Schnellstart: Erstellen einer Azure Data Factory-Instanz mithilfe von PowerShell
GILT FÜR: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Diese Schnellstartanleitung beschreibt, wie Sie mithilfe von PowerShell eine Azure Data Factory-Instanz erstellen. Die in dieser Data Factory erstellte Pipeline kopiert Daten aus einem Ordner in einen anderen Ordner in Azure Blob Storage. Ein Tutorial zum Transformieren von Daten mithilfe von Azure Data Factory finden Sie unter Tutorial: Daten mit Spark transformieren.
Hinweis
Dieser Artikel enthält keine ausführliche Einführung in den Data Factory-Dienst. Eine Einführung in den Azure Data Factory-Dienst finden Sie unter Einführung in Azure Data Factory.
Voraussetzungen
Azure-Abonnement
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Azure-Rollen
Damit Sie Data Factory-Instanzen erstellen können, muss das Benutzerkonto, mit dem Sie sich bei Azure anmelden, ein Mitglied der Rolle Mitwirkender oder Besitzer oder ein Administrator des Azure-Abonnements sein. Wenn Sie die Berechtigungen anzeigen möchten, über die Sie im Abonnement verfügen, wechseln Sie zum Azure-Portal, wählen Sie in der oberen rechten Ecke Ihren Benutzernamen aus, wählen Sie Weitere Optionen (...) aus, und wählen Sie dann Meine Berechtigungen aus. Wenn Sie Zugriff auf mehrere Abonnements besitzen, wählen Sie das entsprechende Abonnement aus.
Für das Erstellen und Verwalten von untergeordneten Ressourcen für Data Factory – z.B. Datasets, verknüpfte Dienste, Pipelines, Trigger und Integration Runtimes – gelten die folgenden Anforderungen:
- Für das Erstellen und Verwalten von untergeordneten Ressourcen im Azure-Portal müssen Sie auf Ressourcengruppenebene oder höher Mitglied der Rolle Mitwirkender von Data Factory sein.
- Zum Erstellen und Verwalten von untergeordneten Ressourcen mit PowerShell oder dem SDK auf Ressourcenebene oder höher ist die Rolle Mitwirkender ausreichend.
Eine Beispielanleitung zum Hinzufügen eines Benutzers zu einer Rolle finden Sie im Artikel Hinzufügen oder Ändern von Azure-Administratorrollen, die das Abonnement oder die Dienste verwalten.
Weitere Informationen finden Sie in den folgenden Artikeln:
- Rolle „Mitwirkender von Data Factory“
- Roles and permissions for Azure Data Factory (Rollen und Berechtigungen für Azure Data Factory)
Azure-Speicherkonto
Sie verwenden in diesem Schnellstart ein allgemeines Azure Storage-Konto (Blobspeicher) als Datenspeicher vom Typ Quelle und vom Typ Ziel. Falls Sie noch nicht über ein allgemeines Azure Storage-Konto verfügen, lesen Sie zum Erstellen die Informationen unter Erstellen Sie ein Speicherkonto.
Abrufen des Speicherkontonamens
In dieser Schnellstartanleitung benötigen Sie den Namen Ihres Azure Storage-Kontos. Das folgende Verfahren enthält die Schritte zum Abrufen des Namens für Ihr Speicherkonto:
- Navigieren Sie in einem Webbrowser zum Azure-Portal, und melden Sie sich mit Ihrem Azure-Benutzernamen und dem zugehörigen Kennwort an.
- Wählen Sie im Menü des Azure-Portals die Option Alle Dienste und anschließend Storage>Speicherkonten aus. Alternativ können Sie auf einer beliebigen Seite nach Speicherkonten suchen und die entsprechende Option auswählen.
- Filtern Sie auf der Seite Speicherkonten nach Ihrem Speicherkonto (falls erforderlich), und wählen Sie dann Ihr Speicherkonto aus.
Alternativ können Sie auf einer beliebigen Seite nach Speicherkonten suchen und die entsprechende Option auswählen.
