Verwenden von Spark- und Hive-Tools für Visual Studio Code
Erfahren Sie, wie Sie Apache Spark- und Hive-Tools für Visual Studio Code verwenden. Verwenden Sie die Tools zum Erstellen und Übermitteln von Batchaufträgen für Apache Hive, interaktiven Hive-Abfragen und PySpark-Skripts für Apache Spark. Zunächst wird beschrieben, wie Sie Spark- und Hive-Tools in Visual Studio Code installieren. Anschließend werden die Schritte zum Übermitteln von Aufträgen an Spark- und Hive-Tools erläutert.
Spark- und Hive-Tools können auf allen von Visual Studio Code unterstützten Plattformen installiert werden. Die folgenden Voraussetzungen gelten für die verschiedenen Plattformen.
Voraussetzungen
Die folgenden Elemente sind zum Ausführen der Schritte in diesem Artikel erforderlich:
- Ein Azure HDInsight-Cluster. Informationen zum Erstellen eines Clusters finden Sie unter Hadoop-Tutorial: Erste Schritte bei der Verwendung von Hadoop in HDInsight. Alternativ können Sie einen Spark- und Hive-Cluster verwenden, der einen Apache Livy-Endpunkt unterstützt.
- Visual Studio Code
- Mono. Mono wird nur für Linux und macOS benötigt.
- Eine interaktive PySpark-Umgebung für Visual Studio Code.
- Ein lokales Verzeichnis. In diesem Artikel wird das Verzeichnis C:\HD\HDexample verwendet.
Installieren von Spark & Hive Tools
Wenn die Voraussetzungen erfüllt sind, können Sie Spark- und Hive-Tools für Visual Studio Code installieren, indem Sie die folgenden Schritte ausführen:
Öffnen Sie Visual Studio Code.
Navigieren Sie über die Menüleiste zu Ansicht>Erweiterungen.
Geben Sie Spark & Hive in das Suchfeld ein.
Wählen Sie in den Suchergebnissen Spark & Hive Tools aus, und wählen Sie dann Installieren aus:

Wählen Sie bei Bedarf Erneut laden aus.
Öffnen eines Arbeitsordners
Um einen Arbeitsordner zu öffnen und eine Datei in Visual Studio Code zu erstellen, führen Sie die folgenden Schritte aus:
Navigieren Sie auf der Menüleiste zu Datei>Ordner öffnen...>C:\HD\HDexample, und klicken Sie dann auf die Schaltfläche Ordner auswählen. Daraufhin wird der Ordner links in der Ansicht Explorer angezeigt.
Wählen Sie in der Explorer-Ansicht den Ordner HDexample aus, und wählen Sie dann neben dem Arbeitsordner das Symbol Neue Datei aus:

Benennen Sie die neue Datei mit der Dateierweiterung
.hql(Hive-Abfragen) oder.py(Spark-Skript). In diesem Beispiel wird HelloWorld.hql verwendet.
Einrichten der Azure-Umgebung
Führen Sie für Benutzer der nationalen Cloud diese Schritte aus, um zunächst die Azure-Umgebung festzulegen, und verwenden Sie anschließend den Befehl Azure: Anmelden, um sich bei Azure anzumelden:
Navigieren Sie zu Datei>Einstellungen>Einstellungen.
Suchen Sie nach folgender Zeichenfolge: Azure: Cloud.
Wählen Sie in der Liste die nationale Cloud aus:

Verbinden mit einem Azure-Konto
Bevor Sie Skripts aus Visual Studio Code an Ihre Cluster übermitteln können, können sich Benutzer entweder beim Azure-Abonnement anmelden oder einen HDInsight-Cluster verknüpfen. Verwenden Sie zum Herstellen einer Verbindung mit Ihrem HDInsight-Cluster den Ambari-Benutzernamen mit dem zugehörigen Kennwort oder die in eine Domäne eingebundenen Anmeldeinformationen für das ESP-Cluster. Führen Sie diese Schritte aus, um eine Verbindung mit Azure herzustellen:
Navigieren Sie auf der Menüleiste zu Ansicht>Befehlspalette... , und geben Sie Azure: Anmelden ein:

Befolgen Sie die Anleitung für die Anmeldung, um sich bei Azure anzumelden. Nach dem Herstellen der Verbindung wird Ihr Azure-Kontoname unten im Visual Studio Code-Fenster in der Statusleiste angezeigt.
Verknüpfen eines Clusters
Verknüpfung: Azure HDInsight
Sie können einen normalen Cluster verknüpfen, indem Sie einen von Apache Ambari verwalteten Benutzernamen verwenden, oder Sie können einen per Enterprise Security Pack geschützten Hadoop-Cluster verknüpfen, indem Sie einen Domänenbenutzernamen (z.B. user1@contoso.com) verwenden.
Navigieren Sie auf der Menüleiste zu Ansicht>Befehlspalette... , und geben Sie Spark/Hive: Link a Cluster (Spark / Hive: Cluster verknüpfen) ein.

Wählen Sie als Typ des verknüpften Clusters Azure HDInsight aus.
Geben Sie die HDInsight-Cluster-URL ein.
Geben Sie Ihren Ambari-Benutzernamen ein. Der Standardname ist admin.
Geben Sie Ihr Ambari-Kennwort ein.
Wählen Sie den Clustertyp aus.
Legen Sie den Anzeigenamen des Clusters fest (optional).
Überprüfen Sie die Ausgabe.
Hinweis
Der verknüpfte Benutzername und das verknüpfte Kennwort werden verwendet, wenn der Cluster beim Azure-Abonnement angemeldet ist und einen Cluster verknüpft hat.
Verknüpfung: Generic Livy Endpoint (Generischer Livy-Endpunkt)
Navigieren Sie auf der Menüleiste zu Ansicht>Befehlspalette... , und geben Sie Spark/Hive: Link a Cluster (Spark / Hive: Cluster verknüpfen) ein.
Wählen Sie als Typ des verknüpften Clusters Generic Livy Endpoint (Generischer Livy-Endpunkt) aus.
Geben Sie den generischen Livy-Endpunkt ein. Beispiel: http://10.172.41.42:18080.
Wählen Sie als Autorisierungstyp Standard oder Keine aus. Wenn Sie Standard auswählen:
Geben Sie Ihren Ambari-Benutzernamen ein. Der Standardname ist admin.
Geben Sie Ihr Ambari-Kennwort ein.
Überprüfen Sie die Ausgabe.
Auflisten der Cluster
Navigieren Sie auf der Menüleiste zu Ansicht>Befehlspalette... , und geben Sie Spark/Hive: List Cluster (Spark / Hive: Cluster auflisten).
Wählen Sie das gewünschte Abonnement aus.
Überprüfen Sie die Ansicht Ausgabe. Diese Ansicht zeigt Ihre verknüpften Cluster und alle Cluster in Ihrem Azure-Abonnement:

Festlegen des Standardclusters
Öffnen Sie den Ordner HDexample, der weiter oben erläutert ist, erneut (sofern er geschlossen ist).
Wählen Sie die Datei HelloWorld.hql aus, die zuvor erstellt wurde. Sie wird im Skript-Editor geöffnet.
Klicken Sie mit der rechten Maustaste auf den Skript-Editor, und wählen Sie dann Spark / Hive: Set Default Cluster (Spark / Hive: Standardcluster festlegen) aus.
Stellen Sie eine Verbindung mit Ihrem Azure-Konto her, oder verknüpfen Sie einen Cluster, sofern dies noch nicht erfolgt ist.
Legen Sie einen Cluster als Standardcluster für die aktuelle Skriptdatei fest. Die Tools aktualisieren die Konfigurationsdatei .VSCode\settings.json automatisch:

