Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Planen Sie vor der Bereitstellung eines HDInsight-Clusters die beabsichtigte Clusterkapazität, indem Sie die erforderliche Leistung und Skalierung ermitteln. Diese Planung trägt dazu bei, sowohl die Benutzerfreundlichkeit als auch die Kosten zu optimieren. Einige Entscheidungen zur Clusterkapazität können nach der Bereitstellung nicht mehr geändert werden. Wenn sich die Leistungsparameter ändern, kann ein Cluster demontiert und neu erstellt werden, ohne gespeicherte Daten zu verlieren.
Die wichtigsten Fragen zur Kapazitätsplanung sind:
- In welcher geografischen Region sollten Sie Ihren Cluster bereitstellen?
- Wie viel Speicher benötigen Sie?
- Welchen Clustertyp sollten Sie bereitstellen?
- Welche Größe und art von virtueller Maschine (VM) sollten Ihre Clusterknoten verwenden?
- Wie viele Arbeitsknoten sollten ihr Cluster aufweisen?
Auswählen einer Azure-Region
Die Azure-Region bestimmt, wo Ihr Cluster physisch bereitgestellt wird. Um die Latenz von Lese- und Schreibvorgängen zu minimieren, sollte sich der Cluster in der Nähe Ihrer Daten befinden.
HDInsight ist in vielen Azure-Regionen verfügbar. Informationen zum Suchen der nächstgelegenen Region finden Sie unter "Nach Region verfügbare Produkte".
Speicherort und Größe auswählen
Speicherort des Standardspeichers
Der Standardspeicher, entweder ein Azure Storage-Konto oder Azure Data Lake Storage, muss sich an demselben Speicherort wie Ihr Cluster befinden. Azure Storage ist an allen Standorten verfügbar. Data Lake Storage ist in einigen Regionen verfügbar – siehe aktuelle Verfügbarkeit von Data Lake Storage.
Speicherort vorhandener Daten
Wenn Sie ein vorhandenes Speicherkonto oder Data Lake Storage als Standardspeicher ihres Clusters verwenden möchten, müssen Sie Den Cluster an diesem Speicherort bereitstellen.
Speichergröße
Auf einem bereitgestellten Cluster können Sie andere Azure Storage-Konten anfügen oder auf andere Data Lake Storage zugreifen. Alle Ihre Speicherkonten müssen sich an demselben Speicherort wie Ihr Cluster befinden. Ein Data-Lake-Speicher kann sich an einem anderen Ort befinden, obwohl große Entfernungen eine höhere Latenz verursachen können.
Azure Storage hat einige Kapazitätsbeschränkungen, während Data Lake Storage fast unbegrenzt ist. Ein Cluster kann auf eine Kombination verschiedener Speicherkonten zugreifen. Typische Beispiele sind:
- Wenn die Datenmenge wahrscheinlich die Speicherkapazität eines einzelnen BLOB-Speichercontainers überschreitet.
- Die Zugriffsrate könnte beim Zugriff auf den Blobcontainer den Schwellenwert überschreiten, bei dem eine Drosselung auftritt.
- Wenn Sie Daten erstellen möchten, haben Sie bereits in einen Blobcontainer hochgeladen, der für den Cluster verfügbar ist.
- Wenn Sie unterschiedliche Teile des Speichers aus Sicherheitsgründen isolieren oder die Verwaltung vereinfachen möchten.
Verwenden Sie für eine bessere Leistung nur einen Container pro Speicherkonto.
Auswählen eines Clustertyps
Der Clustertyp bestimmt die Arbeitslast, für die Ihr HDInsight-Cluster konfiguriert ist. Zu den Typen gehören Apache Hadoop, ApacheKafka oder Apache Spark. Eine detaillierte Beschreibung der verfügbaren Clustertypen finden Sie in der Einführung in Azure HDInsight. Jeder Clustertyp verfügt über eine bestimmte Bereitstellungstopologie, die Anforderungen für die Größe und Anzahl von Knoten enthält.
Wählen Sie die Größe und den Typ des virtuellen Computers aus.
Jeder Clustertyp verfügt über eine Reihe von Knotentypen, und jeder Knotentyp verfügt über bestimmte Optionen für die Größe und den Typ des virtuellen Computers.
