Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server unter Linux
SQL Server unter Linux
Dieser Artikel bietet eine Übersicht über Lösungen für Geschäftskontinuität für Hochverfügbarkeit und Notfallwiederherstellung in SQL Server unter Windows und Linux.
Jeder, der SQL Server bereitstellt, muss sicherstellen, dass alle unternehmenskritischen SQL Server-Instanzen und die darin enthaltenen Datenbanken verfügbar sind, wenn die Geschäfts- und Endbenutzer sie benötigen, unabhängig davon, ob diese Verfügbarkeit in regelmäßigen Geschäftszeiten oder rund um die Uhr erfolgt. Das Ziel ist, das Unternehmen mit minimaler oder ohne Unterbrechung aufrechtzuerhalten. Dieses Konzept wird auch als Geschäftskontinuität bezeichnet.
SQL Server 2017 (14.x) und höhere Versionen haben Features und Verbesserungen für die Verfügbarkeit eingeführt. Die größte Ergänzung ist die Unterstützung für SQL Server auf Linux-Verteilungen. Eine vollständige Liste der neuen Features in SQL Server finden Sie in den folgenden Artikeln:
| Version | Betriebssystem |
|---|---|
| Neuerungen in SQL Server 2025 (17.x) | Windows | Linux |
| Neuerungen in SQL Server 2022 (16.x) | Windows | Linux |
| Neuerungen in SQL Server 2019 (15.x) | Windows | Linux |
| Neuerungen in SQL Server 2017 (14.x) | Windows | Linux |
Dieser Artikel konzentriert sich auf die Verfügbarkeitsszenarien in SQL Server 2017 (14.x) und höheren Versionen sowie auf die neuen und erweiterten Verfügbarkeitsfeatures. Zu den Szenarien gehören Hybridbereitstellungen, die SQL Server-Bereitstellungen sowohl unter Windows Server als auch unter Linux umfassen können, und solche, die die Anzahl der lesbaren Kopien einer Datenbank erhöhen können.
Dieser Artikel behandelt zwar keine Verfügbarkeitsoptionen außerhalb von SQL Server (z. B. Virtualisierung), aber alles, was hier behandelt wird, gilt für SQL Server-Installationen innerhalb eines virtuellen Gastcomputers, ob in der öffentlichen Cloud oder in einem lokalen Hypervisorserver gehostet.
SQL Server-Szenarien, die Verfügbarkeitsfeatures verwenden
Sie können AlwaysOn-Verfügbarkeitsgruppen, Failoverclusterinstanzen und Protokollversand auf unterschiedliche Weise und nicht nur für die Verfügbarkeit verwenden. Es gibt vier Hauptmethoden, wie Sie die Verfügbarkeitsfeatures verwenden können:
- Hochverfügbarkeit
- Notfallwiederherstellung
- Migrationen und Upgrades
- Horizontales Hochskalieren von lesbaren Kopien von einer oder mehreren Datenbanken
In den folgenden Abschnitten werden die relevanten Features für jedes Szenario beschrieben. Ein Feature, das nicht abgedeckt wird, ist die SQL Server-Replikation. Während die SQL Server-Replikation nicht offiziell als Verfügbarkeitsfeature unter dem Always On-Dach festgelegt ist, wird sie häufig verwendet, um Daten in bestimmten Szenarien redundant zu machen. Die Mergereplikation wird für SQL Server unter Linux nicht unterstützt. Weitere Informationen finden Sie unter SQL Server-Replikation unter Linux.
Wichtig
Die SQL Server-Verfügbarkeitsfeatures ersetzen nicht die Anforderung, eine robuste, gut getestete Sicherungs- und Wiederherstellungsstrategie zu haben. Eine Sicherungs- und Wiederherstellungsstrategie ist der grundlegendste Baustein jeder Verfügbarkeitslösung.
Hochverfügbarkeit
Es ist wichtig, sicherzustellen, dass SQL Server-Instanzen oder -Datenbanken verfügbar sind, wenn ein Problem auftritt, das lokal in einem Rechenzentrum oder einer einzelnen Region in der Cloud liegt. In diesem Abschnitt wird erläutert, wie die SQL Server-Verfügbarkeitsfeatures hilfreich sein können. Alle beschriebenen Features sind für Windows Server und Linux verfügbar.
