Überwachen von Datenflüssen
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Nachdem Sie den Aufbau und das Debugging Ihres Datenflusses abgeschlossen haben, planen Sie Ihren Datenfluss am besten so, dass er nach einem Zeitplan im Kontext einer Pipeline ausgeführt wird. Sie können die Pipeline mithilfe von Triggern planen. Zum Testen und Debuggen Ihres Datenflusses aus einer Pipeline können Sie die Schaltfläche „Debuggen“ auf der Symbolleiste oder die Option „Jetzt Auslösen“ im Pipeline Builder verwenden, um eine einmalige Ausführung zum Testen Ihres Datenflusses im Pipelinekontext durchzuführen.
Bei der Ausführung können Sie die Pipeline und alle darin enthaltenen Aktivitäten, einschließlich der Datenflussaktivität, überwachen. Wählen Sie das Symbol „Überwachen“ im linken Bereich der Benutzeroberfläche aus. Daraufhin wird ein Bildschirm angezeigt, der dem folgenden ähnelt. Über die hervorgehobenen Symbole können Sie einen Drilldown in die Aktivitäten der Pipeline ausführen, einschließlich der Datenflussaktivität.
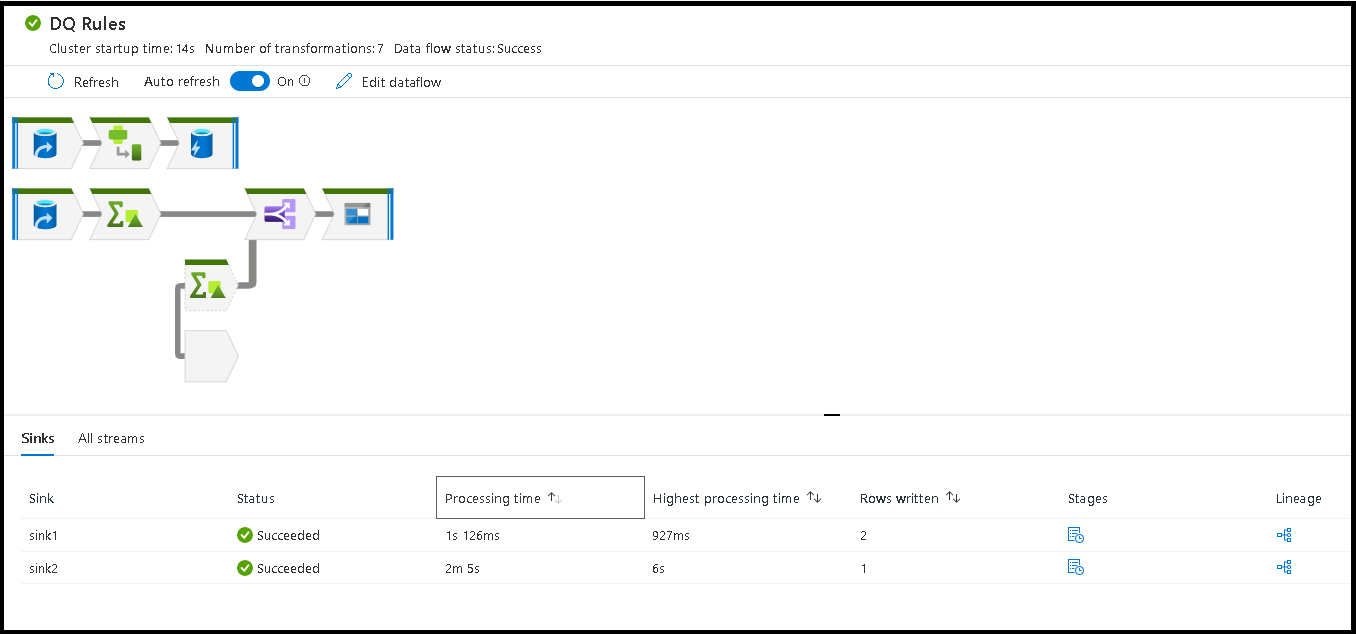
Auf dieser Ebene werden sowohl Statistikdaten als auch die Laufzeiten und der Status angezeigt. Die Ausführungs-ID auf der Aktivitätsebene unterscheidet sich von der Ausführungs-ID auf der Pipelineebene. Die Ausführungs-ID der vorherigen Ebene ist für die Pipeline. Durch Auswählen der Brille erhalten Sie detaillierte Informationen zu Ihrer Datenflussausführung.

