Problembehandlung bei der Sammlung von Prometheus-Metriken in Azure Monitor
Führen Sie die Schritte in diesem Artikel aus, um zu ermitteln, warum Prometheus-Metriken in Azure Monitor nicht wie erwartet gesammelt werden.
Der Replikat-Pod erfasst Metriken aus kube-state-metrics, benutzerdefinierte Scrape-Ziele in der ama-metrics-prometheus-config-Configmap und benutzerdefinierte Scrape-Ziele, die in den benutzerdefinierten Ressourcen definiert sind. DaemonSet-Pods lesen Metriken von den folgenden Zielen auf ihrem jeweiligen Knoten aus: kubelet, cAdvisor, node-exporterund von benutzerdefinierten Auslesezielen in der ama-metrics-prometheus-config-node-Configmap. Der Pod, für den Sie die Protokolle und die Prometheus-Benutzeroberfläche anzeigen möchten, hängt davon ab, welches Ausleseziel Sie untersuchen.
Problembehandlung mithilfe von PowerShell-Skripts
Wenn beim Versuch, die Überwachung für Ihren AKS-Cluster zu aktivieren, ein Fehler auftritt, befolgen Sie diese Anweisungen, um das Skript zur Problembehandlung auszuführen. Dieses Skript ist für eine grundlegende Diagnose jeglicher Konfigurationsprobleme in Ihrem Cluster konzipiert. Sie können die generierten Dateien beim Erstellen einer Supportanfrage anfügen, um die Lösungsfindung für Ihren Supportfall zu beschleunigen.
Drosselung von Metriken
Der verwaltete Azure Monitor-Dienst für Prometheus verfügt über Standardgrenzwerte und Kontingente für die Erfassung. Wenn Sie das Erfassungslimit erreichen, kann eine Drosselung auftreten. Sie können eine Erhöhung dieser Grenzwerte anfordern. Informationen zu den Limits von Prometheus-Metriken finden Sie unter Azure Monitor-Dienstgrenzwerte.
Öffnen Sie den Azure Monitor-Arbeitsbereich im Azure-Portal. Wechseln Sie zu Metrics, und wählen Sie die Metriken Active Time Series % Utilization und Events Per Minute Received % Utilization aus. Vergewissern Sie sich, dass beide unter 100 % liegen.
Weitere Informationen zum Überwachen Ihrer Erfassungsmetriken und Ausgeben von Warnungen für diese finden Sie unter Überwachen der Erfassung von Metriken im Azure Monitor-Arbeitsbereich.
Zeitweilige Lücken in der Metrikdatensammlung
Bei Knotenaktualisierungen kann eine Lücke von 1 bis 2 Minuten in den Metrikdaten für Metriken auftreten, die von unserem Collector auf Clusterebene gesammelt wurden. Die Ursache für die Lücke ist, dass die Ausführung auf einem Knoten erfolgt, der im Rahmen eines normalen Aktualisierungsprozesses aktualisiert wird. Sie betrifft clusterweite Ziele, z. B. kube-state-metrics und benutzerdefinierte Anwendungsziele, die angegeben werden. Sie tritt auf, wenn Ihr Cluster manuell oder per automatischer Aktualisierung aktualisiert wird. Dies ist das erwartete Verhalten, und es tritt aufgrund der Aktualisierung des Knotens auf, auf dem er ausgeführt wird. Keine unserer empfohlenen Warnungsregeln ist von diesem Verhalten betroffen.
Podstatus
Überprüfen Sie den Podstatus mit folgendem Befehl:
kubectl get pods -n kube-system | grep ama-metrics
Wenn der Dienst ordnungsgemäß ausgeführt wird, werden die folgenden Pods im Format ama-metrics-xxxxxxxxxx-xxxxx zurückgegeben:
ama-metrics-operator-targets-*ama-metrics-ksm-*ama-metrics-node-*Pod für jeden Knoten im Cluster.
