Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Datenflüsse sind sowohl in Azure Data Factory-Pipelines als auch in Azure Synapse Analytics-Pipelines verfügbar. Dieser Artikel gilt für die Zuordnung von Datenflüssen. Wenn Sie mit Transformationen noch nicht fertig sind, lesen Sie den einführungsartikel Transformieren von Daten mithilfe von Zuordnungsdatenflüssen.
Bei der bedingten Split-Transformation werden Datenzeilen basierend auf übereinstimmenden Bedingungen an verschiedene Streams geleitet. Die Transformation für bedingtes Teilen ist mit einer CASE-Entscheidungsstruktur in einer Programmiersprache vergleichbar. Die Transformation wertet Ausdrücke aus und leitet dann die Datenzeile basierend auf den Ergebnissen an den angegebenen Datenstrom weiter.
Konfiguration
Mit der Einstellung Teilen bei wird bestimmt, ob die Datenzeile an den ersten übereinstimmenden Stream oder an alle übereinstimmenden Streams weitergeleitet wird.
Verwenden Sie den Ausdrucks-Generator für Datenflüsse, um einen Ausdruck für die Teilungsbedingung einzugeben. Klicken Sie zum Hinzufügen einer neuen Bedingung in einer vorhandenen Zeile auf das Pluszeichen. Darüber hinaus kann für Zeilen, für die sich keine Übereinstimmung mit einer Bedingung ergibt, auch ein Standardstream hinzugefügt werden.
Datenflussskript
Syntax
<incomingStream>
split(
<conditionalExpression1>
<conditionalExpression2>
...
disjoint: {true | false}
) ~> <splitTx>@(stream1, stream2, ..., <defaultStream>)
Beispiel
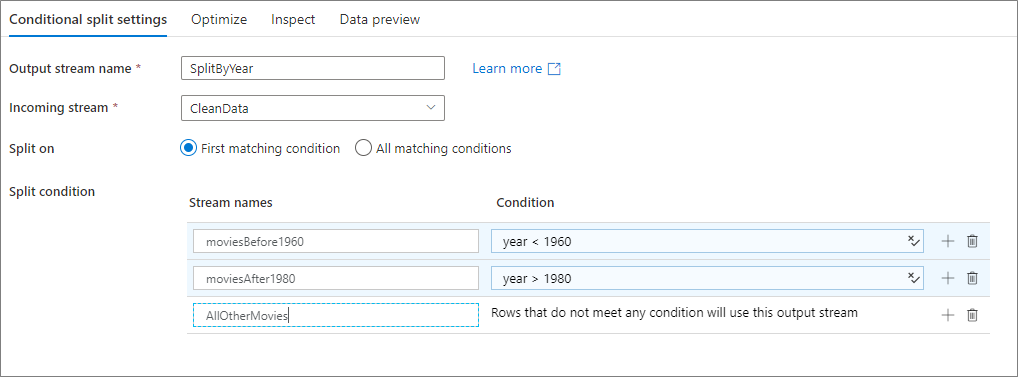
Das folgende Beispiel ist eine Transformation für bedingtes Teilen mit dem Namen SplitByYear, bei der der eingehende Stream CleanData verwendet wird. Diese Transformation verfügt über die beiden Teilungsbedingungen year < 1960 und year > 1980.
disjoint ist „false“, weil die Daten nicht an alle übereinstimmenden Bedingungen, sondern an die erste übereinstimmende Bedingung geleitet werden. Alle Zeilen, die die erste Bedingung erfüllen, werden an den Ausgabestream moviesBefore1960 geleitet. Alle verbleibenden Zeilen, die die zweite Bedingung erfüllen, werden an den Ausgabestream moviesAFter1980 geleitet. Für alle anderen Zeilen wird der Standardstream AllOtherMovies verwendet.
In der Benutzeroberfläche des Diensts sieht diese Transformation wie in der folgenden Abbildung aus:
Das Datenflussskript für diese Transformation befindet sich im folgenden Codeausschnitt:
CleanData
split(
year < 1960,
year > 1980,
disjoint: false
) ~> SplitByYear@(moviesBefore1960, moviesAfter1980, AllOtherMovies)
Zugehöriger Inhalt
Häufig verwendete Datenflusstransformationen, die zusammen mit der bedingten Aufteilung verwendet werden, sind die Join-Transformation, Lookup-Transformation, und die Select-Transformation.