Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Wichtig
Der Standardmetastore bietet eine Azure SQL-Datenbank-Instanz im Basic-Tarif mit nur maximal 5 DTU und 2 GB (KEIN UPGRADE MÖGLICH)! Verwenden Sie dies nur für QA- und Testzwecke. Bei großen Workloads bzw. Produktionsworkloads empfiehlt sich die Migration zu einem externen Metastore!
HDInsight ermöglicht Ihnen das Steuern Ihrer Daten und Metadaten mit externen Datenspeichern. Dieses Feature ist für Apache Hive-Metastore, Apache Oozie-Metastore und Apache Ambari-Datenbank verfügbar.
Der Apache Hive-Metastore in HDInsight ist ein wesentlicher Bestandteil der Apache Hadoop-Architektur. Ein Metastore ist das zentrale Schemarepository. Der Metastore wird von anderen Tools für den Zugriff auf Big Data wie Apache Spark, Interactive Query (LLAP), Presto oder Apache Pig verwendet. HDInsight verwendet eine Azure SQL-Datenbank als Hive-Metastore.
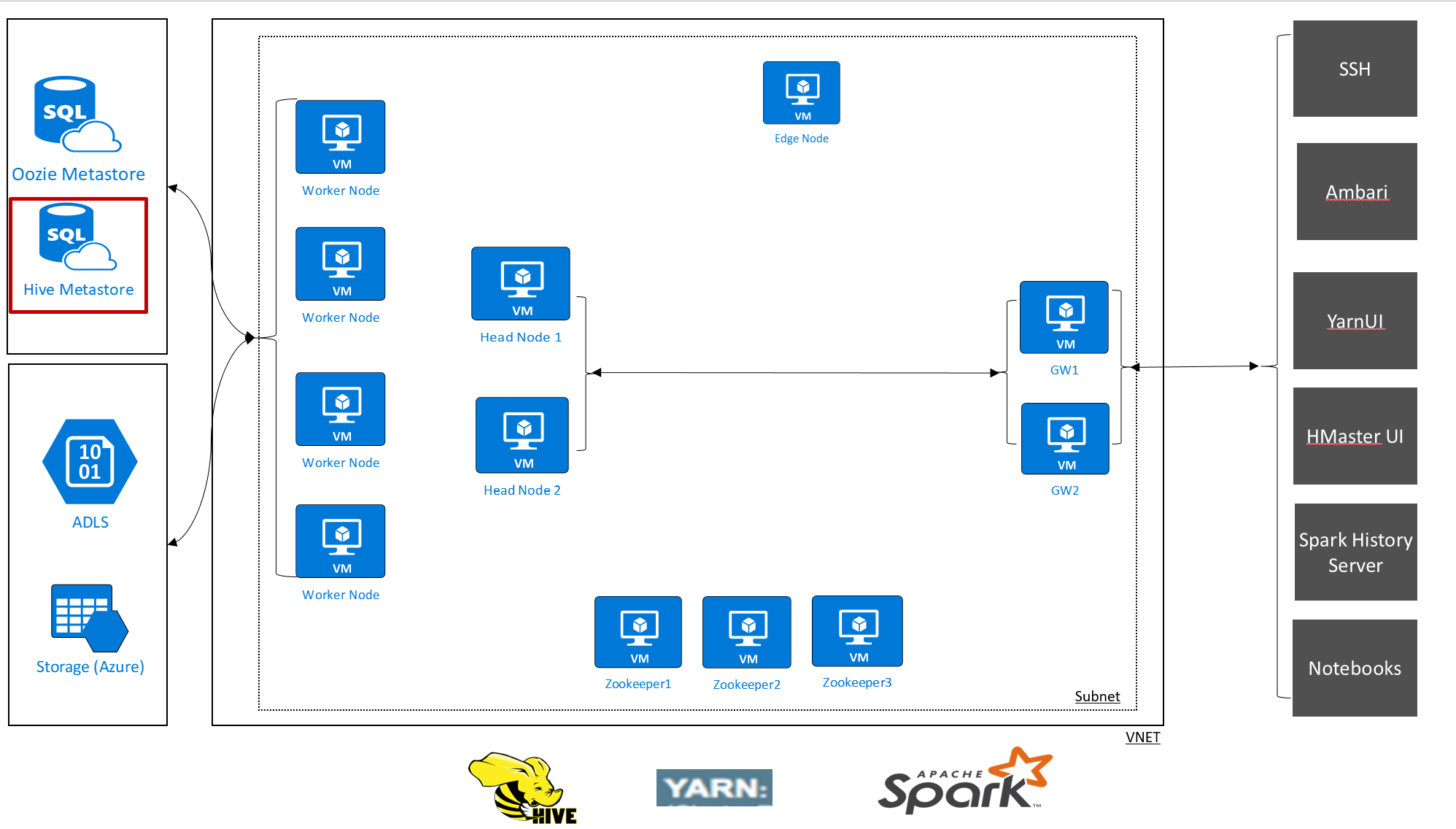
Sie können einen Metastore für Ihre HDInsight-Cluster auf zwei Arten einrichten:
Standardmetastore
HDInsight erstellt standardmäßig einen Metastore für jeden Clustertyp. Sie können stattdessen einen benutzerdefinierten Metastore angeben. Beim Standardmetastore sind folgende Aspekte zu berücksichtigen:
Begrenzte Ressourcen. Siehe Hinweis oben auf der Seite.
Keine Mehrkosten. HDInsight erstellt für jeden Clustertyp einen Metastore ohne Mehrkosten.
