Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisieren, um auf neue Funktionen in data Science, Echtzeitanalysen und Berichterstellung zuzugreifen.
Das Common Data Model-Metadatensystem (CDM) ermöglicht es Daten und deren Bedeutung für die einfache Freigabe über Anwendungen und Geschäftsprozesse hinweg. Weitere Informationen finden Sie in der Übersicht über Common Data Model.
In Azure Data Factory- und Synapse-Pipelines können Benutzer Daten aus CDM-Entitäten in model.json- und Manifestformularen transformieren, die in Azure Data Lake Store Gen2 (ADLS Gen2) gespeichert sind, mithilfe von Zuordnungsdatenflüssen. Sie können Daten mithilfe von Verweisen auf CDM-Entitäten auch als Senken in das CDM-Format transformieren. Dann werden diese im CSV- oder PARQUET-Format in partitionierten Ordnern gespeichert.
Eigenschaften von Zuordnungsdatenflüssen
Die Common Data Model ist als inline-Dataset in der Zuordnung von Datenflüssen sowohl als Quelle als auch als Spüle verfügbar.
Hinweis
Beim Schreiben von CDM-Entitäten muss bereits eine CDM-Entitätsdefinition (Metadatenschema) vorhanden sein, die zur Verwendung als Verweis definiert ist. Die Datenflusssenke liest diese CDM-Entitätsdatei und importiert das Schema in die Senke für die Feldzuordnung.
Hinweis
Bei Verwendung von CDM mit Change Data Capture (CDC) in Datenflüssen werden Aktualisierungen mithilfe eines dateibasierten CDC-Ansatzes erkannt, der von den Zeitstempeln der zuletzt geänderten Datei gesteuert wird.
Quelleigenschaften
In der folgenden Tabelle sind die von einer CDM-Quelle unterstützten Eigenschaften aufgeführt. Sie können diese Eigenschaften auf der Registerkarte Quelloptionen bearbeiten.
| Name | BESCHREIBUNG | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Format | Das Format muss cdm sein |
ja | cdm |
format |
| Metadatenformat | Gibt an, wo sich der Entitätsverweis auf die Daten befindet. Bei Verwendung von CDM-Version 1.0 wählen Sie „manifest“ aus. Bei Verwendung einer früheren CDM-Version als 1.0 wählen Sie „model.json“ aus. | Ja |
'manifest' oder 'model' |
manifestType |
| Stammspeicherort: Container | Der Containername des CDM-Ordners. | ja | String | fileSystem |
| Stammspeicherort: Ordnerpfad | Der Stammspeicherort des CDM-Ordners. | ja | String | folderPath |
| Manifestdatei: Entitätspfad | Der Ordnerpfad der Entität innerhalb des Stammordners. | nein | String | entityPath |
| Manifestdatei: Manifestname | Der Name der Manifestdatei. Der Standardwert lautet „default“. | Nein | String | manifestName |
| Nach der letzten Änderung filtern | Filtern Sie Dateien nach dem Zeitpunkt ihrer letzten Änderung. | nein | Zeitstempel | modifiedAfter modifiedBefore |
| Mit dem Schema verknüpfter Dienst | Der verknüpfte Dienst, in dem sich der Korpus befindet. | Ja, wenn Manifest verwendet wird |
'adlsgen2' oder 'github' |
corpusStore |
| Entitätsverweis-Container | Der Containerkorpus ist in | Ja, wenn Manifest und Korpus in ADLS Gen2 verwendet werden | String | adlsgen2_fileSystem |
| Entitätsverweis-Repository | GitHub Repositoryname | ja, wenn manifest und korpus in GitHub | String | github_repository |
| Entitätsverweis-Verzweigung | GitHub Repository-Verzweigung | ja, wenn manifest und korpus in GitHub | String | github_branch |
| Korpusordner | Der Stammspeicherort des Korpus. | Ja, wenn Manifest verwendet wird | String | corpusPath |
| Korpusentität | Der Pfad zum Entitätsverweis. | ja | String | entity |
| Finden keiner Dateien zulässig | „true“ gibt an, dass kein Fehler ausgelöst wird, wenn keine Dateien gefunden werden. | nein |
true oder false |
ignoreNoFilesFound |
Bei Auswahl von „Entitätsverweis“ in den Quell- und Senkentransformationen können Sie zwischen den drei folgenden Optionen für den Speicherort Ihres Entitätsverweises wählen:
- Bei der Option „Lokal“ wird die Entität verwendet, die in der bereits vom Dienst verwendeten Manifestdatei definiert ist.
