Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server
SQL Server
Eine verteilte Verfügbarkeitsgruppe (Availability Group, AG) ist eine spezielle Verfügbarkeitsgruppe, die zwei separate Verfügbarkeitsgruppen umfasst. Verteilte Verfügbarkeitsgruppen stehen ab SQL Server 2016 zur Verfügung.
In diesem Artikel wird das Feature für verteilte Verfügbarkeitsgruppen beschrieben. Informationen zum Konfigurieren einer verteilten Verfügbarkeitsgruppe finden Sie unter Configure distributed availability groups (Konfigurieren von verteilten Verfügbarkeitsgruppen).
Übersicht
Eine verteilte Verfügbarkeitsgruppe ist ein spezieller Typ einer Verfügbarkeitsgruppe, der zwei separate Verfügbarkeitsgruppen umfasst. Die Verfügbarkeitsgruppen, die Teil einer verteilten Verfügbarkeitsgruppe sind, müssen sich nicht am selben Ort befinden. Sie können physisch, virtuell, lokal, in der öffentlichen Cloud oder an einem sonstigen Ort sein, der die Bereitstellung von Verfügbarkeitsgruppen unterstützt. Dazu gehört die domänen- und plattformübergreifende Konfiguration, z.B. zwischen einer Verfügbarkeitsgruppe unter Linux und einer unter Windows. Solange zwei Verfügbarkeitsgruppen kommunizieren können, können Sie mit diesen eine verteilte Verfügbarkeitsgruppe konfigurieren.
Eine herkömmliche Verfügbarkeitsgruppe hat Ressourcen, die in einem Windows Server Failover Cluster (WSFC) oder unter Linux mit Pacemaker konfiguriert sind. Eine verteilte Verfügbarkeitsgruppe konfiguriert nichts im zugrunde liegenden Cluster (WSFC oder Pacemaker). Sie wird vollständig in SQL Server verwaltet. Informationen zum Anzeigen der Informationen für eine verteilte Verfügungsgruppe finden Sie unter Viewing distributed availability group information (Anzeigen der Informationen für eine verteilte Verfügbarkeitsgruppe).
Bei einer verteilten Verfügbarkeitsgruppe ist erforderlich, dass die zugrunde liegenden Verfügbarkeitsgruppen über einen Listener verfügen. Anstatt den zugrundeliegenden Servernamen für eine eigenständige Instanz (oder bei einer SQL Server-Failoverclusterinstanz (FCI) den Wert, der der Netzwerknamenressource zugeordnet ist) bereitzustellen, wie es bei einer herkömmlichen Verfügbarkeitsgruppe üblich ist, geben Sie beim Erstellen den für die verteilte Verfügbarkeitsgruppe konfigurierten Listener mithilfe des Parameters „ENDPOINT_URL“ an. Obwohl jede zugrunde liegende Verfügbarkeitsgruppe der verteilten Verfügbarkeitsgruppe einen Listener hat, hat eine verteilte Verfügbarkeitsgruppe keinen Listener.
In der folgenden Abbildung finden Sie eine Ansicht auf höchster Ebene für eine verteilte Verfügbarkeitsgruppe, die zwei Verfügbarkeitsgruppen (AG 1 und AG 2) umfasst, von der jede in ihrem eigenen WSFC konfiguriert wurde. Die verteilte Verfügbarkeitsgruppe besitzt zwei Replikate in jeder Verfügbarkeitsgruppe, also insgesamt vier Replikate. Jede Verfügbarkeitsgruppe kann die maximale Anzahl von Replikaten unterstützen. Eine verteilte Verfügbarkeitsgruppe kann also insgesamt bis zu 18 Replikate einschließen.
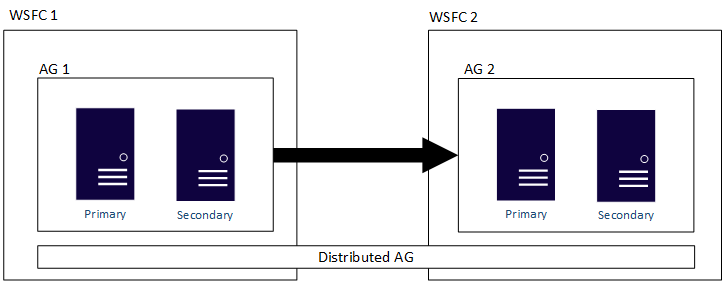
Sie können die Datenverschiebung in verteilten Verfügbarkeitsgruppen als „synchron“ oder „asynchron“ konfigurieren. Die Datenverschiebung innerhalb von verteilten Verfügbarkeitsgruppen weicht jedoch geringfügig von der in einer herkömmlichen Verfügbarkeitsgruppe ab. Obwohl jede Verfügbarkeitsgruppe über ein primäres Replikat verfügt, kann nur eine Kopie der Datenbanken, die Teil einer verteilten Verfügbarkeitsgruppe sind, Einfügungen, Updates und Löschungen akzeptieren. AG 1 ist die primäre Verfügbarkeitsgruppe, wie in der folgenden Abbildung dargestellt. Das primäre Replikat sendet Transaktionen an das sekundäre Replikat von AG 1 und an das primäre Replikat von AG 2. Das primäre Replikat von AG 2 ist auch als Forwarder bekannt. Ein Forwarder ist ein primäres Replikat in einer sekundären Verfügbarkeitsgruppe einer verteilten Verfügbarkeitsgruppe. Der Weiterleiter empfängt Transaktionen vom primären Replikat in der primären Verfügbarkeitsgruppe und leitet diese an die sekundären Replikate in der eigenen Verfügbarkeitsgruppe weiter. Der Weiterleitungsdienst hält dann die sekundären Replikate von AG 2 auf dem neuesten Stand.