Erstellen eines Blobcontainers
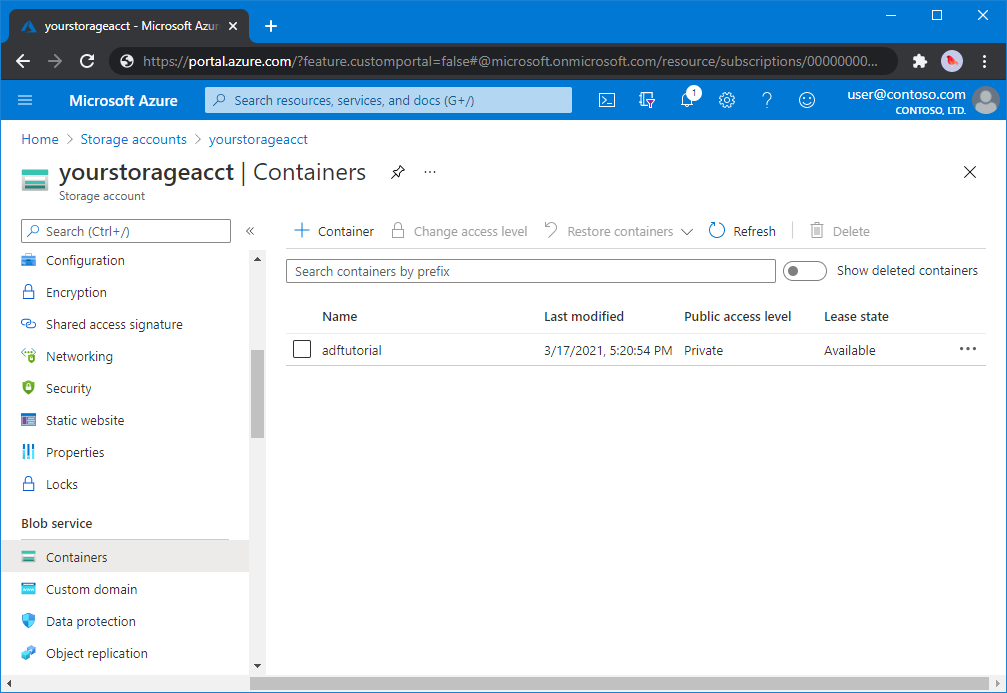
In diesem Abschnitt erstellen Sie einen Blobcontainer mit dem Namen adftutorial in Azure Blob Storage.
Wählen Sie auf der Seite „Speicherkonto“ die Optionen Übersicht>Container aus.
Wählen Sie auf der Symbolleiste der Seite <Kontoname> - Container die Option Container aus.
Geben Sie im Dialogfeld Neuer Container als Namen adftutorial ein, und klicken Sie auf OK. Die Seite <Kontoname> - Container wird aktualisiert, woraufhin die Liste der Container den Eintrag adftutorial enthält.
Hinzufügen eines Eingabeordners und einer Datei für den Blobcontainer
In diesem Abschnitt erstellen Sie einen Ordner mit dem Namen input in dem Container, den Sie erstellt haben, und laden eine Beispieldatei in den Eingabeordner hoch. Öffnen Sie zunächst einen Text-Editor wie Notepad, und erstellen Sie eine Datei mit dem Namen emp.txt und folgendem Inhalt:
John, Doe
Jane, Doe
Speichern Sie die Datei im Ordner C:\ADFv2QuickStartPSH. (Erstellen Sie den Ordner, falls er noch nicht vorhanden ist.) Kehren Sie dann zum Azure-Portal zurück, und führen Sie die folgenden Schritte aus:
Wählen Sie auf der Seite <Kontoname> - Container, auf der Sie Ihre Arbeit unterbrochen haben, in der aktualisierten Liste der Container den Eintrag adftutorial aus.
- Falls Sie das Fenster geschlossen oder zu einer anderen Seite gewechselt haben, melden Sie sich erneut beim Azure-Portal an.
- Wählen Sie im Menü des Azure-Portals die Option Alle Dienste und anschließend Storage>Speicherkonten aus. Alternativ können Sie auf einer beliebigen Seite nach Speicherkonten suchen und die entsprechende Option auswählen.
- Wählen Sie Ihr Speicherkonto und anschließend Container>adftutorial aus.
Wählen Sie auf der Symbolleiste der Seite des Containers adftutorial die Option Hochladen aus.
Wählen Sie auf der Seite Blob hochladen das Feld Dateien aus. Navigieren Sie zur Datei emp.txt, und wählen Sie dann die Datei aus.
