Übersicht über die automatische Clusterskalierung in Azure Kubernetes Service (AKS)
Um die Anwendungsanforderungen in Azure Kubernetes Service (AKS) zu erfüllen, müssen Sie möglicherweise die Anzahl von Knoten anpassen, die Ihre Workloads ausführen. Die Komponente für die automatische Clusterskalierung überwacht auf Pods in Ihrem Cluster, die aufgrund von Ressourceneinschränkungen nicht geplant werden können. Wenn die automatische Clusterskalierung nicht geplante Pods erkennt, skaliert sie die Anzahl der Knoten im Knotenpool hoch, um den Anwendungsbedarf zu erfüllen. Außerdem werden regelmäßig Knoten überprüft, für die keine geplanten Pods vorhanden sind. Die Anzahl der Knoten wird nach Bedarf nach unten skaliert.
In diesem Artikel erfahren Sie, wie die automatische Clusterskalierung in AKS funktioniert. Außerdem finden Sie hier Anleitungen, Best Practices und Überlegungen für die Konfiguration der automatischen Clusterskalierung für Ihre AKS-Workloads. Wenn Sie die automatische Clusterskalierung für Ihre AKS-Workloads aktivieren, deaktivieren oder aktualisieren möchten, finden Sie unter Verwenden der automatischen Clusterskalierung in AKS weitere Informationen.
Grundlegendes zur Autoskalierung für Cluster
Cluster benötigen oft eine Möglichkeit zur automatischen Skalierung, um sich an sich ändernde Anwendungsanforderungen anzupassen, z. B. zwischen Arbeitstagen und Abenden oder an einem Wochenende. AKS-Cluster können auf folgende Weise skaliert werden:
- Die Autoskalierung für Cluster überprüft regelmäßig auf Pods, die aufgrund von Ressourceneinschränkungen nicht auf Knoten geplant werden können. Der Cluster erhöht in diesem Fall automatisch die Anzahl von Knoten. Bei Verwendung der Autoskalierung für Cluster ist die manuelle Skalierung deaktiviert. Weitere Informationen finden Sie unter Wie funktioniert das Hochskalieren?
- Bei der horizontalen automatischen Podskalierung überwacht der Metrikserver in einem Kubernetes-Cluster die Ressourcenanforderungen der Pods. Wenn eine Anwendung mehr Ressourcen benötigt, wird die Anzahl von Pods automatisch erhöht, um den Bedarf zu decken.
- Die vertikale automatische Podskalierung legt basierend auf der vergangenen Nutzung automatisch Ressourcenanforderungen und Grenzwerte für Container pro Workload fest, um sicherzustellen, dass Pods auf Knoten geplant werden, die über die erforderlichen CPU- und Arbeitsspeicherressourcen verfügen.
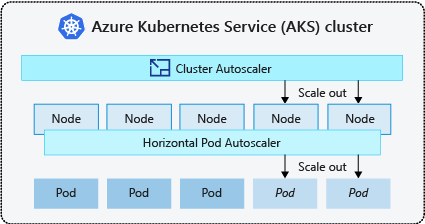
Es ist üblich, die automatische Clusterskalierung für Knoten zu aktivieren, und entweder die vertikale automatische Podskalierung oder die horizontale automatische Podskalierung für Pods. Wenn Sie die automatische Clusterskalierung aktivieren, werden die angegebenen Skalierungsregeln angewendet, wenn die Größe des Knotenpools kleiner als die minimale oder größer als die maximale Knotenanzahl ist. Die automatische Clusterskalierung wartet, bis ein neuer Knoten im Knotenpool benötigt wird oder bis ein Knoten sicher aus dem aktuellen Knotenpool gelöscht werden kann. Weitere Informationen finden Sie unter Wie funktioniert Herunterskalieren?
Bewährte Methoden und Überlegungen
- Bei der Implementierung von Verfügbarkeitszonen mit der automatischen Clusterskalierung empfehlen wir die Verwendung eines einzelnen Knotenpools für jede Zone. Sie können den
--balance-similar-node-groups-Parameter aufTruefestlegen, um für Ihre Workloads beim Hochskalieren eine ausgeglichene Verteilung der Knoten für alle Zonen aufrechtzuerhalten. Andernfalls kann beim Herunterskalieren die Ausgeglichenheit der Knoten für alle Zonen gestört werden. - Für Cluster mit mehr als 400 Knoten empfehlen wir die Verwendung von Azure CNI oder Azure CNI Overlay.