- Bei der Option „Benutzerdefiniert“ werden Sie aufgefordert, auf eine Entitätsmanifestdatei zu verweisen, die sich von der vom Dienst verwendeten Manifestdatei unterscheidet.
- Standard verwendet einen Entitätsverweis aus der Standardbibliothek von CDM-Entitäten, die in
GitHubverwaltet werden.
Senkeneinstellungen
- Zeigen Sie auf die Verweisdatei für die CDM-Entität, die die Definition der Entität enthält, die Sie schreiben möchten.
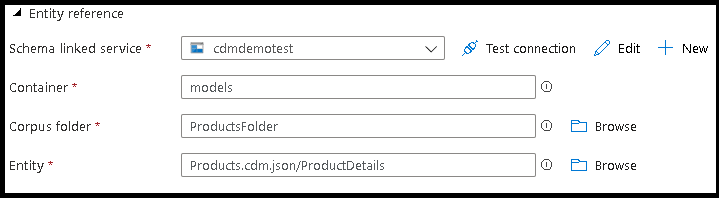
- Definieren Sie den Partitionspfad und das Format der Ausgabedateien, die der Dienst zum Schreiben von Entitäten verwenden soll.
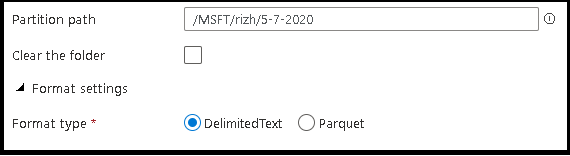
- Legen Sie den Speicherort der Ausgabedatei sowie den Speicherort und den Namen der Manifestdatei fest.

Importieren des Schemas
CDM ist nur als Inlinedataset verfügbar und weist standardmäßig kein zugeordnetes Schema auf. Zum Abrufen von Spaltenmetadaten klicken Sie auf der Registerkarte Projektion auf die Schaltfläche Schema importieren. Auf diese Weise können Sie auf die Spaltennamen und Datentypen verweisen, die durch den Korpus angegeben sind. Zum Importieren des Schemas muss eine Datenfluss-Debugsitzung aktiv sein, und es muss eine CDM-Entitätsdefinitionsdatei vorhanden sein, auf die verwiesen werden kann.
Wenn Sie Entitätseigenschaften in der Senkentransformation Spalten für Zuordnungsdatenflüsse zuordnen möchten, klicken Sie erst auf die Registerkarte „Zuordnen“ und dann auf „Schema importieren“. Der Dienst liest den Entitätsverweis, auf den Sie in den Senkenoptionen verwiesen haben, und ermöglicht es Ihnen, das CDM-Zielschema zuzuordnen.

Hinweis
Wenn Sie model.json Quelltyp verwenden, der aus Power BI- oder Power Platform-Datenflüssen stammt, treten möglicherweise Fehler vom Typ "Korpuspfad ist null oder leer" aus der Quelltransformation auf. Dies ist wahrscheinlich auf Formatierungsprobleme beim Speicherortpfad der Partition in der Datei „model.json“ zurückzuführen. Führen Sie zur Behebung die folgenden Schritte aus:
- Öffnen Sie die Datei „model.json“ in einem Text-Editor.
- Suchen Sie nach der Eigenschaft „partitions.Location“.
- Ändern Sie „blob.core.windows.net“ in „dfs.core.windows.net“.
- Korrigieren Sie eine „%2F“-Codierung in der URL in „/“.