Übermitteln von interaktiven Hive-Abfragen und von Hive-Batchskripts
Mit Spark- und Hive-Tools für Visual Studio Code können Sie interaktive Hive-Abfragen und Hive-Batchskripts an Ihre Cluster übermitteln.
Öffnen Sie den Ordner HDexample, der weiter oben erläutert ist, erneut (sofern er geschlossen ist).
Wählen Sie die Datei HelloWorld.hql aus, die zuvor erstellt wurde. Sie wird im Skript-Editor geöffnet.
Kopieren Sie den folgenden Code, fügen Sie ihn in Ihre Hive-Datei ein, und speichern Sie diese dann:
SELECT * FROM hivesampletable;Stellen Sie eine Verbindung mit Ihrem Azure-Konto her, oder verknüpfen Sie einen Cluster, sofern dies noch nicht erfolgt ist.
Klicken Sie mit der rechten Maustaste auf den Skript-Editor, und wählen Sie Hive: Interactive aus, um die Abfrage zu übermitteln, oder verwenden Sie die Tastenkombination STRG+ALT+I. Wählen Sie Hive: Batch aus, um das Skript zu übermitteln, oder verwenden Sie die Tastenkombination STRG+ALT+H.
Wenn Sie keinen Standardcluster angegeben haben, wählen Sie einen Cluster aus. Die Tools unterstützen es auch, dass Sie über das Kontextmenü einen Codeblock anstelle der gesamten Skriptdatei übermitteln. Nach kurzer Zeit werden die Abfrageergebnisse auf einer neuen Registerkarte angezeigt:

Bereich ERGEBNISSE: Sie können das gesamte Ergebnis als CSV-, JSON- oder Excel-Datei in einem lokalen Pfad speichern oder einfach mehrere Zeilen auswählen.
Bereich MELDUNGEN: Wenn Sie eine Zeilennummer auswählen, gelangen Sie zur ersten Zeile des Skripts, das derzeit ausgeführt wird.
Übermitteln interaktiver PySpark-Abfragen
Voraussetzung für interaktives Pyspark
Beachten Sie hier, dass die Jupyter-Erweiterungsversion (ms-jupyter) v2022.1.1001614873 und die Python-Erweiterungsversion (ms-python) v2021.12.1559732655 sowie Python 3.6.x und 3.7.x für interaktive HDInsight-PySpark-Abfragen erforderlich sind.
Benutzer können interaktive PySpark-Abfragen wie folgt ausführen.
Mithilfe des interaktiven PySpark-Befehls in einer PY-Datei
Gehen Sie wie folgt vor, um die Abfragen mithilfe des interaktiven PySpark-Befehls zu übermitteln:
Öffnen Sie den Ordner HDexample, der weiter oben erläutert ist, erneut (sofern er geschlossen ist).
Erstellen Sie mit den zuvor erläuterten Schritten eine neue HelloWorld.py-Datei.
Kopieren Sie den folgenden Code, und fügen Sie ihn in die Skriptdatei ein:
from operator import add from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName('hdisample') \ .getOrCreate() lines = spark.read.text("/HdiSamples/HdiSamples/FoodInspectionData/README").rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) coll = counters.collect() sortedCollection = sorted(coll, key = lambda r: r[1], reverse = True) for i in range(0, 5): print(sortedCollection[i])Die Aufforderung, den PySpark/Synapse PySpark-Kernel zu installieren, wird unten rechts im Fenster angezeigt. Sie können auf Install (Installieren) klicken, um mit der PySpark/Synapse PySpark-Installation fortzufahren, oder auf Skip (Überspringen), um diesen Schritt auszulassen.

Wenn Sie es später installieren müssen, können Sie zu Datei>Einstellung>Einstellungen navigieren und HDInsight: Enable Skip PySpark Installation (HDInsight: Überspringen der PySpark-Installation aktivieren) in den Einstellungen deaktivieren.

Wenn die Installation in Schritt 4 erfolgreich war, wird das Nachrichtenfeld „PySpark installed successfully“ (PySpark erfolgreich installiert) in der unteren rechten Ecke des Fensters angezeigt. Klicken Sie auf Erneut laden, um das Fenster neu zu laden.

Navigieren Sie in der Menüleiste zu View>Command Palette... (Ansicht > Befehlspalette...), oder verwenden Sie die Tastenkombination UMSCHALT+STRG+P, und geben Sie Python: Select Interpreter to start Jupyter Server (Interpreter auswählen, um Jupyter-Server zu starten) ein.

Wählen Sie unten die Python-Option aus.

Navigieren Sie in der Menüleiste zu View>Command Palette... (Ansicht > Befehlspalette...), oder verwenden Sie die Tastenkombination UMSCHALT+STRG+P, und geben Sie Developer: Fenster neu laden ein.

