Reverseproxy in Azure Service Fabric
Über den in Azure Service Fabric integrierten Reverseproxy können die in einem Service Fabric-Cluster ausgeführten Microservices andere Dienste mit HTTP-Endpunkten ermitteln und mit ihnen kommunizieren.
Microservices-Kommunikationsmodell
Microservices in Service Fabric werden in einer Teilmenge der Knoten im Cluster ausgeführt und können aus verschiedenen Gründen zwischen den Knoten migriert werden. Deshalb können sich die Endpunkte für Microservices dynamisch ändern. Zur Ermittlung und Kommunikation mit anderen Diensten im Cluster müssen Microservices die folgenden Schritte durchlaufen:
- Auflösen des Dienstspeicherorts über den Naming Service
- Stellen Sie eine Verbindung mit dem Dienst her.
- Umschließen der vorherigen Schritte in einer Schleife, mit der die Dienstauflösung und die für Verbindungsfehler anzuwendenden Wiederholungsrichtlinien implementiert werden
Weitere Informationen finden Sie unter Herstellung einer Verbindung mit Diensten in Service Fabric und die Kommunikation mit diesen Diensten.
Kommunizieren mithilfe des Reverseproxys
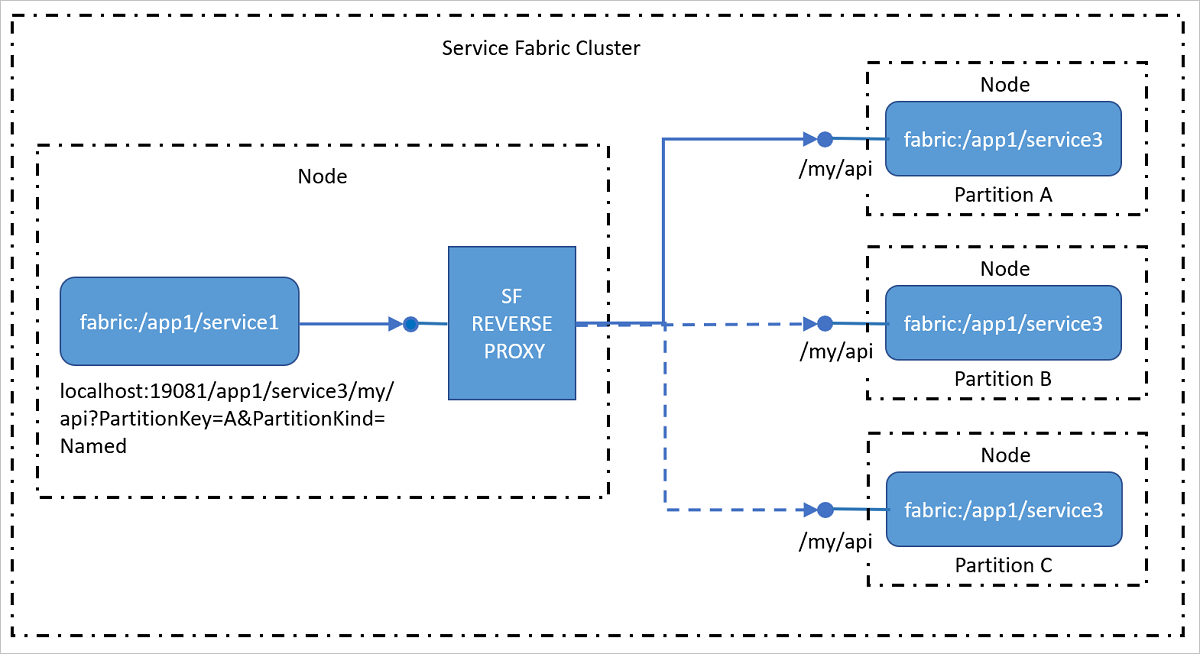
Der Reverseproxy ist ein Dienst, der auf allen Knoten ausgeführt wird und die Endpunktauflösung, die automatische Wiederholung und andere Verbindungsfehler für Clientdienste verarbeitet. Der Reverseproxy kann so konfiguriert werden, dass beim Verarbeiten von Anforderungen von Clientdiensten verschiedene Richtlinien angewendet werden. Durch Verwendung eines Reverseproxys kann der Clientdienst alle clientseitigen HTTP-Kommunikationsbibliotheken nutzen, ohne dass eine spezielle Auflösungs- und Wiederholungslogik im Dienst erforderlich ist.
Der Reverseproxy macht einen oder mehrere Endpunkte auf dem lokalen Knoten für Clientdienste verfügbar, die zum Senden von Anforderungen an andere Dienste verwendet werden können.
Hinweis
Unterstützte Plattformen
Der Reverseproxy in Service Fabric unterstützt derzeit die folgenden Plattformen:
- Windows-Cluster: Windows 8 und höher oder Windows Server 2012 und höher
- Linux-Cluster: Der Reverseproxy ist derzeit für Linux-Cluster nicht verfügbar.
Zugreifen auf Microservices von außerhalb des Clusters
Das Standardmodell für die externe Kommunikation für Microservices ist ein Aktivierungsmodell, was bedeutet, dass externe Clients nicht direkt auf die einzelnen Dienste zugreifen können. Azure Load Balancer ist eine Netzwerkgrenze zwischen Microservices und externen Clients, und er übernimmt die Netzwerkadressübersetzung und leitet externe Anforderungen an interne IP:Port-Endpunkte weiter. Damit externe Clients direkt auf den Endpunkt eines Microservice zugreifen können, müssen Sie den Load Balancer zunächst zum Weiterleiten von Datenverkehr an die einzelnen Ports konfigurieren, die der Dienst im Cluster verwendet. Die meisten Microservices, insbesondere zustandsbehaftete Microservices, sind jedoch nicht auf allen Knoten des Clusters aktiv. Die Microservices können bei einem Failover zwischen Knoten verschoben werden. In solchen Fällen kann Load Balancer die Position des Zielknotens der Replikate, an die der Datenverkehr weitergeleitet werden soll, nicht effektiv bestimmen.
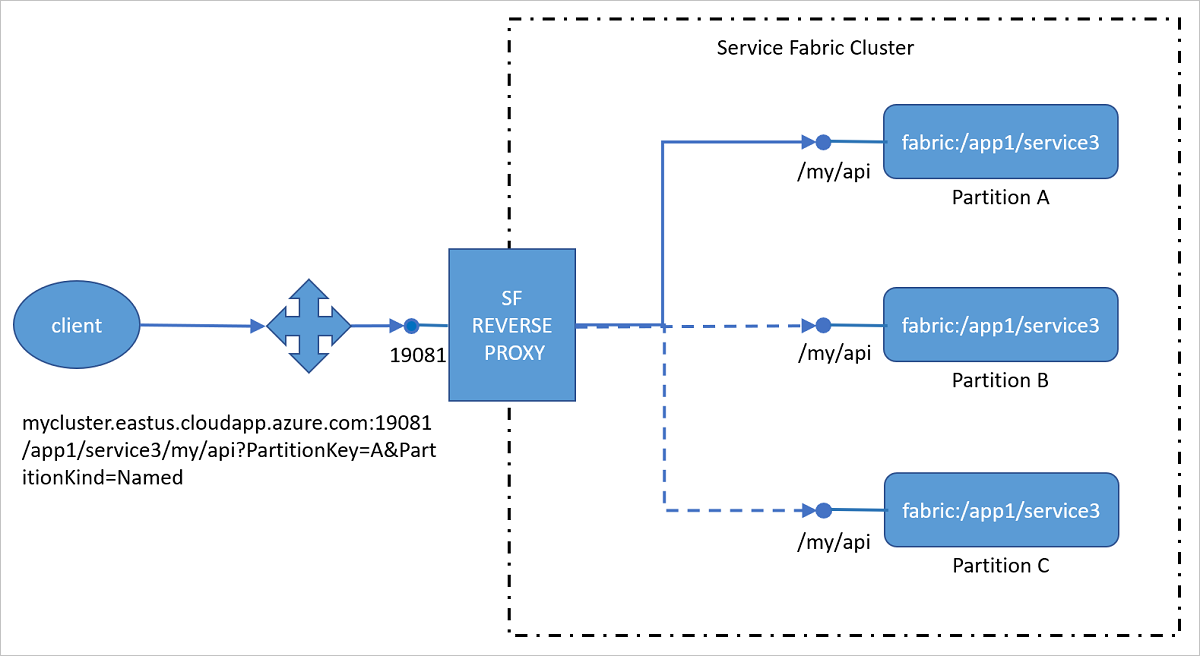
Zugreifen auf Microservices über den Reverseproxy von außerhalb des Clusters
Statt den Port eines einzelnen Diensts in Load Balancer zu konfigurieren, reicht es, wenn Sie nur den Port des Reverseproxys in Load Balancer konfigurieren. Mit dieser Konfiguration können Clients außerhalb des Clusters ohne zusätzliche Konfiguration über den Reverseproxy auf Dienste innerhalb des Clusters zugreifen.
Warnung
Wenn Sie den Port des Reverseproxys in Load Balancer konfigurieren, können alle Microservices im Cluster, die einen HTTP-Endpunkt verfügbar machen, von außerhalb des Clusters adressiert werden. Dies bedeutet, dass Microservices, die intern gedacht sind, von einem bestimmten böswilligen Benutzer entdeckt werden können. Dies legt potenziell schwerwiegende Schwachstellen offen, die ausgenutzt werden können:
- Ein böswilliger Benutzer könnte zum Beispiel einen Denial-of-Service-Angriff starten, indem er wiederholt einen internen Dienst aufruft, der keine ausreichend geschützte Angriffsfläche hat.
- Ein böswilliger Benutzer könnte fehlerhafte Pakete an einen internen Dienst senden, was zu unbeabsichtigtem Verhalten führt.
- Ein interner Dienst könnte private oder vertrauliche Informationen zurückgeben, die nicht für Dienste außerhalb des Clusters bestimmt sind, wodurch diese vertraulichen Informationen einem böswilligen Benutzer zugänglich gemacht werden könnten.
Stellen Sie sicher, dass Sie alle potenziellen Auswirkungen auf die Sicherheit Ihres Clusters und der darauf laufenden Apps kennen und verringern, bevor Sie den Reverseproxyport veröffentlichen.
URI-Format für die Adressierung von Diensten über den Reverseproxy
Der Reverseproxy verwendet ein bestimmtes URI-Format (Uniform Resource Identifier), um die Dienstpartition zu bestimmen, an die die eingehende Anforderung weitergeleitet werden soll:
http(s)://<Cluster FQDN | internal IP>:Port/<ServiceInstanceName>/<Suffix path>?PartitionKey=<key>&PartitionKind=<partitionkind>&ListenerName=<listenerName>&TargetReplicaSelector=<targetReplicaSelector>&Timeout=<timeout_in_seconds>
http(s): Der Reverseproxy kann zum Akzeptieren von HTTP- oder HTTPS-Datenverkehr konfiguriert werden. Für die HTTPS-Weiterleitung lesen Sie die Informationen unter Herstellen einer Verbindung mit einem sicheren Dienst mit dem Reverseproxy, nachdem Sie den Reverseproxy für das Lauschen von HTTPS eingerichtet haben.
Cluster fully qualified domain name (FQDN) | internal IP (Voll qualifizierter Domänenname (Fully Qualified Domain Name, FQDN) des Clusters | interne IP): Für externe Clients können Sie den Reverseproxy so konfigurieren, dass er über die Clusterdomäne erreichbar ist, z.B. „mycluster.eastus.cloudapp.azure.com“. Standardmäßig wird der Reverseproxy auf jedem Knoten ausgeführt. Für internen Datenverkehr ist der Reverseproxy unter „localhost“ oder einer beliebigen internen Knoten-IP (z.B. 10.0.0.1) erreichbar.
Port: Der Port, z.B. 19081, der für den Reverseproxy angegeben wurde
ServiceInstanceName: Der vollqualifizierte Name der bereitgestellten Dienstinstanz, den Sie erreichen möchten, ohne das Schema „fabric:/“. Um beispielsweise den Dienst fabric:/myapp/myservice/ zu erreichen, müssen Sie myapp/myservice verwenden.
Beim Dienstinstanznamen wird Groß-/Kleinschreibung beachtet. Eine andere Groß-/Kleinschreibung für den Dienstinstanznamen in der URL bewirkt, dass die Anforderungen mit 404 (Nicht gefunden) fehlschlagen.
Suffix path (Suffixpfad): Der tatsächliche URL-Pfad des Diensts, mit dem Sie eine Verbindung herstellen möchten, z.B. myapi/values/add/3.
PartitionKey: Für einen partitionierten Dienst ist dies der berechnete Partitionsschlüssel der Partition, die Sie erreichen möchten. Beachten Sie, dass dies nicht die GUID der Partitions-ID ist. Dieser Parameter ist für Dienste, die mit einem einzelnen Partitionsschema arbeiten, nicht erforderlich.
PartitionKind: Das Partitionsschema des Diensts. Dies kann „Int64Range“ oder „Named“ sein. Dieser Parameter ist für Dienste, die mit einem einzelnen Partitionsschema arbeiten, nicht erforderlich.
ListenerName Die Endpunkte des Diensts weisen folgendes Format auf: {"Endpoints":{"Listener1":"Endpoint1","Listener2":"Endpoint2" ...}} Wenn der Dienst mehrere Endpunkte verfügbar macht, identifiziert dieser Parameter den Endpunkt, an den die Clientanforderung weitergeleitet werden soll. Dieser Parameter kann ausgelassen werden, wenn der Dienst nur über einen Listener verfügt.
TargetReplicaSelector Gibt an, wie das Zielreplikat oder die Zielinstanz ausgewählt werden soll.
- Wenn der Zieldienst zustandsbehaftet ist, kann der TargetReplicaSelector entweder „PrimaryReplica“, „RandomSecondaryReplica“ oder „RandomReplica“ sein. Ist dieser Parameter nicht angegeben, lautet der Standardwert „PrimaryReplica“.
- Wenn der Zieldienst zustandslos ist, wählt der Reverseproxy eine zufällige Instanz der Dienstpartition aus, an die die Anforderung weitergeleitet wird.
Timeout: Gibt das Timeout für die HTTP-Anforderung an, die im Auftrag der Clientanforderung vom Reverseproxy für den Dienst erstellt wird. Der Standardwert beträgt 120 Sekunden. Dies ist ein optionaler Parameter.
Beispielverwendung
Nehmen wir als Beispiel den Dienst fabric:/MyApp/MyService, der einen HTTP-Listener für die folgende URL öffnet:
http://10.0.0.5:10592/3f0d39ad-924b-4233-b4a7-02617c6308a6-130834621071472715/
Dies sind die Ressourcen für den Dienst:
/index.html/api/users/<userId>
Wenn der Dienst ein einzelnes Partitionierungsschema verwendet, sind die Abfragezeichenfolgen-Parameter PartitionKey und PartitionKind nicht erforderlich. Der Dienst kann wie folgt über das Gateway erreicht werden:
- Extern:
http://mycluster.eastus.cloudapp.azure.com:19081/MyApp/MyService - Intern:
http://localhost:19081/MyApp/MyService
Wenn der Dienst das Partitionierungsschema „Uniform Int64“ verwendet, müssen die Abfragezeichenfolgen-Parameter PartitionKey und PartitionKind verwendet werden, um eine Partition des Diensts zu erreichen:
- Extern:
http://mycluster.eastus.cloudapp.azure.com:19081/MyApp/MyService?PartitionKey=3&PartitionKind=Int64Range - Intern:
http://localhost:19081/MyApp/MyService?PartitionKey=3&PartitionKind=Int64Range
Um die vom Dienst verfügbar gemachten Ressourcen zu erreichen, fügen Sie einfach hinter dem Dienstnamen den Ressourcenpfad in die URL ein:
- Extern:
http://mycluster.eastus.cloudapp.azure.com:19081/MyApp/MyService/index.html?PartitionKey=3&PartitionKind=Int64Range - Intern:
http://localhost:19081/MyApp/MyService/api/users/6?PartitionKey=3&PartitionKind=Int64Range
Das Gateway leitet dann diese Anfragen an die Dienst-URL weiter:
http://10.0.0.5:10592/3f0d39ad-924b-4233-b4a7-02617c6308a6-130834621071472715/index.htmlhttp://10.0.0.5:10592/3f0d39ad-924b-4233-b4a7-02617c6308a6-130834621071472715/api/users/6
Spezielle Einrichtung für Dienste mit Portfreigabe
Der Service Fabric-Reverseproxy versucht erneut, eine Dienstadresse aufzulösen und die Anforderung zu wiederholen, wenn ein Dienst nicht erreichbar ist. Wenn ein Dienst nicht erreicht werden kann, bedeutet dies normalerweise, dass die Dienstinstanz oder das Replikat im Rahmen des normalen Lebenszyklus auf einen anderen Knoten verschoben wurde. In diesem Fall kann der Reverseproxy einen Netzwerkverbindungsfehler erhalten, was bedeutet, dass ein Endpunkt in der ursprünglich aufgelösten Adresse nicht mehr geöffnet ist.
Allerdings können Replikate oder Dienstinstanzen einen Hostprozess und auch einen Port freigeben, wenn ein http.sys-basierter Webserver als Host fungiert, wie z.B.:
In dieser Situation ist es wahrscheinlich, dass der Webserver im Hostprozess verfügbar ist und auf Anforderungen antwortet, aber die aufgelöste Dienstinstanz oder das Replikat nicht mehr auf dem Host verfügbar ist. In diesem Fall empfängt das Gateway vom Webserver eine Antwort des Typs „HTTP 404“. Daher kann eine HTTP 404-Antwort zwei unterschiedliche Bedeutungen haben:
- Fall 1: Die Dienstadresse ist richtig, aber die vom Benutzer angeforderte Ressource ist nicht vorhanden.
- Fall 2: Die Dienstadresse ist falsch, und die vom Benutzer angeforderte Ressource ist vielleicht auf einem anderen Knoten vorhanden.
Der erste Fall ist eine normale HTTP 404-Antwort, die als Benutzerfehler betrachtet wird. Allerdings hat der Benutzer im zweiten Fall eine Ressource angefordert, die nicht vorhanden ist. Der Reverseproxy konnte sie nicht finden, weil der Dienst selbst verschoben wurde. Der Reverseproxy muss die Adresse erneut auflösen und die Anforderung wiederholen.
Der Reverseproxy benötigt daher eine Möglichkeit zur Unterscheidung zwischen diesen beiden Fällen. Um diese Unterscheidung vornehmen zu können, ist ein Hinweis des Servers erforderlich.
Standardmäßig geht der Reverseproxy vom 2. Fall aus und versucht, die Anforderung erneut aufzulösen und zu stellen.
Um dem Reverseproxy den 1. Fall anzugeben, muss der Dienst den folgenden HTTP-Antwortheader zurückgeben:
X-ServiceFabric : ResourceNotFound
Dieser HTTP-Antwortheader gibt eine normale HTTP 404-Situation an, in der die angeforderte Ressource nicht vorhanden ist und der Reverseproxy nicht versucht, die Dienstadresse erneut aufzulösen.
Spezieller Umgang mit Diensten, die in Containern ausgeführt werden
Für Dienste, die in Containern ausgeführt werden, können Sie die Umgebungsvariable Fabric_NodeIPOrFQDN zum Erstellen der Reverseproxy-URL verwenden, wie im folgenden Code veranschaulicht:
var fqdn = Environment.GetEnvironmentVariable("Fabric_NodeIPOrFQDN");
var serviceUrl = $"http://{fqdn}:19081/DockerSFApp/UserApiContainer";
Für den lokalen Cluster wird Fabric_NodeIPOrFQDN standardmäßig auf „localhost“ festgelegt. Starten Sie den lokalen Cluster mit dem Parameter -UseMachineName, um sicherzustellen, dass Container den Reverseproxy erreichen können, der auf dem Knoten ausgeführt wird. Weitere Informationen finden Sie unter Konfigurieren der Entwicklerumgebung zum Debuggen von Containern.
Service Fabric-Dienste, die innerhalb von Docker Compose-Containern ausgeführt werden, erfordern eine spezielle HTTP- oder HTTPS-Konfiguration für den Abschnitt „Ports“ in der „docker-compose.yml“. Weitere Informationen finden Sie unter Docker Compose-Bereitstellungsunterstützung in Azure Service Fabric.
Nächste Schritte
- Einrichten und Konfigurieren eines Reverseproxys in einem Cluster
- Einrichten der Weiterleitung an einen sicheren HTTP-Dienst mit dem Reverseproxy
- Diagnostizieren von Reverseproxyereignissen
- Ein Beispiel für die HTTP-Kommunikation zwischen Diensten finden Sie im Beispielprojekt auf GitHub.
- Remoteprozeduraufrufe mit Reliable Services-Remoting
- Web-API, die OWIN in Reliable Services verwendet
- WCF-Kommunikation mit Reliable Services
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für