- Wenn Sie Workloads sowohl auf Spot- als auch auf Fixed-Knotenpools effektiv ausführen möchten, sollten Sie Prioritätserweiterungen verwenden. Hierdurch können Sie Pods basierend auf der Priorität des Knotenpools planen.
- Gehen Sie bei der Zuweisung von CPU/Arbeitsspeicheranforderungen auf Pods vorsichtig vor. Die automatische Clusterskalierung wird basierend auf ausstehenden Pods und nicht basierend auf einer hohen CPU-/Arbeitsspeicherauslastung auf Knoten hochskaliert.
- Für Cluster, die gleichzeitig sowohl zeitintensive Workloads wie Web-Apps als auch kurze Auftragsworkloads mit Auslastungsspitzen hosten, empfehlen wir, diese in unterschiedliche Knotenpools mit Affinitätsregeln/Erweiterungen zu trennen oder das PodDisruptionBudget-Objekt zu verwenden, um ein unnötiges Entladen oder Herunterskalieren der Knoten zu vermeiden. Wenn Sie die Anmerkung cluster-autoscaler.kubernetes.io/safe-to-evict: "false" in der Podspezifikation angeben, wird zudem verhindert, dass die Pods entfernt werden. Verwenden Sie diese Anmerkung mit Vorsicht, da bei der automatischen Clusterskalierung Probleme auftreten können, wenn ein Knoten mit einem ausgeführten Pod, der diese Anmerkung enthält, ausgeglichen wird.
- In einem automatisch skalierten Knotenpool können Sie Knoten herunterskalieren, indem Sie Workloads entfernen, anstatt die Knotenanzahl manuell zu reduzieren. Dies kann problematisch sein, wenn der Knotenpool bereits seine maximale Kapazität erreicht hat oder wenn auf den Knoten aktive Workloads ausgeführt werden. Dies kann möglicherweise zu unerwartetem Verhalten durch die automatische Clusterskalierung führen.
- Knoten werden nicht hochskaliert, wenn Pods einen PriorityClass-Wert unter -10 aufweisen. Die Priorität -10 ist für eine Überbereitstellung von Pods reserviert. Weitere Informationen finden Sie unter Verwenden der automatischen Clusterskalierung mit Podpriorität und vorzeitiger Entfernung.
- Kombinieren Sie keine anderen Mechanismen für eine automatische Knotenskalierung wie VMSS-Autoskalierungen mit der automatischen Clusterskalierung.
- Die automatische Clusterskalierung kann Knoten möglicherweise nicht herunterskalieren, wenn ein Verschieben der Pods nicht möglich ist. Dies kann in folgenden Situationen der Fall sein:
- Ein Pod wird direkt erstellt und nicht von einem Controllerobjekt wie z. B. einer Bereitstellung oder einem ReplicaSet unterstützt.
- Ein Budget für die Unterbrechung von Pods (Pod Disruption Budget, PDB) ist zu restriktiv und lässt nicht zu, dass die Anzahl der Pods unter einen bestimmten Schwellenwert fällt.
- Ein Pod verwendet Knotenselektoren oder Anti-Affinität, die nicht berücksichtigt werden können, wenn der Pod auf einem anderen Knoten geplant wird. Weitere Informationen finden Sie unter Welche Podtypen können das Entfernen eines Knotens durch die automatische Clusterskalierung verhindern?.
Wichtig
Nehmen Sie keine Änderungen an einzelnen Knoten innerhalb der automatisch skalierten Knotenpools vor. Alle Knoten in einer Knotengruppe müssen über einheitliche Kapazitäten, Bezeichnungen, Taints und Systempods verfügen, die auf diesen Knoten ausgeführt werden.
- Die automatische Clusterskalierung ist unabhängig von der Podplanung nicht für das Erzwingen einer „maximalen Knotenanzahl“ in einem Clusterknotenpool verantwortlich. Wenn ein automatischer Skalierungsakteur (kein Cluster) die Anzahl der Knoten im Knotenpool auf eine Zahl festlegt, die über das von der automatischen Clusterskalierung konfigurierte Maximum hinausgeht, entfernt diese die Knoten nicht automatisch. Das Verhalten des Herunterskalierens der automatischen Clusterskalierung bleibt auf das Entfernen von Knoten festgelegt, die keine geplanten Pods aufweisen. Der einzige Zweck der Konfiguration der maximalen Knotenanzahl durch die automatische Clusterskalierung besteht darin, eine Obergrenze für Hochskalierungsvorgänge zu erzwingen. Sie hat keine Auswirkungen auf das Herunterskalieren.