Stellen Sie eine Verbindung mit Ihrem Azure-Konto her, oder verknüpfen Sie einen Cluster, sofern dies noch nicht erfolgt ist.
Wählen Sie den gesamten Code aus, klicken Sie mit der rechten Maustaste auf den Skript-Editor, und wählen Sie Spark: PySpark Interactive/Synapse: PySpark Interactive aus, um die Abfrage zu übermitteln.

Wählen Sie den Cluster aus, wenn Sie keinen Standardcluster angegeben haben. Nach kurzer Zeit werden die Python Interactive-Ergebnisse in einer neuen Registerkarte angezeigt. Klicken Sie auf PySpark, um den Kernel auf PySpark/Synapse Pyspark umzustellen. Anschließend wird der Code erfolgreich ausgeführt. Wenn Sie zum Synapse PySpark-Kernel wechseln möchten, empfehlen wir Ihnen, die automatischen Einstellungen im Azure-Portal zu deaktivieren. Andernfalls kann es sehr lange dauern, den Cluster zu aktivieren und den Synapse-Kernel für die erstmalige Verwendung festzulegen. Die Tools unterstützen es auch, dass Sie über das Kontextmenü einen Codeblock anstelle der gesamten Skriptdatei übermitteln:

Geben Sie %%info ein, und drücken Sie dann UMSCHALT+EINGABETASTE, um die Auftragsinformationen anzuzeigen (optional):

Das Tool unterstützt auch die Spark SQL-Abfrage:

Ausführen einer interaktiven Abfrage in der PY-Datei mithilfe des Kommentars #%%
Fügen Sie #%% vor dem Py-Code hinzu, um zur Notebook-Oberfläche zu wechseln.

Klicken Sie auf Zelle ausführen. Nach kurzer Zeit werden die Python Interactive-Ergebnisse auf einer neuen Registerkarte angezeigt. Klicken Sie auf PySpark, um den Kernel auf PySpark/Synapse PySpark umzustellen. Wenn Sie anschließend erneut auf Zelle ausführen klicken, ist die Ausführung erfolgreich.

Nutzen der IPYNB-Unterstützung über die Python-Erweiterung
Sie können eine Jupyter Notebook-Instanz per Befehl über die Befehlspalette oder durch Erstellen einer neuen IPYNB-Datei in Ihrem Arbeitsbereich erstellen. Weitere Informationen finden Sie unter Arbeiten mit Jupyter Notebook in Visual Studio Code.
Klicken Sie auf Zelle ausführen, folgen Sie den Aufforderungen bis zu Set the default spark pool (Spark-Standardpool festlegen) (das Festlegen des Standardclusters/-pools vor dem Öffnen eines Notebooks ist dringend zu empfehlen), und wählen Sie dann Neu laden aus, um das Fenster neu zu laden.

Klicken Sie auf PySpark, um den Kernel auf PySpark/Synapse PySpark umzustellen, und klicken Sie dann auf Zelle ausführen. Nach einer Weile wird das Ergebnis angezeigt.

Hinweis
Bei Synapse PySpark-Installationsfehlern wird die Abhängigkeit nicht mehr von anderen Teams und so auch generell nicht mehr verwaltet. Wenn Sie versuchen, Synapse Pyspark interaktiv zu verwenden, wechseln Sie stattdessen zu Azure Synapse Analytics. Dies ist eine langfristige Änderung.
Übermitteln von PySpark-Batchaufträgen
Öffnen Sie den Ordner HDexample, der weiter oben erläutert ist, erneut (sofern er geschlossen ist).
Erstellen Sie mit den zuvor erläuterten Schritten eine neue BatchFile.py-Datei.
Kopieren Sie den folgenden Code, und fügen Sie ihn in die Skriptdatei ein:
from __future__ import print_function import sys from operator import add from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() lines = spark.read.text('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv').rdd.map(lambda r: r[0]) counts = lines.flatMap(lambda x: x.split(' '))\ .map(lambda x: (x, 1))\ .reduceByKey(add) output = counts.collect() for (word, count) in output: print("%s: %i" % (word, count)) spark.stop()Stellen Sie eine Verbindung mit Ihrem Azure-Konto her, oder verknüpfen Sie einen Cluster, sofern dies noch nicht erfolgt ist.
Klicken Sie mit der rechten Maustaste in den Skript-Editor, und wählen Sie dann Spark: PySpark-Batch oder Synapse: PySpark-Batch* aus.
Wählen Sie einen Cluster/Spark-Pool aus, an den Ihr PySpark-Auftrag übermittelt werden soll:

Nachdem Sie einen Python-Auftrag übermittelt haben, werden Übermittlungsprotokolle im Ausgabefenster in Visual Studio Code angezeigt. Die URL der Spark-Benutzeroberfläche und die URL der Yarn-Benutzeroberfläche werden ebenfalls angezeigt. Wenn Sie den Batchauftrag an einen Apache Spark-Pool übermitteln, werden die URL der Spark-Verlaufsoberfläche und die URL der Benutzeroberfläche der Spark-Auftragsanwendung ebenfalls angezeigt. Sie können die URL in einem Webbrowser öffnen, um den Status des Auftrags zu verfolgen.
Integrieren in den HDInsight-Identitätsbroker (HIB)
Herstellen einer Verbindung mit Ihrem HDInsight ESP-Cluster mit Identitätsbroker (HIB)
Sie können die normalen Schritte zum Anmelden beim Azure-Abonnement ausführen, um eine Verbindung mit Ihrem HDInsight ESP-Cluster mit Identitätsbroker (HIB) herzustellen. Nach der Anmeldung wird die Clusterliste im Azure Explorer angezeigt. Weitere Anweisungen finden Sie unter Herstellen einer Verbindung mit Ihrem HDInsight-Cluster.
Ausführen eines Hive-/PySpark-Auftrags in einem ESP-Cluster in HDInsight mit Identitätsbroker (HIB)
Zum Ausführen eines Hive-Auftrags können Sie die normalen Schritte ausführen, um einen Auftrag an einen HDInsight-ESP-Cluster mit Identitätsbroker zu übermitteln. Weitere Informationen finden Sie unter Übermitteln von interaktiven Hive-Abfragen und Hive-Batchskripts.
Zum Ausführen eines interaktiven PySpark-Auftrags können Sie die normalen Schritte ausführen, um einen Auftrag an einen HDInsight ESP-Cluster mit dem Identitätsbroker (HIB) zu übermitteln. Weitere Informationen finden Sie unter „Übermitteln interaktiver PySpark-Abfragen“.
Zum Ausführen eines PySpark-Batchauftrags können Sie die normalen Schritte ausführen, um einen Auftrag an einen HDInsight-ESP-Cluster mit Identitätsbroker zu übermitteln. Weitere Informationen finden Sie unter Übermitteln von PySpark-Batchaufträgen.
Apache Livy-Konfiguration
Die Apache Livy-Konfiguration wird unterstützt. Sie können Sie in der Datei .VSCode\settings.json im Arbeitsbereichsordner konfigurieren. Derzeit wird in der Livy-Konfiguration nur das Python-Skript unterstützt. Weitere Informationen finden Sie in der Livy-Infodatei.
Auslösen der Livy-Konfiguration
Methode 1
- Navigieren Sie in der Menüleiste zu Datei>Einstellungen>Einstellungen.
- Geben Sie in das Feld Sucheinstellungen die Zeichenfolge HDInsight Job Submission: Livy Conf (HDInsight-Auftragsübermittlung: Livy-Konfiguration) ein.
- Klicken Sie beim relevanten Suchergebnis auf In „settings.json“ bearbeiten.
Methode 2
Übermitteln Sie eine Datei. Daraufhin wird der Ordner .vscode automatisch dem Arbeitsordner hinzugefügt. Sie können die Livy-Konfiguration anzeigen, indem Sie .vscode\settings.json auswählen.
Die Projekteinstellungen:

Hinweis
Legen Sie für die Einstellungen driverMemory und executorMemory den Wert und die Einheit fest. Beispiel: 1g oder 1024m.
Unterstützte Livy-Konfigurationen:
POST /batches
Anforderungstext
name description type file Die Datei, die die auszuführende Anwendung enthält Pfad (erforderlich) proxyUser Der Benutzer, dessen Identität beim Ausführen des Auftrags angenommen werden soll String className Die Java-/Spark-Hauptklasse der Anwendung String args Die Befehlszeilenargumente für die Anwendung Liste von Zeichenfolgen jars JAR-Dateien, die in dieser Sitzung verwendet werden Liste von Zeichenfolgen pyFiles Die Python-Dateien, die in dieser Sitzung verwendet werden sollen Liste von Zeichenfolgen files Dateien, die in dieser Sitzung verwendet werden Liste von Zeichenfolgen driverMemory Die Menge an Arbeitsspeicher, die für den Treiberprozess verwendet werden soll String driverCores Die Anzahl der Kerne, die für den Treiberprozess verwendet werden soll Int executorMemory Die Menge an Arbeitsspeicher, die pro Executorprozess verwendet werden soll String executorCores Die Anzahl von Kernen, die für jeden Executor verwendet werden sollen Int numExecutors Die Anzahl der Executors, die für diese Sitzung gestartet werden sollen Int archives Die Archive, die in dieser Sitzung verwendet werden sollen Liste von Zeichenfolgen queue Der Name der YARN-Warteschlange, an die gesendet wird String name Der Name dieser Sitzung String conf Spark-Konfigurationseigenschaften Zuordnung von Schlüsseln zu Werten Antworttext Das erstellte Batchobjekt.
name description type id Sitzungs-ID Int appId Die Anwendungs-ID dieser Sitzung String appInfo Detaillierte Anwendungsinformationen Zuordnung von Schlüsseln zu Werten log Protokollzeilen Liste von Zeichenfolgen state Batchstatus String Hinweis
Die zugewiesene Livy-Konfiguration wird im Ausgabebereich angezeigt, wenn Sie das Skript übermitteln.
Integration mit Azure HDInsight per Explorer
Sie können eine Vorschau der Hive-Tabelle in Ihren Clustern direkt über den Azure HDInsight-Explorer anzeigen:
Stellen Sie eine Verbindung mit Ihrem Azure-Konto her, sofern noch keine Verbindung besteht.
Wählen Sie das Azure-Symbol in der äußerst linken Spalte aus.
Erweitern Sie im linken Bereich AZURE: HDINSIGHT. Die verfügbaren Abonnements und Cluster werden aufgelistet.
Erweitern Sie den Cluster, um die Hive-Metadatendatenbank und das Hive-Tabellenschema anzuzeigen.
Klicken Sie mit der rechten Maustaste auf die Hive-Tabelle. Zum Beispiel: hivesampletable. Wählen Sie Vorschau aus.

Das Fenster Ergebnisvorschau wird geöffnet:

Bereich ERGEBNISSE
Sie können das gesamte Ergebnis als CSV-, JSON- oder Excel-Datei in einem lokalen Pfad speichern, oder wählen Sie einfach mehrere Zeilen aus.
Bereich MELDUNGEN
Wenn die Tabelle mehr als 100 Zeilen enthält, sehen Sie die folgende Meldung: „Die ersten 100 Zeilen werden für die Hive-Tabelle angezeigt.“
Wenn die Tabelle bis zu 100 Zeilen enthält, sehen Sie die folgende Meldung: „60 Zeilen werden für die Hive-Tabelle angezeigt.“
Wenn die Tabelle keine Zeilen enthält, sehen Sie die folgende Meldung: „
0 rows are displayed for Hive table.“Hinweis
Installieren Sie unter Linux xclip, um das Kopieren von Tabellendaten zu ermöglichen.

