Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Erfahren Sie, wie Ihre Blobs und Container gespeichert, organisiert und in der Produktion verwendet werden, damit Sie die Kompromisse zwischen Kosten und Leistung besser optimieren können.
In diesem Tutorial erfahren Sie, wie Sie Statistiken generieren und visualisieren, z. B. Datenwachstum im Zeitverlauf, im Laufe der Zeit hinzugefügte Daten, Anzahl geänderter Dateien, Blobmomentaufnahmegrößen, Zugriffsmuster über jede Ebene, und wie Daten sowohl aktuell als auch im Zeitverlauf verteilt werden (z. B. Verteilung von Daten über Ebenen, Dateitypen, in Containern und Blobtypen).
In diesem Tutorial lernen Sie, wie die folgenden Aufgaben ausgeführt werden:
- Generieren eines Blobinventurberichts
- Einrichten eines Synapse-Arbeitsbereichs
- Einrichten von Synapse Studio
- Generieren von Analysedaten in Synapse Studio
- Visualisieren der Ergebnisse in Power BI
Voraussetzungen
Ein Azure-Abonnement: Erstellen eines kostenlosen Kontos
Ein Azure-Speicherkonto: Erstellen eines Speicherkontos
Vergewissern Sie sich, dass Ihrer Benutzeridentität die Rolle Mitwirkender an Storage-Blobdaten zugewiesen ist.
Generieren eines Inventurberichts
Aktivieren Sie Blobinventurberichte für Ihr Speicherkonto. Weitere Informationen finden Sie unter Aktivieren von Azure Storage-Blobinventurberichten.
Möglicherweise müssen Sie nach dem Aktivieren von Inventurberichten bis zu 24 Stunden warten, bis der erste Bericht generiert werden kann.
Einrichten eines Synapse-Arbeitsbereichs
Erstellen Sie einen Azure Synapse-Arbeitsbereich. Weitere Informationen finden Sie unter Erstellen eines Synapse-Arbeitsbereichs.
Hinweis
Beim Erstellen des Arbeitsbereichs erstellen Sie ein Speicherkonto mit einem hierarchischen Namespace. Azure Synapse speichert Spark-Tabellen und Anwendungsprotokolle in diesem Konto. Azure Synapse bezieht sich auf dieses Konto als primäres Speicherkonto. Um Verwirrung zu vermeiden, wird in diesem Artikel der Begriff Inventurberichtskonto verwendet, um auf das Konto zu verweisen, das Inventurberichte enthält.
Weisen Sie ihrer Benutzeridentität im Synapse-Arbeitsbereich die Rolle Mitwirkender zu. Weitere Informationen finden Sie unter Azure RBAC: Besitzer-Rolle für den Arbeitsbereich.
Erteilen Sie dem Synapse-Arbeitsbereich die Berechtigung, auf die Inventurberichte in Ihrem Speicherkonto zuzugreifen, indem Sie zu Ihrem Inventurberichtskonto navigieren und dann der systemverwalteten Identität des Arbeitsbereichs die Rolle Mitwirkender für Speicherblobdaten zuweisen. Weitere Informationen finden Sie unter Zuweisen von Azure-Rollen mit dem Azure-Portal.
Navigieren Sie zum primären Speicherkonto, und weisen Sie Ihrer Benutzeridentität die Rolle Blob Storage-Mitwirkender zu.
Einrichten von Synapse Studio
Öffnen Sie Ihren Synapse-Arbeitsbereich in Synapse Studio. Weitere Informationen finden Sie unter Öffnen von Synapse Studio.
Stellen Sie in Synapse Studio sicher, dass Ihrer Identität die Rolle Synapse-Administrator zugewiesen ist. Weitere Informationen finden Sie unter Synapse RBAC: Synapse-Administratorrolle für den Arbeitsbereich.
Einen Apache Spark-Pool erstellen Weitere Informationen finden Sie unter Erstellen eines serverlosen Apache Spark-Pools.
Einrichten und Ausführen des Beispielnotebooks
In diesem Abschnitt generieren Sie statistische Daten, die Sie in einem Bericht visualisieren. Um dieses Tutorial zu vereinfachen, werden in diesem Abschnitt eine Beispielkonfigurationsdatei und ein PySpark-Beispielnotebook verwendet. Das Notebook enthält eine Sammlung von Abfragen, die in Azure Synapse Studio ausgeführt werden.
Ändern und Hochladen der Beispielkonfigurationsdatei
Laden Sie die Datei BlobInventoryStorageAccountConfiguration.json herunter.