Erweitern Sie die Überschrift Erweitert. Die Seite wird jetzt wie folgt angezeigt:
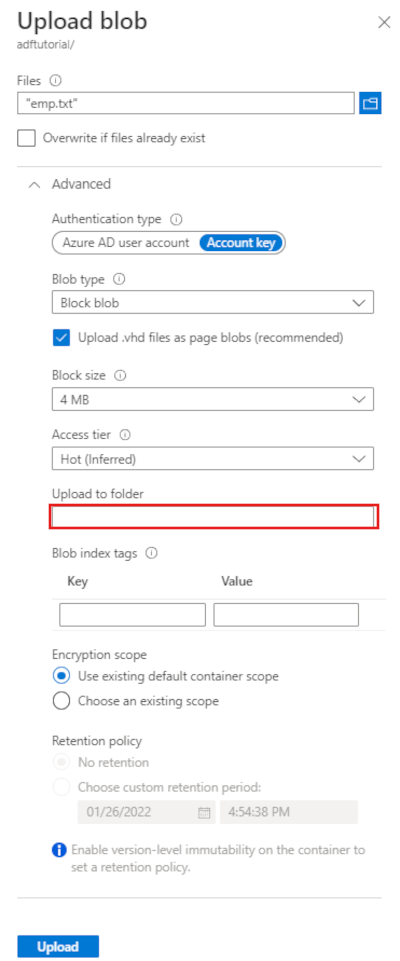
Geben Sie im Feld In Ordner hochladen den Namen input ein.
Wählen Sie die Schaltfläche Hochladen. Daraufhin sollten in der Liste die Datei emp.txt und der Status des Uploads angezeigt werden.
Wählen Sie das Symbol Schließen (das X) aus, um die Seite Blob hochladen zu schließen.
Lassen Sie die Seite des Containers adftutorial geöffnet. Sie überprüfen darauf am Ende dieser Schnellstartanleitung die Ausgabe.
Azure PowerShell
Hinweis
Es wird empfohlen, das Azure Az PowerShell-Modul für die Interaktion mit Azure zu verwenden. Informationen zu den ersten Schritten finden Sie unter Installieren von Azure PowerShell. Informationen zum Migrieren zum Az PowerShell-Modul finden Sie unter Migrieren von Azure PowerShell von AzureRM zum Az-Modul.
Installieren Sie die aktuellen Azure PowerShell-Module, indem Sie die Anweisungen unter Installieren und Konfigurieren von Azure PowerShell befolgen.
Warnung
Wenn Sie nicht die neuesten Versionen von PowerShell und des Data Factory-Moduls verwenden, treten beim Ausführen der Befehle möglicherweise Deserialisierungsfehler auf.
Anmelden an PowerShell
Starten Sie PowerShell auf Ihrem Computer. Lassen Sie PowerShell bis zum Ende dieser Schnellstartanleitung geöffnet. Wenn Sie PowerShell schließen und erneut öffnen, müssen Sie die Befehle erneut ausführen.
Führen Sie den folgenden Befehl aus, und geben Sie den gleichen Azure-Benutzernamen und das gleiche Kennwort ein, die Sie bei der Anmeldung beim Azure-Portal verwendet haben:
Connect-AzAccountFühren Sie den folgenden Befehl aus, um alle Abonnements für dieses Konto anzuzeigen:
Get-AzSubscriptionSollten Ihrem Konto mehrere Azure-Abonnements zugeordnet sein, führen Sie den folgenden Befehl aus, um das zu verwendende Abonnement auszuwählen. Ersetzen Sie SubscriptionId durch die ID Ihres Azure-Abonnements:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"
Erstellen einer Data Factory
Definieren Sie eine Variable für den Ressourcengruppennamen zur späteren Verwendung in PowerShell-Befehlen. Kopieren Sie den folgenden Befehlstext nach PowerShell, geben Sie einen Namen für die Azure-Ressourcengruppe in doppelten Anführungszeichen an, und führen Sie dann den Befehl aus. Beispiel:
"ADFQuickStartRG".$resourceGroupName = "ADFQuickStartRG";Beachten Sie, dass die Ressourcengruppe ggf. nicht überschrieben werden soll, falls sie bereits vorhanden ist. Weisen Sie der Variablen
$ResourceGroupNameeinen anderen Wert zu, und führen Sie den Befehl erneut aus.Führen Sie den folgenden Befehl aus, um die Azure-Ressourcengruppe zu erstellen:
$ResGrp = New-AzResourceGroup $resourceGroupName -location 'East US'Beachten Sie, dass die Ressourcengruppe ggf. nicht überschrieben werden soll, falls sie bereits vorhanden ist. Weisen Sie der Variablen
$ResourceGroupNameeinen anderen Wert zu, und führen Sie den Befehl erneut aus.Definieren Sie eine Variable für den Namen der Data Factory.