Zusätzliche Funktionen
Spark und Hive für Visual Studio Code unterstützt auch die folgenden Features:
Die automatische Vervollständigung von IntelliSense: Es werden Vorschläge für Schlüsselwörter, Methoden, Variablen und weitere Programmierelemente aufgelistet. Die unterschiedlichen Objekttypen werden durch entsprechende Symbole dargestellt:

IntelliSense-Fehlermarkierung: Der Sprachdienst unterstreicht Bearbeitungsfehler im Hive-Skript.
Syntaxhervorhebungen: Der Sprachdienst verwendet verschiedene Farben, um Variablen, Schlüsselwörter, Datentypen, Funktionen und weitere Programmierelemente zu unterscheiden:

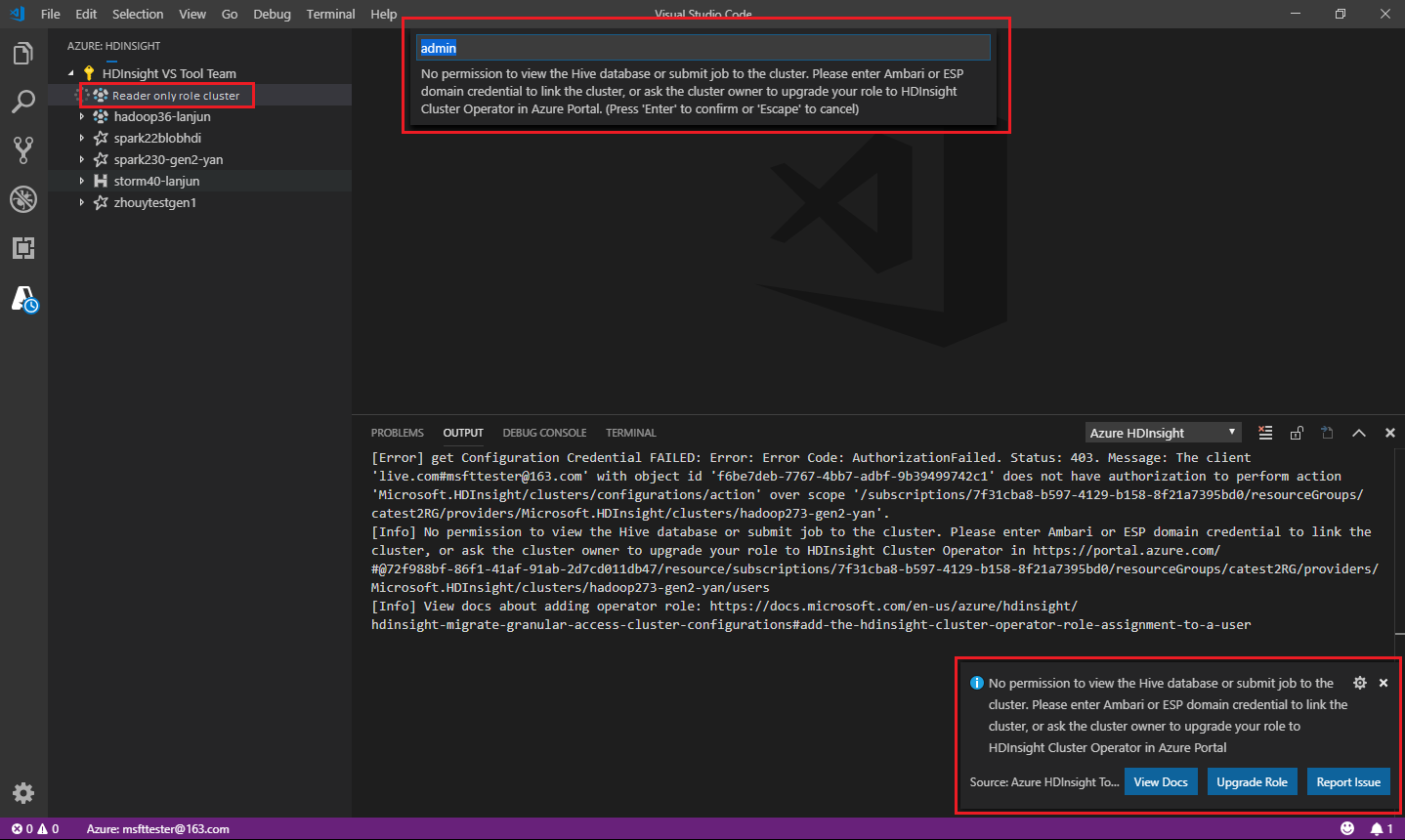
Rolle nur mit Leseberechtigung
Benutzer, denen für den Cluster die Rolle „Nur Leser“ (reader-only) zugewiesen ist, können keine Aufträge an den HDInsight-Cluster übermitteln und die Hive-Datenbank nicht anzeigen. Wenden Sie sich an den Clusteradministrator, damit Ihre Rolle im Azure-Portal auf HDInsight-Clusteroperator aktualisiert wird. Wenn Sie gültige Ambari-Anmeldeinformationen haben, können Sie manuell mit dem Cluster verknüpfen, indem Sie die weiter unten aufgeführten Anweisungen ausführen.
Durchsuchen des HDInsight-Clusters
Wenn Sie im Azure HDInsight-Explorer einen HDInsight-Cluster auswählen, um diesen zu erweitern, werden Sie zum Verknüpfen mit dem Cluster aufgefordert, wenn Sie für den Cluster die Rolle „Nur Leser“ haben. Verwenden Sie die folgende Methode, um über Ihre Ambari-Anmeldeinformationen die Verknüpfung mit dem Cluster herzustellen.
Übermitteln des Auftrags an den HDInsight-Cluster
Wenn Sie für den Cluster die Rolle „Nur Leser“ haben und einen Auftrag an den HDInsight-Cluster übermitteln, werden Sie aufgefordert, mit dem Cluster zu verknüpfen. Führen Sie die folgenden Schritte aus, um über die Ambari-Anmeldeinformationen die Verknüpfung mit dem Cluster herzustellen.
Verknüpfen mit dem Cluster
Geben Sie einen gültigen Ambari-Benutzernamen ein.
Geben Sie ein gültiges Kennwort ein.

Hinweis
Sie können
Spark / Hive: List Clusterverwenden, um den verknüpften Cluster zu überprüfen:
Azure Data Lake Storage Gen2
Durchsuchen eines Data Lake Storage Gen2-Kontos
Wählen Sie Azure HDInsight-Explorer aus, um ein Data Lake Storage Gen2-Konto zu erweitern. Sie werden aufgefordert, den Speicherzugriffsschlüssel einzugeben, wenn Ihr Azure-Konto keinen Zugriff auf den Gen2-Speicher hat. Sobald der Zugriffsschlüssel validiert ist, wird das Data Lake Storage Gen2-Konto automatisch erweitert.
Übermitteln von Aufträgen an einen HDInsight-Cluster mit Data Lake Storage Gen2
Übermitteln Sie einen Auftrag an einen HDInsight-Cluster mit Data Lake Storage Gen2. Sie werden aufgefordert, den Speicherzugriffsschlüssel einzugeben, wenn Ihr Azure-Konto keinen Schreibzugriff auf den Gen2-Speicher hat. Sobald der Zugriffsschlüssel validiert ist, wird der Auftrag erfolgreich übermittelt.

Hinweis
Den Zugriffsschlüssel für das Speicherkonto erhalten Sie über das Azure-Portal. Weitere Informationen finden Sie unter Verwalten von Speicherkonto-Zugriffsschlüsseln.
Aufheben der Verknüpfung von Clustern
Navigieren Sie auf der Menüleiste zu Ansicht>Befehlspalette, und geben Sie dann Spark / Hive: Unlink a Cluster (Spark / Hive: Clusterverknüpfung aufheben) ein.
Wählen Sie den Cluster aus, dessen Verknüpfung aufgehoben werden soll.
Sehen Sie sich die Ansicht AUSGABE zur Überprüfung an.
Abmelden
Navigieren Sie auf der Menüleiste zu Ansicht>Befehlspalette, und geben Sie dann Azure: Abmelden ein.
Bekannte Probleme
Synapse PySpark-Installationsfehler.
Bei Synapse PySpark-Installationsfehlern wird die Abhängigkeit nicht mehr von anderen Teams und so auch generell nicht mehr verwaltet. Wenn Sie versuchen, Synapse Pyspark interaktiv zu verwenden, verwenden Sie stattdessen Azure Synapse Analytics. Dies ist eine langfristige Änderung.

Nächste Schritte
Ein Video, in dem die Verwendung von Spark und Hive für Visual Studio Code gezeigt wird, finden Sie unter Spark und Hive für Visual Studio Code.