Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel erfahren Sie, wie Sie Daten unter Verwendung des Deltaformats in eine bzw. aus einer Delta Lake-Instanz kopieren, die in Azure Data Lake Store Gen2 oder in Azure Blob Storage gespeichert ist. Dieser Connector ist als Inlinedataset in Zuordnungsdatenflüssen sowohl als Quelle als auch als Senke verfügbar.
Eigenschaften von Mapping Data Flow
Dieser Connector ist als Inlinedataset in Zuordnungsdatenflüssen sowohl als Quelle als auch als Senke verfügbar.
Quelleigenschaften
Die folgende Tabelle enthält die von einer Deltaquelle unterstützten Eigenschaften. Sie können diese Eigenschaften auf der Registerkarte Quelloptionen bearbeiten.
| Name | BESCHREIBUNG | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Format | Das Format muss delta sein |
ja | delta |
format |
| Dateisystem | Der Container bzw. das Dateisystem der Delta Lake-Instanz. | ja | String | fileSystem |
| Ordnerpfad | Das Verzeichnis der Delta Lake-Instanz | ja | String | folderPath |
| Komprimierungstyp | Der Komprimierungstyp der Deltatabelle. | nein | bzip2gzipdeflateZipDeflatesnappylz4 |
compressionType |
| Komprimierungsgrad | Wählen Sie aus, ob die Komprimierung schnellstmöglich abgeschlossen oder die resultierende Datei optimal komprimiert werden soll. | Erforderlich, wenn compressedType angegeben wird. |
Optimal oder Fastest |
compressionLevel |
| Zeitreise | Wählen Sie aus, ob eine ältere Momentaufnahme einer Deltatabelle abgefragt werden soll. | nein | Abfrage nach Zeitstempel: Zeitstempel Abfragen nach Version: Integer |
timestampAsOf versionAsOf |
| Finden keiner Dateien zulässig | Falls TRUE, wird kein Fehler ausgelöst, wenn keine Dateien gefunden werden. | nein |
true oder false |
ignoreNoFilesFound |
Schema importieren
Delta ist nur als Inlinedataset verfügbar und verfügt standardmäßig über kein zugeordnetes Schema. Zum Abrufen von Spaltenmetadaten klicken Sie auf der Registerkarte Projektion auf die Schaltfläche Schema importieren. Dadurch können Sie auf die Spaltennamen und Datentypen verweisen, die vom Korpus angegeben sind. Zum Importieren des Schemas muss eine Debugsitzung für den Datenfluss aktiv sein, und es muss eine CDM-Entitätsdefinitionsdatei vorhanden sein, auf die verwiesen werden kann.
Skriptbeispiel für Deltaquelle
source(output(movieId as integer,
title as string,
releaseDate as date,
rated as boolean,
screenedOn as timestamp,
ticketPrice as decimal(10,2)
),
store: 'local',
format: 'delta',
versionAsOf: 0,
allowSchemaDrift: false,
folderPath: $tempPath + '/delta'
) ~> movies
Senkeneigenschaften
Die folgende Tabelle enthält die von einer Deltasenke unterstützten Eigenschaften. Sie können diese Eigenschaften auf der Registerkarte Einstellungen bearbeiten.