Jeder Podstatus sollte Running lauten. Außerdem sollte die Anzahl der Neustarts der Anzahl angewendeter ConfigMap-Änderungen entsprechen. Der ama-metrics-operator-targets-*-Pod hat möglicherweise einen zusätzlichen Neustart am Anfang, und dies wird erwartet:

Wenn jeder Podstatus Running lautet, aber mindestens ein Pod neu gestartet wurde, führen Sie den folgenden Befehl aus:
kubectl describe pod <ama-metrics pod name> -n kube-system
- Dieser Befehl gibt den Grund für die Neustarts an. Pod-Neustarts sind zu erwarten, wenn ConfigMap-Änderungen vorgenommen wurden. Wenn der Grund für den Neustart
OOMKilledlautet, kann der Pod die Menge an Metriken nicht bewältigen. Weitere Informationen finden Sie in den Skalierungsempfehlungen für das Metrikvolumen.
Wenn die Pods wie erwartet ausgeführt werden, sollten Sie als Nächstes die Containerprotokolle überprüfen.
Überprüfen auf Neubezeichnungskonfigurationen
Wenn Metriken fehlen, können Sie auch überprüfen, ob Sie Konfigurationen zur Neubezeichnung eingestellt haben. Stellen Sie bei Konfigurationen zur Neubezeichnung sicher, dass die neue Bezeichnung die Ziele nicht herausfiltert, und die konfigurierten Bezeichnungen den Zielen ordnungsgemäß entsprechen. Weitere Informationen finden Sie in der Prometheus-Dokumentation zur Konfiguration zur Neubezeichnung.
Containerprotokolle
Zeigen Sie die Containerprotokolle mit dem folgenden Befehl an:
kubectl logs <ama-metrics pod name> -n kube-system -c prometheus-collector
Beim Start werden alle anfänglichen Fehler in Rot und Warnungen in Gelb ausgegeben. (Zum Anzeigen der farbcodierten Protokolle sind mindestens PowerShell, Version 7, oder eine Linux-Distribution erforderlich.)
- Überprüfen Sie, ob beim Abrufen des Authentifizierungstokens ein Problem vorliegt:
- Die Meldung Keine Konfiguration für die AKS-Ressource vorhanden wird alle 5 Minuten protokolliert.
- Der Pod nimmt alle 15 Minuten einen Neustart vor, allerdings wird dabei der folgende Fehler ausgegeben: Keine Konfiguration für die AKS-Ressource vorhanden.
- Wenn ja, überprüfen Sie, ob die Datensammlungsregel und der Datensammlungsendpunkt in Ihrer Ressourcengruppe vorhanden sind.
- Überprüfen Sie außerdem, ob der Azure Monitor-Arbeitsbereich vorhanden ist.
- Stellen Sie sicher, dass Sie über keinen privaten AKS-Cluster verfügen und nicht mit einem Azure Monitor-Private Link-Bereich für einen anderen Dienst verknüpft sind. Dieses Szenario wird derzeit nicht unterstützt.
Konfigurationsverarbeitung
Zeigen Sie die Containerprotokolle mit dem folgenden Befehl an:
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c config-reader
- Stellen Sie sicher, dass beim Analysieren der Prometheus-Konfiguration keine Fehler auftreten, dass das Zusammenführen mit allen standardmäßigen Auslesezielen aktiviert ist und dass die vollständige Konfiguration überprüft wird.