Profil für die automatische Clusterskalierung
Das Profil für die automatische Clusterskalierung enthält verschiedene Parameter, die das Verhalten der automatischen Clusterskalierung steuern. Sie können das Profil für die automatische Clusterskalierung konfigurieren, wenn Sie einen neuen Cluster erstellen oder einen vorhandenen Cluster aktualisieren.
Optimieren des Profils für die automatische Clusterskalierung
Sie sollten die Profileinstellungen für die automatische Clusterskalierung Ihren spezifischen Workloadszenarios entsprechend optimieren und gleichzeitig Kompromisse zwischen Leistung und Kosten berücksichtigen. Dieser Abschnitt enthält Beispiele, in denen diese Kompromisse erläutert werden.
Beachten Sie, dass die Profileinstellungen für die automatische Clusterskalierung für den gesamten Cluster gelten und auf alle automatisch skalierten Knotenpools angewendet werden. Sämtliche Skalierungen, die in einem Knotenpool ausgeführt werden, können sich auf das Verhalten der automatischen Skalierung anderer Knotenpools auswirken. Dies kann zu unerwarteten Ergebnissen führen. Stellen Sie sicher, dass Sie konsistente und synchronisierte Profilkonfigurationen für alle relevanten Knotenpools anwenden, um die gewünschten Ergebnisse zu erhalten.
Beispiel 1: Optimieren für Leistung
Bei Clustern, die umfangreiche Workloads und Workloads mit Auslastungsspitzen verarbeiten, die sich primär auf die Leistung konzentrieren, empfehlen wir, die Einstellung für scan-interval zu erhöhen und die für scale-down-utilization-threshold zu verringern. Mit diesen Einstellungen können mehrere Skalierungsvorgänge in einem einzelnen Aufruf gestapelt werden, wodurch die Skalierungszeit und die Auslastung von Computekontingenten für Lese-/Schreibvorgänge optimiert werden. Dies hilft außerdem dabei, das Risiko eines schnellen Herunterskalierens auf nicht ausgelasteten Knoten zu verringern, wodurch die Effizienz der Podplanung verbessert wird. Erhöhen Sie ebenfalls die Werte für ok-total-unready-count und max-total-unready-percentage.
Bei Clustern mit DaemonSet-Pods empfehlen wir, ignore-daemonsets-utilization auf true festzulegen. Hierdurch werden die Knotenauslastung durch DaemonSet-Pods effektiv ignoriert und unnötige Herunterskalierungen minimiert. Weitere Informationen finden Sie unter Profil für Workloads mit Auslastungsspitzen.
Beispiel 2: Optimieren für Kosten
Wenn Sie ein kostenoptimiertes Profil möchten, empfehlen wir, die folgenden Parameterkonfigurationen festzulegen:
- Reduzieren Sie
scale-down-unneeded-time. Dies ist die Dauer, wie lange ein Knoten nicht benötigt werden sollte, bevor er für ein Herunterskalieren in Frage kommt. - Reduzieren Sie
scale-down-delay-after-add. Dies ist die Dauer, die nach dem Hinzufügen eines Knotens gewartet werden soll, bevor er für ein Herunterskalieren in Frage kommt. - Erhöhen Sie
scale-down-utilization-threshold. Dies ist der Auslastungsschwellenwert für das Entfernen von Knoten. - Erhöhen Sie
max-empty-bulk-delete. Dies ist die maximale Anzahl von Knoten, die in einem einzelnen Aufruf gelöscht werden können. - Legen Sie
skip-nodes-with-local-storageauf „false“ fest. - Erhöhen Sie
ok-total-unready-countundmax-total-unready-percentage.
Häufige Probleme und Empfehlungen für die Entschärfung
Sie können Skalierungsfehler und Ereignisse für nicht ausgelöste Hochskalierungen über die CLI oder das Portal anzeigen.