Wenn Sie sich in der grafischen Knotenüberwachungsansicht befinden, wird eine vereinfachte reine Ansichtsversion Ihres Datenflussdiagramms angezeigt. Verwenden Sie den Zoom-Schieberegler auf der rechten Seite der Arbeitsfläche, um die Detailansicht mit größeren Diagrammknoten und Beschriftungen der Transformationsstages anzuzeigen. Sie können auch die Schaltfläche Suchen auf der rechten Seite verwenden, um Teile Ihrer Datenflusslogik in dem Graph zu suchen.

Anzeigen der Ausführungspläne für den Datenfluss
Wenn Ihr Datenfluss in Spark ausgeführt wird, bestimmt der Dienst basierend auf Ihrem gesamten Datenfluss die optimalen Codepfade. Darüber hinaus können die Ausführungspfade auf verschiedenen horizontalen Skalierungsknoten und Datenpartitionen auftreten. Daher stellt das Überwachungsdiagramm den Entwurf Ihres Flusses dar, wobei der Ausführungspfad Ihrer Transformationen berücksichtigt wird. Wenn Sie einzelne Knoten auswählen, werden „Phasen“ angezeigt, die den auf dem Cluster gemeinsam ausgeführten Code darstellen. Die angezeigten Zeitangaben und Anzahlen stellen diese Gruppen oder Phasen im Gegensatz zu den einzelnen Schritten in Ihrem Entwurf dar.

Wenn Sie das freie Feld im Überwachungsfenster auswählen, zeigen die Statistiken im unteren Bereich die Zeitangabe und die Anzahl der Zeilen für jede Senke und die Transformationen an, die zu den Senkendaten für die Transformationsherkunft geführt haben.
Wenn Sie einzelne Transformationen auswählen, wird auf der rechten Seite zusätzliches Feedback angezeigt, das Partitionsstatistiken, Spaltenanzahl, Schiefe (wie gleichmäßig die Daten auf Partitionen verteilt sind) und Kurtosis (wie viele Spitzen die Daten haben) enthält.
Das Sortieren nach Verarbeitungszeit hilft Ihnen zu erkennen, welche Stages in Ihrem Datenfluss die meiste Zeit in Anspruch genommen haben.
Um zu ermitteln, welche Transformationen innerhalb der einzelnen Stages die meiste Zeit in Anspruch genommen haben, sortieren Sie nach der längsten Verarbeitungszeit.
Die geschriebenen *Zeilen können auch sortiert werden, um zu identifizieren, welche Datenströme in Ihrem Datenfluss die meisten Daten schreiben.
Wenn Sie die Senke in der Knotenansicht auswählen, wird die Spaltenherkunft angezeigt. Es gibt drei verschiedene Methoden, mit denen Spalten während des gesamten Datenflusses akkumuliert werden, um in die Senke weitergeleitet zu werden. Sie lauten wie folgt:
- Berechnet: Sie verwenden die Spalte für die bedingte Verarbeitung oder innerhalb eines Ausdrucks in Ihrem Datenfluss; sie wird aber nicht in die Senke weitergeleitet.
- Abgeleitet: Die Spalte ist eine neue Spalte, die Sie in Ihrem Datenfluss generiert haben, d. h., sie war in der Quelle nicht vorhanden
- Zugeordnet: Die Spalte stammt aus der Quelle und Sie ordnen sie einem Senkenfeld zu
- „Data flow status“ (Datenflussstatus): Der aktuelle Status Ihrer Ausführung.
- „Cluster startup time“ (Startzeit des Clusters): Zeitraum zum Abrufen der JIT-Spark-Computeumgebung für Ihre Datenflussausführung.
- „Number of transforms“ (Anzahl von Transformationen): Die Anzahl von Transformationsschritten, die in Ihrem Fluss ausgeführt werden.