Um die optimale Clustergröße für Ihre Anwendung zu ermitteln, können Sie die Clusterkapazität vergleichen und die Größe wie angegeben erhöhen. Sie können beispielsweise eine simulierte Workload oder eine Canaryabfrage verwenden. Führen Sie Ihre simulierten Workloads auf unterschiedlichen Größenclustern aus. Erhöhen Sie die Größe schrittweise, bis die beabsichtigte Leistung erreicht ist. Eine "Canary Query" kann regelmäßig neben den anderen Produktionsabfragen eingefügt werden, um zu zeigen, ob der Cluster über genügend Ressourcen verfügt.
Weitere Informationen zum Auswählen der richtigen VM-Familie für Ihre Workload finden Sie unter Auswählen der richtigen VM-Größe für Ihren Cluster.
Auswählen der Clusterskala
Die Skalierung eines Clusters wird durch die Menge seiner VM-Knoten bestimmt. Für alle Clustertypen gibt es Knotentypen, die eine bestimmte Skalierung aufweisen, und Knotentypen, die das Skalieren unterstützen. Beispielsweise kann ein Cluster genau drei Apache ZooKeeper-Knoten oder zwei Head-Knoten erfordern. Arbeitsknoten, die die Datenverarbeitung auf verteilte Weise durchführen, profitieren von anderen Arbeitsknoten.
Je nach Clustertyp wird durch erhöhende Anzahl von Arbeitsknoten mehr Rechenkapazität (z. B. mehr Kerne) hinzugefügt. Weitere Knoten erhöhen den Gesamtspeicher, der für den gesamten Cluster erforderlich ist, um den speicherinternen Speicher der verarbeiteten Daten zu unterstützen. Wie bei der Auswahl der VM-Größe und des Typs wird die Auswahl der richtigen Clusterskala in der Regel empirisch erreicht. Verwenden Sie simulierte Workloads oder Canary-Abfragen.
Sie können Ihren Cluster skalieren, um Spitzenlastanforderungen zu erfüllen. Skalieren Sie sie dann wieder nach unten, wenn diese zusätzlichen Knoten nicht mehr benötigt werden. Mit der Autoskalierungsfunktion können Sie Ihren Cluster automatisch basierend auf vordefinierten Metriken und Anzeigedauern skalieren. Weitere Informationen zum manuellen Skalieren Ihrer Cluster finden Sie unter Scale HDInsight Cluster.
Clusterlebenszyklus
Die Lebensdauer des Clusters wird Ihnen in Rechnung gestellt. Wenn nur bestimmte Zeiten vorhanden sind, die Sie für Ihren Cluster benötigen, erstellen Sie On-Demand-Cluster mithilfe von Azure Data Factory. Sie können auch PowerShell-Skripts erstellen, die Ihren Cluster bereitstellen und löschen, und diese Skripts dann mithilfe von Azure Automation planen.
Hinweis
Wenn ein Cluster gelöscht wird, wird der standardmäßige Hive-Metaspeicher ebenfalls gelöscht. Verwenden Sie einen externen Metadatenspeicher wie Azure Database oder Apache Oozie, um den Metastore für die nächste Clusterreerstellung beizubehalten.
Isolieren von Fehlern bei Clusteraufträgen
Manchmal können Fehler aufgrund paralleler Ausführung von Mehrfachzuordnungen auftreten und Komponenten auf einem Cluster mit mehreren Knoten reduzieren. Um das Problem zu isolieren, testen Sie verteilte Tests. Führen Sie mehrere Aufträge gleichzeitig auf einem einzelnen Workerknotencluster aus. Erweitern Sie dann diesen Ansatz, um mehrere Aufträge gleichzeitig auf Clustern auszuführen, die mehr als einen Knoten enthalten. Verwenden Sie zum Erstellen eines HDInsight-Clusters mit einem einzigen Knoten in Azure die Custom(size, settings, apps) Option und verwenden Sie den Wert 1 für die Anzahl der Workerknoten im Abschnitt "Clustergröße ", wenn Sie einen neuen Cluster im Portal bereitstellen.
Verwaltung der HDInsight-Kontingente anzeigen
Zeigen Sie eine granulare Ebene und Kategorisierung des Kontingents auf einer VM-Familienebene an. Zeigen Sie das aktuelle Kontingent an, und wie viel Kontingent für eine Region auf VM-Familienebene verbleibt.