- Wenn Sie eine benutzerdefinierte Prometheus-Konfiguration einbezogen haben, überprüfen Sie, ob sie in den Protokollen erkannt wird. Gehen Sie wie folgt vor, falls dies nicht so ist:
- Vergewissern Sie sich, dass Ihre Configmap den richtigen Namen hat:
ama-metrics-prometheus-configimkube-system-Namespace. - Vergewissern Sie sich, dass sich ihre Prometheus-Konfiguration in der Konfigurationszuordnung unter einem Abschnitt befindet, der
prometheus-configunterdataheißt, wie hier gezeigt:kind: ConfigMap apiVersion: v1 metadata: name: ama-metrics-prometheus-config namespace: kube-system data: prometheus-config: |- scrape_configs: - job_name: <your scrape job here>
- Vergewissern Sie sich, dass Ihre Configmap den richtigen Namen hat:
- Wenn Sie benutzerdefinierte Ressourcen erstellt haben, sollten während der Erstellung von Pod/Dienst-Monitoren Überprüfungsfehler aufgetreten sein. Wenn die Metriken aus den Zielen immer noch nicht angezeigt werden, stellen Sie sicher, dass in den Protokollen keine Fehler angezeigt werden.
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c targetallocator
- Stellen Sie sicher, dass
MetricsExtensionbei der Authentifizierung beim Azure Monitor-Arbeitsbereich keine Fehler verursacht. - Stellen Sie sicher, dass der
OpenTelemetry collectorbeim Auslesen der Ziele keine Fehler verursacht.
Führen Sie den folgenden Befehl aus:
kubectl logs <ama-metrics pod name> -n kube-system -c addon-token-adapter
- Dieser Befehl zeigt einen Fehler an, wenn bei der Authentifizierung beim Azure Monitor-Arbeitsbereich ein Problem auftritt. Das folgende Beispiel zeigt Protokolle ohne Probleme:
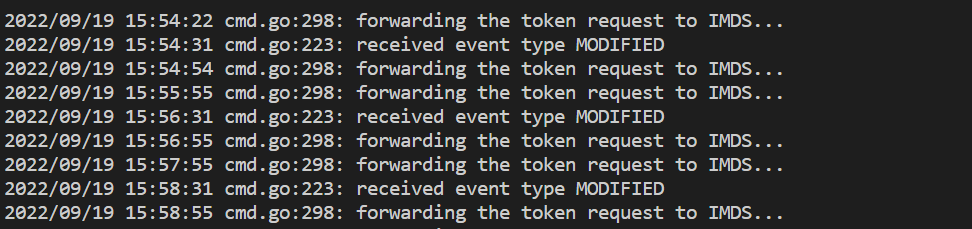

Wenn in den Protokollen keine Fehler auftreten, kann die Prometheus-Schnittstelle zum Debuggen verwendet werden, um die erwartete Konfiguration zu überprüfen und sicherzustellen, dass die Ziele ausgelesen werden.
Prometheus-Schnittstelle
Für jeden ama-metrics-*-Pod steht die Benutzeroberfläche des Prometheus-Agent-Modus an Port 9090 zur Verfügung.
Benutzerdefinierte Konfiguration und benutzerdefinierte Ressourcen-Ziele werden vom ama-metrics-* Pod und den Knotenzielen des ama-metrics-node-*-Pods abgefragt.
Portieren Sie entweder in den Replikatpod oder einen der Daemonset-Pods, um die Konfiguration, die Dienstermittlung und die Zielendpunkte wie hier beschrieben zu überprüfen, um zu verifizieren, ob die benutzerdefinierten Konfigurationen korrekt sind, die beabsichtigten Ziele für jeden Auftrag ermittelt wurden und keine Fehler beim Scraping bestimmter Ziele auftreten.
Führen Sie den Befehl kubectl port-forward <ama-metrics pod> -n kube-system 9090 aus.