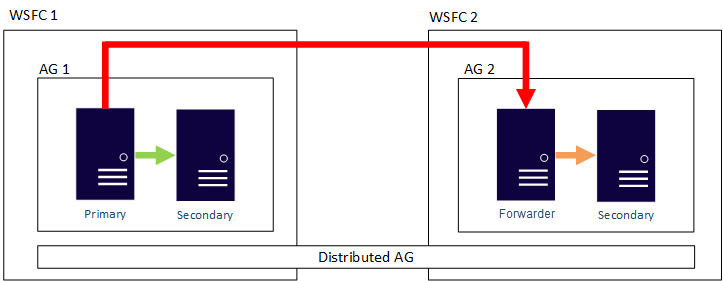
Die einzige Möglichkeit, dem primären Replikat von AG 2 das Akzeptieren von Einfügungen, Updates und Löschungen zu ermöglichen, besteht im Auslösen eines manuellen Failovers der verteilten Verfügbarkeitsgruppe von AG 1. In der obigen Abbildung enthält AG 1 die beschreibbare Kopie der Datenbank, deshalb macht das Auslösen eines Failovers AG 2 zu der Verfügbarkeitsgruppe, die Einfügungen, Updates und Löschungen verarbeiten kann. Weitere Informationen darüber, wie ein Failover von einer verteilten Verfügbarkeitsgruppe zu einer anderen durchgeführt wird, finden Sie unter Failover to a secondary availability group (Failover auf eine sekundäre Verfügbarkeitsgruppe).
Hinweis
- Verteilte Verfügbarkeitsgruppen in SQL Server 2016 unterstützen Failover nur von einer Verfügbarkeitsgruppe zu einer anderen mithilfe der Option
FORCE_FAILOVER_ALLOW_DATA_LOSS. - Wenn Sie die Transaktionsreplikation mit verteilten Verfügbarkeitsgruppen verwenden, kann das Weiterleitungsreplikat nicht als Verleger konfiguriert werden.
SQL Server 2025-Änderungen
SQL Server 2025 (17.x) führt die folgenden Änderungen ein:
Verbesserung der verteilten AG-Synchronisierung
SQL Server 2025 (17.x) führt eine Änderung des internen Synchronisierungsmechanismus für verteilte Verfügbarkeitsgruppen ein, um die Synchronisierungsleistung zu verbessern, indem die Netzwerksättigung reduziert wird, wenn sich das Weiterleitungsreplikat im asynchronen Commitmodus befindet. Diese Änderung ist standardmäßig aktiviert und erfordert keine Konfiguration.
Hinweis
Das Konfigurieren Ihrer verteilten Verfügbarkeitsgruppe mit einem Konflikt zwischen den Verfügbarkeitsmodi der beiden zugrunde liegenden Verfügbarkeitsgruppen wird nicht empfohlen und kann die Synchronisierungslatenz einführen. Beide Verfügbarkeitsgruppen sollten mit demselben Verfügbarkeitsmodus (synchron oder asynchron) konfiguriert werden, um eine optimale Leistung und Synchronisierung sicherzustellen.
Unterstützung für enthaltene Verfügbarkeitsgruppen
SQL Server 2025 (17.x) bietet Unterstützung für eine verteilte enthaltene Verfügbarkeitsgruppe. Wenn Sie beabsichtigen, eine enthaltene AG als Weiterleitungsinstanz in einer verteilten Verfügbarkeitsgruppe zu verwenden, müssen Sie die enthaltene AG mithilfe der AUTOSEEDING_SYSTEM_DATABASES-Klausel für die WITH | CONTAINED-Option des Befehls CREATE AVAILABILITY GROUP erstellen.
Anforderungen an Version und Edition
Verteilte Verfügbarkeitsgruppen in SQL Server 2017 oder höher können verschiedene Hauptversionen von SQL Server in der gleichen verteilten Verfügbarkeitsgruppe kombinieren. Die AG, die das primäre Replikat für Lese-/Schreibzugriff enthält, kann dieselbe oder eine niedrigere Version haben als die anderen AGs, die an der verteilten Verfügbarkeitsgruppe teilnehmen. Die anderen AGs können dieselbe oder eine höhere Version haben. Dieses Szenario gilt für Upgrade- und Migrationsszenarios. Wenn die Verfügbarkeitsgruppe, die das primäre Replikat für Lese-/Schreibzugriff enthält, beispielsweise SQL Server 2016 aufweist, Sie jedoch per Migration oder Upgrade zu SQL Server 2017 oder höher wechseln möchten, können die anderen Verfügbarkeitsgruppen in der verteilten Verfügbarkeitsgruppe mit SQL Server 2017 konfiguriert werden.
Da das Feature der verteilten Verfügbarkeitsgruppen in SQL Server 2012 oder 2014 noch nicht existiert hat, können Verfügbarkeitsgruppen, die mit diesen Versionen erstellt wurden, nicht Teil von verteilten Verfügbarkeitsgruppen werden.
Hinweis
Abhängig von der Version von SQL Server können Sie beim Herstellen einer Verbindung mit Azure-Diensten (z. B. dem Link "Verwaltete Instanz") eine verteilte Verfügbarkeitsgruppe mit Standard-Edition oder eine Mischung aus Standard- und Enterprise-Editionen konfigurieren. Weitere Informationen finden Sie unter KB5016729.
Da zwei separate Verfügbarkeitsgruppen vorliegen, weicht der Installationsprozess für ein Service Pack oder ein kumulatives Update auf ein Replikat, das Teil einer verteilten Verfügbarkeitsgruppe ist, geringfügig von dem für eine herkömmliche Verfügbarkeitsgruppe ab:
Beginnen Sie mit dem Aktualisieren der Replikate der sekundären Verfügbarkeitsgruppe in der verteilten Verfügbarkeitsgruppe.
Patchen Sie die Replikate der primären Verfügbarkeitsgruppe in der verteilten Verfügbarkeitsgruppe.
Führen Sie, genau wie bei einer herkömmlichen Verfügbarkeitsgruppe, ein Failover der primären Verfügbarkeitsgruppe auf eines ihrer eigenen Replikate (nicht auf das primäre Replikat der sekundären Verfügbarkeitsgruppe) durch und patchen Sie dieses Replikat. Wenn kein anderes als das primäre Replikat vorhanden ist, ist ein manuelles Failover auf die sekundäre Verfügbarkeitsgruppe erforderlich.