Der Standardmetastore ist Teil des Clusterlebenszyklus. Wenn Sie einen Cluster löschen, werden der entsprechende Metastore und die jeweiligen Metadaten ebenfalls gelöscht.
Der Standardmetastore wird nur für einfache Workloads empfohlen. Workloads, für die weder mehrere Cluster noch eine Beibehaltung von Metadaten über den Lebenszyklus des Clusters hinaus erforderlich sind.
Der Standardmetastore kann nicht für andere Cluster freigegeben werden.
Benutzerdefinierter Metastore
HDInsight unterstützt auch benutzerdefinierte Metastores, der für Produktionscluster empfohlen werden:
Sie geben Ihre eigene Azure SQL-Datenbank-Instanz als Metastore an.
Der Lebenszyklus des Metastore ist nicht an den Lebenszyklus eines Clusters gebunden, sodass Sie Cluster ohne Verlust von Metadaten erstellen und löschen können. Metadaten, wie z. B. Ihre Hive-Schemas, bleiben auch nach dem Löschen und erneuten Erstellen des HDInsight-Clusters erhalten.
Ein benutzerdefinierter Metastore ermöglicht das Anfügen mehrerer Cluster und Clustertypen an diesen Metastore. Beispielsweise kann ein einzelner Metastore für Interactive Query-, Hive- und Spark-Cluster in HDInsight freigegeben werden.
Die Kosten für einen Metastore (Azure SQL-Datenbank) richten sich nach der von Ihnen ausgewählten Leistungsstufe.
Sie können den Metastore nach Bedarf hochskalieren.
Cluster und externer Metastore müssen in der gleichen Region gehostet werden.