Öffnen Sie einen Browser mit der Adresse
127.0.0.1:9090/config. Diese Benutzeroberfläche verfügt über die vollständige Scraping-Konfiguration. Überprüfen Sie, ob alle Aufträge in der Konfiguration enthalten sind.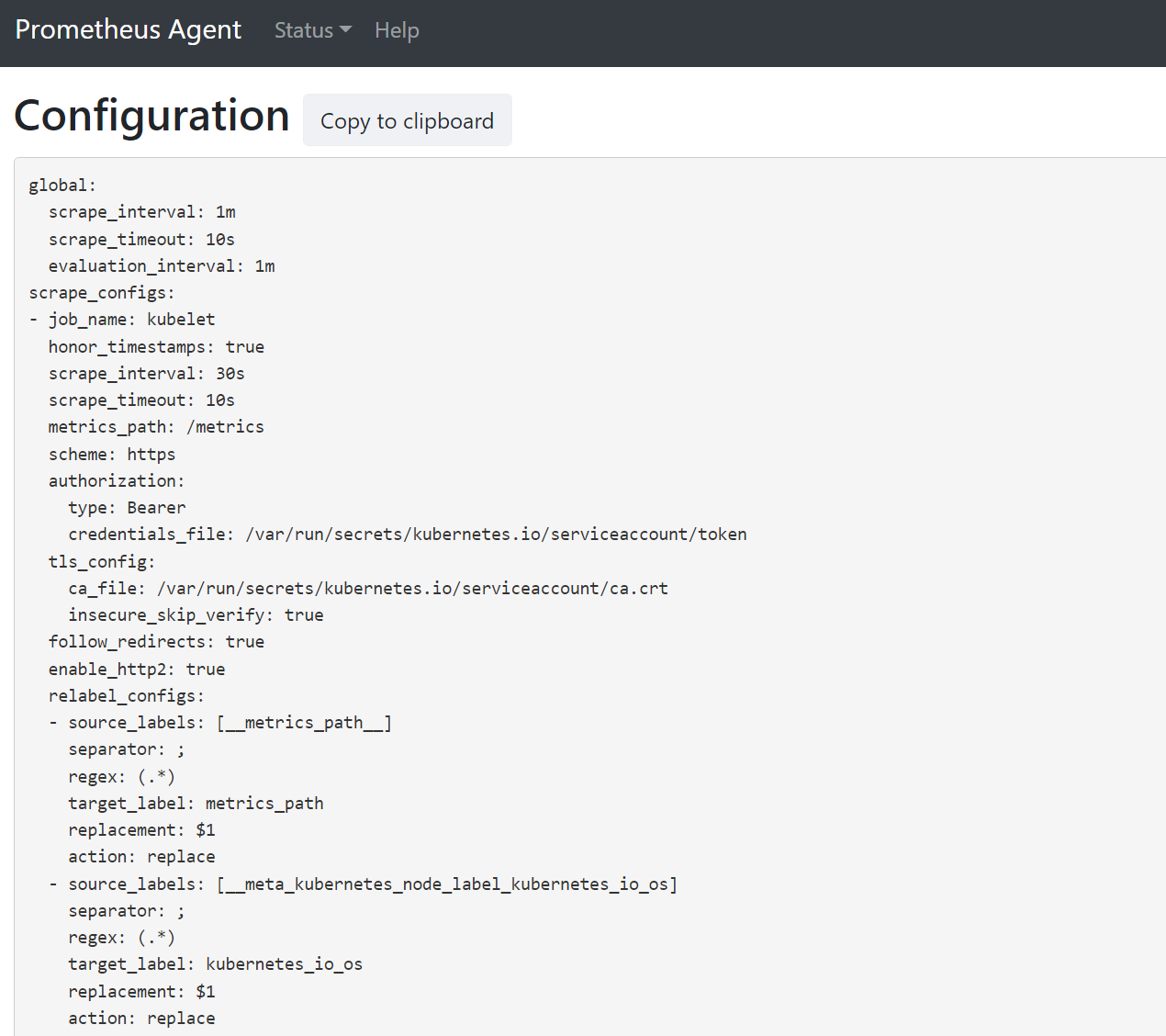
Wechseln Sie zu
127.0.0.1:9090/service-discovery, um die vom angegebenen Dienstermittlungsobjekt ermittelten Ziele und