Verfügbarkeitsgruppen
Verfügbarkeitsgruppen (Availability Groups, AGs) bieten Schutz auf Datenbankebene, indem jede Transaktion einer Datenbank an eine andere Instanz oder ein Replikat gesendet wird, das eine Kopie dieser Datenbank in einem speziellen Zustand enthält. Sie können eine AG auf den Standard- oder Enterprise-Editionen bereitstellen. Die Instanzen, die in einer Verfügbarkeitsgruppe enthalten sind, können eigenständig oder Always On-Failoverclusterinstanzen (FCIs, im nächsten Abschnitt beschrieben) sein. Da die Transaktionen direkt an ein Replikat gesendet werden, werden Verfügbarkeitsgruppen empfohlen, wenn Anforderungen für niedrigere Ziele bei Wiederherstellungspunkten und der Wiederherstellungszeit gelten. Das Verschieben von Daten zwischen Replikaten kann synchron oder asynchron erfolgen. Die Enterprise Edition unterstützt bis zu drei synchrone Replikate, einschließlich des primären Replikats. Eine Verfügbarkeitsgruppe enthält eine vollständige Lese-/Schreibkopie der Datenbank, die sich auf dem primären Replikat befindet. Sekundäre Replikate können keine Transaktionen direkt von Benutzer*innen oder Anwendungen empfangen.
Hinweis
Always On ist ein Überbegriff für die Verfügbarkeitsfeatures in SQL Server und schließt Verfügbarkeitsgruppen und FCIs ein. Always On ist nicht der Name des AG-Features.
Vor SQL Server 2022 (16.x) boten Verfügbarkeitsgruppen nur Schutz auf Datenbankebene und nicht auf Instanzebene. Alles, was nicht im Transaktionsprotokoll erfasst oder in der Datenbank konfiguriert ist, muss für jedes sekundäre Replikat manuell synchronisiert werden. Einige Beispiele für Objekte, die manuell synchronisiert werden müssen, sind Anmeldungen auf Instanzebene, Verbindungsserver und SQL Server-Agent-Aufträge.
In SQL Server 2022 (16.x) und höheren Versionen können Sie Metadatenobjekte wie Benutzer, Anmeldungen, Berechtigungen und SQL Server-Agent-Aufträge auf AG-Ebene zusätzlich zur Instanzebene verwalten. Weitere Informationen finden Sie unter Was ist eine eigenständige Verfügbarkeitsgruppe?
Eine Verfügbarkeitsgruppe besitzt eine weitere Komponente, die als Listener bezeichnet wird. Durch diesen können Anwendungen und Benutzer*innen eine Verbindung herstellen, ohne zu wissen, welche Instanz von SQL Server das primäre Replikat hostet. Jede AG verfügt über einen eigenen Listener. Die Implementierungen des Listeners unterscheiden sich zwar geringfügig unter Windows Server und Linux, bieten aber beide die gleiche Funktionalität und Nutzbarkeit. Das folgende Diagramm zeigt eine Windows Server-basierte AG, die einen Windows Server-Failovercluster (WSFC) verwendet. Ein zugrunde liegender Cluster auf der Betriebssystemebene ist für die Verfügbarkeit erforderlich, unabhängig davon, ob es sich auf Linux oder Windows Server befindet. Dieses Beispiel zeigt eine einfache Konfiguration für zwei Server oder Knoten, bei der ein WSFC den zugrunde liegenden Cluster darstellt.
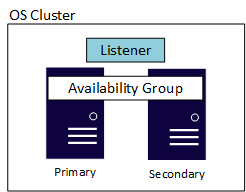
Bei Replikaten gelten für die Standard Edition und die Enterprise Edition unterschiedliche Höchstwerte. Eine Verfügbarkeitsgruppe in der Standard Edition, die als Basis-Verfügbarkeitsgruppe bezeichnet wird, unterstützt zwei Replikate (ein primäres und ein sekundäres) mit nur einer einzigen Datenbank in der Verfügbarkeitsgruppe. In der Enterprise Edition können nicht nur mehrere Datenbanken für eine einzige Verfügbarkeitsgruppe konfiguriert werden, sondern es können auch bis zu neun Replikate (ein primäres, acht sekundäre) verwendet werden. Die Enterprise Edition bietet weitere optionale Vorteile, z.B. lesbare sekundäre Replikate, das Erstellen von Sicherungen aus einem sekundären Replikat usw.
