Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Datenflüsse sind sowohl in Azure Data Factory-Pipelines als auch in Azure Synapse Analytics-Pipelines verfügbar. Dieser Artikel gilt für Datenflusszuordnungen. Wenn Sie mit Transformationen noch nicht fertig sind, lesen Sie den einführungsartikel Transformieren von Daten mithilfe von Zuordnungsdatenflüssen.
Verwenden Sie die Pivottransformation, um aus den eindeutigen Zeilenwerten einer einzelnen Spalte mehrere Spalten zu erstellen. Pivotieren ist eine Aggregationstransformation, bei der Sie die Option „Nach Spalten gruppieren“ auswählen und mithilfe von Aggregatfunktionen Pivotspalten erstellen.
Konfiguration
Für die Pivottransformation sind drei verschiedene Eingaben erforderlich: Gruppierung nach Spalten, der Pivotschlüssel und die Art und Weise, wie die pivotierten Spalten generiert werden sollen.
Gruppieren nach
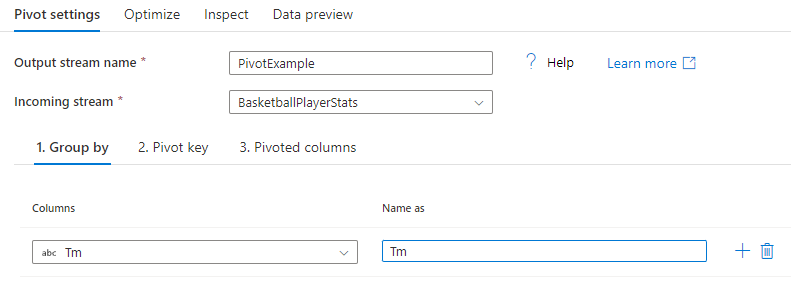
