Laden von Daten in Azure Synapse Analytics mithilfe einer Azure Data Factory- oder Synapse-Pipeline
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Azure Synapse Analytics ist eine cloudbasierte Datenbank mit horizontaler Skalierung, mit der sehr große Datenvolumen verarbeitet werden können, und zwar sowohl relational als auch nicht relational. Azure Synapse Analytics basiert auf der MPP-Architektur (Massively Parallel Processing), die für Data-Warehouse-Workloads auf Unternehmensniveau optimiert ist. Es bietet Cloudelastizität mit der Flexibilität, Speicher zu skalieren und unabhängig zu berechnen.
Das Ausführen der ersten Schritte mit Azure Synapse Analytics ist jetzt einfacher als je zuvor. Azure Data Factory und das entsprechende Pipelinefeature in Azure Synapse bieten einen vollständig verwalteten cloudbasierten Datenintegrationsdienst. Mithilfe dieses Diensts können Sie eine Azure Synapse Analytics-Instanz mit Daten aus dem vorhandenen System auffüllen und so Zeit beim Erstellen von Analyselösungen sparen.
Azure Data Factory- und Synapse-Pipelines bieten die folgenden Vorteile beim Laden von Daten in Azure Synapse Analytics:
- Mühelose Einrichtung: Intuitiver Assistent mit 5 Schritten. Keine Skripterstellung erforderlich.
- Unterstützung für umfangreiche Datenspeicher: Integrierte Unterstützung für umfangreiche lokale und cloudbasierte Datenspeicher. Eine ausführliche Liste finden Sie in der Tabelle Unterstützte Datenspeicher.
- Sicher und kompatibel: Daten werden über HTTPS oder ExpressRoute übertragen. Globale Dienste stellen sicher, dass Ihre Daten nie die geografische Grenze verlassen.
- Beispiellose Leistung mithilfe von PolyBase: PolyBase ist die effizienteste Methode zum Verschieben von Daten in Azure Synapse Analytics. Mit der Funktion „Stagingblob“ werden schnelle Ladezeiten für alle Arten von Datenspeicher erreicht. Dies gilt auch für Azure Blob Storage und Data Lake Store. (Azure Blob Storage und Azure Data Lake Store werden standardmäßig von Polybase unterstützt.) Weitere Informationen finden Sie unter Leistung der Kopieraktivität.