Windows Server-Versionen und verteilte Verfügbarkeitsgruppen
Eine verteilte Verfügbarkeitsgruppe umfasst mehrere Verfügbarkeitsgruppen, jede auf ihrer eigenen zugrunde liegenden WSFC. Eine verteilte Verfügbarkeitsgruppe ist ein ausschließlich in SQL Server vorhandenes Konstrukt. Das bedeutet, dass die WSFC-Cluster, auf denen sich die einzelnen Verfügbarkeitsgruppen befinden, verschiedene Hauptversionen von Windows Server verwenden können. Die Hauptversionen von SQL müssen, wie im vorherigen Abschnitt erläutert wurde, identisch sein. Ähnlich wie bei der ersten Abbildung zeigt die folgende Abbildung AG 1 und AG 2 als Teil einer verteilten Verfügbarkeitsgruppe, aber jeder der WSFC-Cluster verwendet eine unterschiedliche Version von Windows Server.
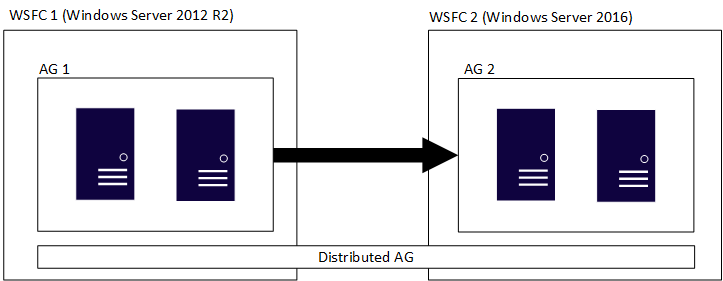
Für die einzelnen WSFC-Cluster und ihre entsprechenden Verfügbarkeitsgruppen gelten die herkömmlichen Regeln. Das bedeutet, dass sie mit einer Domäne verknüpft werden können oder nicht (Windows Server 2016 und höher). Wenn zwei verschiedene Verfügbarkeitsgruppen in einer einzigen verteilten Verfügbarkeitsgruppe vereint werden, gibt es vier Szenarios:
- Beide WSFC treten derselben Domäne bei.
- Jeder WSFC-Cluster wird mit einer unterschiedlichen Domäne verknüpft.
- Ein WSFC ist mit einer Domäne verknüpft, und ein WSFC ist nicht mit einer Domäne verknüpft.
- Keiner der WSFC-Cluster ist mit einer Domäne verknüpft.
Wenn beide WSFCs in derselben Domäne (nicht vertrauenswürdigen Domänen) verbunden sind, müssen Sie beim Erstellen der verteilten Verfügbarkeitsgruppe nichts Besonderes tun. Bei Verfügbarkeitsgruppen und WSFC-Clustern, die nicht mit derselben Domäne verknüpft sind, müssen Sie Zertifikate verwenden, damit die verteilte Verfügbarkeitsgruppe funktioniert. Dabei gehen Sie so ähnlich vor wie beim Erstellen einer Verfügbarkeitsgruppe für eine domänenunabhängige Verfügbarkeitsgruppe. Weitere Informationen zum Konfigurieren von Zertifikaten für eine verteilte Verfügbarkeitsgruppe finden Sie in den Schritten 3 bis 13 unter Create a domain-independent availability group (Erstellen einer domänenunabhängigen Verfügbarkeitsgruppe).
Bei einer verteilten Verfügbarkeitsgruppe müssen die primären Replikate in jeder zugrunde liegenden Verfügbarkeitsgruppe jeweils die Zertifikate der anderen besitzen. Wenn Sie bereits Endpunkte haben, die keine Zertifikate verwenden, konfigurieren Sie diese Endpunkte neu, indem Sie die Anweisung ALTER ENDPOINT verwenden, um das Verwenden von Zertifikaten anzuzeigen.
Verwendungsszenarios
Im Folgenden finden Sie die drei Hauptverwendungsszenarios für eine verteilte Verfügbarkeitsgruppe:
- Notfallwiederherstellung und vereinfachte Konfigurationen für mehrere Standorte
- Migration zu neuer Hardware oder neuen Konfigurationen, die möglicherweise das Verwenden neuer Hardware oder das Ändern des zugrunde liegenden Betriebssystems erfordert
- Erhöhen der Anzahl der lesbaren Replikate auf mehr als acht in einer einzigen Verfügbarkeitsgruppe, indem mehrere Verfügbarkeitsgruppen umfasst werden
Szenarios für Notfallwiederherstellung und mehrere Standorte
Bei einer herkömmlichen Verfügbarkeitsgruppe ist erforderlich, dass alle Server Teil desselben WSFC-Clusters sind, wodurch das Umfassen mehrerer Rechenzentren eine Herausforderung darstellen kann. Die folgende Abbildung zeigt eine herkömmliche Architektur für eine Verfügbarkeitsgruppe mit mehreren Standorten, einschließlich des Datenflusses. Es gibt ein primäres Replikat, das Transaktionen an alle sekundären Replikate sendet. Diese Konfiguration ist in mancher Hinsicht weniger umfassend als eine verteilte Verfügbarkeitsgruppe. Sie müssen beispielsweise Elemente wie Active Directory (sofern vorhanden) und den Zeugen für ein Quorum in den WSFC-Cluster implementieren. Sie müssen gegebenenfalls auch andere Aspekte eines WSFC berücksichtigen, zum Beispiel das Ändern von Knotenstimmen.

Verteilte Verfügbarkeitsgruppen bieten ein flexibleres Bereitstellungsszenario für Verfügbarkeitsgruppen, die mehrere Rechenzentren umfassen. Sie können sogar verteilte Verfügbarkeitsgruppen in Szenarien wie der Notfallwiederherstellung verwenden, wo in der Vergangenheit Funktionen wie der Protokollversand genutzt wurden. Im Gegensatz zum Protokollversand kann bei verteilten Verfügbarkeitsgruppen die Anwendung von Transaktionen jedoch nicht verzögert werden. Das bedeutet, dass weder Verfügbarkeitsgruppen noch verteilte Verfügbarkeitsgruppen im Fall eines menschlichen Fehlers, bei dem Daten fälschlicherweise aktualisiert oder gelöscht werden, helfen können.