Wählen Sie aus, über welche Spalten die pivotierten Spalten aggregiert werden sollen. Die Ausgabedaten fassen alle Zeilen mit denselben Gruppierungswerten zu einer Zeile zusammen. Die Aggregation, die in der pivotierten Spalte ausgeführt wird, erfolgt für jede Gruppe.
Dieser Abschnitt ist optional. Wenn keine Gruppieren nach-Spalten ausgewählt werden, wird der gesamte Datenstrom aggregiert und nur eine Zeile ausgegeben.
Pivotschlüssel
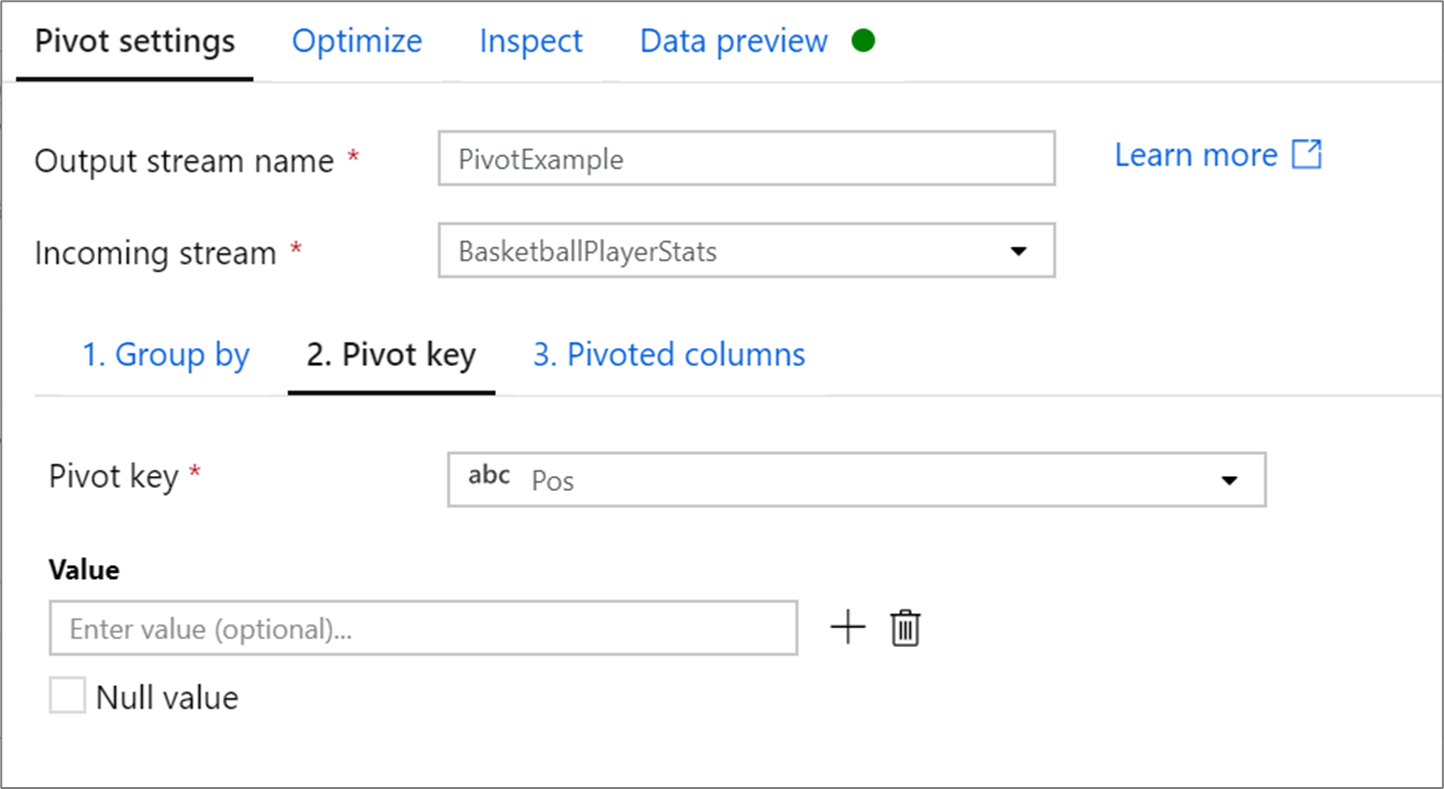
Der Pivotschlüssel ist die Spalte, deren Zeilenwerte in neue Spalten pivotiert werden. Standardmäßig erstellt die Pivottransformation eine neue Spalte für jeden eindeutigen Zeilenwert.
Im Abschnitt Wert können Sie bestimmte Zeilenwerte eingeben, die pivotiert werden sollen. Nur die in diesem Abschnitt eingegebenen Zeilenwerte werden pivotiert. Durch Aktivieren von NULL-Wert wird eine pivotierte Spalte für die NULL-Werte in der Spalte erstellt.