Wichtig
Aktualisieren Sie den Data Factory-Namen, damit er global eindeutig ist. Beispiel: ADFTutorialFactorySP1127.
$dataFactoryName = "ADFQuickStartFactory";Führen Sie zum Erstellen der Data Factory das folgende Cmdlet vom Typ Set-AzDataFactoryV2 aus. Verwenden Sie dabei den Standort und die Eigenschaft „ResourceGroupName“ aus der Variablen „$ResGrp“:
$DataFactory = Set-AzDataFactoryV2 -ResourceGroupName $ResGrp.ResourceGroupName ` -Location $ResGrp.Location -Name $dataFactoryName
Beachten Sie folgende Punkte:
Der Name der Azure Data Factory muss global eindeutig sein. Wenn die folgende Fehlermeldung angezeigt wird, ändern Sie den Namen, und wiederholen Sie den Vorgang.
The specified Data Factory name 'ADFv2QuickStartDataFactory' is already in use. Data Factory names must be globally unique.Damit Sie Data Factory-Instanzen erstellen können, muss das Benutzerkonto, mit dem Sie sich bei Azure anmelden, ein Mitglied der Rolle Mitwirkender oder Besitzer oder ein Administrator des Azure-Abonnements sein.
Eine Liste der Azure-Regionen, in denen Data Factory derzeit verfügbar ist, finden Sie, indem Sie die für Sie interessanten Regionen auf der folgenden Seite auswählen und dann Analysen erweitern, um Data Factory zu finden: Verfügbare Produkte nach Region. Die von der Data Factory verwendeten Datenspeicher (Azure Storage, Azure SQL-Datenbank usw.) und Computedienste (HDInsight usw.) können sich in anderen Regionen befinden.
Erstellen eines verknüpften Diensts
Erstellen Sie verknüpfte Dienste in einer Data Factory, um Ihre Datenspeicher und Computedienste mit der Data Factory zu verknüpfen. In dieser Schnellstartanleitung erstellen Sie einen mit Azure Storage verknüpften Dienst, der sowohl als Quellspeicher als auch als Senkenspeicher verwendet wird. Der verknüpfte Dienste enthält die Verbindungsinformationen, die der Data Factory-Dienst zur Laufzeit zur Verbindungsherstellung verwendet.
Tipp
In dieser Schnellstartanleitung verwenden Sie Kontoschlüssel als Authentifizierungstyp für Ihren Datenspeicher, können bei Bedarf aber auch andere unterstützte Authentifizierungsmethoden (SAS-URI, Dienstprinzipal und Verwaltete Identität) auswählen. Ausführlichere Informationen finden Sie in den entsprechenden Abschnitten dieses Artikels. Zum sicheren Speichern von Geheimnissen für Datenspeicher empfiehlt sich darüber hinaus die Verwendung einer Azure Key Vault-Instanz. Eine ausführliche Erläuterung finden Sie in diesem Artikel.
Erstellen Sie im Ordner C:\ADFv2QuickStartPSH eine JSON-Datei mit dem Namen AzureStorageLinkedService.jso und dem unten angegebenen Inhalt: (Erstellen Sie den Ordner „ADFv2QuickStartPSH“, falls er nicht bereits vorhanden ist.)
Wichtig
Ersetzen Sie <accountname> und <accountkey> durch den Namen bzw. Schlüssel Ihres Azure-Speicherkontos, bevor Sie die Datei speichern.