Hinweis
Die Datenbankspiegelung, die in SQL Server 2012 (11.x) als veraltet markiert wurde, ist in der Linux-Version von SQL Server weder verfügbar noch wird sie hinzugefügt. Kund*innen, die die Datenbankspiegelung immer noch verwenden, sollten die Migration zu Verfügbarkeitsgruppen planen, die den Ersatz für die Datenbankspiegelung darstellen.
Verfügbarkeitsgruppen können für die Verfügbarkeit entweder automatische oder manuelle Failover bereitstellen. Automatische Failover können auftreten, wenn die synchrone Datenverschiebung konfiguriert ist und die Datenbank auf dem primären und sekundären Replikat sich in einem synchronisierten Zustand befindet. Solange der Listener verwendet wird und die Anwendung eine unterstützte Version des .NET Frameworks (3.5 mit Service Pack 1 oder 4.6.2 und höher) nutzt, sollte das Failover mit minimaler bis keiner Auswirkung auf die Endbenutzer durchgeführt werden. Ein Failover zu einem sekundären Replikat, das dieses zum neuen primären Replikat macht, kann als automatisch oder manuell konfiguriert werden und wird im Allgemeinen in Sekunden gemessen.
In der folgenden Liste werden einige Unterschiede zwischen AGs auf Windows Server im Vergleich zu Linux hervorgehoben:
Aufgrund der Funktionsweise des zugrunde liegenden Clusters unter Linux und Windows Server werden alle AG-Failovers (manuell oder automatisch) über den Cluster unter Linux durchgeführt. Bei Bereitstellungen von Windows Server-basierten Verfügbarkeitsgruppen müssen manuelle Failover über SQL Server ausgeführt werden. Automatische Failover werden unter Windows Server und Linux von den zugrunde liegenden Clustern behandelt.
Für SQL Server unter Linux sollten Sie eine Verfügbarkeitsgruppe (AG) mit mindestens drei Replikaten konfigurieren, da dies für das zugrunde liegende Clustering erforderlich ist.
Unter Linux wird der gemeinsame Name, der von jedem Listener verwendet wird, in DNS und nicht im Cluster definiert, wie er sich auf Windows Server befindet.
SQL Server 2017 (14.x) hat die folgenden Features und Verbesserungen für AGs eingeführt:
- Clustertypen
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT- Erweiterte MS DTC-Unterstützung (Microsoft Distributed Transaction Coordinator) für Windows Server-basierte Konfigurationen
- Zusätzliche Szenarios für das horizontale Hochskalieren von schreibgeschützten Datenbanken (später in diesem Artikel beschrieben)
Clustertypen für Verfügbarkeitsgruppen
Das integrierte Verfügbarkeitsformular des Clusterings in Windows Server wird über eine Funktion namens Failoverclustering aktiviert. Dadurch kann ein WSFC erstellt werden, der mit einer Verfügbarkeitsgruppe oder einer Failoverclusterinstanz (FCI) verwendet werden kann. SQL Server liefert clusterfähige Ressourcen-DLLs, die Integration für AGs und FCIs bieten.
SQL Server für Linux unterstützt mehrere Clustertechnologien. Microsoft unterstützt die SQL Server Komponenten, während unsere Partner die entsprechende Clustertechnologie bereitstellen. So unterstützt SQL Server für Linux zusammen mit Pacemaker als Clusterlösung auch HPE Serviceguard und DH2i DxEnterprise.
Ein Windows-basierter Failovercluster und eine Linux-Clusterlösung haben mehr Gemeinsamkeiten als Unterschiede. Beide ermöglichen das Kombinieren von einzelnen Servern in einer Konfiguration, um die Verfügbarkeit zu gewährleisten und enthalten Konzepte für Ressourcen, Einschränken (die jedoch unterschiedlich implementiert sind), Failover usw.