Pivotierte Spalten
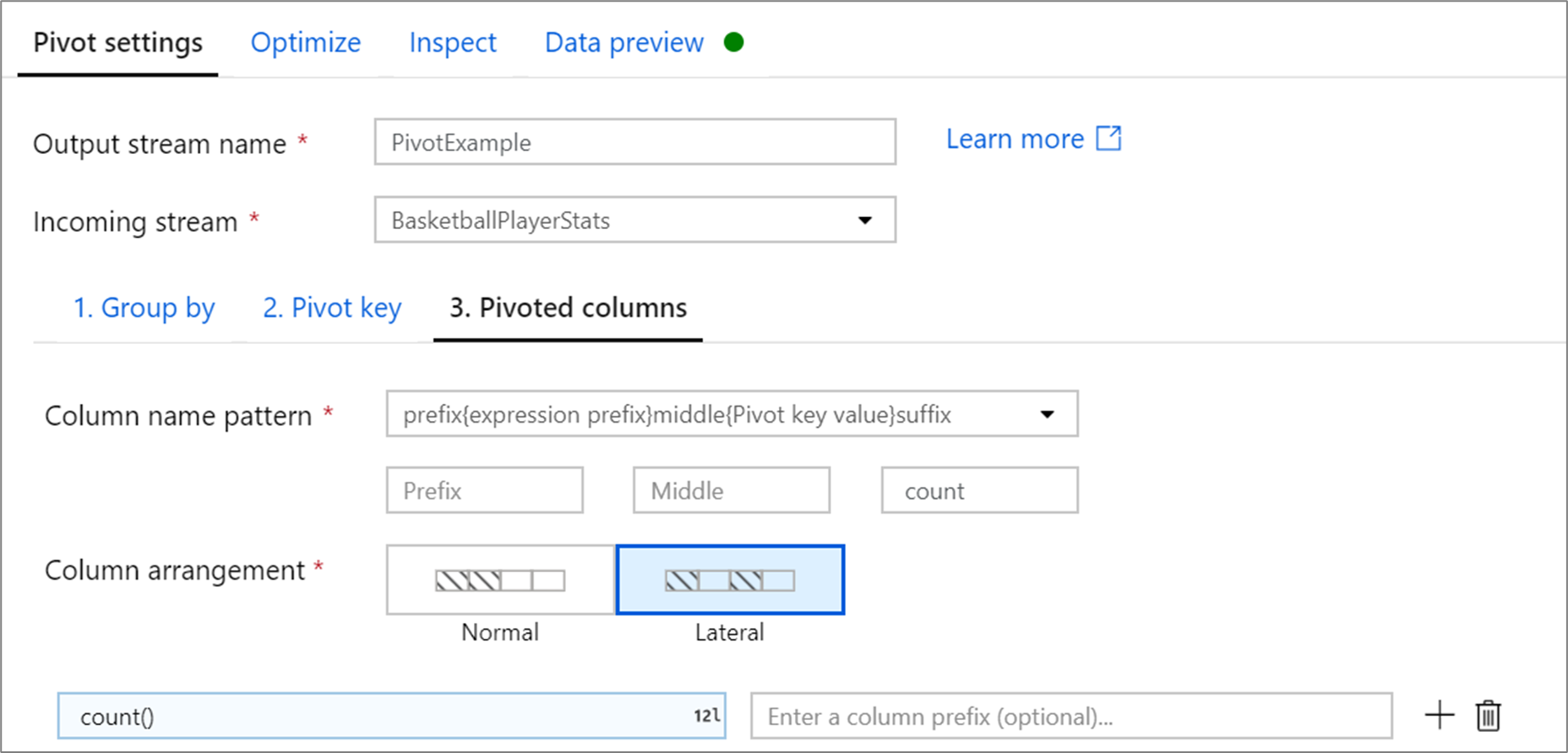
Generieren Sie für jeden eindeutigen Pivotschlüsselwert, der zu einer Spalte transformiert wird, einen aggregierten Zeilenwert für jede Gruppe. Sie können mehrere Spalten pro Pivotschlüssel erstellen. Jede Pivotspalte muss mindestens eine Aggregatfunktion enthalten.
Spaltennamensmuster: Wählen Sie aus, wie der Spaltenname jeder Pivotspalte formatiert werden soll. Der ausgegebene Spaltenname ist eine Kombination aus dem Pivotschlüsselwert, dem Spaltenpräfix und optionalen Präfix, Suffix und Zeichen in der Mitte.
Spaltenanordnung: Wenn Sie mehr als eine Pivotspalte pro Pivotschlüssel generieren, wählen Sie aus, wie die Spalten angeordnet werden sollen.
Spaltenpräfix: Wenn Sie mehr als eine Pivotspalte pro Pivotschlüssel generieren, geben Sie ein Spaltenpräfix für jede Spalte ein. Diese Einstellung ist optional, wenn Sie nur über eine pivotierte Spalte verfügen.