Nicht ausgelöste Hochskalierungen
| Häufige Ursachen | Empfehlungen für die Entschärfung |
|---|---|
| Konflikte mit der PersistentVolume-Knotenaffinität, die auftreten können, wenn die automatische Clusterskalierung mit mehreren Verfügbarkeitszonen verwendet wird oder wenn sich die Zone eines Pods oder eines persistenten Volumes von der Zone des Knotens unterscheidet. | Verwenden Sie einen Knotenpool pro Verfügbarkeitszone, und aktivieren Sie --balance-similar-node-groups. Sie können in der Podspezifikation auch das Feld „volumeBindingMode“ auf „WaitForFirstConsumer“ festlegen, um zu verhindern, dass das Volume an einen Knoten gebunden wird, bis ein Pod mit dem Volume erstellt wird. |
| Taints- und Toleranzen/Konflikte mit der Knotenaffinität | Bewerten Sie die Taints, die Ihren Knoten zugewiesen sind, und überprüfen Sie die in Ihren Pods definierten Toleranzen. Nehmen Sie bei Bedarf Anpassungen an den Taints und Toleranzen vor, um sicherzustellen, dass die Pods auf den Knoten effizient geplant werden können. |
Fehler beim Hochskalieren
| Häufige Ursachen | Empfehlungen für die Entschärfung |
|---|---|
| Ausschöpfung der IP-Adressen im Subnetz | Fügen Sie ein weiteres Subnetz im selben virtuellen Netzwerk hinzu, und fügen Sie dem neuen Subnetz einen weiteren Knotenpool hinzu. |
| Ausschöpfung des Kernkontingents | Das genehmigte Kernkontingent wurde ausgeschöpft. Fordern Sie eine Kontingenterhöhung an. Die automatische Clusterskalierung wechselt innerhalb der angegebenen Knotengruppe in einen exponentiellen Backoffstatus, wenn mehrere Hochskalierungsversuche fehlgeschlagen sind. |
| Maximale Größe des Knotenpools | Erhöhen Sie die maximale Anzahl an Knoten im Knotenpool, oder erstellen Sie einen neuen Knotenpool. |
| Anforderungen/Aufrufe überschreiten die Quotengrenze | Weitere Informationen finden Sie unter Fehler „429 – Zu viele Anforderungen“. |
Fehler beim Herunterskalieren
| Häufige Ursachen | Empfehlungen für die Entschärfung |
|---|---|
| Pod verhindert Entladen von Knoten/Pod kann nicht entfernt werden | • Sehen Sie sich an, welche Podtypen ein Herunterskalieren verhindern können. • Legen Sie für Pods, die den lokalen Speicher verwenden, z. B. hostPath und emptyDir, das Profilflag skip-nodes-with-local-storage für die automatische Clusterskalierung auf false fest. • Legen Sie in der Podspezifikation die Anmerkung cluster-autoscaler.kubernetes.io/safe-to-evict auf true fest. • Überprüfen Sie Ihr PDB, da es möglicherweise restriktiv ist. |
| Minimale Größe des Knotenpools | Verringern Sie die minimale Größe des Knotenpools. |
| Anforderungen/Aufrufe überschreiten die Quotengrenze | Weitere Informationen finden Sie unter Fehler „429 – Zu viele Anforderungen“. |
| Schreibvorgänge gesperrt | Nehmen Sie keine Änderungen an der vollständig verwalteten AKS-Ressourcengruppe vor (weitere Informationen finden Sie unter Unterstützungsrichtlinien für Azure Kubernetes Service). Entfernen oder setzen Sie alle Ressourcensperren zurück, die Sie zuvor auf die Ressourcengruppe angewendet haben. |
Andere Probleme
| Häufige Ursachen | Empfehlungen für die Entschärfung |
|---|---|
| PriorityConfigMapNotMatchedGroup | Stellen Sie sicher, dass Sie alle Knotengruppen, für die eine automatische Skalierung erforderlich ist, der Konfigurationsdatei der Erweiterung hinzufügen. |
Knotenpool in Backoff
Der Status „Knotenpool in Backoff“ wurde in Version 0.6.2 eingeführt und bewirkt, dass die automatische Clusterskalierung nach einem Skalierungsfehler eines Knotenpools ausgesetzt wird.
Je nachdem, wie lange die Skalierungsvorgänge fehlschlagen, kann es bis zu 30 Minuten dauern, bis ein weiterer Versuch unternommen wird. Sie können den Backoffstatus des Knotenpools zurücksetzen, indem Sie die automatische Skalierung deaktivieren und dann erneut aktivieren.

Azure Kubernetes Service