Microsoft stellt z. B. für die Unterstützung von Pacemaker für die Konfiguration von Verfügbarkeitsgruppen und FCIs, einschließlich des automatischen Failovers, das Paket mssql-server-ha bereit. Dieses ähnelt den Ressourcen-DLLs in einem WSFC, ist aber nicht mit diesen identisch. Einer der Unterschiede zwischen einem WSFC und Pacemaker besteht darin, dass Pacemaker keine Netzwerknamenressource enthält. Diese Komponente ermöglicht das Abstrahieren des Namens des Listeners (oder der FCI) auf einem WSFC. Verwenden Sie DNS für die Namensauflösung unter Linux.
Aufgrund des Unterschieds im Clusterstapel müssen AGs in SQL Server 2017 (14.x) und höheren Versionen einige der Metadaten behandeln, die von einem WSFC nativ behandelt werden. Es gibt z. B. drei Clustertypen für eine Verfügbarkeitsgruppe, die in den sys.availability_groups und cluster_type Spalten gespeichert cluster_type_desc sind:
- WSFC
- Extern
- Keine
Alle Verfügbarkeitsgruppen, die Verfügbarkeit erfordern, müssen einen zugrunde liegenden Cluster verwenden. Dies ist im Fall von SQL Server 2017 (14.x) und höher ein WSFC oder ein Linux-Cluster-Agent. Für Windows Server-basierte AGs, die einen zugrunde liegenden WSFC verwenden, ist der Standardclustertyp WSFC, und Sie müssen ihn nicht festlegen. Bei Linux-basierten AGs müssen Sie den Clustertyp beim Erstellen der AG auf "Extern" festlegen. Die Integration mit einer externen Clusterlösung unter Linux wird nach der Erstellung der Verfügbarkeitsgruppe konfiguriert, während dies bei einem WSFC zur Erstellungszeit erfolgt.
Der Clustertyp „Keiner“ kann für Windows Server- und Linux-Verfügbarkeitsgruppen verwendet werden. Das Festlegen des Clustertyps auf „Keiner“ bedeutet, dass die Verfügbarkeitsgruppe keinen zugrunde liegenden Cluster erfordert. Das bedeutet, dass es sich bei SQL Server 2017 (14.x) um die erste Version von SQL Server handelt, die Verfügbarkeitsgruppen ohne einen Cluster unterstützt. Der Nachteil hierbei ist jedoch, dass diese Konfiguration nicht als Hochverfügbarkeitslösung unterstützt wird.
Wichtig
In SQL Server 2017 (14.x) und höheren Versionen können Sie einen Clustertyp für eine AG nach der Erstellung nicht mehr ändern. Diese Einschränkung bedeutet, dass eine AG nicht von "None" auf "External" oder "WSFC" umgestellt werden kann und umgekehrt.
Wenn Sie nur zusätzliche schreibgeschützte Kopien einer Datenbank hinzufügen möchten oder von den Vorteilen einer AG für Migration und Upgrades profitieren wollen, ohne sich mit der Komplexität eines zugrunde liegenden Clusters oder sogar einer Replikation auseinandersetzen zu müssen, sollten Sie die Einrichtung einer AG mit dem Clustertyp "Keine" in Betracht ziehen. Weitere Informationen finden Sie in den Abschnitten "Migrationen und Upgrades" und " Read-Scale".
Der folgende Screenshot zeigt die Unterstützung für die verschiedenen Arten von Clustertypen in SQL Server Management Studio (SSMS). Sie müssen Version 17.1 oder höher ausführen. Der folgende Screenshot stammt aus Version 17.2:

REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT
In SQL Server 2016 (13.x) wurde die Unterstützung für die Anzahl von synchronen Replikaten in der Enterprise Edition von zwei auf drei erhöht. Wenn jedoch ein sekundäres Replikat synchronisiert wird, das andere Replikat jedoch ein Problem aufweist, gibt es keine Möglichkeit, das Verhalten zu steuern, um das primäre Replikat entweder auf das fehlerhafte Replikat zu warten oder zuzulassen, dass es fortzufahren. In diesem Szenario konnte das primäre Replikat weiterhin Schreibdatenverkehr empfangen, obwohl sich das sekundäre Replikat nicht in einem synchronisierten Zustand befindet, was zu Datenverlusten im sekundären Replikat führt.