Aktualisieren Sie die folgenden Platzhalter dieser Datei:
Legen Sie
storageAccountNameauf den Namen Ihres Inventurberichtskontos fest.Legen Sie
destinationContainerauf den Namen des Containers fest, der die Inventurberichte enthält.Legen Sie
blobInventoryRuleNameauf den Namen der Inventurberichtsregel fest, die die Ergebnisse generiert hat, die Sie analysieren möchten.Legen Sie
accessKeyauf den Kontoschlüssel des Inventurberichtskontos fest.
Laden Sie diese Datei in den Container in Ihrem primären Speicherkonto hoch, den Sie beim Erstellen des Synapse-Arbeitsbereichs angegeben haben.
Importieren des PySpark-Beispielnotebooks
Laden Sie das Beispielnotebook ReportAnalysis.ipynb herunter.
Hinweis
Speichern Sie diese Datei unbedingt mit der
.ipynb-Erweiterung.Öffnen Sie Ihren Synapse-Arbeitsbereich in Synapse Studio. Weitere Informationen finden Sie unter Öffnen von Synapse Studio.
Wählen Sie in Synapse Studio die Registerkarte Entwickeln aus.
Wählen Sie das Pluszeichen (+) aus, um ein Element hinzuzufügen.
Wählen Sie Importieren aus, navigieren Sie zu der heruntergeladenen Beispieldatei, wählen Sie diese Datei aus, und wählen Sie Öffnen aus.
Daraufhin wird das Dialogfeld Eigenschaften angezeigt.
Wählen Sie im Dialogfeld Eigenschaften den Link Sitzung konfigurieren aus.
Das Dialogfeld Sitzung konfigurieren wird geöffnet.
Wählen Sie in der Dropdownliste Anfügen an des Dialogfelds Sitzung konfigurieren den Spark-Pool aus, den Sie zuvor in diesem Artikel erstellt haben. Wählen Sie anschließend die Schaltfläche Anwenden aus.
Ändern des Python-Notebooks
Legen Sie in der ersten Zelle des Python-Notebooks den Wert der
storage_account-Variablen auf den Namen des primären Speicherkontos fest.Aktualisieren Sie den Wert der
container_name-Variablen mit dem Namen des Containers in diesem Konto, den Sie beim Erstellen des Synapse-Arbeitsbereichs angegeben haben.Wählen Sie die Schaltfläche Veröffentlichen aus.
Ausführen des PySpark-Notebooks
Wählen Sie im PySpark-Notebook Alle ausführen aus.
Es dauert einige Minuten bis zum Start der Spark-Sitzung, und noch einige weitere Minuten, um die Inventurberichte zu verarbeiten. Die erste Ausführung könnte eine Weile dauern, wenn zahlreiche Inventurberichte zu verarbeiten sind. Nachfolgende Ausführungen verarbeiten nur die neuen, seit der letzten Ausführung erstellten Inventurberichte.
Hinweis
Wenn Sie Änderungen an dem Notebook vornehmen, während es ausgeführt wird, veröffentlichen Sie diese Änderungen unbedingt mit der Schaltfläche Veröffentlichen.
Wählen Sie die Registerkarte Daten aus, um zu überprüfen, ob das Notebook erfolgreich ausgeführt wurde.
Eine Datenbank mit dem Namen reportdata sollte auf der Registerkarte Arbeitsbereich des Bereichs Daten angezeigt werden. Wenn diese Datenbank nicht angezeigt wird, müssen Sie möglicherweise die Webseite aktualisieren.
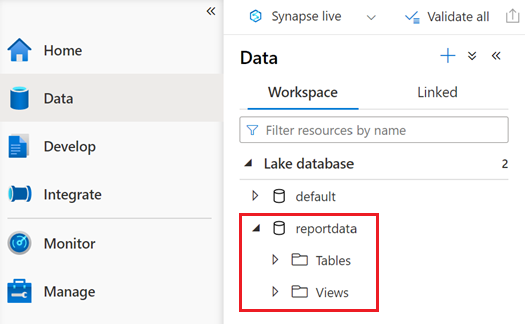
Die Datenbank enthält eine Reihe von Tabellen. Jede Tabelle enthält Informationen, die durch Ausführen der Abfragen aus dem PySpark-Notebook abgerufen werden.
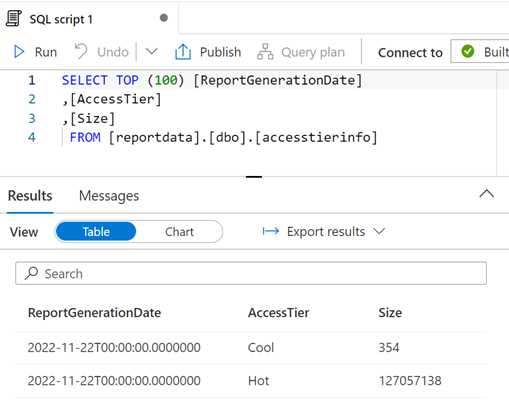
Um den Inhalt einer Tabelle zu untersuchen, erweitern Sie den Ordner Tables der Datenbank reportdata. Klicken Sie dann mit der rechten Maustaste auf eine Tabelle, und wählen Sie SQL-Skript auswählen und dann OBERSTE 100 Zeilen auswählen aus.

Sie können die Abfrage nach Bedarf ändern und dann Ausführen auswählen, um die Ergebnisse anzuzeigen.
Visualisieren der Daten
Laden Sie die Beispielberichtsdatei ReportAnalysis.pbit herunter.
Öffnen Sie Power BI Desktop. Installationsanleitungen finden Sie unter Erwerben von Power BI Desktop.
Wählen Sie in Power BI Datei, Bericht öffnen und dann Berichte durchsuchen aus.
Ändern Sie im Dialogfeld Öffnen den Dateityp in Power BI-Vorlagendateien (*.pbit).

Navigieren Sie zum Speicherort der heruntergeladenen Datei ReportAnalysis.pbit, und wählen Sie dann Öffnen aus.
Es wird ein Dialogfeld angezeigt, in dem Sie aufgefordert werden, den Namen des Synapse-Arbeitsbereichs und den Namen der Datenbank anzugeben.
Legen Sie im Dialogfeld für das Feld synapse_workspace_name den Arbeitsbereichsnamen und für das Feld database_name
reportdatafest. Wählen Sie dann die Schaltfläche Laden aus.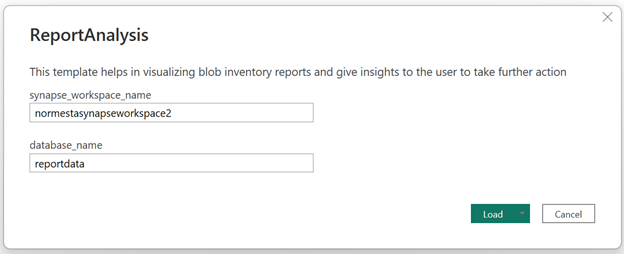
Es wird ein Bericht angezeigt, der Visualisierungen der vom Notebook abgerufenen Daten bereitstellt. Die folgenden Abbildungen zeigen die Typen der Diagramme, die in diesem Bericht angezeigt werden.
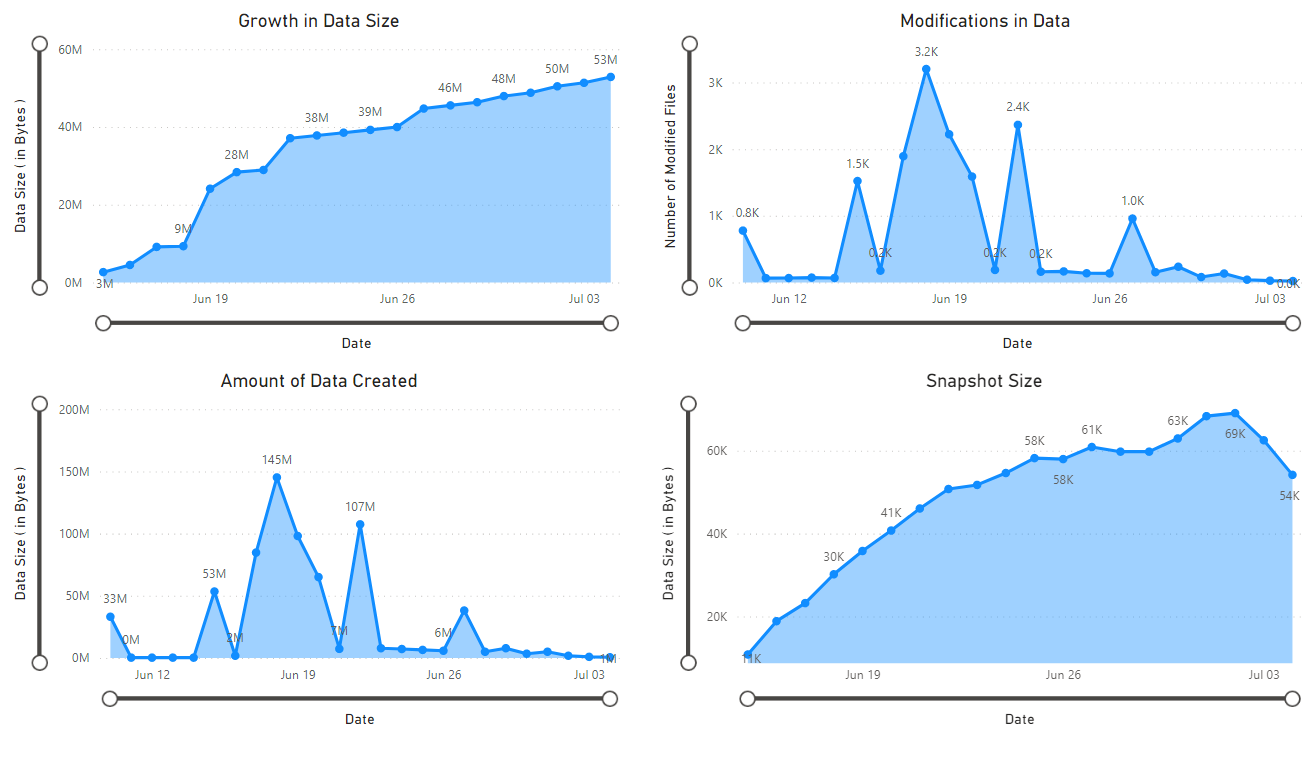
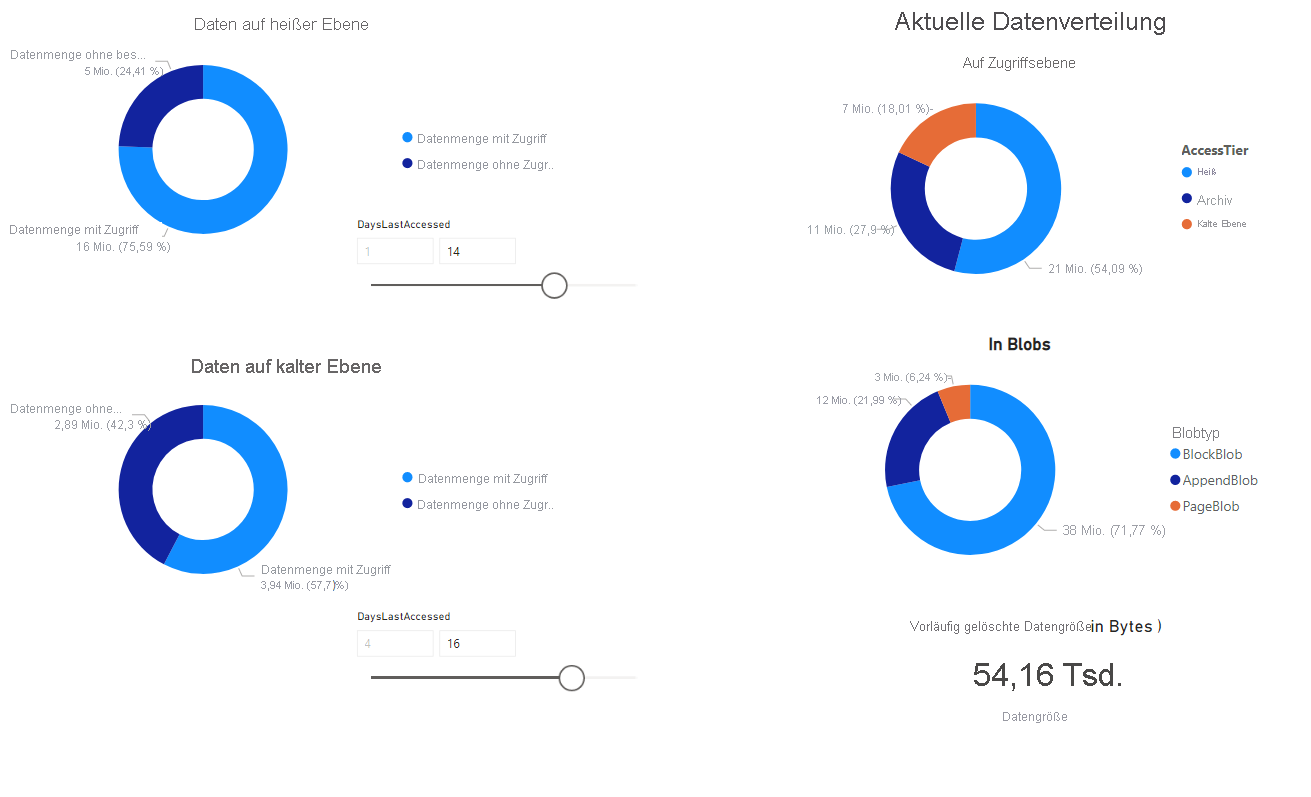
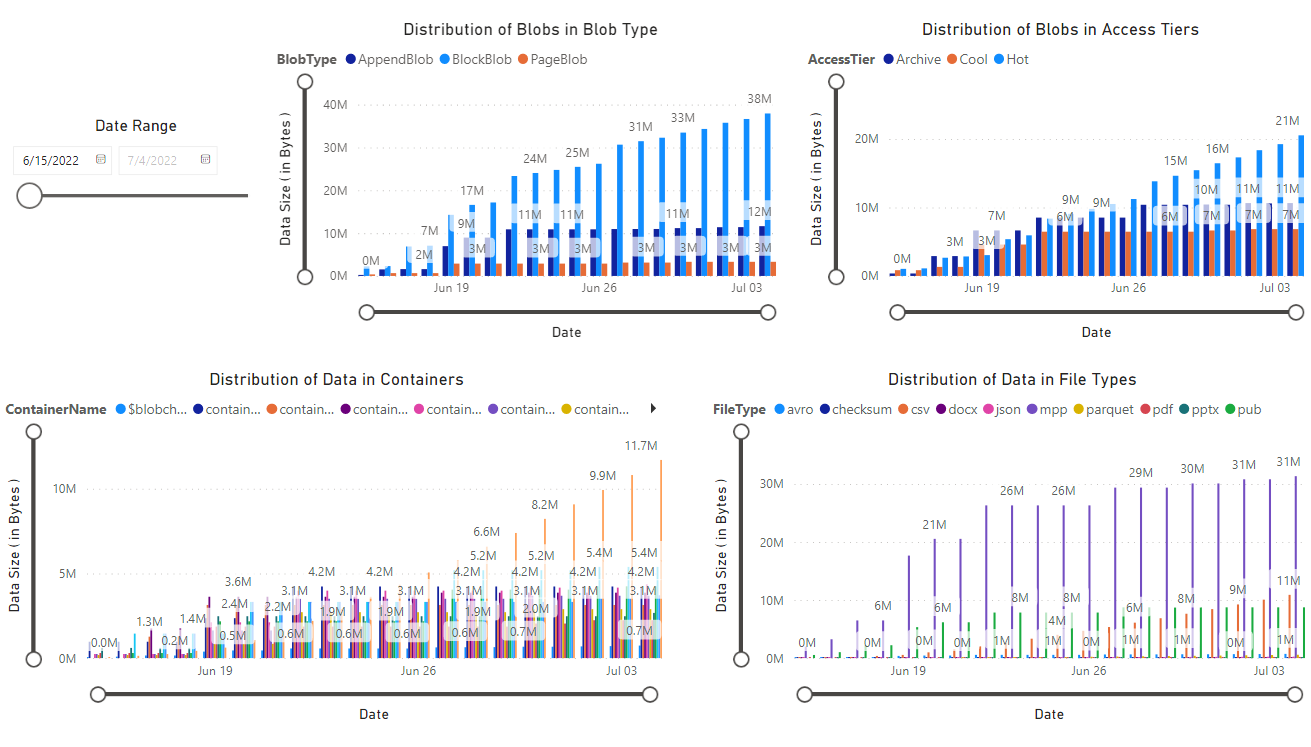
Nächste Schritte
Richten Sie eine Azure Synapse-Pipeline ein, um Ihr Notebook in regelmäßigen Abständen auszuführen. Auf diese Weise können Sie neue Inventurberichte verarbeiten, während sie erstellt werden. Nach der ersten Ausführung analysiert jede der nächsten Ausführungen inkrementelle Daten und aktualisiert dann die Tabellen mit den Ergebnissen dieser Analyse. Eine Anleitung finden Sie unter Integrieren mit Pipelines.
Erfahren Sie mehr über Möglichkeiten zum Analysieren einzelner Container in Ihrem Speicherkonto. Informationen hierzu finden Sie in diesen Artikeln:
Berechnen der Anzahl und Gesamtgröße von Blobs pro Container mit dem Azure Storage-Bestand
Tutorial: Berechnen von Containerstatistiken mithilfe von Databricks
Erfahren Sie mehr über Möglichkeiten, Ihre Kosten auf Basis der Analyse Ihrer Blobs und Container zu optimieren. Informationen hierzu finden Sie in diesen Artikeln:
Planen und Verwalten von Kosten für Azure Blob Storage
Schätzen der Kosten für die Archivierung von Daten
Optimieren von Kosten durch automatisches Verwalten des Datenlebenszyklus