die durch „relabel_configs“ gefilterten Ziele anzuzeigen. Wenn z. B. Metriken aus einem bestimmten Pod fehlen, können Sie feststellen, ob dieser Pod ermittelt wurde und wie sein URI lautet. Anschließend können Sie mit diesem URI beim Anzeigen der Ziele feststellen, ob Auslesefehler aufgetreten sind.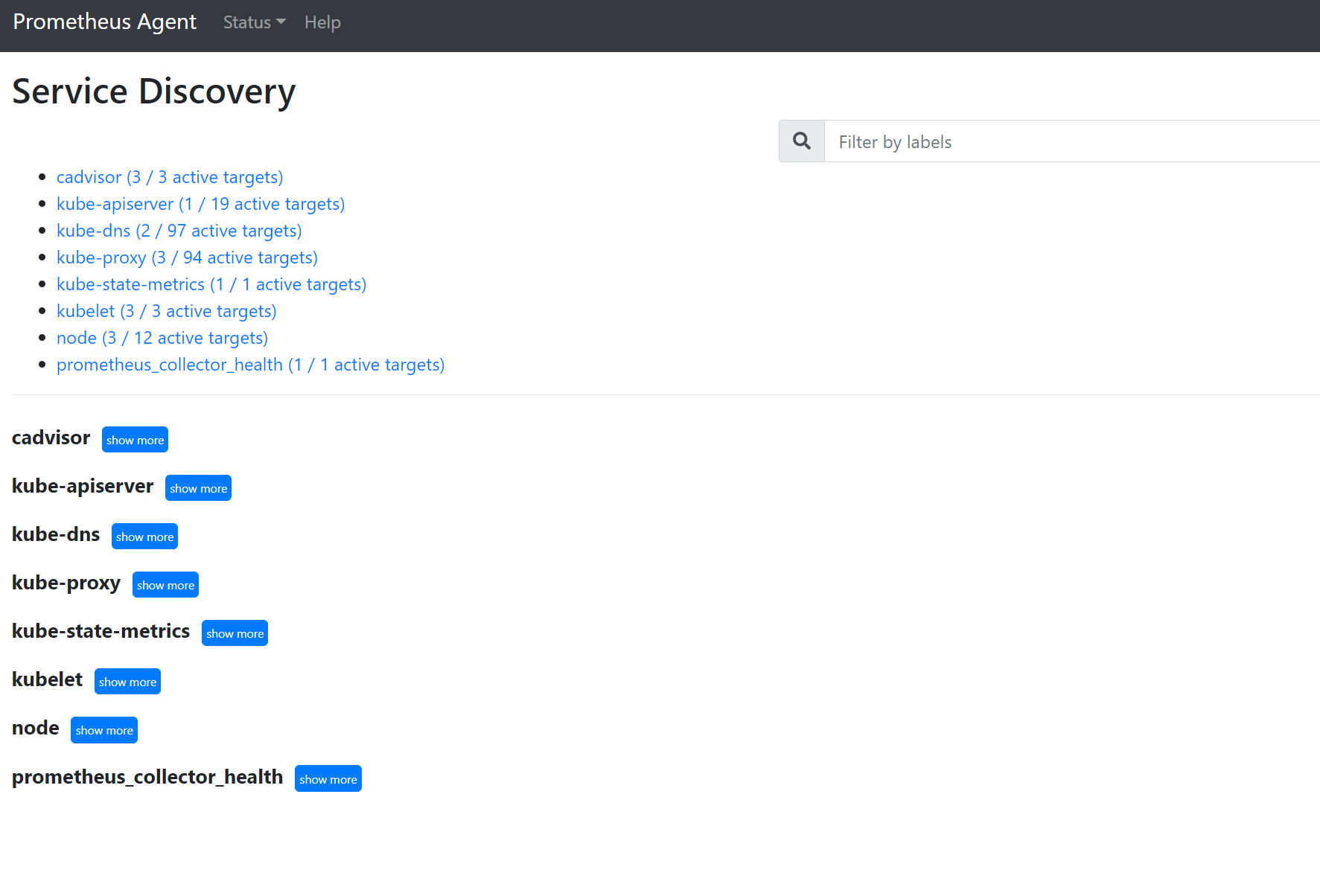
Wechseln Sie zu