In SQL Server 2017 (14.x) und höheren Versionen können Sie das Verhalten steuern, wenn synchrone Replikate mit REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT vorhanden sind. Diese Option funktioniert folgendermaßen:
- Es gibt drei mögliche Werte:
0,1, und2. - Der Wert ist die Anzahl der sekundären Replikate, die synchronisiert werden müssen, was Auswirkungen auf Datenverlust, AG-Verfügbarkeit und Failover hat.
- Für WSFCs und einen Clustertyp von None lautet der Standardwert
0, und Sie können ihn manuell auf1oder2festlegen. - Bei einem Clustertyp "Extern" legt der Clustermechanismus diesen Wert standardmäßig fest, und Sie können ihn manuell überschreiben. Für drei synchrone Replikate lautet
1der Standardwert .
Unter Linux konfigurieren Sie den Wert für REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT für die AG-Ressource im Cluster. Unter Windows legen Sie sie über Transact-SQL fest.
Ein höherer Wert als 0 gewährleistet einen höheren Datenschutz, denn wenn die erforderliche Anzahl sekundärer Replikate nicht verfügbar ist, ist die primäre Replik nicht verfügbar, bis diese Bedingung behoben wird.
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT wirkt sich auch auf das Failoververhalten aus, da das automatische Failover nicht auftreten kann, wenn sich die richtige Anzahl sekundärer Replikate nicht im richtigen Zustand befindet. Unter Linux erlaubt ein Wert von 0 kein automatisches Failover. Wenn Sie also unter Linux synchron mit automatischem Failover verwenden, müssen Sie den Wert höher als 0 festlegen, um automatisches Failover zu erreichen.
0 unter Windows Server entspricht dem Verhalten in SQL Server 2016 (13.x) und früheren Versionen.
Erweiterte Unterstützung für den Microsoft Distributed Transaction Coordinator
Vor SQL Server 2016 (13.x) war die einzige Möglichkeit, die Verfügbarkeit für Anwendungen in SQL Server sicherzustellen, die verteilte Transaktionen erfordern und die intern DTC nutzen, FCIs bereitzustellen. Eine verteilte Transaktion kann auf zwei Arten erfolgen:
- Eine Transaktion, die mehrere Datenbanken in derselben SQL Server-Instanz umfasst.
- Eine Transaktion, die mehrere SQL Server-Instanzen umfasst oder möglicherweise eine Nicht-SQL Server-Datenquelle umfasst.
In SQL Server 2016 (13.x) wurde eine Teilunterstützung für DTC mit Verfügbarkeitsgruppen eingeführt, die das zweite Szenario abdecken. SQL Server 2017 (14.x) unterstützte dann beide Szenarien mit DTC.
In SQL Server 2017 (14.x) und höheren Versionen können Sie einer AG nach der Erstellung DTC-Unterstützung hinzufügen. In SQL Server 2016 (13.x) können Sie die DTC-Unterstützung nur beim Erstellen der AG aktivieren.
Failoverclusterinstanzen
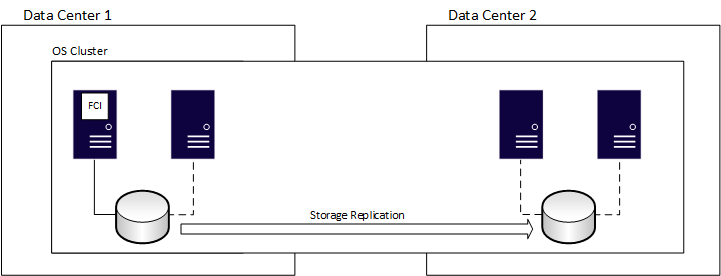
Failoverclusterinstanzen (FCIs) stellen die Verfügbarkeit für die gesamte Installation von SQL Server bereit, die als Instanz bezeichnet wird. Wenn bei FCIs ein Problem auftritt, wird alles innerhalb der Instanz auf einen anderen Server verschoben, einschließlich Datenbanken, SQL Server-Agent-Aufträgen, verknüpften Servern und mehr. Alle FCIs erfordern einen gemeinsamen Speicher, auch wenn er netzwerkdefiniert ist. Ein Knoten kann jederzeit die Ressourcen der FCI verwalten und besitzen. Im folgenden Diagramm besitzt der erste Knoten des Clusters das FCI. Sie besitzt außerdem die zugeordneten freigegebenen Speicherressourcen, die durch die durchgezogene Linie zum Speicher angezeigt werden.