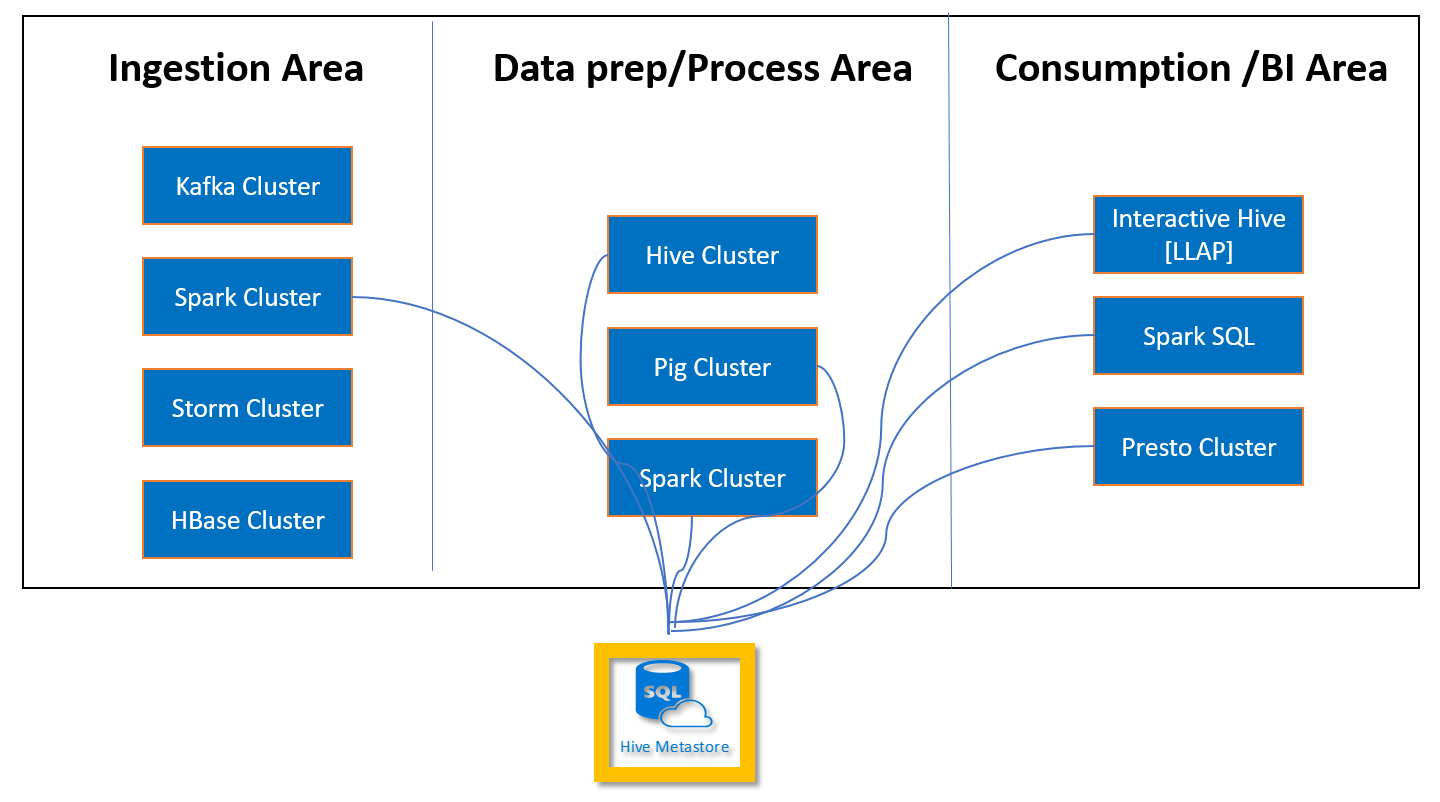
Erstellen und Konfigurieren der Azure SQL-Datenbank für den benutzerdefinierten Metastore
Vor dem Einrichten eines benutzerdefinierten Hive-Metastores für einen HDInsight-Cluster müssen Sie eine Azure SQL-Datenbank erstellen, oder es muss bereits eine Azure SQL-Datenbank vorhanden sein. Weitere Informationen finden Sie unter Quickstart: Erstellen einer Einzeldatenbank in Azure SQL-Datenbank.
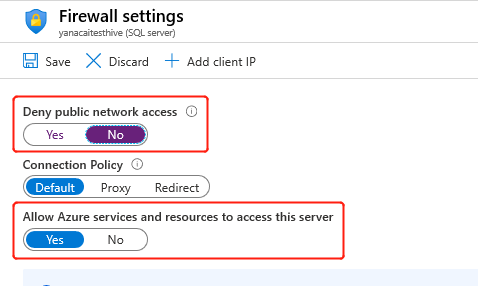
Wenn Sie den Cluster erstellen, muss der HDInsight-Dienst eine Verbindung mit dem externen Metastore herstellen und Ihre Anmeldeinformationen überprüfen. Konfigurieren Sie die Regeln der Azure SQL-Datenbank-Firewall, um Azure-Diensten und -Ressourcen den Zugriff auf den Server zu ermöglichen. Aktivieren Sie diese Option im Azure-Portal, indem Sie Serverfirewall festlegen auswählen. Wählen Sie dann unterhalb von Zugriff auf öffentliches Netzwerk verweigernNein und unterhalb von Azure-Diensten Zugriff auf den Server erlauben für Azure SQL-Datenbank Ja aus. Weitere Informationen finden Sie unter IP-Firewallregeln für Azure SQL-Datenbank und Azure SQL Data Warehouse.