In diesem Artikel erfahren Sie, wie Sie das Tool „Kopieren von Daten“ zum Laden von Daten aus der Azure SQL-Datenbank in Azure Synapse Analytics verwenden. Sie können ähnliche Schritte zum Kopieren von Daten aus anderen Typen von Datenspeichern ausführen.
Hinweis
Weitere Informationen finden Sie unter Kopieren von Daten nach und aus Azure Synapse Analytics.
Voraussetzungen
- Azure-Abonnement: Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
- Azure Synapse Analytics: Dieses Data Warehouse enthält die Daten, die aus der SQL-Datenbank kopiert werden. Wenn Sie keine Azure Synapse Analytics-Instanz besitzen, finden Sie unter Erstellen einer Azure Synapse Analytics-Instanz die entsprechenden Anweisungen.
- Azure SQL-Datenbank: In diesem Tutorial werden Daten aus einem Beispieldataset von Adventure Works LT nach Azure SQL-Datenbank kopiert. Sie können diese Beispieldatenbank in SQL-Datenbank erstellen, indem Sie den Anweisungen unter Schnellstart: Erstellen einer Azure SQL-Einzeldatenbank folgen.
- Azure-Speicherkonto: Azure Storage wird im Massenkopiervorgang als Stagingblob verwendet. Falls Sie noch nicht über ein Azure-Speicherkonto verfügen, finden Sie Anweisungen dazu unter Erstellen eines Speicherkontos.
Erstellen einer Data Factory
Wenn Sie Ihre Data Factory noch nicht erstellt haben, befolgen Sie die Schritte im Schnellstart: Erstellen einer Data Factory mithilfe des Azure-Portals und Azure Data Factory Studio, um eine zu erstellen. Navigieren Sie nach dem Erstellen zur Data Factory im Azure-Portal.
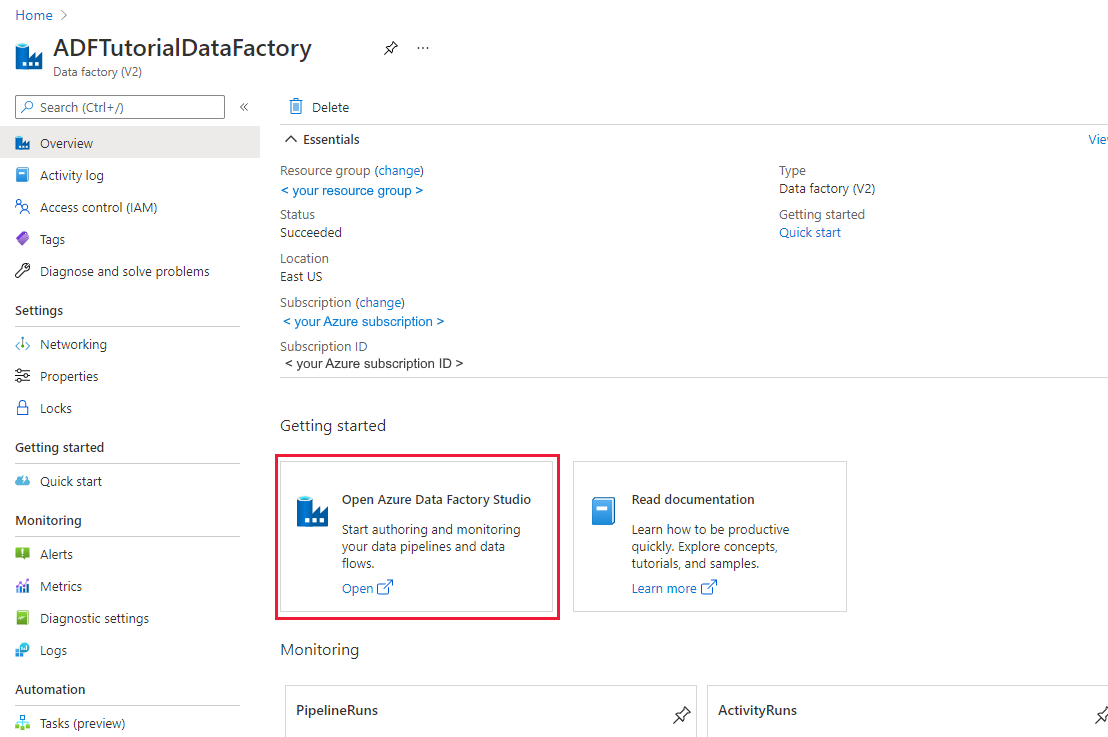
Klicken Sie auf der Kachel Open Azure Data Factory Studio auf Öffnen, um die Datenintegrationsanwendung in einer separaten Registerkarte zu starten.
Laden von Daten in Azure Synapse Analytics
Wählen Sie auf der Startseite von dem Azure Data Factory- oder Azure Synapse-Arbeitsbereich die Kachel Erfassen aus, um das Tool „Daten kopieren“ zu starten. Sie können dann die Integrierte Kopieraufgabe verwenden.
Klicken Sie auf der Seite Eigenschaften unter Vorgangsart auf den Typ Integrierte Kopieraufgabe und dann auf Weiter.