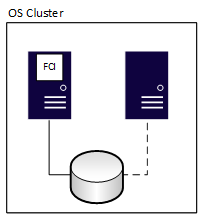
Nach einem Failover ändert sich der Besitz, wie im folgenden Diagramm dargestellt:
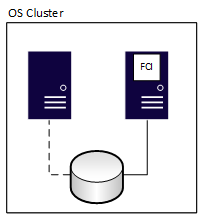
Ein FCI hat keinen Datenverlust, aber der zugrunde liegende freigegebene Speicher ist ein einzelner Fehlerpunkt, da eine Kopie der Daten vorhanden ist. Um redundante Kopien von Datenbanken zu haben, kombinieren Sie FCIs mit einer anderen Verfügbarkeitsmethode, z. B. einem AG oder einem Logversand. Die andere Methode muss physisch getrennten Speicher vom FCI verwenden. Wenn der FCI auf einen anderen Knoten überschlägt, wird er auf einem Knoten angehalten und auf einem anderen Knoten gestartet. Dieser Vorgang ähnelt dem Ausschalten eines Servers und dem Aktivieren des Servers.
Ein FCI durchläuft den normalen Wiederherstellungsprozess. Es rollt alle Transaktionen weiter, die vorwärts gerollt werden müssen, und setzt alle unvollständigen Transaktionen zurück. Daher ist die Datenbank von einem Datenpunkt bis zum Zeitpunkt des Fehlers oder manuellen Failovers konsistent, sodass kein Datenverlust auftritt. Datenbanken sind erst verfügbar, nachdem die Wiederherstellung abgeschlossen ist. Die Wiederherstellungszeit hängt von vielen Faktoren ab und ist im Allgemeinen länger als ein Ausfall einer AG. Der Kompromiss besteht darin, dass beim Fehlschlagen einer AG möglicherweise zusätzliche Aufgaben erforderlich sind, um eine Datenbank nutzbar zu machen, z. B. das Aktivieren eines SQL Server-Agent-Auftrags.
Hinweis
Die beschleunigte Datenbankwiederherstellung (ADR) kann die Wiederherstellungszeit verringern. Weitere Informationen finden Sie unter Beschleunigte Datenbankwiederherstellung.
FCIs abstrahieren genau wie Verfügbarkeitsgruppen, auf welchem Knoten des zugrunde liegenden Clusters diese gehostet werden. Eine FCI behält immer denselben Namen bei. Anwendungen und Endbenutzer stellen niemals eine Verbindung mit den Knoten her. Stattdessen verwenden sie den eindeutigen Namen, der der FCI zugewiesen ist. Eine FCI kann in einer Verfügbarkeitsgruppe als eine der Instanzen enthalten sein, die entweder ein primäres oder ein sekundäres Replikat hosten.
In der folgenden Liste werden einige Unterschiede mit FCIs unter Windows Server und Linux hervorgehoben:
- Unter Windows Server ist FCI ein Teil des Installationsvorgangs. Sie konfigurieren eine FCI unter Linux nach der Installation von SQL Server.
- Linux unterstützt nur eine einzelne Installation von SQL Server pro Host, sodass alle FCIs eine Standardinstanz sind. Windows Server unterstützt bis zu 25 FCIs pro WSFC.
- Der allgemeine Name, der von FCIs unter Linux verwendet wird, wird in DNS definiert und sollte mit dem der Ressource identisch sein, die für die FCI erstellt wurde.
Protokollversand
Wenn Wiederherstellungspunkt- und Wiederherstellungszeitziele flexibler sind oder Datenbanken nicht äußerst unternehmenskritisch sind, ist der Protokollversand ein weiteres bewährtes Verfügbarkeitsfeature in SQL Server. Basierend auf den nativen Sicherungen von SQL Server generiert der Prozess für den Protokollversand automatisch Transaktionsprotokollsicherungen, kopiert diese auf eine oder mehrere Instanzen, die als betriebsbereit bekannt sind, und wendet sie auf diese Standbyinstanzen an. Der Protokollversand verwendet SQL Server-Agent-Aufträge, um den Sicherungs- und Kopiervorgang sowie den Anwendungsvorgang der Transaktionsprotokollsicherungen zu automatisieren.