Verteilte Verfügbarkeitsgruppen sind lose gekoppelt, was in diesem Fall bedeutet, dass sie keinen einzelnen WSFC-Cluster erfordern und von SQL Server verwaltet werden. Da die WSFC-Cluster einzeln verwaltet werden und die Synchronisation zwischen den beiden Verfügbarkeitsgruppen in erster Linie asynchron abläuft, ist die Konfiguration der Notfallwiederherstellung auf einer anderen Website einfacher. Die primären Replikate in jeder Verfügbarkeitsgruppe synchronisieren ihre eigenen sekundären Replikate.
- Für eine verteilte Verfügbarkeitsgruppe wird nur manuelles Failover unterstützt. Im Fall einer Notfallwiederherstellung, bei der Sie die Rechenzentren wechseln müssen, sollten Sie kein automatisches Failover konfigurieren (von wenigen Ausnahmen abgesehen).
- Sie müssen einige der herkömmlichen Elemente oder Parameter für WSFC-Cluster für Subnetze oder mehrere Standorte (z. B: CrossSubnetTreshold) wahrscheinlich nicht festlegen, aber Sie müssen sich dennoch um die Netzwerklatenz auf einer anderen Ebene für den Datentransport kümmern. Der Unterschied besteht darin, dass jeder WSFC-Cluster seine eigene Verfügbarkeit verwaltet, der Cluster ist also keine große Entität mit vier Knoten. Sie haben zwei separate WSFCs mit jeweils zwei Knoten, wie in der vorherigen Abbildung dargestellt.
- Wir empfehlen eine asynchrone Datenverschiebung, da diese Vorgehensweise für die Notfallwiederherstellung verwendet wird.
- Wenn Sie eine synchrone Datenverschiebung zwischen dem primären Replikat und mindestens einem sekundären Replikat der sekundären Verfügbarkeitsgruppe konfigurieren, und Sie die synchrone Verschiebung auf der verteilten Verfügbarkeitsgruppe konfigurieren, wird die verteilte Verfügbarkeitsgruppe warten, bis alle synchronen Kopien bestätigen, dass sie die Daten empfangen haben. Wenn mehrere verteilte Verfügbarkeitsgruppen verkettet wurden (AG1 -> AG2 -> AG3) und auf „synchron“ festgelegt sind, wartet jede verteilte Verfügbarkeitsgruppe, bis das letzte Replikat der vorherigen Verfügbarkeitsgruppe aktualisiert wurde.
Migrieren
Da verteilte Verfügbarkeitsgruppen auch zwei vollkommen unterschiedliche Konfigurationen von Verfügbarkeitsgruppen unterstützen, ermöglichen diese nicht nur eine einfachere Notfallwiederherstellung und Szenarios für mehrere Standorte, sondern auch Migrationsszenarios. Unabhängig davon, ob Sie zu neuer Hardware oder virtuellen Computern (lokal oder durch IaaS in der öffentlichen Cloud) migrieren, ermöglicht eine verteilte Verfügbarkeitsgruppe das Ausführen einer Migration in Fällen, in denen Sie vormals Sicherungen, Kopien und Wiederherstellungen oder Protokollversand verwendet haben.
Die Migration ist besonders nützlich in Szenarios, in denen Sie das zugrunde liegende Betriebssystem ändern oder aktualisieren, während Sie dieselbe Version von SQL Server behalten. Obwohl Windows Server 2016 ein paralleles Upgrade von Windows Server 2012 R2 auf derselben Hardware zulässt, entscheiden sich die meisten Benutzer für das Bereitstellen von neuer Hardware oder virtuellen Computern.
Beenden Sie am Ende des Migrationsprozesses den gesamten Datenverkehr zur ursprünglichen Verfügbarkeitsgruppe, und ändern Sie die verteilte Verfügbarkeitsgruppe zur synchronen Datenverschiebung, um die Migration zur neuen Konfiguration abzuschließen. Diese Aktion gewährleistet, dass das primäre Replikat der sekundären Verfügbarkeitsgruppe vollständig synchronisiert wird, sodass keine Daten verloren gehen. Nachdem Sie die Synchronisierung überprüft haben, führen Sie ein Failover der verteilten Verfügbarkeitsgruppe zur sekundären Verfügbarkeitsgruppe durch. Weitere Informationen finden Sie unter Fail over to a secondary availability group (Failover auf eine sekundäre Verfügbarkeitsgruppe).
Nach der Migration ist die sekundäre Verfügbarkeitsgruppe nun die neue primäre Verfügbarkeitsgruppe, und Sie müssen eventuell einen der folgenden Schritte durchführen:
- Benennen Sie den Listener auf der sekundären Verfügbarkeitsgruppe um (und löschen oder benennen Sie den alten Listener auf der ursprünglichen primären Verfügbarkeitsgruppe nach Möglichkeit um), oder erstellen Sie ihn mithilfe des Listeners auf der ursprünglichen primären Verfügbarkeitsgruppe neu, sodass Anwendungen und Benutzer auf die neue Konfiguration zugreifen können.
- Wenn eine Umbenennung oder Neuerstellung nicht möglich ist, verweisen Sie Anwendungen und Benutzer auf den Listener in der sekundären Verfügbarkeitsgruppe.
Migrieren zu höheren SQL Server-Versionen
In einem Migrationsszenario ist es zwar möglich, eine verteilte Verfügbarkeitsgruppe so zu konfigurieren, dass Ihre Datenbanken zu einem SQL Server-Ziel migriert werden, das eine höhere Version als die Quelle hat, es gibt jedoch einige Einschränkungen.