Führen Sie auf der Seite Quelldatenspeicher die folgenden Schritte aus:
Tipp
In diesem Tutorial verwenden Sie die SQL-Authentifizierung als Authentifizierungstyp für Ihren Quelldatenspeicher, Sie können bei Bedarf aber auch andere unterstützte Authentifizierungsmethoden auswählen: Dienstprinzipal oder Verwaltete Identität. Ausführlichere Informationen finden Sie in den entsprechenden Abschnitten dieses Artikels. Zum sicheren Speichern von Geheimnissen für Datenspeicher empfiehlt sich darüber hinaus die Verwendung einer Azure Key Vault-Instanz. Eine ausführliche Erläuterung finden Sie in diesem Artikel.
Wählen Sie + Neue Verbindung aus.
Wählen Sie im Katalog Azure SQL-Datenbank und dann Weiter aus. Sie können in das Suchfeld zum Filtern der Connectors „SQL“ eingeben.

Wählen Sie auf der Seite Neue Verbindung (Azure SQL Database) in der Dropdownliste Ihren Server- und Datenbanknamen aus und geben Sie den Benutzernamen und das Kennwort an. Wählen Sie Verbindung testen aus, um die Einstellungen zu überprüfen. Wählen Sie dann Erstellen aus.

Wählen Sie auf der Seite Zieldatenspeicher die neu erstellte Verbindung als Quelle in dem Bereich Verbindung aus.
Geben Sie SalesLT in dem Abschnitt Quelltabellen ein, um die Tabellen zu filtern. Aktivieren Sie das Kontrollkästchen (Alles auswählen) , um alle Tabellen für den Kopiervorgang zu verwenden, und wählen Sie dann Weiter aus.

Geben Sie auf der Seite Filter anwenden die Einstellungen an, oder wählen Sie Weiter aus. Sie können eine Datenvorschau anzeigen und das Schema der Eingabedaten einsehen, indem Sie die Schaltfläche Datenvorschau auswählen.

Führen Sie auf der Seite Zieldatenspeicher die folgenden Schritte aus:
Tipp
In diesem Tutorial verwenden Sie die SQL-Authentifizierung als Authentifizierungstyp für Ihren Zieldatenspeicher, Sie können bei Bedarf aber auch andere unterstützte Authentifizierungsmethoden auswählen: Dienstprinzipal oder Verwaltete Identität. Ausführlichere Informationen finden Sie in den entsprechenden Abschnitten dieses Artikels. Zum sicheren Speichern von Geheimnissen für Datenspeicher empfiehlt sich darüber hinaus die Verwendung einer Azure Key Vault-Instanz. Eine ausführliche Erläuterung finden Sie in diesem Artikel.
Wählen Sie + Neue Verbindung aus, um eine Verbindung hinzuzufügen.
Wählen Sie im Katalog Azure Synapse Analytics aus, und klicken Sie auf Weiter.

Wählen Sie auf der Seite Neue Verbindung (Azure Synapse Analytics) in der Dropdownliste Ihren Server- und Datenbanknamen aus und geben Sie den Benutzernamen und das Kennwort an. Wählen Sie Verbindung testen aus, um die Einstellungen zu überprüfen. Wählen Sie dann Erstellen aus.

Wählen Sie auf der Seite Zieldatenspeicher die neu erstellte Verbindung als Senke in dem Bereich Verbindung aus.
Überprüfen Sie den Inhalt der Seite Tabellenzuordnung und klicken Sie dann auf Weiter. Eine intelligente Tabellenzuordnung wird angezeigt. Die Quelltabellen werden den Zieltabellen auf Grundlage der Tabellennamen zugeordnet. Wenn eine Quelltabelle im Ziel nicht vorhanden ist, wird von dem Service standardmäßig eine Zieltabelle mit dem gleichen Namen erstellt. Sie können eine Quelltabelle auch einer vorhandenen Zieltabelle zuordnen.

Überprüfen Sie den Inhalt der Seite Spaltenzuordnung, und wählen Sie dann Weiter aus. Die intelligente Tabellenzuordnung basiert auf dem Spaltennamen. Wenn Sie den Dienst die Tabellen automatisch erstellen lassen, kann eine Datentypkonvertierung erfolgen, wenn zwischen den Quell- und Zielspeichern Inkompatibilitäten vorliegen. Wenn es eine nicht unterstützte Datentypkonvertierung zwischen der Quell- und Zielspalte gibt, wird eine Fehlermeldung neben der entsprechenden Tabelle angezeigt.