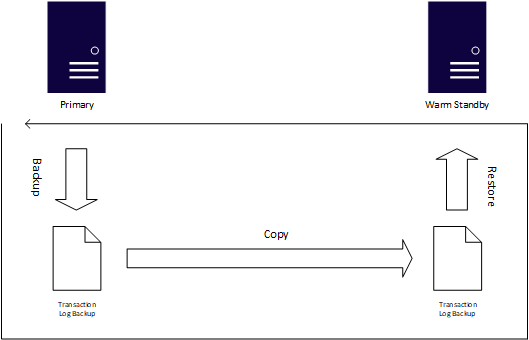
Der größte Vorteil der Verwendung von Log Shipping besteht darin, dass menschliche Fehler berücksichtigt werden, da Sie die Anwendung von Transaktionsprotokollen verzögern können. Wenn beispielsweise jemand eine UPDATE ohne Klausel WHERE ausgibt, hat der Standbymodus möglicherweise nicht die Änderung, sodass Sie während der Reparatur des primären Systems zu diesem Wechseln wechseln können. Während der Protokollversand einfach zu konfigurieren ist, ist der Wechsel von der primären zu einem warmen Standbymodus, der als Rollenänderung bezeichnet wird, immer manuell. Sie initiieren eine Rollenänderung über Transact-SQL und wie eine AG müssen alle Objekte, die nicht im Transaktionsprotokoll erfasst werden, manuell synchronisieren. Sie müssen den Protokollversand pro Datenbank konfigurieren, während eine einzelne AG mehrere Datenbanken enthalten kann.
Im Gegensatz zu einer Verfügbarkeitsgruppe oder FCI bietet der Protokollversand keine Abstraktion für eine Rollenänderung, die Anwendungen verarbeiten können müssen. Techniken wie ein DNS-Alias (CNAME) können eingesetzt werden, es gibt jedoch Vor- und Nachteile, z.B. die Zeit, die ein DNS nach dem Wechsel zum Aktualisieren benötigt.
Notfallwiederherstellung
Wenn Ihr primärer Verfügbarkeitsstandort einer Katastrophe wie einem Erdbeben oder einer Überschwemmung ausgesetzt ist, muss das Unternehmen darauf vorbereitet sein, die Systeme an anderer Stelle online schalten zu können. In diesem Abschnitt wird erläutert, wie die SQL Server-Verfügbarkeitsfeatures die Geschäftskontinuität unterstützen können.
Verfügbarkeitsgruppen
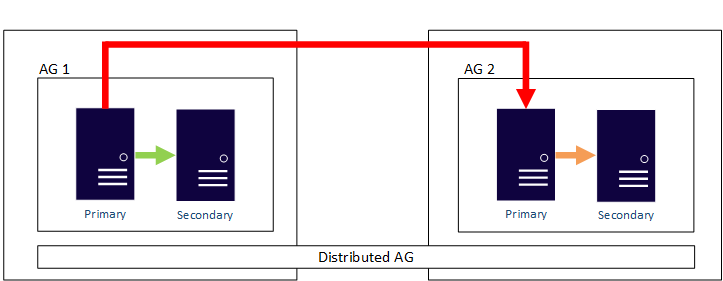
Einer der Vorteile von AGs besteht darin, dass Sie sowohl hohe Verfügbarkeit als auch Notfallwiederherstellung mithilfe eines einzelnen Features konfigurieren. Ohne die Anforderung, dass die Hochverfügbarkeit des freigegebenen Speichers sichergestellt werden muss, ist es deutlich einfacher, lokale Replikate für die Hochverfügbarkeit in einem Rechenzentrum und Remotereplikate mit jeweils separatem Speicher für die Notfallwiederherstellung in anderen Rechenzentren zu verwalten. Das Vorhandensein von zusätzlichen Kopien der Datenbank ist der Nachteil zur Gewährleistung von Redundanz. Ein Beispiel für eine AG, die mehrere Rechenzentren umfasst, wird im folgenden Diagramm gezeigt. Ein primäres Replikat ist dafür verantwortlich, alle sekundären Replikate zu synchronisieren.