127.0.0.1:9090/targets, um Folgendes anzuzeigen: alle Aufträge, wann der Endpunkt für diesen Auftrag zum letzten Mal ausgelesen wurde und alle Fehler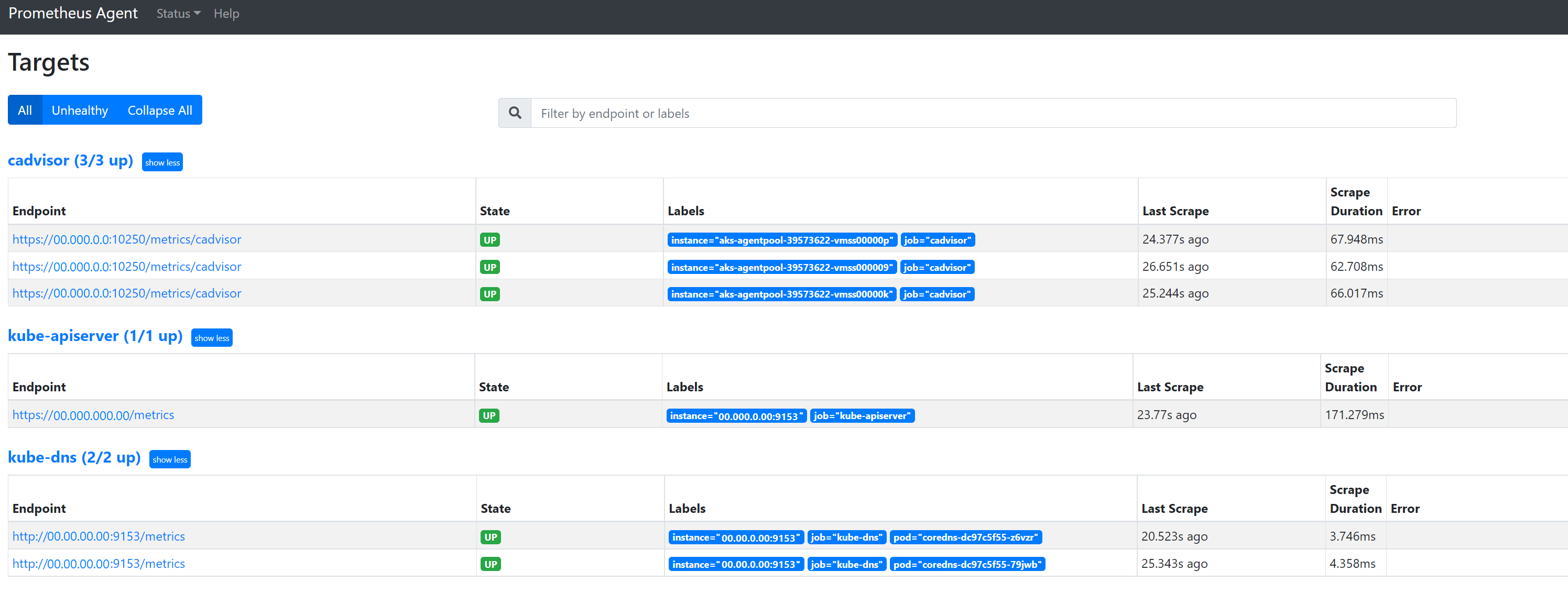



Benutzerdefinierte Ressourcen
- Wenn Sie benutzerdefinierte Ressourcen eingeschlossen haben, stellen Sie sicher, dass sie unter Konfiguration, Dienstermittlung und Zielen angezeigt werden.