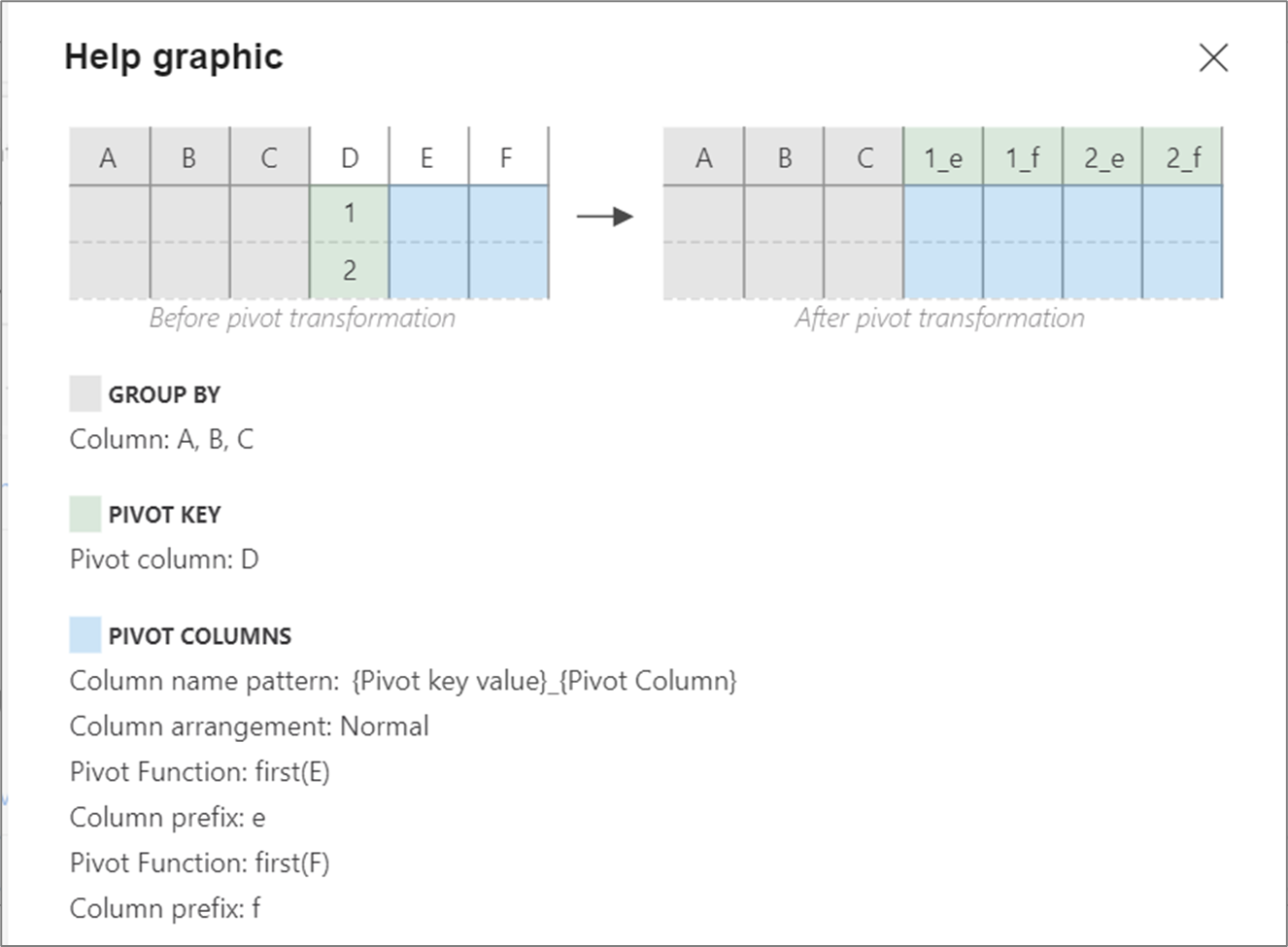
Hilfegrafik
Die folgende Hilfegrafik zeigt, wie die verschiedenen Pivotkomponenten miteinander interagieren:
Pivotmetadaten
Wenn in der Pivotschlüsselkonfiguration keine Werte angegeben sind, werden die pivotierten Spalten dynamisch zur Laufzeit generiert. Die Anzahl von pivotierten Spalten entspricht der Anzahl von eindeutigen Pivotschlüsselwerte multipliziert mit der Anzahl von Pivotspalten. Da diese Zahl veränderlich ist, werden die Spaltenmetadaten auf der Benutzeroberfläche auf der Registerkarte Untersuchen nicht angezeigt, und es erfolgt keine Spaltenweitergabe. Verwenden Sie zum Transformieren dieser Spalten die Spaltenmuster-Funktionen des Zuordnungsdatenflusses.
Wenn bestimmte Pivotschlüsselwerte festgelegt wurden, werden die pivotierten Spalten in den Metadaten angezeigt. Spaltennamen stehen Ihnen in der Zuordnung für Untersuchung und Senke zur Verfügung.
Generieren von Metadaten aus verschobenen Spalten
Pivot generiert neue Spaltennamen dynamisch basierend auf Zeilenwerten. Sie können diese neuen Spalten zu den Metadaten hinzufügen, auf die später im Datenfluss verwiesen werden kann. Verwenden Sie hierzu die Schnellaktion Abweichende zuordnen in der Datenvorschau.