Private Endpunkte für SQL-Speicher sind nur in Clustern unterstützt, die mit ResourceProviderConnection vom Typ outbound erstellt wurden. Weitere Informationen finden Sie in dieser Dokumentation.

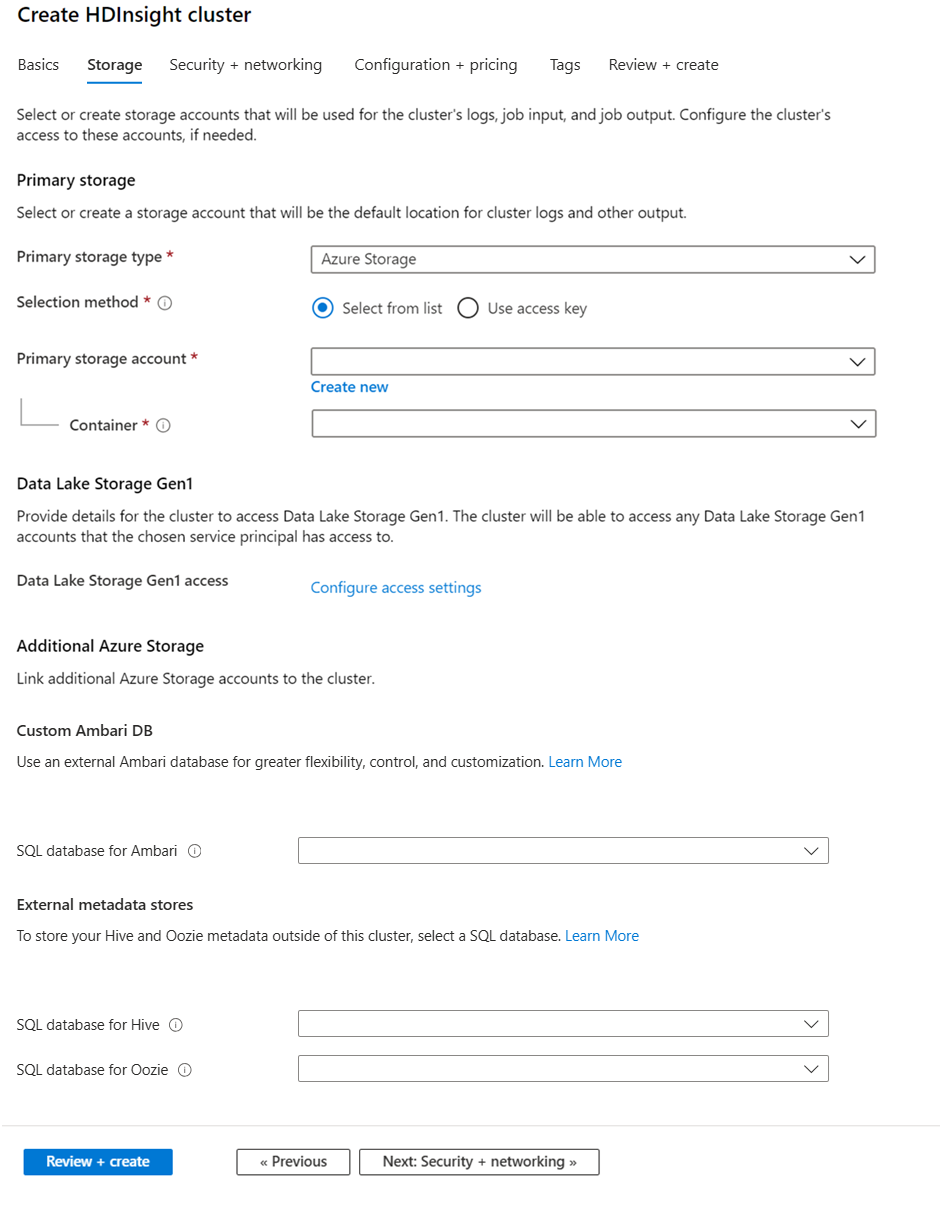
Auswählen eines benutzerdefinierten Metastore während der Clustererstellung
Sie können jederzeit einen Verweis des Clusters auf eine zuvor erstellte Azure SQL-Datenbank festlegen. Bei der Clustererstellung über das Portal wird die Option über Speicher > Metastore-Einstellungen angegeben.