Konfiguration

Dienstsuche

Targets

Wenn keine Probleme auftreten und die beabsichtigten Ziele ausgelesen werden, können Sie den Debugmodus aktivieren und genau die Metriken anzeigen, die ausgelesen werden.
Debugmodus
Warnung
Dieser Modus kann sich auf die Leistung auswirken und sollte nur für kurze Zeit zum Debuggen aktiviert werden.
Das Metrik-Add-On kann für die Ausführung im Debugmodus konfiguriert werden. Dazu ändern Sie die ConfigMap-Einstellung enabled unter debug-mode in true, wie hier beschrieben.
Wenn er aktiviert ist, werden alle ausgelesenen Prometheus-Metriken an Port 9091 gehostet. Führen Sie den folgenden Befehl aus:
kubectl port-forward <ama-metrics pod name> -n kube-system 9091
Wechseln Sie in einem Browser zu 127.0.0.1:9091/metrics, um festzustellen, ob die Metriken vom OpenTelemetry-Collector ausgelesen wurden. Auf diese Benutzeroberfläche kann für jeden ama-metrics-*-Pod zugegriffen werden. Wenn keine Metriken vorhanden sind, könnte ein Problem mit den Längen der Metrik- oder Bezeichnungsnamen oder der Anzahl von Bezeichnungen vorliegen. Überprüfen Sie auch, ob das Erfassungskontingent für Prometheus-Metriken überschritten wird, wie in diesem Artikel angegeben.
Metriknamen, Bezeichnungsnamen und Bezeichnungswerte
Für das Scraping von Metriken gelten derzeit die in der folgenden Tabelle aufgeführten Einschränkungen:
| Eigenschaft | Begrenzung |
|---|---|
| Länge des Bezeichnungsnamens | Maximal 511 Zeichen. Wenn dieser Grenzwert für eine Zeitreihe in einem Auftrag überschritten wird, schlägt der gesamte Ausleseauftrag fehl, und die Metriken werden vor der Erfassung aus diesem Auftrag gelöscht. Für diesen Auftrag wird „up=0“ angezeigt. Außerdem ist der Grund für „up=0“ in der Ziel-Benutzeroberfläche angegeben. |
| Länge des Bezeichnungswerts | Maximal 1023 Zeichen. Wenn dieses Limit für eine Zeitreihe in einem Auftrag überschritten wird, schlägt der gesamte Auslesevorgang fehl, und die Metriken werden vor der Erfassung aus diesem Auftrag gelöscht. Für diesen Auftrag wird „up=0“ angezeigt. Außerdem ist der Grund für „up=0“ in der Ziel-Benutzeroberfläche angegeben. |
| Anzahl der Bezeichnungen pro Zeitreihe | Maximal 63. Wenn dieser Grenzwert für eine Zeitreihe in einem Auftrag überschritten wird, schlägt der gesamte Ausleseauftrag fehl, und die Metriken werden vor der Erfassung aus diesem Auftrag gelöscht. Für diesen Auftrag wird „up=0“ angezeigt. Außerdem ist der Grund für „up=0“ in der Ziel-Benutzeroberfläche angegeben. |
| Länge von Metriknamen | Maximal 511 Zeichen. Wenn dieser Grenzwert für eine Zeitreihe in einem Auftrag überschritten wird, wird nur diese bestimmte Zeitreihe gelöscht. Das Löschen der Metrik kann in MetricextensionConsoleDebugLog verfolgt werden. |
| Bezeichnungsnamen mit unterschiedlicher Groß-/Kleinschreibung | Zwei Bezeichnungen innerhalb desselben Metrikbeispiels mit unterschiedlicher Groß- und Kleinschreibung werden als doppelte Bezeichnungen behandelt und bei der Erfassung gelöscht. Beispielsweise wird die Zeitreihe my_metric{ExampleLabel="label_value_0", examplelabel="label_value_1} aufgrund doppelter Bezeichnungen verworfen, da ExampleLabel und examplelabel als derselbe Bezeichnungsname angesehen wird. |
Überprüfen des Erfassungskontingents im Azure Monitor-Arbeitsbereich
Wenn Metriken fehlen, können Sie zunächst überprüfen, ob die Erfassungslimits für Ihren Azure Monitor-Arbeitsbereich überschritten wurden. Im Azure-Portal können Sie die aktuelle Nutzung für jeden Azure Monitor-Arbeitsbereich überprüfen. Die aktuellen Nutzungsmetriken werden im Menü Metrics für den Azure Monitor-Arbeitsbereich angezeigt. Die folgenden Nutzungsmetriken sind als Standardmetriken für jeden Azure Monitor-Arbeitsbereich verfügbar.