{ "name": "AzureStorageLinkedService", "properties": { "annotations": [], "type": "AzureBlobStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>;EndpointSuffix=core.windows.net" } } }Wählen Sie bei Verwendung des Editors im Dialogfeld Speichern unter für Dateityp die Option Alle Dateien. Andernfalls wird der Datei ggf. die Erweiterung
.txthinzugefügt. Beispiel:AzureStorageLinkedService.json.txt. Wenn Sie die Datei vor dem Öffnen im Editor im Datei-Explorer erstellen, wird die Erweiterung.txtggf. nicht angezeigt, da die Option Erweiterungen bei bekannten Dateitypen ausblenden standardmäßig aktiviert ist. Entfernen Sie die Erweiterung.txt, bevor Sie mit dem nächsten Schritt fortfahren.Wechseln Sie in PowerShell zum Ordner ADFv2QuickStartPSH.
Set-Location 'C:\ADFv2QuickStartPSH'Führen Sie das Cmdlet Set-AzDataFactoryV2LinkedService aus, um den verknüpften Dienst zu erstellen: AzureStorageLinkedService.
Set-AzDataFactoryV2LinkedService -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName -Name "AzureStorageLinkedService" ` -DefinitionFile ".\AzureStorageLinkedService.json"Hier ist die Beispielausgabe:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobStorageLinkedService
Erstellen von Datasets
In diesem Verfahren erstellen Sie zwei Datasets: InputDataset und OutputDataset. Diese Datasets sind vom Typ Binär. Sie verweisen auf den mit Azure Storage verknüpften Dienst, den Sie im vorherigen Abschnitt erstellt haben. Das Eingabedataset stellt die Quelldaten im Eingabeordner dar. In der Definition des Eingabedatasets geben Sie den Blobcontainer (adftutorial), den Ordner (input) und die Datei (emp.txt) mit den Quelldaten an. Das Ausgabedataset stellt die Daten dar, die zum Ziel kopiert werden. In der Definition des Ausgabedatasets geben Sie den Blobcontainer (adftutorial), den Ordner (output) und die Datei an, in die die Daten kopiert werden.
Erstellen Sie im Ordner C:\ADFv2QuickStartPSH eine JSON-Datei mit dem Namen InputDataset.json und dem folgenden Inhalt:
{ "name": "InputDataset", "properties": { "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" }, "annotations": [], "type": "Binary", "typeProperties": { "location": { "type": "AzureBlobStorageLocation", "fileName": "emp.txt", "folderPath": "input", "container": "adftutorial" } } } }Führen Sie zum Erstellen des Datasets InputDataset das Cmdlet Set-AzDataFactoryV2Dataset aus.
Set-AzDataFactoryV2Dataset -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName -Name "InputDataset" ` -DefinitionFile ".\InputDataset.json"Hier ist die Beispielausgabe:
DatasetName : InputDataset ResourceGroupName : <resourceGroupname> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.BinaryDatasetWiederholen Sie die Schritte zum Erstellen des Ausgabedatasets. Erstellen Sie im Ordner C:\ADFv2QuickStartPSH eine JSON-Datei mit dem Namen OutputDataset.json und dem folgenden Inhalt:
{ "name": "OutputDataset", "properties": { "linkedServiceName": { "referenceName": "AzureStorageLinkedService", "type": "LinkedServiceReference" }, "annotations": [], "type": "Binary", "typeProperties": { "location": { "type": "AzureBlobStorageLocation", "folderPath": "output", "container": "adftutorial" } } } }Führen Sie das Cmdlet Set-AzDataFactoryV2Dataset aus, um OutDataset zu erstellen:
Set-AzDataFactoryV2Dataset -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName -Name "OutputDataset" ` -DefinitionFile ".\OutputDataset.json"Hier ist die Beispielausgabe:
DatasetName : OutputDataset ResourceGroupName : <resourceGroupname> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.BinaryDataset
Erstellen einer Pipeline
In diesem Schritt erstellen Sie eine Pipeline mit einer Copy-Aktivität, die das Eingabe- und Ausgabedataset verwendet. Die Copy-Aktivität kopiert Daten aus der in den Einstellungen des Eingabedatasets angegebenen Datei in die Datei, die in den Einstellungen des Ausgabedatasets angegeben ist.