| Name | BESCHREIBUNG | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Format | Das Format muss delta sein |
ja | delta |
format |
| Dateisystem | Der Container bzw. das Dateisystem der Delta Lake-Instanz. | ja | String | fileSystem |
| Ordnerpfad | Das Verzeichnis der Delta Lake-Instanz | ja | String | folderPath |
| Komprimierungstyp | Der Komprimierungstyp der Deltatabelle. | nein | bzip2gzipdeflateZipDeflatesnappylz4TarGZiptar |
compressionType |
| Komprimierungsgrad | Wählen Sie aus, ob die Komprimierung schnellstmöglich abgeschlossen oder die resultierende Datei optimal komprimiert werden soll. | Erforderlich, wenn compressedType angegeben wird. |
Optimal oder Fastest |
compressionLevel |
| Vakuum | Löscht Dateien, die älter als die angegebene Dauer und für die aktuelle Tabellenversion nicht mehr relevant sind. Bei Angabe eines Werts kleiner oder gleich 0 erfolgt der Bereinigungsvorgang nicht. | ja | Integer | vacuum |
| Aktion table | Informiert ADF, was mit der Ziel-Deltatabelle in Ihrer Senke zu tun ist. Sie können die Tabelle unverändert lassen und neue Zeilen anfügen, die vorhandene Tabellendefinition und -daten mit neuen Metadaten und Daten überschreiben oder die vorhandene Tabellenstruktur beibehalten, aber zuerst alle Zeilen abschneiden und dann die neuen Zeilen einfügen. | nein | Keine, Abschneiden, Überschreiben | Differenz abschneiden, Überschreiben |
| Updatemethode | Wenn Sie allein „Einfügen zulassen“ auswählen oder in eine neue Deltatabelle schreiben, empfängt das Ziel alle eingehenden Zeilen, und zwar unabhängig von den festgelegten Zeilenrichtlinien. Wenn Ihre Daten Zeilen mit anderen Zeilenrichtlinien enthalten, müssen diese mit einer vorhergehenden Filtertransformation ausgeschlossen werden. Wenn alle Update-Methoden ausgewählt sind, erfolgt eine Zusammenführung, bei der Zeilen gemäß den festgelegten Richtlinien für Zeilen eingefügt/gelöscht/aktualisiert und eingefügt/aktualisiert werden, und zwar mithilfe einer vorhergehenden Alter Row-Transformation. |
ja |
true oder false |
insertable deletable upsertable updateable |
| Optimierter Schreibvorgang | Erzielen Sie einen höheren Durchsatz für den Schreibvorgang, indem Sie das interne Mischen in Spark-Executors optimieren. Dies führt ggf. zu weniger Partitionen und größeren Dateien. | nein |
true oder false |
OptimizedWrite: true |
| Automatisches Komprimieren | Nach dem Abschließen der einzelnen Schreibvorgänge führt Spark automatisch den Befehl OPTIMIZE aus, um die Daten neu zu organisieren. Dies führt bei Bedarf zu weiteren Partitionen, um künftig eine bessere Leseleistung zu erzielen. |
nein |
true oder false |
autoCompact: wahr |
Skriptbeispiel für Deltasenke
Das zugehörige Datenflussskript ist:
moviesAltered sink(
input(movieId as integer,
title as string
),
mapColumn(
movieId,
title
),
insertable: true,
updateable: true,
deletable: true,
upsertable: false,
keys: ['movieId'],
store: 'local',
format: 'delta',
vacuum: 180,
folderPath: $tempPath + '/delta'
) ~> movieDB
Deltasenke mit Partitionsbereinigung
Mit dieser Option unter der Updatemethode oben (also update/upsert/delete) können Sie die Anzahl der Partitionen einschränken, die überprüft werden. Nur Partitionen, die diese Bedingung erfüllen, werden vom Zielspeicher abgerufen. Sie können feste Werte angeben, die eine Partitionsspalte annehmen kann.
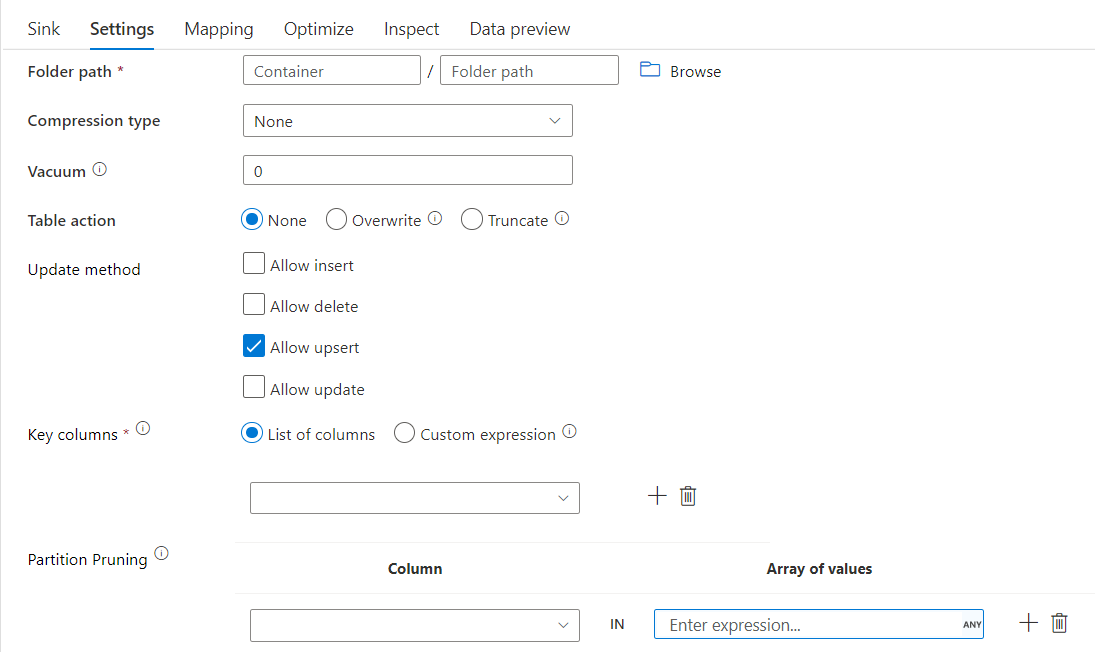
Beispielskript für eine Deltasenke mit Partitionsbereinigung
Ein Beispielskript finden Sie unten.