Wenn Sie die verteilte Verfügbarkeitsgruppe mit einem SQL Server-Migrationsziel konfigurieren, das eine höhere Version als die Quelle aufweist, wird automatisches Seeding nicht unterstützt. Daher muss der Seedingmodus auf MANUAL festgelegt werden. Wenn Sie AUTO-SEEDING nicht deaktivieren, tritt bei Ihrer Migration ein Fehler auf, und die Fehlermeldung 946 „Datenbank 'DistributionAG', Version xxx, kann nicht geöffnet werden. Aktualisieren Sie die Datenbank auf die neueste Version“ wird im Fehlerprotokoll angezeigt. Sie müssen den Seeding-Modus auf MANUELL festlegen und eine vollständige Sicherung sowie eine Transaktionsprotokollsicherung der Quelldatenbank manuell aus der primären Verfügbarkeitsgruppe durchführen. Stellen Sie sie dann zusammen mit dem Transaktionsprotokoll manuell in der sekundären Verfügbarkeitsgruppe wieder her. Weitere Informationen zum Konfigurieren Ihrer verteilten Verfügbarkeitsgruppe finden Sie in den Schritten zum manuellen Seeding sowie in Skripts zum Sichern und Wiederherstellen Ihrer Datenbank von der primären Verfügbarkeitsgruppe in der sekundären Verfügbarkeitsgruppe.
Wenn die sekundäre Verfügbarkeitsgruppe (AG2) das Migrationsziel ist und diese eine höhere Version aufweist als die primäre Verfügbarkeitsgruppe (AG1), beachten Sie die folgenden Einschränkungen:
- Sie besitzen keinen Lesezugriff auf Replikatdatenbanken der sekundären Verfügbarkeitsgruppe, solange die primäre Verfügbarkeitsgruppe eine niedrigere Version aufweist.
- Während dieser Zeit werden Updates weiterhin von der primären Verfügbarkeitsgruppe (AG1) zur sekundären Verfügbarkeitsgruppe (AG2) übertragen. Der Status der sekundären Verfügbarkeitsgruppe wird jedoch als „Teilweise fehlerfrei“ angezeigt, und Datenbanken auf sekundären Replikaten der sekundären Verfügbarkeitsgruppe (AG2) werden mit dem Status „Wird synchronisiert/wiederhergestellt“ angezeigt (auch wenn sich die Verfügbarkeitsgruppe im Synchronisierungscommit befindet).
- Sobald für die verteilte Verfügbarkeitsgruppe ein Failover auf die höhere Version (AG2) durchgeführt wurde, sollte AG2 „Gesund“ werden.
- Während dieser Zeit ist ein Failback auf AG1 nicht möglich, da es sich in einer niedrigeren Version befindet.
- Da AG1 eine niedrigere Version hat, werden Updates von AG2 nach dem Failover auf AG2 nicht in AG1 repliziert.
- Wählen Sie an diesem Punkt aus, ob Sie die ursprüngliche (primäre) Verfügbarkeitsgruppe (AG) außer Betrieb nehmen oder AG1 aktualisieren und die verteilte Verfügbarkeitsgruppe beibehalten möchten.
- Wenn Sie AG1 außer Betrieb nehmen möchten, entfernen Sie die ursprüngliche primäre AG aus der verteilten AG. Damit ist der Prozess abgeschlossen.
- Wenn Sie sich dafür entscheiden, die verteilte AG beizubehalten, dann führen Sie ein Upgrade der SQL Server-Version für AG1 durch, um der von AG2 zu entsprechen. Nach dem Upgrade von AG1 werden sowohl AG1 als auch die verteilte Verfügbarkeitsgruppe als fehlerfrei angezeigt, die Replikate können synchronisiert werden, und ein Failback wird möglich.
Aufskalieren lesbarer Replikate
Eine einzelne verteilte Verfügbarkeitsgruppe kann je nach Bedarf bis zu 16 sekundäre Replikate enthalten. Sie kann daher bis zu 18 Lesekopien haben, einschließlich der zwei primären Replikate der unterschiedlichen Verfügbarkeitsgruppen. Dieser Ansatz bedeutet, dass mehr als eine Website beinahe Echtzeitzugriff haben kann, um Berichte an zahlreiche Anwendungen zu senden.
Verteilte Verfügbarkeitsgruppen können Ihnen helfen, eine schreibgeschützte Farm stärker auszuweiten, als es mit nur einer einzigen Verfügbarkeitsgruppe möglich ist. Für das horizontale Hochskalieren von lesbaren Replikaten mit einer verteilten Verfügbarkeitsgruppe gibt es zwei Möglichkeiten:
- Sie können das primäre Replikat der zweiten Verfügbarkeitsgruppe in einer verteilten Verfügbarkeitsgruppe zum Erstellen einer weiteren verteilten Verfügbarkeitsgruppe verwenden, auch wenn sich die Datenbank nicht im Status „RECOVERY“ befindet.
- Sie können auch das primäre Replikat der primären Verfügbarkeitsgruppe verwenden, um eine weitere verteilte Verfügbarkeitsgruppe zu erstellen.
Das heißt, ein primäres Replikat kann an unterschiedlichen verteilten Verfügbarkeitsgruppen teilnehmen. Die folgende Abbildung zeigt AG 1 und AG 2, die beide Teil der verteilten AG 1 sind, während AG 2 und AG 3 Teil der verteilten AG 2 sind. Das primäre Replikat (oder die Weiterleitung) von AG 2 ist sowohl ein sekundäres Replikat für Distributed AG 1 als auch ein primäres Replikat von Distributed AG 2.
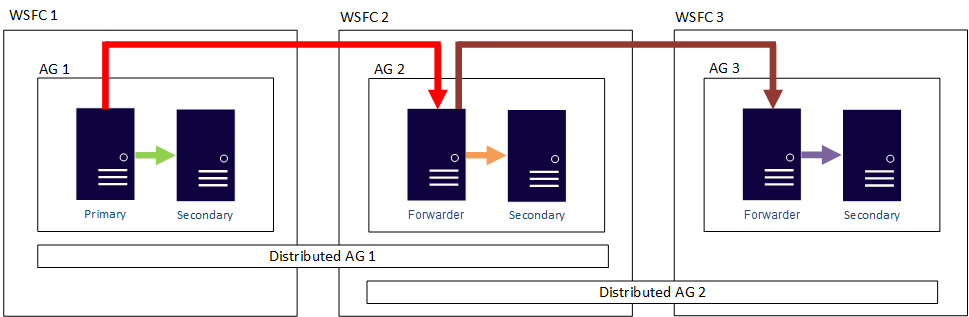
Die folgende Abbildung zeigt AG 1 als das primäre Replikat von zwei unterschiedlichen verteilten Verfügbarkeitsgruppen: Distributed AG 1 (bestehend aus AG 1 und AG 2) und Distributed AG 2 (bestehend aus AG 1 und AG 3).