Erstellen Sie im Ordner C:\ADFv2QuickStartPSH eine JSON-Datei mit dem Namen Adfv2QuickStartPipeline.json und dem folgenden Inhalt:
{ "name": "Adfv2QuickStartPipeline", "properties": { "activities": [ { "name": "CopyFromBlobToBlob", "type": "Copy", "dependsOn": [], "policy": { "timeout": "7.00:00:00", "retry": 0, "retryIntervalInSeconds": 30, "secureOutput": false, "secureInput": false }, "userProperties": [], "typeProperties": { "source": { "type": "BinarySource", "storeSettings": { "type": "AzureBlobStorageReadSettings", "recursive": true } }, "sink": { "type": "BinarySink", "storeSettings": { "type": "AzureBlobStorageWriteSettings" } }, "enableStaging": false }, "inputs": [ { "referenceName": "InputDataset", "type": "DatasetReference" } ], "outputs": [ { "referenceName": "OutputDataset", "type": "DatasetReference" } ] } ], "annotations": [] } }Führen Sie zum Erstellen der Pipeline Adfv2QuickStartPipeline das Cmdlet Set-AzDataFactoryV2Pipeline aus.
$DFPipeLine = Set-AzDataFactoryV2Pipeline ` -DataFactoryName $DataFactory.DataFactoryName ` -ResourceGroupName $ResGrp.ResourceGroupName ` -Name "Adfv2QuickStartPipeline" ` -DefinitionFile ".\Adfv2QuickStartPipeline.json"
Erstellen einer Pipelineausführung
In diesem Schritt erstellen Sie eine Pipelineausführung.
Führen Sie das Cmdlet Invoke-AzDataFactoryV2Pipeline aus, um eine Pipelineausführung zu erstellen. Das Cmdlet gibt die ID der Pipelineausführung für die zukünftige Überwachung zurück.
$RunId = Invoke-AzDataFactoryV2Pipeline `
-DataFactoryName $DataFactory.DataFactoryName `
-ResourceGroupName $ResGrp.ResourceGroupName `
-PipelineName $DFPipeLine.Name
Überwachen der Pipelineausführung
Führen Sie das folgende PowerShell-Skript aus, um den Status der Pipelineausführung kontinuierlich zu überwachen, bis das Kopieren der Daten beendet ist. Kopieren Sie das folgende Skript, fügen Sie es in das PowerShell-Fenster ein, und drücken Sie die EINGABETASTE.
while ($True) { $Run = Get-AzDataFactoryV2PipelineRun ` -ResourceGroupName $ResGrp.ResourceGroupName ` -DataFactoryName $DataFactory.DataFactoryName ` -PipelineRunId $RunId if ($Run) { if ( ($Run.Status -ne "InProgress") -and ($Run.Status -ne "Queued") ) { Write-Output ("Pipeline run finished. The status is: " + $Run.Status) $Run break } Write-Output ("Pipeline is running...status: " + $Run.Status) } Start-Sleep -Seconds 10 }Hier ist die Beispielausgabe der Pipelineausführung:
Pipeline is running...status: InProgress Pipeline run finished. The status is: Succeeded ResourceGroupName : ADFQuickStartRG DataFactoryName : ADFQuickStartFactory RunId : 00000000-0000-0000-0000-0000000000000 PipelineName : Adfv2QuickStartPipeline LastUpdated : 8/27/2019 7:23:07 AM Parameters : {} RunStart : 8/27/2019 7:22:56 AM RunEnd : 8/27/2019 7:23:07 AM DurationInMs : 11324 Status : Succeeded Message :Führen Sie das folgende Skript aus, um Ausführungsdetails zur Kopieraktivität abzurufen, z.B. die Größe der gelesenen/geschriebenen Daten.
