bei Bedarf die Option "Konfiguration ändern" aus, um die entsprechende Hardwarekonfiguration für Ihre Workload auszuwählen.
- Wählen Sie den vCores-Schieberegler aus, wenn Sie die Anzahl der für Ihre Datenbank verfügbaren vCores unter der Hyperscale-Dienstebene ändern möchten.
- Wählen Sie den Schieberegler High-Availability für sekundäre Replikate aus , wenn Sie die Anzahl der Replikate unter der Hyperscale-Dienstebene ändern möchten.
- Wählen Sie Anwenden.
- Überwachen Sie die Konvertierung im Azure-Portal.
- Navigieren zur Datenbank im Azure-Portal.
- Wählen Sie in der linken Navigationsleiste die Option "Übersicht" aus.
- Überprüfen Sie den Abschnitt "Benachrichtigungen" unten im rechten Bereich. Wenn aktuell Vorgänge ausgeführt werden, wird ein Benachrichtigungsfeld angezeigt.
- Wählen Sie das Benachrichtigungsfeld aus, um Details anzuzeigen.
- Der Bereich "Laufende Vorgänge " wird geöffnet. Überprüfen Sie die Details der laufenden Vorgänge.
Wenn Sie den manuellen Übernahmemodus ausgewählt haben, zeigt Ihnen das Azure-Portal bei Bedarf eine Schaltfläche "Übernahme" an.