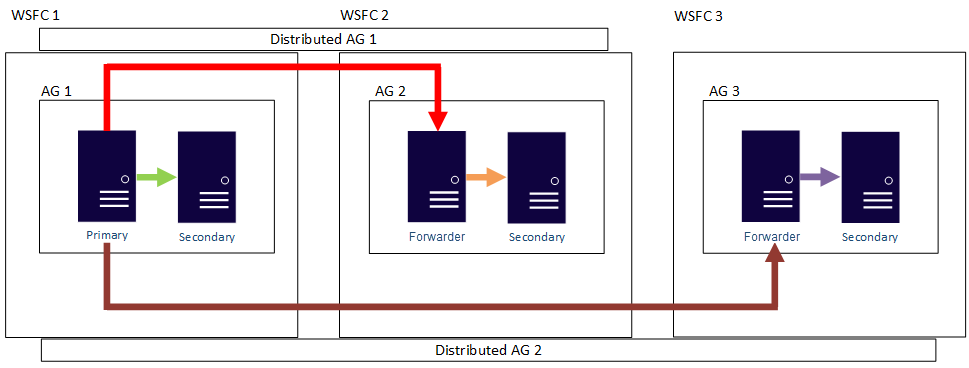
In den beiden obigen Beispielen können insgesamt bis zu 27 Replikate in den drei Verfügbarkeitsgruppen vorhanden sein, von denen jedes für schreibgeschützte Abfragen verwendet werden kann.
Schreibgeschütztes Routing funktioniert nur eingeschränkt mit verteilten Verfügbarkeitsgruppen. Dies umfasst insbesondere Folgendes:
- Schreibgeschütztes Routing kann konfiguriert werden und funktioniert für die primäre Verfügbarkeitsgruppe der verteilten Verfügbarkeitsgruppe.
- Das Read-Only Routing kann konfiguriert werden, funktioniert jedoch nicht für die sekundäre Verfügbarkeitsgruppe innerhalb der verteilten Verfügbarkeitsgruppe. Alle Abfragen, die den Listener verwenden, um eine Verbindung mit der sekundären Verfügbarkeitsgruppe herzustellen, werden an das primäre Replikat der sekundären Verfügbarkeitsgruppe weitergeleitet. Andernfalls müssen Sie jedes Replikat so konfigurieren, dass alle Verbindungen als sekundäres Replikat zugelassen werden und direkt auf diese zugegriffen wird. Das schreibgeschützte Routing funktioniert jedoch, wenn die sekundäre Verfügbarkeitsgruppe nach einem Failover zur primären Verfügbarkeitsgruppe wird. Dieses Verhalten wird mit einem Update zu SQL Server 2016 oder in einer zukünftigen Version von SQL Server möglicherweise geändert.
Initialisieren sekundärer Verfügbarkeitsgruppen
Verteilte Verfügbarkeitsgruppen wurden mit automatischem Seeding als Hauptmethode zum Initialisieren des primären Replikats auf die sekundäre Verfügbarkeitsgruppe entwickelt. Eine vollständige Wiederherstellung einer Datenbank auf dem primären Replikat der sekundären Verfügbarkeitsgruppe ist möglich, wenn Sie folgende Aktionen durchführen:
- Stellen Sie die Datenbanksicherung mit „WITH NORECOVERY“ wieder her.
- Falls nötig, stellen Sie die richtigen Sicherungen der Transaktionsprotokolle mit „WITH NORECOVERY“ wieder her.
- Erstellen Sie die sekundäre Verfügbarkeitsgruppe ohne einen Datenbanknamen anzugeben, und legen Sie SEEDING_MODE auf AUTOMATIC fest.
- Erstellen Sie die verteilte Verfügbarkeitsgruppe mithilfe von automatischem Seeding.
Wenn Sie das primäre Replikat der sekundären Verfügbarkeitsgruppe zu der verteilten Verfügbarkeitsgruppe hinzufügen, wird das Replikat mit der primären Datenbank der primären Verfügbarkeitsgruppe verglichen und die Datenbank wird durch automatisches Seeding auf den gleichen Stand wie die Quelle gebracht. Es gibt einige Vorbehalte:
Die Ausgabe, die in
sys.dm_hadr_automatic_seedingauf dem primären Replikat der zweiten Verfügbarkeitsgruppe angezeigt wird, zeigt eincurrent_statevon „FAILED“ mit der Fehlermeldung „Seeding Check Message Timeout“.Das aktuelle SQL Server-Fehlerprotokoll auf dem primären Replikat der sekundären Verfügbarkeitsgruppe wird anzeigen, dass das automatische Seeding erfolgreich war und dass die LSNs synchronisiert wurden.
Die in
sys.dm_hadr_automatic_seedingauf dem primären Replikat der ersten Verfügbarkeitsgruppe angezeigte Ausgabe zeigt einen current_state von COMPLETED an.Das automatische Seeding weist bei verteilten Verfügbarkeitsgruppen ebenfalls ein unterschiedliches Verhalten auf. Damit das automatische Seeding auf dem sekundären Replikat beginnt, müssen Sie den Befehl
ALTER AVAILABILITY GROUP [AGName] GRANT CREATE ANY DATABASEauf dem Replikat ausführen. Obwohl diese Bedingung immer noch auf jedes sekundäre Replikat zutrifft, das Teil der zugrunde liegenden Verfügbarkeitsgruppe ist, verfügt das primäre Replikat der sekundären Verfügbarkeitsgruppe schon über die erforderlichen Berechtigungen, um mit dem automatischen Seeding zu beginnen, nachdem es zu der verteilten Verfügbarkeitsgruppe hinzugefügt wurde.