Write-Output "Activity run details:" $Result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $DataFactory.DataFactoryName -ResourceGroupName $ResGrp.ResourceGroupName -PipelineRunId $RunId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) $Result Write-Output "Activity 'Output' section:" $Result.Output -join "`r`n" Write-Output "Activity 'Error' section:" $Result.Error -join "`r`n"Vergewissern Sie sich, dass die Ausgabe ähnlich aussieht wie die folgende Beispielausgabe des Ergebnisses einer Aktivitätsausführung:
ResourceGroupName : ADFQuickStartRG DataFactoryName : ADFQuickStartFactory ActivityRunId : 00000000-0000-0000-0000-000000000000 ActivityName : CopyFromBlobToBlob PipelineRunId : 00000000-0000-0000-0000-000000000000 PipelineName : Adfv2QuickStartPipeline Input : {source, sink, enableStaging} Output : {dataRead, dataWritten, filesRead, filesWritten...} LinkedServiceName : ActivityRunStart : 8/27/2019 7:22:58 AM ActivityRunEnd : 8/27/2019 7:23:05 AM DurationInMs : 6828 Status : Succeeded Error : {errorCode, message, failureType, target} Activity 'Output' section: "dataRead": 20 "dataWritten": 20 "filesRead": 1 "filesWritten": 1 "sourcePeakConnections": 1 "sinkPeakConnections": 1 "copyDuration": 4 "throughput": 0.01 "errors": [] "effectiveIntegrationRuntime": "DefaultIntegrationRuntime (Central US)" "usedDataIntegrationUnits": 4 "usedParallelCopies": 1 "executionDetails": [ { "source": { "type": "AzureBlobStorage" }, "sink": { "type": "AzureBlobStorage" }, "status": "Succeeded", "start": "2019-08-27T07:22:59.1045645Z", "duration": 4, "usedDataIntegrationUnits": 4, "usedParallelCopies": 1, "detailedDurations": { "queuingDuration": 3, "transferDuration": 1 } } ] Activity 'Error' section: "errorCode": "" "message": "" "failureType": "" "target": "CopyFromBlobToBlob"
Überprüfen der bereitgestellten Ressourcen
Die Pipeline erstellt den Ausgabeordner automatisch im Blobcontainer „adftutorial“. Anschließend wird die Datei „emp.txt“ aus dem Eingabe- in den Ausgabeordner kopiert.
Wählen Sie im Azure-Portal auf der Seite des Containers adftutorial die Option Aktualisieren aus, um den Ausgabeordner anzuzeigen.
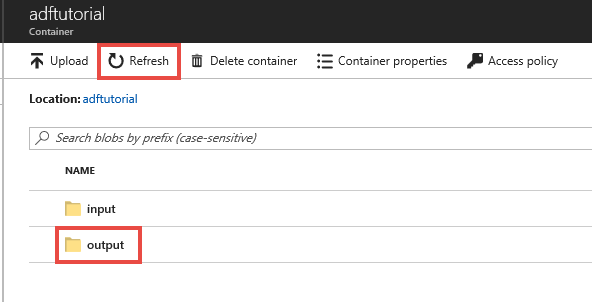
Wählen Sie in der Ordnerliste output aus.
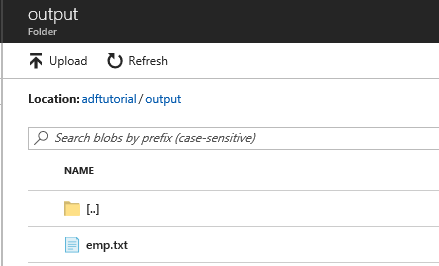
Überprüfen Sie, ob die Datei emp.txt in den Ausgabeordner kopiert wurde.
Bereinigen von Ressourcen
Die im Rahmen dieser Schnellstartanleitung erstellten Ressourcen können auf zwei Arten bereinigt werden. Sie können die Azure-Ressourcengruppe einschließlich aller darin enthaltenen Ressourcen löschen. Falls die anderen Ressourcen erhalten bleiben sollen, löschen Sie nur die Data Factory, die Sie in diesem Tutorial erstellt haben.
Wenn Sie eine Ressourcengruppe löschen, werden alle Ressourcen einschließlich enthaltener Data Factorys gelöscht. Führen Sie den folgenden Befehl aus, um die gesamte Ressourcengruppe zu löschen:
Remove-AzResourceGroup -ResourceGroupName $resourcegroupname
Hinweis
Das Löschen einer Ressourcengruppe kann einige Zeit in Anspruch nehmen. Bitte haben Sie etwas Geduld.
Wenn Sie nur die Data Factory und nicht die gesamte Ressourcengruppe löschen möchten, führen Sie den folgenden Befehl aus:
Remove-AzDataFactoryV2 -Name $dataFactoryName -ResourceGroupName $resourceGroupName
Zugehöriger Inhalt
Die Pipeline in diesem Beispiel kopiert Daten in einem Azure Blob Storage von einem Speicherort in einen anderen. Arbeiten Sie die Tutorials durch, um zu erfahren, wie Sie Data Factory in anderen Szenarien verwenden können.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für