Gegenüberstellung der Gesamtverarbeitungszeit für die Senke und der Verarbeitungszeit für die Transformation
Jede Transformationsphase enthält eine Gesamtzeit bis zum Abschluss der Phase. Hierbei handelt es sich um die Summe der einzelnen Partitionsausführungszeiten. Wenn Sie die Senke auswählen, wird die Verarbeitungszeit für die Senke angezeigt. Diese Zeit enthält die gesamte Transformationszeit sowie die E/A-Zeit, die zum Schreiben Ihrer Daten in den Zielspeicher benötigt wurde. Der Unterschied zwischen der Verarbeitungszeit für die Senke und der Gesamtzeit für die Transformation ist die E/A-Zeit zum Schreiben der Daten.
Wenn Sie die JSON-Ausgabe Ihrer Datenflussaktivität in der Pipelineüberwachungsansicht öffnen, werden ausführliche Zeitangaben zu den einzelnen Partitionstransformationsschritten angezeigt. Die JSON-Ausgabe enthält millisekundengenaue Zeitangaben für jede Partition. Die Überwachungsansicht auf der Benutzeroberfläche zeigt dagegen aggregierte Zeitangaben von Partitionen, die miteinander addiert wurden:
{
"stage": 4,
"partitionTimes": [
14353,
14914,
14246,
14912,
...
]
}
Verarbeitungszeit für die Senke
Wenn Sie in der Zuordnung ein Symbol für eine Senkentransformation auswählen, zeigt das Flyout-Panel auf der rechten Seite unten einen zusätzlichen Datenpunkt namens „Nachbearbeitungszeit“. Dies ist die Zeitspanne, die für die Ausführung des Auftrags im Spark-Cluster benötigt wurde, nachdem die Daten geladen, transformiert und geschrieben wurden. Dieser Zeitraum kann das Schließen von Verbindungspools, das Herunterfahren von Treibern, das Löschen von Dateien, dass Zusammenfügen von Dateien und weitere Aufgaben umfassen. Wenn Sie in Ihrem Flow Aktionen wie „Dateien verschieben“ und „Ausgabe in einer einzelnen Datei“ ausführen, werden Sie vermutlich einen Anstieg des Werts für die Nachbearbeitungszeit bemerken.
- Dauer der Schreibphase: Die Zeit zum Schreiben der Daten an einen Stagingspeicherort für Synapse SQL.
- Dauer der SQL-Tabellenvorgänge: Die Zeit für das Verschieben von Daten aus temporären Tabellen in die Zieltabelle.
- Dauer der vorab und im Anschluss ausgeführten SQL-Vorgänge: Die Zeit für das Ausführen vor-/nachgeschalteter SQL-Befehle.
- Dauer der vorab und im Anschluss ausgeführten Befehle: Die Zeit für das Ausführen vor-/nachgeschalteter Vorgänge für dateibasierte Quellen/Senken. Beispielsweise das Verschieben oder Löschen von Dateien nach der Verarbeitung.
- Zusammenführungsdauer: Die Zeit für das Zusammenführen der Datei. Zusammengeführte Dateien werden für dateibasierte Senken verwendet, wenn in eine einzelne Datei geschrieben oder „Dateiname als Spaltendaten“ verwendet wird. Wenn für diese Metrik viel Zeit aufgewendet wird, sollten Sie diese Optionen vermeiden.
- Phasendauer: Die gesamte in Spark benötige Zeit, um den Vorgang als Phase abzuschließen.
- Temporäre Stagingtabelle: Der Name der temporären Tabelle, die von Datenflüssen zum Bereitstellen von Daten in der Datenbank verwendet wird.
Fehlerzeilen
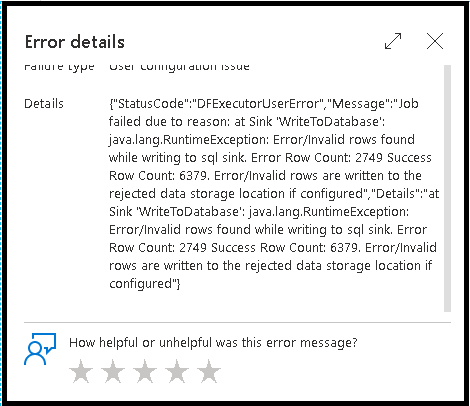
Die Aktivierung der Fehlerzeilenbehandlung in der Datenflusssenke wird in der Überwachungsausgabe berücksichtigt. Wenn Sie die Senke auf „Bericht bei Fehler als erfolgreich markieren“ festlegen, wird in der Überwachungsausgabe die Anzahl der erfolgreichen und fehlerhaften Zeilen angezeigt, wenn Sie den Überwachungsknoten der Senke auswählen.

Wenn Sie „Bericht bei Fehler als erfolgreich markieren“ auswählen, wird dieselbe Ausgabe nur im Ausgabetext der Aktivitätsüberwachung angezeigt. Dies liegt daran, dass die Datenflussaktivität für die Ausführung einen Fehler zurückgibt und die ausführliche Überwachungsansicht nicht verfügbar ist.
Symbole für die Überwachung
Dieses Symbol bedeutet, dass die Transformationsdaten bereits auf dem Cluster zwischengespeichert wurden, sodass die Zeitangaben und der Ausführungspfad dies berücksichtigt haben:

In der Transformation werden auch grüne Kreissymbole angezeigt. Sie stellen die Anzahl von Senken dar, in die der Datenfluss geleitet wird.