Hinweis
- Die sekundäre Verfügbarkeitsgruppe muss denselben Datenbankspiegelungsendpunkt verwenden. Andernfalls stoppt die Replikation nach einem lokalen Failover.
- Die zugrunde liegenden Verfügbarkeitsgruppen sollten sich im gleichen Verfügbarkeitsmodus befinden – entweder sollten sich beide Verfügbarkeitsgruppen im synchronen Commitmodus befinden, oder beide sollten sich im asynchronen Commitmodus befinden. Wenn Sie nicht sicher sind, welche Option Sie verwenden sollen, stellen Sie beide auf den asynchronen Commit-Modus, bis Sie bereit sind, ein Failover durchzuführen.
Gesundheitsüberwachung
Eine verteilte Verfügbarkeitsgruppe ist ein nur in SQL Server verfügbares Konstrukt und wird nicht im zugrunde liegenden WSFC-Cluster angezeigt. Das folgende Codebeispiel zeigt zwei unterschiedliche WSFC-Cluster („CLUSTER_A“ und „CLUSTER_B“), von denen jedes seine eigenen Verfügbarkeitsgruppen besitzt. Im Folgenden werden nur AG 1 in „CLUSTER_A“ und AG 2 in „CLUSTER_B“ erläutert.
PS C:\> Get-ClusterGroup -Cluster CLUSTER_A
Name OwnerNode State
---- --------- -----
AG1 DENNIS Online
Available Storage GLEN Offline
Cluster Group JY Online
New_RoR DENNIS Online
Old_RoR DENNIS Online
SeedingAG DENNIS Online
PS C:\> Get-ClusterGroup -Cluster CLUSTER_B
Name OwnerNode State
---- --------- -----
AG2 TOMMY Online
Available Storage JC Offline
Cluster Group JC Online
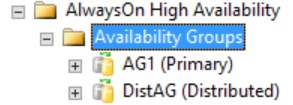
Die detaillierten Informationen über eine verteilte Verfügbarkeitsgruppe befindet sich in SQL Server, insbesondere in den dynamischen Verwaltungsansichten für Verfügbarkeitsgruppen. Derzeit werden Informationen über verteilte Verfügbarkeitsgruppen in SQL Server Management Studio nur auf dem primären Replikat der Verfügbarkeitsgruppe angezeigt. Wie in der folgenden Abbildung dargestellt zeigt SQL Server Management Studio unter dem Ordner „Verfügbarkeitsgruppen“ an, dass es eine verteilte Verfügbarkeitsgruppe gibt. Die Abbildung zeigt AG1 als primäres Replikat einer einzelnen Verfügbarkeitsgruppe, die lokal für diese Instanz ist, nicht aber als das einer verteilten Verfügbarkeitsgruppe.
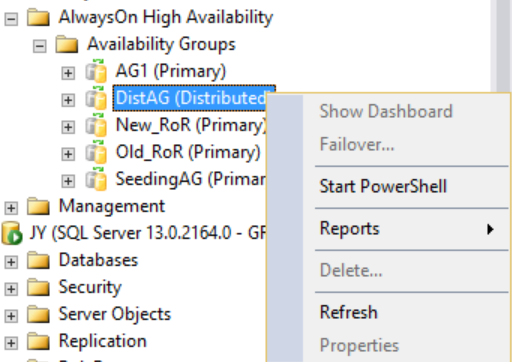
Wenn Sie jedoch mit der rechten Maustaste auf die verteilte Verfügbarkeitsgruppe klicken, sind keine Optionen verfügbar (siehe folgende Abbildung) und die erweiterten Verfügbarkeitsdatenbanken, Verfügbarkeitsgruppenlistener und Verfügbarkeitsreplikatordner sind alle leer. SQL Server Management Studio 16 zeigt dieses Ergebnis an, das sich jedoch in einer zukünftigen Version von SQL Server Management Studio ändern könnte.
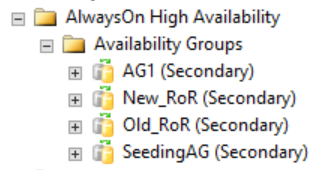
Wie in der folgenden Abbildung dargestellt zeigen sekundäre Replikate in SQL Server Management Studio nichts an, das sich auf die verteilte Verfügbarkeitsgruppe bezieht. Die Namen dieser Verfügbarkeitsgruppen können den Rollen zugeordnet werden, die im vorherigen Bild (CLUSTER_A – WSFC) angezeigt wurden.
DMV-Abfrage zur Auflistung aller Verfügbarkeitsreplikat-Namen
Die gleichen Konzepte gelten, wenn Sie die dynamischen Verwaltungsansichten verwenden. Indem Sie die folgende Abfrage verwenden, können Sie alle Verfügbarkeitsgruppen (reguläre und verteilte) und die enthaltenen Knoten anzeigen lassen. Dieses Ergebnis wird nur angezeigt, wenn Sie das primäre Replikat in einem der WSFCs abfragen, die an der verteilten Verfügbarkeitsgruppe teilnehmen. Es gibt eine neue Spalte namens sys.availability_groups in der dynamischen Verwaltungsansicht is_distributed, die den Wert „1“ enthält, wenn es sich bei der Verfügbarkeitsgruppe um eine verteilte Verfügbarkeitsgruppe handelt. Zum Anzeigen dieser Spalte ist Folgendes nötig:
-- shows replicas associated with availability groups
SELECT
ag.[name] AS [AG Name],
ag.Is_Distributed,
ar.replica_server_name AS [Replica Name]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id;
GO
In der folgenden Abbildung wird ein Beispiel für eine Ausgabe des zweiten WSFC-Clusters gezeigt, das an einer verteilten Verfügbarkeitsgruppe teilnimmt. SPAG1 besteht aus zwei Replikaten: DENNIS und JY. Die verteilte Verfügbarkeitsgruppe namens „SPDistAG“ verfügt jedoch über die Namen der zwei enthaltenen Verfügbarkeitsgruppen (SPAG1 und SPAG2) statt der Namen der Instanzen, wie es bei herkömmlichen Verfügbarkeitsgruppen der Fall ist.