Hinweis
Dieses Feature ist derzeit in HDInsight 4.x und 5.x für die EUAP-Region „USA, Osten“ verfügbar. Weitere Regionen, die anschließend folgen sollen.
Aktuelles Kontingent anzeigen:
Sehen Sie sich das aktuelle Kontingent an und wie viel Kontingent für eine Region auf VM-Familienebene verbleibt.
Suchen Sie in Azure-Portal in der oberen Suchleiste nach Kontingenten, und wählen Sie dies aus.
Wählen Sie auf der Seite "Kontingent" die Option "Azure HDInsight" aus.
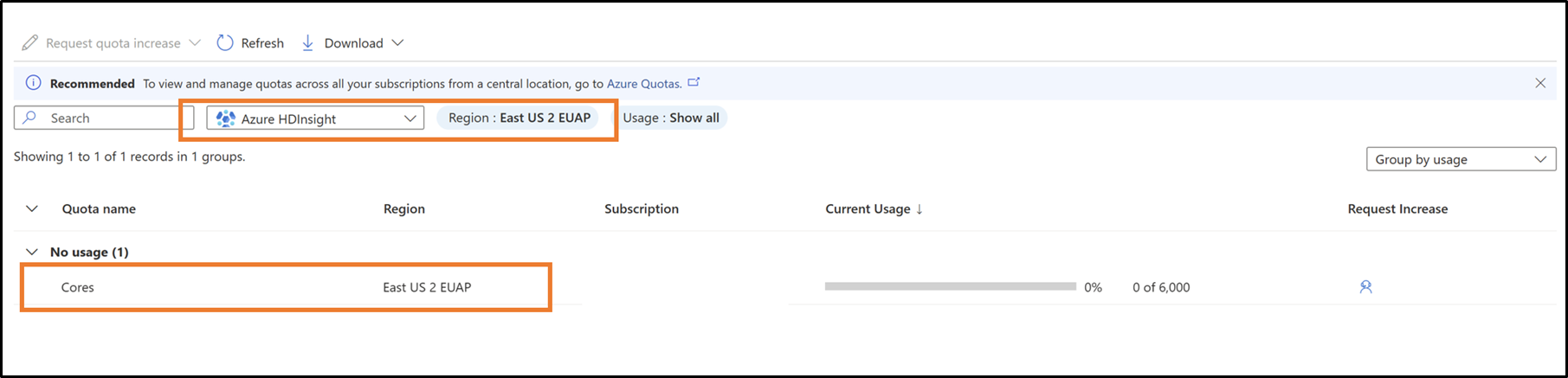
Wählen Sie im Dropdownfeld Ihr Abonnement und Ihre Region aus.
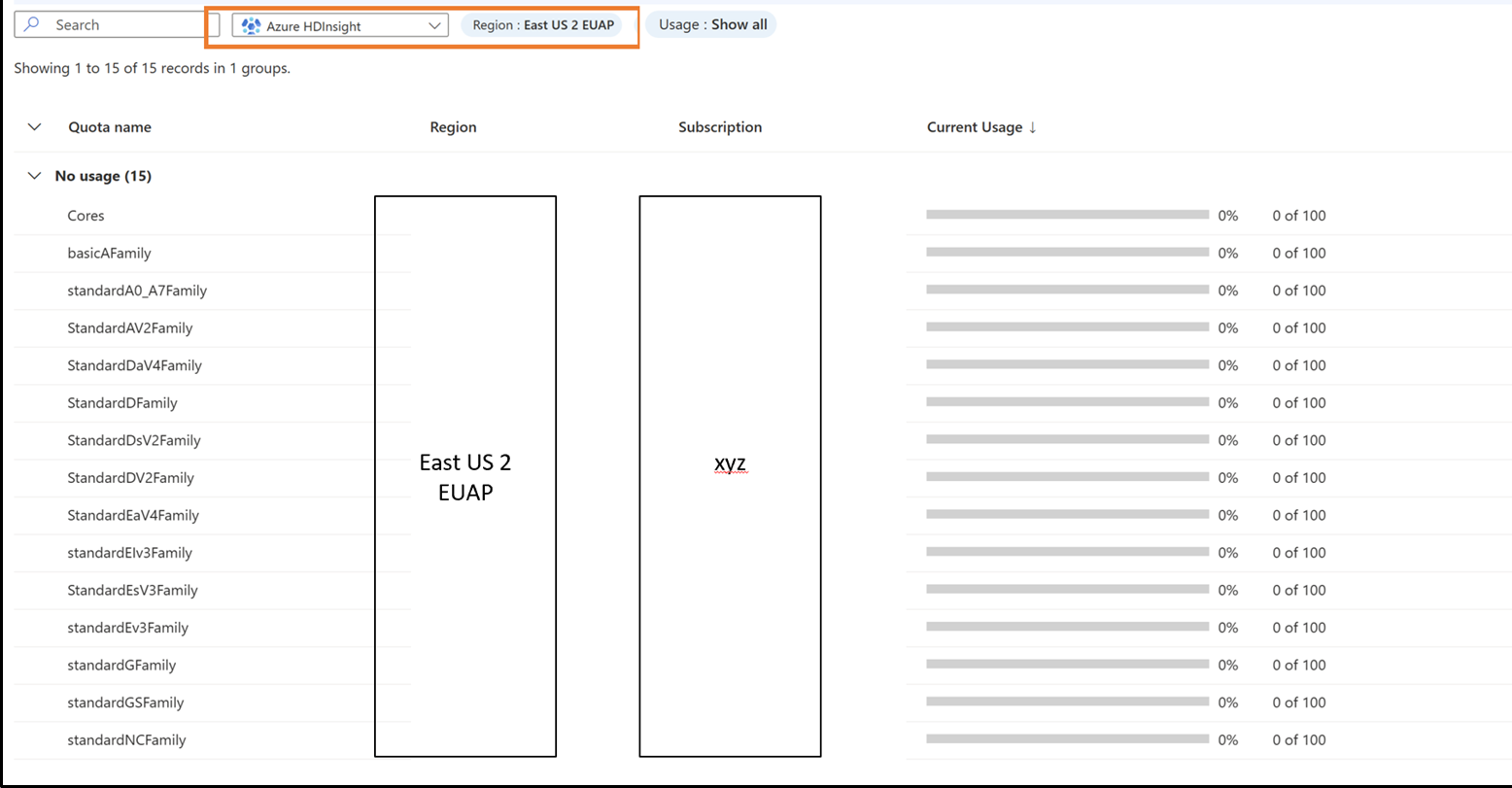