Richtlinien für Apache Hive-Metastore
Hinweis
Verwenden Sie wann immer möglich einen benutzerdefinierten Metastore, um das Trennen von Computeressourcen (Ihre ausgeführten Cluster) und Metadaten (im Metastore gespeichert) zu erleichtern. Beginnen Sie mit dem S2-Tarif, der 50 DTUs und 250 GB Speicher bietet. Wenn Sie einen Engpass feststellen, können Sie die Datenbank zentral hochskalieren.
Wenn Sie mehreren HDInsight-Clustern Zugriff auf separate Daten gewähren möchten, verwenden Sie für den Metastore auf jedem Cluster eine eigene Datenbank. Wenn Sie einen Metastore für mehrere HDInsight-Cluster freigeben, bedeutet dies, dass die Cluster dieselben Metadaten und zugrunde liegenden Benutzerdatendateien verwenden.
Sichern Sie Ihren benutzerdefinierten Metastore regelmäßig. Die Azure SQL-Datenbank generiert Sicherungen automatisch, der Aufbewahrungszeitraum der Sicherungen variiert jedoch. Weitere Informationen finden Sie unter Informationen zu automatischen Sicherungen von SQL-Datenbank.
Platzieren Sie den Metastore und den HDInsight-Cluster in derselben Region. Diese Konfiguration bietet die höchste Leistung und die niedrigsten Gebühren für ausgehenden Netzwerkdatenverkehr.
Überwachen Sie den Metastore in Hinblick auf Leistung und Verfügbarkeit. Verwenden Sie dazu Überwachungstools für die Azure SQL-Datenbank, z. B. Azure Monitor-Protokolle.
Wenn eine neue, höhere Version von Azure HDInsight anhand einer vorhandenen benutzerdefinierten Metastoredatenbank erstellt wird, aktualisiert das System das Metastoreschema. Das Upgrade kann nicht rückgängig gemacht werden, ohne die Datenbank aus einer Sicherung wiederherzustellen.
Falls Sie einen Metastore für mehrere Cluster freigeben, achten Sie darauf, dass alle Cluster die gleiche HDInsight-Version haben. Verschiedene Hive-Versionen verwenden unterschiedliche Schemas der Metastoredatenbank. So können Sie beispielsweise einen Metastore nicht für Hive 2.1- und Hive 3.1-Cluster freigeben.
In HDInsight 4.0 verwenden Spark und Hive unabhängige Kataloge für den Zugriff auf SparkSQL- oder Hive-Tabellen. Eine von Spark erstellte Tabelle befindet sich im Spark-Katalog. Eine von Hive erstellte Tabelle befindet sich im Hive-Katalog. Dies unterscheidet sich von HDInsight 3.6, wo in Hive und Spark der gleiche Katalog verwendet wurde. Die Integration von Hive und Spark in HDInsight 4.0 basiert auf Hive Warehouse Connector (HWC). HWC funktioniert als Brücke zwischen Spark und Hive. Informationen zu Hive Warehouse Connector.
Wenn Sie in HDInsight 4.0 den Metastore für Hive und Spark freigeben möchten, können Sie in Ihrem Spark-Cluster den Wert für die Eigenschaft „metastore.catalog.default“ in „hive“ ändern. Diese Eigenschaft finden Sie in Ambari unter „Advanced spark2-hive-site-override“. Es ist wichtig zu verstehen, dass die Freigabe des Metastores nur für externe Hive-Tabellen funktioniert. Sie funktioniert nicht bei internen/verwalteten Hive-Tabellen oder ACID-Tabellen.