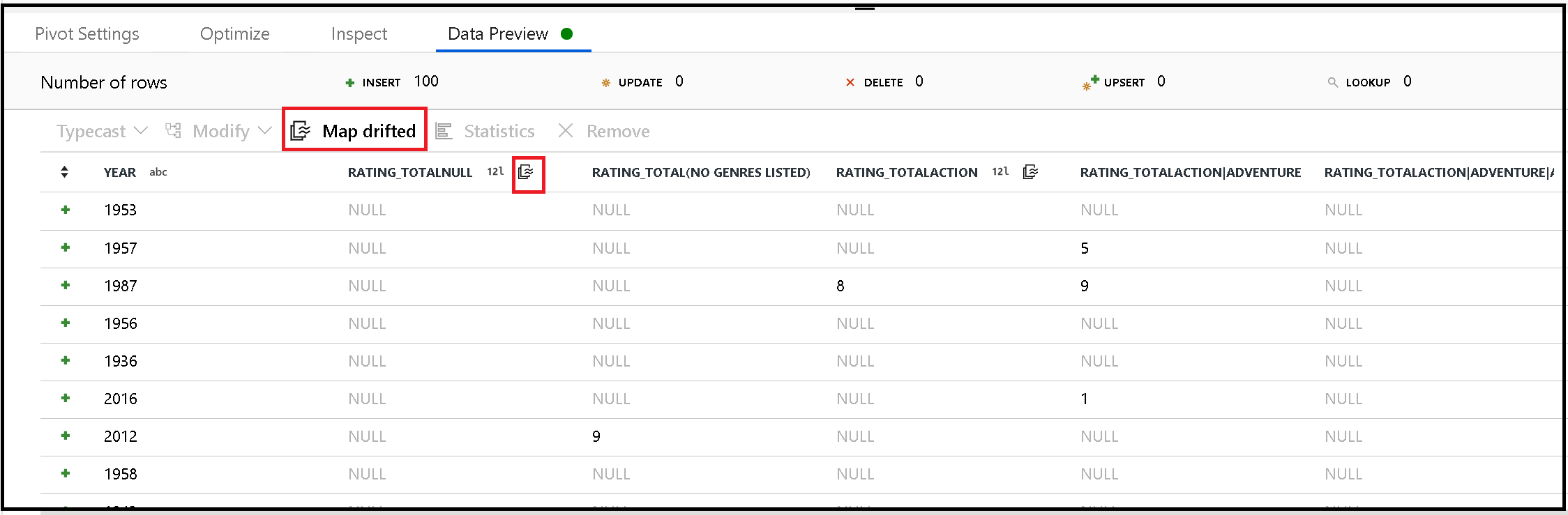
Senken für pivotierte Spalten
Pivotierte Spalten sind zwar dynamisch, können aber trotzdem in Ihren Zieldatenspeicher geschrieben werden. Aktivieren Sie in Ihren Senkeneinstellungen die Option Schemaabweichung zulassen. Sie können Spalten schreiben, die nicht in den Metadaten enthalten sind. Die neuen dynamischen Namen werden nicht in Ihren Spaltenmetadaten angezeigt, die Option zur Schemaabweichung ermöglicht Ihnen aber trotzdem die Bereitstellung der Daten.
Erneutes Verknüpfen der ursprünglichen Felder
Die Pivottransformation wird nur für die Gruppieren nach-Spalten und die pivotierten Spalten ausgeführt. Wenn die Ausgabedaten auch andere Eingabespalten enthalten sollen, verwenden Sie ein Selbstverknüpfungsmuster.
Datenflussskript
Syntax
<incomingStreamName>
pivot(groupBy(Tm),
pivotBy(<pivotKeyColumn, [<specifiedColumnName1>,...,<specifiedColumnNameN>]),
<pivotColumnPrefix> = <pivotedColumnValue>,
columnNaming: '< prefix >< $N | $V ><middle >< $N | $V >< suffix >',
lateral: { 'true' | 'false'}
) ~> <pivotTransformationName
Beispiel
Den im Konfigurationsabschnitt gezeigten Screenshots liegt das folgende Datenflussskript zugrunde:
BasketballPlayerStats pivot(groupBy(Tm),
pivotBy(Pos),
{} = count(),
columnNaming: '$V$N count',
lateral: true) ~> PivotExample
Zugehöriger Inhalt
Versuchen Sie, die Entpivotierungstransformation durchzuführen, um Spaltenwerte in Zeilenwerte umzuwandeln.