Anfordern neuer Kontingente pro VM-Familie und Region
- Klicken Sie auf die Zeile, für die Sie die Kontingentdetails anzeigen möchten.
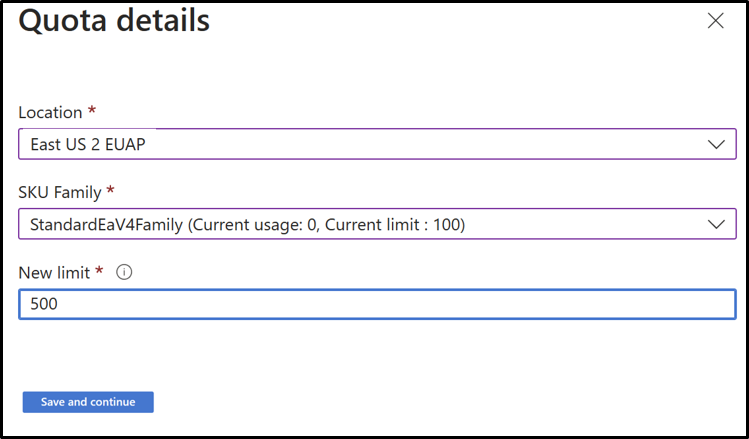




Quoten
Weitere Informationen zum Verwalten von Abonnementkontingenten finden Sie unter Anfordern von Kontingenterhöhungen.
Nächste Schritte
- Einrichten von Clustern in HDInsight mit Apache Hadoop, Spark, Kafka und mehr: Erfahren Sie, wie Sie Cluster in HDInsight einrichten und konfigurieren.
- Überwachen der Clusterleistung: Erfahren Sie mehr über wichtige Szenarien, die Sie auf Ihrem HDInsight-Cluster überwachen können, die sich auf die Kapazität Ihres Clusters auswirken können.