DerivedColumn1 sink(
input(movieId as integer,
title as string
),
allowSchemaDrift: true,
validateSchema: false,
format: 'delta',
container: 'deltaContainer',
folderPath: 'deltaPath',
mergeSchema: false,
autoCompact: false,
optimizedWrite: false,
vacuum: 0,
deletable:false,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
pruneCondition:['part_col' -> ([5, 8])],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink2
Delta liest nur zwei Partitionen aus dem Zieldeltaspeicher, für die part_col == 5 und 8 gilt, und nicht alle Partitionen. part_col ist eine Spalte, nach der die Zieldeltadaten partitioniert werden. Sie muss in den Quelldaten nicht enthalten sein.
Optionen zur Deltasenkenoptimierung
Auf der Registerkarte „Einstellungen“ finden Sie drei weitere Optionen zum Optimieren der Deltasenkentransformation.
Wenn die Option Schema zusammenführen aktiviert ist, ermöglicht sie eine Schemaweiterentwicklung, d. h. alle Spalten, die im aktuellen eingehenden Datenstrom, aber nicht in der Deltazieltabelle vorhanden sind, werden automatisch deren Schema hinzugefügt. Diese Option wird für alle Updatemethoden unterstützt.
Wenn Automatisch komprimieren aktiviert ist, wird bei der Transformation nach einem einzelnen Schreibvorgang überprüft, ob Dateien weiter komprimiert werden können. Zudem wird ein schneller OPTIMIZE-Auftrag (mit Dateigrößen von 128 MB anstelle von 1 GB) ausgeführt, um Dateien für Partitionen mit der höchsten Anzahl kleiner Dateien weiter zu komprimieren. Die automatische Komprimierung hilft bei der Zusammenführung einer großen Anzahl kleiner Dateien in eine kleinere Anzahl großer Dateien. Die automatische Komprimierung erfolgt nur, wenn mindestens 50 Dateien vorhanden sind. Nachdem ein Komprimierungsvorgang ausgeführt wurde, wird eine neue Version der Tabelle erstellt und eine neue Datei geschrieben, die die Daten mehrerer früherer Dateien in einem kompakten, komprimierten Formular enthält.
Wenn Schreiben optimieren aktiviert ist, optimiert die Senkentransformation die Partitionsgrößen dynamisch basierend auf den tatsächlichen Daten, indem versucht wird, Dateien mit einer Größe von 128 MB für jede Tabellenpartition zu schreiben. Dies ist eine ungefähre Größe und kann je nach Datasetmerkmalen variieren. Mit der Option „Schreiben optimieren“ wird die Gesamteffizienz der Schreibvorgänge und nachfolgenden Lesevorgänge verbessert. Dabei werden Partitionen so organisiert, dass die Leistung nachfolgender Lesevorgänge verbessert wird.
Tipp
Der optimierte Schreibvorgang wird ihren gesamten ETL-Auftrag verlangsamen, da der Senke den Spark Delta Lake Optimize Befehl ausstellen wird, nachdem Ihre Daten verarbeitet wurden. Es ist empfohlen “Optimierter Schreibzugriff“ sparsam zu benutzen. Wenn Sie beispielsweise über eine stundenweise Datenpipeline verfügen, führen Sie täglich einen Datenfluss mit "Optimierter Schreibzugriff" aus.
Bekannte Einschränkungen
Beim Schreiben in eine Deltasenke wird aufgrund einer bekannten Einschränkung die Anzahl geschriebener Zeilen nicht in der Überwachungsausgabe gezeigt.
Zugehöriger Inhalt
- Erstellen Sie eine Quelltransformation in einem Zuordnungsdatenfluss.
- Erstellen Sie eine Senkentransformation in einem Zuordnungsdatenfluss.
- Erstellen Sie eine Zeilenänderungstransformation, um Zeilen als Einfüge-, Aktualisierungs-, Upsert- oder Löschvorgänge zu markieren.