Führen Sie auf der Seite Einstellungen die folgenden Schritte aus:
Geben Sie CopyFromSQLToSQLDW in das Feld Aufgabenname ein.
Klicken Sie im Abschnitt Stagingeinstellungen auf + Neu, um einen neuen Stagingspeicher zu erstellen. Der Speicher wird für das Staging der Daten verwendet, bevor diese mit PolyBase in Azure Synapse Analytics geladen werden. Nach Abschluss des Kopiervorgangs werden die vorläufigen Daten in Azure Blob Storage automatisch bereinigt.
Wählen Sie auf der Seite Neuer verknüpfter Dienst Ihr Speicherkonto und dann Erstellen aus, um den verknüpften Dienst bereitzustellen.
Deaktivieren Sie die Option Typstandard verwenden, und wählen Sie dann Weiter aus.

Überprüfen Sie auf der Seite Zusammenfassung die Einstellungen, und klicken Sie dann auf Weiter.
Klicken Sie auf der Seite Bereitstellung auf Überwachen, um die Pipeline (Task) zu überwachen.

Beachten Sie, dass die Registerkarte Überwachen auf der linken Seite automatisch ausgewählt ist. Wenn die Pipelineausführung erfolgreich abgeschlossen wurde, wählen Sie den Link CopyFromSQLToSQLDW unter der Spalte Pipelinename aus, um Details zur Aktivitätsausführung anzuzeigen oder die Pipeline erneut auszuführen.
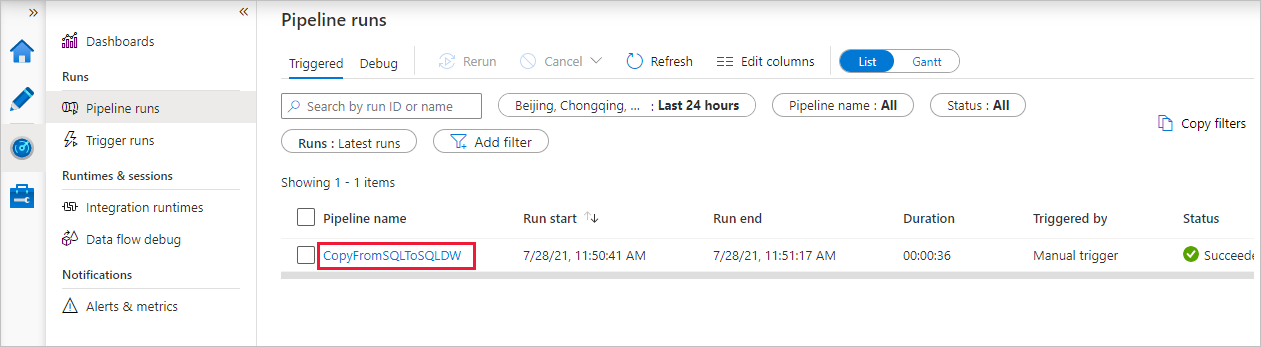
Wählen Sie oben den Link Alle Pipelineausführungen aus, um zurück zur Ansicht mit den Pipelineausführungen zu wechseln. Klicken Sie zum Aktualisieren der Liste auf Aktualisieren.

Zum Überwachen der Ausführungsdetails jeder Kopieraktivität wählen Sie in der Ansicht der Aktivitätsausführungen unter Aktivitätsname den Link Details (Brillensymbol) aus. Sie können Details wie die Menge der Daten, die aus der Quelle in die Senke kopiert wurden, den Datendurchsatz, die Ausführungsschritte mit entsprechender Dauer sowie die verwendeten Konfigurationen überwachen.


Zugehöriger Inhalt
Lesen Sie den folgenden Artikel, um mehr über die Unterstützung von Azure Synapse Analytics zu erfahren: