Entwickeln von Regelpaketen für vertrauliche Informationen in Exchange 2013
Gilt für: Exchange Server 2013
Das XML-Schema und die Anleitungen in diesem Artikel sollen Ihnen beim Einstieg in die Erstellung eigener grundlegender XML-Dateien zur Verhinderung von Datenverlust (Data Loss Prevention, DLP) helfen, in denen Sie in einem Klassifizierungsregelpaket Ihre eigenen Typen vertraulicher Informationen definieren. Nachdem Sie eine wohlgeformte XML-Datei erstellt haben, können Sie sie entweder über das Exchange Admin Center oder die Exchange-Verwaltungsshell importieren, um eine Microsoft Exchange Server 2013-DLP-Lösung zu erstellen. Eine XML-Datei, die als benutzerdefinierte DLP-Richtlinienvorlage dient, kann das XML enthalten, das sich in Ihrem Klassifizierungsregelpaket befindet. Eine Übersicht über die Definition eigener DLP-Vorlagen als XML-Dateien finden Sie unter Definition eigener DLP-Vorlagen und Informationstypen.
Übersicht über das Regelerstellungsverfahren
Das Regelerstellungsverfahren setzt sich aus den folgenden allgemeinen Schritte zusammen.
Bereiten Sie eine Reihe von Testdokumenten vor, die repräsentativ für die jeweilige Zielumgebung sind. Zu den wichtigsten Merkmalen, die für die Gruppe von Testdokumenten zu berücksichtigen sind, gehören: Eine Teilmenge der Dokumente enthält die Entität oder Affinität, für die die Regel erstellt wird, und eine Teilmenge der Dokumente enthält nicht die Entität oder Affinität, für die die Regel erstellt wird.
Ermitteln Sie die Regeln, die den Akzeptanzanforderungen (Genauigkeit und Rückruf) entsprechen, um qualifizierende Inhalte zu identifizieren. Dieser Identifizierungsaufwand kann die Entwicklung mehrerer Bedingungen innerhalb einer Regel erfordern, die an boolesche Logik gebunden sind, die zusammen die mindesten Übereinstimmungsanforderungen zum Identifizieren von Zieldokumenten erfüllen.
Legen Sie die empfohlene Zuverlässigkeitsstufe für die Regeln basierend auf den Akzeptanzanforderungen (Genauigkeit und Rückruf) fest. Das empfohlene Zuverlässigkeitselement kann als standardmäßige Zuverlässigkeitsstufe für die Regel betrachtet werden.
Überprüfen Sie die Regeln, indem Sie hiermit eine Richtlinie in Kraft setzen und den Inhalt des Tests überwachen. Passen Sie die Regeln oder die Zuverlässigkeitsstufe basierend auf den Ergebnissen an, um ein Maximum an Inhalten zu erkennen und gleichzeitig falsch positive und negative Ergebnisse zu minimieren. Setzen Sie die Überprüfung und Anpassung der Regeln so lange fort, bis ein zufriedenstellendes Niveau an Inhaltserkennung sowohl für positive als auch für negative Beispiele erreicht ist.
Informationen zur XML-Schemadefinition für Richtlinienvorlagendateien finden Sie unter Entwickeln von Vorlagendateien für DLP-Richtlinien.
Regelbeschreibung
Für das DLP-Modul zur Erkennung vertraulicher Informationen können zwei Hauptregeltypen erstellt werden: Entität und Affinität. Der gewählte Regel typ basiert auf der Art der Verarbeitungslogik, die bei der Verarbeitung des Inhalts wie in den vorstehenden Abschnitten beschrieben angewendet werden sollte. Die Regeldefinitionen werden in einem XML-Dokument in dem Format konfiguriert, das von der standardisierten Regel-XSD vorgegeben wird. Die Regeln beschreiben sowohl den Inhaltstyp, der verglichen werden soll, als auch die Zuverlässigkeitsstufe, die die beschriebene Übereinstimmung im Zielinhalt repräsentiert. Die Zuverlässigkeit stufe gibt die Wahrscheinlichkeit ein, mit der die Entität vorhanden ist, wenn im Inhalt ein Muster gefunden wird, oder die Wahrscheinlichkeit, mit der die Affinität vorhanden ist, wenn im Inhalt ein Nachweis gefunden wird.
Grundlegende Regelstruktur
Die Regeldefinition setzt sich aus drei Hauptkomponenten zusammen:
Entität definiert die Übereinstimmungs- und Zählungslogik für diese Regel
Affinität definiert die Übereinstimmungslogik für die Regel
Lokalisierte Zeichenfolgen Lokalisierung von Regelnamen und deren Beschreibungen
Drei weitere unterstützende Elemente werden verwendet, die die Details der Verarbeitung definieren und innerhalb der Standard Komponenten referenziert werden: Schlüsselwort, RegEx und Funktion. Mithilfe von Verweisen kann eine einzige Definition der unterstützenden Elemente, wie eine Sozialversicherungsnummer, in mehreren Entitäts- oder Affinitätsregeln verwendet werden. Die grundlegende Regelstruktur im XML-Format kann wie folgt beschrieben werden.
<?xml version="1.0" encoding="utf-8"?>
<RulePackage xmlns="http://schemas.microsoft.com/office/2011/mce">
<RulePack id="DAD86A92-AB18-43BB-AB35-96F7C594ADAA">
<Version major="1" minor="0" build="0" revision="0"/>
<Publisher id="619DD8C3-7B80-4998-A312-4DF0402BAC04"/>
<Details defaultLangCode="en-us">
<LocalizedDetails langcode="en-us">
<PublisherName>DLP by EPG</PublisherName>
<Name>CSO Custom Rule Pack</Name>
<Description>This is a rule package for a EPG demo.</Description>
</LocalizedDetails>
</Details>
</RulePack>
<Rules>
<!-- Employee ID -->
<Entity id="E1CC861E-3FE9-4A58-82DF-4BD259EAB378" patternsProximity="300" recommendedConfidence="75">
<Pattern confidenceLevel="75">
<IdMatch idRef="Regex_employee_id" />
<Match idRef="Keyword_employee" />
</Pattern>
</Entity>
<Regex id="Regex_employee_id">(\s)(\d{9})(\s)</Regex>
<Keyword id="Keyword_employee">
<Group matchStyle="word">
<Term>Identification</Term>
<Term>Contoso Employee</Term>
</Group>
</Keyword>
<LocalizedStrings>
<Resource idRef="E1CC861E-3FE9-4A58-82DF-4BD259EAB378">
<Name default="true" langcode="en-us">
Employee ID
</Name>
<Description default="true" langcode="en-us">
A custom classification for detecting Employee ID's
</Description>
</Resource>
</LocalizedStrings>
</Rules>
</RulePackage>
Entitätsregeln
Entitätsregeln sind auf klar definierte Bezeichner ausgerichtet, z. B. Sozialversicherungsnummer, und werden durch eine Sammlung von zählbaren Mustern dargestellt. Entitätsregeln geben die Anzahl sowie die Zuverlässigkeitsstufe einer Übereinstimmung zurück, wobei die Anzahl gleich der Gesamtanzahl Vorkommen der Entität ist, die gefunden wurde, und die Vertraulichkeitsstufe für die Wahrscheinlichkeit steht, dass die angegebene Entität im jeweiligen Dokument vorkommt. Die Entität enthält das Attribut "Id" als eindeutigen Bezeichner. Der Bezeichner wird für Lokalisierung, Versionierung und Abfragen verwendet. Die Entitäts-ID muss eine GUID sein. Die Entitäts-ID darf nicht in anderen Entitäten oder Affinitäten dupliziert werden. Darauf wird im Abschnitt lokalisierte Zeichenfolgen verwiesen.
Entitätsregeln enthalten optionale patternsProximity-Attribut (Standard = 300), das verwendet wird, wenn boolesche Logik angewendet wird, um die Kohärenz mehrerer Muster anzugeben, die erforderlich sind, um die Übereinstimmungsbedingung zu erfüllen. Entity-Element enthält mindestens ein untergeordnetes Pattern-Element, wobei jedes Muster eine eigene Darstellung der Entität ist, z. B. Kreditkartenentität oder Driver's License Entity. Das Pattern-Element verfügt über das erforderliche Attribut confidenceLevel, das die Genauigkeit des Musters basierend auf dem Beispieldataset darstellt. Das Pattern-Element kann drei untergeordnete Elemente aufweisen:
IdMatch: Dieses Element ist erforderlich.
Vergleich
Any
Wenn ein beliebiges Pattern-Element den Wert "true" zurückgibt, ist das Muster erfüllt. Die Anzahl des Entity-Elements entspricht der Summe aller erkannten Pattern-Elemente.
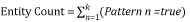
"k" ist dabei die Anzahl von Pattern-Elementen für die Entität ist.
Ein Pattern-Element muss über genau ein IdMatch-Element verfügen. "IdMatch" steht für den Bezeichner, der mit dem Muster verglichen werden soll, z. B. eine Kreditkartennummer oder eine ITIN-Nummer. Die Anzahl eines Pattern-Elements ist gleich der Anzahl von IdMatches, die mit dem Pattern-Element verglichen wurden. Das IdMatch-Element verankert das Näherungsfenster für die Match-Elemente.
Ein weiteres optionales Unterelement des Pattern-Elements ist das Match-Element, das bestätigende Beweise darstellt, die abgeglichen werden müssen, um die Suche nach dem IdMatch-Element zu unterstützen. Die Regel für höhere Zuverlässigkeit kann z. B. erfordern, dass zusätzlich zum Suchen eines Guthabens Karte Zahl zusätzliche Artefakte im Dokument innerhalb eines Näherungsfensters des Karte des Guthabens vorhanden sind, z. B. Adresse und Name. Diese zusätzlichen Artefakte werden durch das Match-Element oder any-Element dargestellt (ausführlich im Abschnitt Abgleichsmethoden und -techniken beschrieben). Mehrere Match-Elemente können in eine Pattern-Definition eingeschlossen werden, die direkt in das Pattern-Element eingeschlossen oder mithilfe des Any-Elements kombiniert werden kann, um die übereinstimmende Semantik zu definieren. Es wird true zurückgegeben, wenn eine Übereinstimmung im Näherungsfenster gefunden wird, das um den IdMatch-Inhalt verankert ist.
Sowohl das IdMatch- als auch das Match-Element definieren nicht die Details, welche Inhalte abgeglichen werden müssen, sondern verweisen stattdessen über das idRef-Attribut darauf. Dieser Verweis fördert die Wiederverwendbarkeit von Definitionen in mehreren Musterkonstrukten.
<Entity id="..." patternsProximity="300" >
<Pattern confidenceLevel="85">
<IdMatch idRef="FormattedSSN" />
<Any minMatches="1">
<Match idRef="SSNKeyword" />
<Match idRef="USDate" />
<Match idRef="USAddress" />
<Match idRef="Name" />
</Any>
</Pattern>
<Pattern confidenceLevel="65">
<IdMatch idRef="UnformattedSSN" />
<Match idRef="SSNKeyword" />
<Any minMatches="1">
<Match idRef="USDate" />
<Match idRef="USAddress" />
<Match idRef="Name" />
</Any>
</Pattern>
</Entity>
Das Entitäts-ID-Element, das im vorherigen XML durch "..." dargestellt wird sollte eine GUID sein, auf die im Abschnitt Lokalisierte Zeichenfolgen verwiesen wird.
Näherungsfenster für das Entity-Muster
"Entity" enthält den optionalen Attributwert "patternsProximity" (ganze Zahl, Standardwert = 300), der für die Suche nach Mustern verwendet wird. Für jedes Muster definiert der Attributwert den Abstand (in Unicode-Zeichen) vom IdMatch-Speicherort für alle anderen Übereinstimmungen, die für dieses Muster angegeben sind. Das Näherungsfenster wird von der IdMatch-Position verankert, wobei das Fenster links und rechts von "IdMatch" erweitert wird.
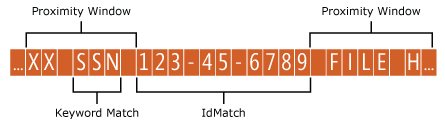
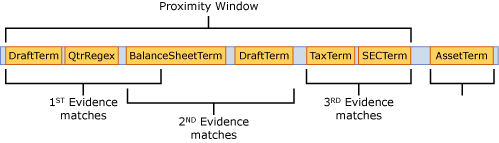
Das folgende Beispiel veranschaulicht, wie sich das Näherungsfenster auf den übereinstimmenden Algorithmus auswirkt, bei dem das SSN IdMatch-Element mindestens eine der bestätigenden Übereinstimmungen für Adresse, Name oder Datum erfordert. Aufgrund von SSN2 und SSN3 gibt es nur Übereinstimmungen für SSN1 und SSN4, und im Näherungsfenster wird kein oder nur ein teilweise bestätigender Nachweis gefunden.
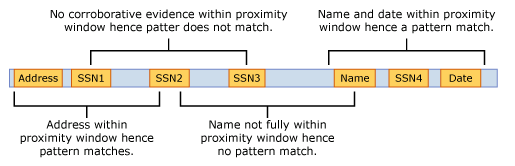
Der Nachrichtentext und jede Anlage werden als unabhängige Elemente behandelt. Diese Bedingung bedeutet, dass das Näherungsfenster nicht über das Ende der einzelnen Elemente hinausgeht. Für jedes Element (Anlage oder Text) müssen sich sowohl der idMatch- als auch der bestätigende Beweis in jedem befinden.
Zuverlässigkeitsstufe für "Entity"
Die Zuverlässigkeitsstufe des Entity-Elements ist die Kombination aus allen bestätigten Zuverlässigkeitsstufen von "Pattern". Sie werden mit der folgenden Gleichung kombiniert:

Wobei k die Anzahl der Pattern-Elemente für die Entität und ein Muster, das nicht übereinstimmt, eine Konfidenzstufe von 0 zurückgibt.
Rückbezüglich auf das Codebeispiel für die Struktur des Entity-Elements gilt, dass die Zuverlässigkeitsstufe der Entität bei 94,75 % liegt, wenn beide Muster verglichen werden, basierend auf der folgenden Berechnung:
CLEntität= 1-[(1-CLMuster1) x (1-CLMuster1)]
= 1-[(1-0,85) x (1-0,65)]
= 1-(0,15 x 0,35)
= 94.75%
Ebenso gilt, dass die Zuverlässigkeitsstufe der Entität 65 % beträgt, wenn nur das zweite Muster eine Übereinstimmung ergibt, und zwar basierend auf der folgenden Berechnung:
CLEntität= 1 - [(1 - CLMuster1) X (1 - CLMuster1)]
= 1 - [(1 - 0) X (1 - 0,65)]
= 1 - (1 X 0,35)
= 65%
Diese Zuverlässigkeitsstufenwerte werden in den Regeln für einzelne Muster zugewiesen, und zwar basierend auf der Sammlung der Testdokumente, die als Teil des Regelerstellungsverfahrens ausgewertet wurden.
Affinitätsregeln
Affinitätsregel beziehen sich auf Inhalte ohne ordnungsgemäß definierte Bezeichner, z. B. Sarbanes-Oxley oder Finanzdokumente des Unternehmens. Für diesen Inhalt kann kein einziger konsistenter Bezeichner gefunden werden, und stattdessen muss für die Analyse bestimmt werden, ob eine Sammlung von Beweisen vorhanden ist. Affinitätsregeln geben keine Anzahl zurück, sondern geben bei Gefundener den zugehörigen Konfidenzgrad zurück. Affinitätsinhalte werden als eine Sammlung von unabhängigen Nachweisen dargestellt. Als Nachweis gilt eine Häufung von erforderlichen Treffern innerhalb einer bestimmten Näherung. Für eine Affinitätsregel werden die Näherung mit dem Attribut "evidencesProximity" (Standardwert 600) und die minimale Zuverlässigkeitsstufe mit dem Attribut "thresholdConfidenceLevel" definiert.
Affinitätsregeln enthalten das Id-Attribut für den eindeutigen Bezeichner, der für Lokalisierung, Versionsverwaltung und Abfragen verwendet wird. Da Affinitätsregeln im Gegensatz zu Entitätsregeln nicht auf klar definierten Bezeichnern basieren, enthalten sie nicht das IdMatch-Element.
Jede Affinitätsregel enthält ein oder mehrere untergeordnete Evidence-Elemente, die den zu findenden Beweis und die Zuverlässigkeitsstufe definieren, die zur Affinitätsregel beiträgt. Die Affinität wird nicht als gefunden betrachtet, wenn das resultierende Konfidenzniveau unter dem Schwellenwert liegt. Jeder Nachweis stellt logisch einen bestätigenden Nachweis für diesen "Typ" Dokument dar, und das Attribut "confidenceLevel" steht für die Genauigkeit dieses Nachweises im Testdatenset.
Evidence-Elemente weisen ein oder mehrere untergeordnete Match- oder Any-Elemente auf. Wenn es eine Übereinstimmung mit allen untergeordneten Match- und Any-Elementen gibt, gilt der Nachweis als erbracht, und die Zuverlässigkeitsstufe geht in die Berechnung der Zuverlässigkeitsstufe der Regel ein. Für die Match- oder Any-Elemente in Affinitätsregeln gilt dieselbe Beschreibung wie bei Entitätsregeln.
<Affinity id="..."
evidencesProximity="1000"
thresholdConfidenceLevel="65">
<Evidence confidenceLevel="40">
<Any>
<Match idRef="AssetsTerms" />
<Match idRef="BalanceSheetTerms" />
<Match idRef="ProfitAndLossTerms" />
</Any>
</Evidence>
<Evidence confidenceLevel="40">
<Any minMatches="2">
<Match idRef="TaxTerms" />
<Match idRef="DollarAmountTerms" />
<Match idRef="SECTerms" />
<Match idRef="SECFilingFormTerms" />
<Match idRef="DollarTotalRegex" />
</Any>
</Evidence>
</Affinity>
Näherungsfenster für Affinität
Das Näherungsfenster für die Affinität wird anders berechnet als für Entity-Muster. Bei der Affinität folgt die Näherung einem gleitenden Fenster-Modell. Mit dem Näherungsalgorithmus für die Affinität wird versucht, in einem bestimmten Fenster die maximale Anzahl von übereinstimmenden Nachweisen zu finden. Die Nachweise im Näherungsfenster müssen über eine Zuverlässigkeitsstufe verfügen, die größer als der Schwellenwert der verwendeten Affinitätsregel ist.

Zuverlässigkeit stufe für Affinität
Die Zuverlässigkeitsstufe für die Affinität entspricht der Kombination der Nachweise, die im Näherungsfenster der Affinitätsregel gefunden wurden. Dies ist zwar mit der Zuverlässigkeitsstufe der Entitätsregel vergleichbar, der Hauptunterschied liegt jedoch in der Anwendung des Näherungsfensters. Ebenso wie bei Entitätsregeln ist die Zuverlässigkeitsstufe des Affinity-Elements eine Kombination aus allen erfüllten Zuverlässigkeitsstufe des Evidence-Elements, bei der Affinitätsregel steht dies jedoch nur für die höchste Kombination aus Evidence-Elementen, die im Näherungsfenster gefunden wurden. Die Zuverlässigkeitsstufen des Evidence-Elements werden mit der folgenden Gleichung kombiniert:
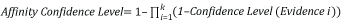
"k" ist dabei die Anzahl von Evidence-Elementen für die Affinität, für die im Näherungsfenster eine Übereinstimmung gefunden wurde.
Rückblickend auf Abbildung 4, "Beispiel für die Struktur einer Affinitätsregel", gilt: Wenn es für alle drei Nachweise im gleitenden Näherungsfenster Übereinstimmungen gibt, beträgt die Zuverlässigkeit stufe der Affinität basierend auf der nachstehenden Berechnung 85,6 %. Dieser Wert überschreitet den Schwellenwert für Affinitätsregel von 65, was zum Regelabgleich führt.
CLAffinität= 1 - [(1 - CLNachweis 1) X (1 - CLNachweis 2) X (1 - CLNachweis 2)]
= 1 - [(1 - 0,6) X (1 - 0,4) X (1 - 0,4)]
= 1 - (0,4 X 0,6 X 0,6)
= 85.6%
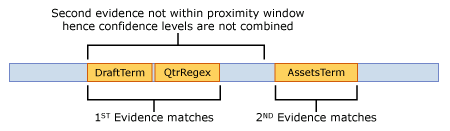
Wenn nur der erste Beweis übereinstimmt, weil sich der zweite Beweis außerhalb des Näherungsfensters befindet, beträgt die höchste Affinitätsvertrauensstufe basierend auf der folgenden Berechnung 60 %, und die Affinitätsregel stimmt nicht überein, da der Schwellenwert von 65 nicht erreicht wurde.
CLAffinität= 1 - [(1 - CLNachweis 1) X (1 - CLNachweis 2) X (1 - CLNachweis 2)]
= 1 - [(1 - 0,6) X (1 - 0) X (1 - 0)]
= 1 - (0,4 X 1 X 1)
= 60%
Optimieren von Zuverlässigkeitsstufen
Einer der wichtigsten Aspekte im Regelerstellungsverfahren besteht darin, die Zuverlässigkeitsstufen für Entitäts- und Affinitätsregeln zu optimieren. Nach der Erstellung der Regeldefinitionen sollten Sie die Regel auf repräsentative Inhalte anwenden und die Daten im Hinblick auf die Genauigkeit überprüfen. Vergleichen Sie die zurückgegebenen Ergebnisse für jedes Muster oder jeden Nachweis mit den für die Testdokumente zu erwartenden Ergebnissen.
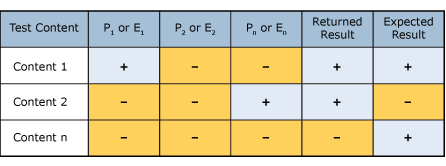
Wenn die Regeln die Akzeptanzanforderungen erfüllen, d. h. das Muster oder der Beweis eine Konfidenzrate hat, die einen festgelegten Schwellenwert überschreitet (z. B. 75 %), ist der Übereinstimmungsausdruck abgeschlossen und kann in den nächsten Schritt verschoben werden.
Wenn das Muster oder der Beweis nicht dem Konfidenzniveau entspricht, führen Sie es erneut aus (z. B. fügen Sie weitere bestätigende Beweise hinzu, entfernen oder hinzufügen sie zusätzliche Muster/Beweise usw.), und wiederholen Sie diesen Schritt.
Optimieren Sie im nächsten Schritt die Zuverlässigkeitsstufe für jedes Muster oder jeden Nachweis in Ihren Regeln basierend auf den Ergebnissen des vorherigen Schritts. Aggregieren Sie für jedes Muster oder Jeden Beweis die Anzahl von True Positives (TP), eine Teilmenge der Dokumente, die die Entität oder Affinität enthalten, für die die Regel erstellt wird und die zu einer Übereinstimmung und der Anzahl falsch positiver Ergebnisse (False Positives, FP) geführt hat, eine Teilmenge von Dokumenten, die nicht die Entität oder Affinität enthalten, für die die Regel erstellt wird und die ebenfalls eine Übereinstimmung zurückgegeben hat. Legen Sie die Zuverlässigkeitsstufe für jedes Muster/jeden Nachweis mithilfe der folgenden Berechnung fest:
Zuverlässigkeitsstufe = richtig positive Ergebnisse / (richtig positive Ergebnisse + falsch positive Ergebnisse)
| Muster oder Nachweise | Richtig positive Ergebnisse | Falsch positive Ergebnisse | Zuverlässigkeitsstufe |
|---|---|---|---|
| P1oder E1 | 4 | 1 | 80% |
| P2oder E2 | 2 | 2 | 50% |
| Pnoder En | 9 | 10 | 47% |
Verwenden von lokalen Sprachen in einer XML-Datei
Das Regelschema unterstützt die Speicherung von lokalisierten Namen und Beschreibungen für alle Entity- und Affinity-Elemente. Für jedes Entity- und Affinity-Element muss es ein entsprechendes Element im Abschnitt "LocalizedStrings" geben. Zum Lokalisieren der einzelnen Elemente schließen Sie ein Resource-Element als untergeordnetes Element des LocalizedStrings-Elements ein, um den Namen und die Beschreibungen für mehrere Gebietsschemas für jedes Element zu speichern. Das Resource-Element enthält ein erforderliches idRef-Attribut, das dem entsprechenden idRef-Attribut für jedes element entspricht, das lokalisiert wird. Die untergeordneten Locale-Elemente des Resource-Elements enthalten den lokalisierten Namen und die Beschreibungen für jedes angegebene Gebietsschema.
<LocalizedStrings>
<Resource idRef="guid">
<Locale langcode="en-US" default="true">
<Name>affinity name en-us</Name>
<Description>
affinity description en-us
</Description>
</Locale>
<Locale langcode="de">
<Name>affinity name de</Name>
<Description>
affinity description de
</Description>
</Locale>
</Resource>
</LocalizedStrings>
XML-Schema-Definition des Klassifizierungsregelpakets
<?xml version="1.0" encoding="utf-8"?>
<xs:schema xmlns:mce="http://schemas.microsoft.com/office/2011/mce"
targetNamespace="http://schemas.microsoft.com/office/2011/mce"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified"
attributeFormDefault="unqualified"
id="RulePackageSchema">
<xs:simpleType name="LangType">
<xs:union memberTypes="xs:language">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value=""/>
</xs:restriction>
</xs:simpleType>
</xs:union>
</xs:simpleType>
<xs:simpleType name="GuidType" final="#all">
<xs:restriction base="xs:token">
<xs:pattern value="[0-9a-fA-F]{8}\-([0-9a-fA-F]{4}\-){3}[0-9a-fA-F]{12}"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RulePackageType">
<xs:sequence>
<xs:element name="RulePack" type="mce:RulePackType"/>
<xs:element name="Rules" type="mce:RulesType">
<xs:key name="UniqueRuleId">
<xs:selector xpath="mce:Entity|mce:Affinity"/>
<xs:field xpath="@id"/>
</xs:key>
<xs:key name="UniqueProcessorId">
<xs:selector xpath="mce:Regex|mce:Keyword"></xs:selector>
<xs:field xpath="@id"/>
</xs:key>
<xs:key name="UniqueResourceIdRef">
<xs:selector xpath="mce:LocalizedStrings/mce:Resource"/>
<xs:field xpath="@idRef"/>
</xs:key>
<xs:keyref name="ReferencedRuleMustExist" refer="mce:UniqueRuleId">
<xs:selector xpath="mce:LocalizedStrings/mce:Resource"/>
<xs:field xpath="@idRef"/>
</xs:keyref>
<xs:keyref name="RuleMustHaveResource" refer="mce:UniqueResourceIdRef">
<xs:selector xpath="mce:Entity|mce:Affinity"/>
<xs:field xpath="@id"/>
</xs:keyref>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="RulePackType">
<xs:sequence>
<xs:element name="Version" type="mce:VersionType"/>
<xs:element name="Publisher" type="mce:PublisherType"/>
<xs:element name="Details" type="mce:DetailsType">
<xs:key name="UniqueLangCodeInLocalizedDetails">
<xs:selector xpath="mce:LocalizedDetails"/>
<xs:field xpath="@langcode"/>
</xs:key>
<xs:keyref name="DefaultLangCodeMustExist" refer="mce:UniqueLangCodeInLocalizedDetails">
<xs:selector xpath="."/>
<xs:field xpath="@defaultLangCode"/>
</xs:keyref>
</xs:element>
<xs:element name="Encryption" type="mce:EncryptionType" minOccurs="0" maxOccurs="1"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="VersionType">
<xs:attribute name="major" type="xs:unsignedShort" use="required"/>
<xs:attribute name="minor" type="xs:unsignedShort" use="required"/>
<xs:attribute name="build" type="xs:unsignedShort" use="required"/>
<xs:attribute name="revision" type="xs:unsignedShort" use="required"/>
</xs:complexType>
<xs:complexType name="PublisherType">
<xs:attribute name="id" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="LocalizedDetailsType">
<xs:sequence>
<xs:element name="PublisherName" type="mce:NameType"/>
<xs:element name="Name" type="mce:RulePackNameType"/>
<xs:element name="Description" type="mce:OptionalNameType"/>
</xs:sequence>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:complexType>
<xs:complexType name="DetailsType">
<xs:sequence>
<xs:element name="LocalizedDetails" type="mce:LocalizedDetailsType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="defaultLangCode" type="mce:LangType" use="required"/>
</xs:complexType>
<xs:complexType name="EncryptionType">
<xs:sequence>
<xs:element name="Key" type="xs:normalizedString"/>
<xs:element name="IV" type="xs:normalizedString"/>
</xs:sequence>
</xs:complexType>
<xs:simpleType name="RulePackNameType">
<xs:restriction base="xs:token">
<xs:minLength value="1"/>
<xs:maxLength value="64"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="NameType">
<xs:restriction base="xs:normalizedString">
<xs:minLength value="1"/>
<xs:maxLength value="256"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="OptionalNameType">
<xs:restriction base="xs:normalizedString">
<xs:minLength value="0"/>
<xs:maxLength value="256"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="RestrictedTermType">
<xs:restriction base="xs:string">
<xs:minLength value="1"/>
<xs:maxLength value="512"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RulesType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Entity" type="mce:EntityType"/>
<xs:element name="Affinity" type="mce:AffinityType"/>
</xs:choice>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="Regex" type="mce:RegexType"/>
<xs:element name="Keyword" type="mce:KeywordType"/>
</xs:choice>
<xs:element name="LocalizedStrings" type="mce:LocalizedStringsType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="EntityType">
<xs:sequence>
<xs:element name="Pattern" type="mce:PatternType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
<xs:attribute name="patternsProximity" type="mce:ProximityType" use="required"/>
<xs:attribute name="recommendedConfidence" type="mce:ProbabilityType"/>
<xs:attribute name="workload" type="mce:WorkloadType"/>
</xs:complexType>
<xs:complexType name="PatternType">
<xs:sequence>
<xs:element name="IdMatch" type="mce:IdMatchType"/>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="confidenceLevel" type="mce:ProbabilityType" use="required"/>
</xs:complexType>
<xs:complexType name="AffinityType">
<xs:sequence>
<xs:element name="Evidence" type="mce:EvidenceType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
<xs:attribute name="evidencesProximity" type="mce:ProximityType" use="required"/>
<xs:attribute name="thresholdConfidenceLevel" type="mce:ProbabilityType" use="required"/>
<xs:attribute name="workload" type="mce:WorkloadType"/>
</xs:complexType>
<xs:complexType name="EvidenceType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="confidenceLevel" type="mce:ProbabilityType" use="required"/>
</xs:complexType>
<xs:complexType name="IdMatchType">
<xs:attribute name="idRef" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="MatchType">
<xs:attribute name="idRef" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="AnyType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="minMatches" type="xs:nonNegativeInteger" default="1"/>
<xs:attribute name="maxMatches" type="xs:nonNegativeInteger" use="optional"/>
</xs:complexType>
<xs:simpleType name="ProximityType">
<xs:restriction base="xs:positiveInteger">
<xs:minInclusive value="1"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="ProbabilityType">
<xs:restriction base="xs:integer">
<xs:minInclusive value="1"/>
<xs:maxInclusive value="100"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="WorkloadType">
<xs:restriction base="xs:string">
<xs:enumeration value="Exchange"/>
<xs:enumeration value="Outlook"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RegexType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="id" type="xs:token" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="KeywordType">
<xs:sequence>
<xs:element name="Group" type="mce:GroupType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="xs:token" use="required"/>
</xs:complexType>
<xs:complexType name="GroupType">
<xs:sequence>
<xs:choice>
<xs:element name="Term" type="mce:TermType" maxOccurs="unbounded"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="matchStyle" default="word">
<xs:simpleType>
<xs:restriction base="xs:NMTOKEN">
<xs:enumeration value="word"/>
<xs:enumeration value="string"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
<xs:complexType name="TermType">
<xs:simpleContent>
<xs:extension base="mce:RestrictedTermType">
<xs:attribute name="caseSensitive" type="xs:boolean" default="false"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="LocalizedStringsType">
<xs:sequence>
<xs:element name="Resource" type="mce:ResourceType" maxOccurs="unbounded">
<xs:key name="UniqueLangCodeUsedInNamePerResource">
<xs:selector xpath="mce:Name"/>
<xs:field xpath="@langcode"/>
</xs:key>
<xs:key name="UniqueLangCodeUsedInDescriptionPerResource">
<xs:selector xpath="mce:Description"/>
<xs:field xpath="@langcode"/>
</xs:key>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="ResourceType">
<xs:sequence>
<xs:element name="Name" type="mce:ResourceNameType" maxOccurs="unbounded"/>
<xs:element name="Description" type="mce:DescriptionType" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="idRef" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="ResourceNameType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="default" type="xs:boolean" default="false"/>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="DescriptionType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="default" type="xs:boolean" default="false"/>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:schema>