- Aktive Zeitreihen: Die Anzahl der eindeutigen Zeitreihen, die in den letzten 12 Stunden im Arbeitsbereich erfasst wurden
- Aktives Zeitreihenlimit: Das Limit für die Anzahl eindeutiger Zeitreihen, die aktiv im Arbeitsbereich erfasst werden können
- Aktive Zeitreihenauslastung in %: Der Prozentsatz der aktuell verwendeten aktiven Zeitreihen
- Erfasste Ereignisse pro Minute: Die Anzahl der Ereignisse (Beispiele) pro Minute, die kürzlich empfangen wurden
- Ereignis-pro-Minute-Erfassungslimit: Die maximale Anzahl von Ereignissen pro Minute, die vor der Drosselung erfasst werden können
- Erfasste Ereignisse pro Minute in % Auslastung: Der Prozentsatz der aktuellen Metrikerfassungsrate, der genutzt wird
Um eine Einschränkung der Metrikerfassung zu vermeiden, können Sie die Erfassungsgrenzwerte überwachen und eine Warnung einrichten. Weitere Informationen finden Sie unter Überwachen der Erfassungsgrenzwerte.
Informationen zu den Dienstkontingenten und -grenzwerten für Standardkontingente finden Sie auch, um zu verstehen, was basierend auf Ihrer Nutzung erhöht werden kann. Sie können eine Erhöhung des Kontingents für Azure Monitor-Arbeitsbereiche über das Support Request-Menü für den Azure Monitor-Arbeitsbereich anfordern. Stellen Sie sicher, dass Sie die ID, die interne ID und den Standort/die Region für den Azure Monitor-Arbeitsbereich in die Supportanfrage einschließen, die Sie im Menü „Eigenschaften“ für den Azure Monitor-Arbeitsbereich im Azure-Portal finden.
Fehler beim Erstellen von Azure Monitor-Arbeitsbereichen aufgrund der Azure Policy-Auswertung
Wenn die Erstellung eines Azure Monitor-Arbeitsbereichs mit der Fehlermeldung „Die Ressource ‘resource-name-xyz‘ wurde durch eine Richtlinie abgelehnt.“ fehlschlägt, ist möglicherweise eine Azure-Richtlinie vorhanden, die die Erstellung der Ressource verhindert. Wenn eine Richtlinie vorhanden ist, die eine Namenskonvention für Ihre Azure-Ressourcen oder -Ressourcengruppen erzwingt, müssen Sie eine Ausnahme für die Namenskonvention für die Erstellung eines Azure Monitor-Arbeitsbereichs erstellen.
Wenn Sie einen Azure Monitor-Arbeitsbereich erstellen, wird standardmäßig eine Datensammlungsregel und ein Datensammlungsendpunkt im Format „azure-monitor-workspace-name“ automatisch in einer Ressourcengruppe im Format „MA_azure-monitor-workspace-name_location_managed“ erstellt. Derzeit gibt es keine Möglichkeit, die Namen dieser Ressourcen zu ändern, und Sie müssen eine Ausnahme für das Azure Policy-Element festlegen, um die oben genannten Ressourcen von der Richtlinienauswertung auszuschließen. Weitere Informationen finden Sie unter Azure Policy-Ausnahmenstruktur.