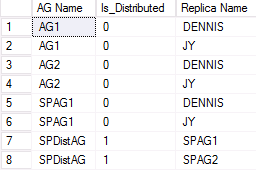
DMV zur Auflistung der verteilten AG-Gesundheit
Jeder Status, der in SQL Server Management Studio auf dem Dashboard und in anderen Bereichen angezeigt wird, ist nur für die lokale Synchronisierung innerhalb der betreffenden Verfügbarkeitsgruppe bestimmt. Führen Sie eine Abfrage der dynamischen Verwaltungsansichten durch, um den Zustand einer verteilten Verfügbarkeitsgruppe anzuzeigen. Die folgende Beispielabfrage erweitert und präzisiert die vorherige Abfrage:
-- shows sync status of distributed AG
SELECT
ag.[name] AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [Underlying AG],
ars.role_desc AS [Role],
ars.synchronization_health_desc AS [Sync Status]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

DMV, um die zugrunde liegende Leistung anzuzeigen
Sie können die vorherige Abfrage weiter erweitern, indem Sie sys.dm_hadr_database_replicas_states hinzufügen, um die zugrunde liegende Leistung in der dynamischen Verwaltungsansicht anzuzeigen. Die dynamische Verwaltungsansicht speichert derzeit nur Informationen über die zweite Verfügbarkeitsgruppe. Die folgende Beispielabfrage, die auf der primären Verfügbarkeitsgruppe ausgeführt wird, erzeugt die unten dargestellte Beispielausgabe:
-- shows underlying performance of distributed AG
SELECT
ag.[name] AS [Distributed AG Name],
ar.replica_server_name AS [Underlying AG],
dbs.[name] AS [Database],
ars.role_desc AS [Role],
drs.synchronization_health_desc AS [Sync Status],
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate
FROM sys.databases AS dbs
INNER JOIN sys.dm_hadr_database_replica_states AS drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups AS ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

DMV zur Betrachtung von Leistungszählern für verteilte AG
Die unten dargestellte Abfrage zeigt die Leistungsindikatoren an, die mit der betreffenden verteilten Verfügbarkeitsgruppe verknüpft sind.
-- displays OS performance counters related to the distributed ag named 'distributedag'
SELECT * FROM sys.dm_os_performance_counters WHERE instance_name LIKE '%distributed%'
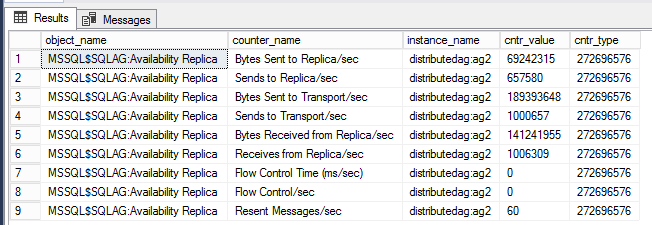
Hinweis
Der Filter LIKE muss den Namen der verteilten Verfügbarkeitsgruppe besitzen. In diesem Beispiel lautet der Name der verteilten Verfügbarkeitsgruppe „distributedag“. Ändern Sie den LIKE-Modifizierer, um den Namen Ihrer verteilten Verfügbarkeitsgruppe widerzuspiegeln.
DMV zur Anzeige des Gesundheitszustands der Verfügbarkeitsgruppe und der verteilten Verfügbarkeitsgruppe
Die folgende Abfrage zeigt eine Fülle von Informationen über den Zustand der Verfügbarkeitsgruppe und der verteilten Verfügbarkeitsgruppe an. (Reproduziert mit der Erlaubnis von Tracy Boggiano.)
-- displays sync status, send rate, and redo rate of availability groups,
-- including distributed AG
SELECT ag.name AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [AG],
dbs.name AS [Database],
ars.role_desc,
drs.synchronization_health_desc,
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate,
drs.suspend_reason_desc,
drs.last_sent_time,
drs.last_received_time,
drs.last_hardened_time,
drs.last_redone_time,
drs.last_commit_time,
drs.secondary_lag_seconds
FROM sys.databases dbs
INNER JOIN sys.dm_hadr_database_replica_states drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas ar
ON ar.replica_id = ars.replica_id
--WHERE ag.is_distributed = 1
GO

DMVs zum Anzeigen von Metadaten der verteilten Verfügbarkeitsgruppe
Die folgende Abfragen zeigt Informationen über Endpunkt-URLs an, die von den Verfügbarkeitsgruppen verwendet werden, einschließlich der verteilten Verfügbarkeitsgruppe. (Reproduziert mit Erlaubnis von David Barbarin.)
-- shows endpoint url and sync state for ag, and dag
SELECT
ag.name AS group_name,
ag.is_distributed,
ar.replica_server_name AS replica_name,
ar.endpoint_url,
ar.availability_mode_desc,
ar.failover_mode_desc,
ar.primary_role_allow_connections_desc AS allow_connections_primary,
ar.secondary_role_allow_connections_desc AS allow_connections_secondary,
ar.seeding_mode_desc AS seeding_mode
FROM sys.availability_replicas AS ar
JOIN sys.availability_groups AS ag
ON ar.group_id = ag.group_id;
GO

DMV zum Anzeigen des aktuellen Seedingstatus
Die folgende Abfrage zeigt Informationen zum aktuellen Seedingstatus an. Dies ist nützlich für die Problembehandlung von Synchronisierungsfehlern zwischen Replikaten. (Reproduziert mit Erlaubnis von David Barbarin.)
-- shows current_state of seeding
SELECT ag.name AS aag_name,
ar.replica_server_name,
d.name AS database_name,
has.current_state,
has.failure_state_desc AS failure_state,
has.error_code,
has.performed_seeding,
has.start_time,
has.completion_time,
has.number_of_attempts
FROM sys.dm_hadr_automatic_seeding AS has
INNER JOIN sys.availability_groups AS ag
ON ag.group_id = has.ag_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = has.ag_remote_replica_id
INNER JOIN sys.databases AS d
ON d.group_database_id = has.ag_db_id;
GO