- Bei Verwendung von ADF-Datenflüssen müssen Sonderzeichen im Partitionsdateipfad durch alphanumerische Werte ersetzt oder zu Azure Synapse Datenflüssen wechseln.
Beispiel eines Datenflussskripts für eine CDM-Quelle
source(output(
ProductSizeId as integer,
ProductColor as integer,
CustomerId as string,
Note as string,
LastModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
entity: 'Product.cdm.json/Product',
format: 'cdm',
manifestType: 'manifest',
manifestName: 'ProductManifest',
entityPath: 'Product',
corpusPath: 'Products',
corpusStore: 'adlsgen2',
adlsgen2_fileSystem: 'models',
folderPath: 'ProductData',
fileSystem: 'data') ~> CDMSource
Senkeneigenschaften
In der folgenden Tabelle sind die von einer CDM-Senke unterstützten Eigenschaften aufgeführt. Sie können diese Eigenschaften auf der Registerkarte Einstellungen bearbeiten.
| Name | BESCHREIBUNG | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Format | Das Format muss cdm sein |
ja | cdm |
format |
| Stammspeicherort: Container | Der Containername des CDM-Ordners. | ja | String | fileSystem |
| Stammspeicherort: Ordnerpfad | Der Stammspeicherort des CDM-Ordners. | ja | String | folderPath |
| Manifestdatei: Entitätspfad | Der Ordnerpfad der Entität innerhalb des Stammordners. | nein | String | entityPath |
| Manifestdatei: Manifestname | Der Name der Manifestdatei. Der Standardwert lautet „default“. | Nein | String | manifestName |
| Mit dem Schema verknüpfter Dienst | Der verknüpfte Dienst, in dem sich der Korpus befindet. | ja |
'adlsgen2' oder 'github' |
corpusStore |
| Entitätsverweis-Container | Der Containerkorpus ist in | Ja, wenn der Korpus in ADLS Gen2 ist | String | adlsgen2_fileSystem |
| Entitätsverweis-Repository | GitHub Repositoryname | Ja, wenn Korpus in GitHub | String | github_repository |
| Entitätsverweis-Verzweigung | GitHub Repository-Verzweigung | Ja, wenn Korpus in GitHub | String | github_branch |
| Korpusordner | Der Stammspeicherort des Korpus. | ja | String | corpusPath |
| Korpusentität | Der Pfad zum Entitätsverweis. | ja | String | entity |
| Partitionspfad | Der Speicherort, an den die Partition geschrieben wird. | nein | String | partitionPath |
| Ordner löschen | Wenn der Zielordner vor dem Schreiben gelöscht wird. | nein |
true oder false |
truncate |
| Formattyp | Hiermit wird das Parquet-Format ausgewählt. | nein |
parquet, wenn angegeben |
subformat |
| Spaltentrennzeichen | Hiermit wird beim Schreiben in „DelimitedText“ das Trennen von Spalten angegeben. | Ja, wenn in „DelimitedText“ geschrieben wird | String | columnDelimiter |
| Erste Zeile als Kopfzeile | Hiermit wird bei Verwendung von „DelimitedText“ angegeben, ob die Spaltennamen als Kopfzeile hinzugefügt werden. | nein |
true oder false |
columnNamesAsHeader |
Beispiel eines Datenflussskripts für eine CDM-Senke
Das zugehörige Datenflussskript ist:
CDMSource sink(allowSchemaDrift: true,
validateSchema: false,
entity: 'Product.cdm.json/Product',
format: 'cdm',
entityPath: 'ProductSize',
manifestName: 'ProductSizeManifest',
corpusPath: 'Products',
partitionPath: 'adf',
folderPath: 'ProductSizeData',
fileSystem: 'cdm',
subformat: 'parquet',
corpusStore: 'adlsgen2',
adlsgen2_fileSystem: 'models',
truncate: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CDMSink
Zugehöriger Inhalt
Erstellen Sie eine Quelltransformation in einem Zuordnungsdatenfluss.