Hinweis
Sie können die Option „Verwaltete Identität“ zur SQL-Datenbank-Authentifizierung für Hive verwenden. Weitere Informationen finden Sie unter Verwenden der Option „Verwaltete Identität“ für die SQL-Datenbank-Authentifizierung in Azure HDInsight.
Aktualisieren des benutzerdefinierten Hive-Metastore-Kennworts
Bei Verwendung einer benutzerdefinierten Hive-Metastore-Datenbank haben Sie die Möglichkeit, das SQL-Datenbankkennwort zu ändern. Wenn Sie das Kennwort für den benutzerdefinierten Metastore ändern, funktionieren die Hive-Dienste erst, wenn Sie das Kennwort im HDInsight-Cluster aktualisiert haben.
So aktualisieren Sie das Hive-Metastore-Kennwort
- Öffnen Sie die Ambari-Benutzeroberfläche.
- Klicken Sie auf Dienste --> Hive --> Konfigurationen --> Datenbank.
- Aktualisieren Sie die Felder Datenbankkennwort auf das neue SQL-Datenbankkennwort.
- Klicken Sie auf die Schaltfläche Verbindung testen, um sicherzustellen, dass das neue Kennwort funktioniert.
- Klicken Sie auf die Schaltfläche Save .
- Befolgen Sie die Ambari-Eingabeaufforderungen, um die Konfiguration zu speichern und die erforderlichen Dienste neu zu starten.
Apache Oozie-Metastore
Apache Oozie ist ein Koordinationssystem für Workflows zur Verwaltung von Hadoop-Aufträgen. Oozie unterstützt Hadoop-Aufträge für Apache MapReduce, Pig, Hive und andere. Oozie verwendet einen Metastore zum Speichern von Details zu Workflows. Zur Leistungssteigerung bei Verwendung von Oozie können Sie eine Azure SQL-Datenbank als benutzerdefinierten Metastore verwenden. Der Metastore bietet Zugriff auf Oozie-Auftragsdaten, nachdem Sie den Cluster gelöscht haben.
Anleitungen zum Erstellen eines Oozie-Metastore mit einer Azure SQL-Datenbank finden Sie unter Verwenden von Apache Oozie für Workflows.
Aktualisieren des benutzerdefinierten Oozie-Metastore-Kennworts
Bei Verwendung einer benutzerdefinierten Oozie-Metastore-Datenbank haben Sie die Möglichkeit, das SQL-Datenbankkennwort zu ändern. Wenn Sie das Kennwort für den benutzerdefinierten Metastore ändern, funktionieren die Oozie-Dienste erst, wenn Sie das Kennwort im HDInsight-Cluster aktualisiert haben.
So aktualisieren Sie das Oozie-Metastore-Kennwort
- Öffnen Sie die Ambari-Benutzeroberfläche.
- Klicken Sie auf Dienste --> Oozie --> Konfigurationen --> Datenbank.
- Aktualisieren Sie die Felder Datenbankkennwort auf das neue SQL-Datenbankkennwort.
- Klicken Sie auf die Schaltfläche Verbindung testen, um sicherzustellen, dass das neue Kennwort funktioniert.
- Klicken Sie auf die Schaltfläche Save .
- Befolgen Sie die Ambari-Eingabeaufforderungen, um die Konfiguration zu speichern und die erforderlichen Dienste neu zu starten.
Hinweis
Sie können die Option „Verwaltete Identität“ zur SQL-Datenbank-Authentifizierung für Oozie verwenden. Weitere Informationen finden Sie unter Verwenden der Option „Verwaltete Identität“ für die SQL-Datenbank-Authentifizierung in Azure HDInsight.
Benutzerdefinierte Ambari-Datenbank
Informationen zum Verwenden Ihrer eigenen externen Datenbank mit Apache Ambari in HDInsight finden Sie unter Benutzerdefinierte Apache Ambari-Datenbank.
Hinweis
Sie können die Option „Verwaltete Identität“ zur SQL-Datenbank-Authentifizierung für Ambari verwenden. Weitere Informationen finden Sie unter Verwenden der Option „Verwaltete Identität“ für die SQL-Datenbank-Authentifizierung in Azure HDInsight.