Außerhalb einer AG mit einem Clustertyp "None" erfordert eine AG, dass alle Replikate Teil desselben zugrunde liegenden Clusters sind, unabhängig davon, ob es sich um eine WSFC- oder eine externe Clusterlösung handelt. Im vorherigen Diagramm wird der WSFC gestreckt, um in zwei verschiedenen Rechenzentren zu arbeiten, was die Komplexität unabhängig von der Plattform (Windows Server oder Linux) erhöht. Das Strecken von Clustern über Entfernungen erhöht die Komplexität.
In SQL Server 2016 (13.x) wurde eingeführt, dass eine verteilte Verfügbarkeitsgruppe einer Verfügbarkeitsgruppe ermöglichen kann, Verfügbarkeitsgruppen auf mehrere Cluster zu erweitern. Verteilte Verfügbarkeitsgruppen entkoppeln die Anforderung, dass alle Knoten im selben Cluster enthalten sein müssen. Dadurch wird das Konfigurieren der Notfallwiederherstellung wesentlich einfacher. Weitere Informationen finden Sie unter Verteilte Verfügbarkeitsgruppen.
Failoverclusterinstanzen
Sie können FCIs für die Notfallwiederherstellung verwenden. Wie bei einer normalen AG müssen Sie den zugrunde liegenden Clustermechanismus auf alle Standorte erweitern, was Komplexität hinzufügt. Für FCIs müssen Sie auch den gemeinsam genutzten Speicher berücksichtigen. Die primären und sekundären Websites benötigen Zugriff auf dieselben Datenträger. Um sicherzustellen, dass der vom FCI verwendete Speicher an beiden Standorten vorhanden ist, verwenden Sie eine externe Methode, z. B. die vom Speicheranbieter auf der Hardwareebene bereitgestellten Funktionen. Alternativ können Sie speicherreplikate in Windows Server verwenden.
Protokollversand
Der Protokollversand ist eine der ältesten Methoden für die Bereitstellung der Notfallwiederherstellung für SQL Server-Datenbanken. Der Protokollversand wird häufig mit AGs und FCIs verwendet, um eine kostengünstige und einfachere Notfallwiederherstellung bereitzustellen, bei der andere Optionen aufgrund von Umgebung, Verwaltungskenntnissen oder Budget eine Herausforderung darstellen können. Ähnlich wie bei der Hohen Verfügbarkeit für den Protokollversand verzögern viele Umgebungen das Laden eines Transaktionsprotokolls, um menschliche Fehler zu berücksichtigen.
Migrationen und Upgrades
Wenn eine Organisation neue Instanzen bereitstellt oder alte Instanzen aktualisiert, können lange Ausfälle nicht toleriert werden. In diesem Abschnitt wird erläutert, wie die Verfügbarkeitsfeatures von SQL Server verwendet werden können, um die Ausfallzeiten in einer geplanten Architekturänderung, Serverwechsel, Plattformänderung (z. B. Windows Server zu Linux oder umgekehrt) oder während des Patchings zu minimieren.
Hinweis
Sie können auch andere Methoden wie Sicherungen und Wiederherstellungen für Migrationen und Upgrades verwenden. In diesem Artikel werden diese Methoden nicht behandelt.
Verfügbarkeitsgruppen
Sie können eine vorhandene Instanz aktualisieren, die eine oder mehrere Verfügbarkeitsgruppen (AGs) enthält, auf spätere Versionen von SQL Server. Während dieses Upgrade einige Ausfallzeiten erfordert, kann es mit der richtigen Menge an Planung minimiert werden.
Wenn Sie zu neuen Servern migrieren möchten, ohne die Konfiguration zu ändern (einschließlich des Betriebssystems oder der SQL Server-Version), fügen Sie diese Server als Knoten zum vorhandenen zugrunde liegenden Cluster hinzu, und fügen Sie sie dann der AG hinzu. Sobald sich das Replikat oder die Replikate im richtigen Zustand befinden, führen Sie manuell ein Failover zu einem neuen Server durch. Entfernen Sie dann die alten Server aus der AG und setzen Sie sie außer Betrieb.
Verteilte Verfügbarkeitsgruppen stellen eine weitere Methode zum Migrieren zu einer neuen Konfiguration oder zum Aktualisieren von SQL Server dar. Da eine verteilte AG unterschiedliche zugrunde liegende AGs für verschiedene Architekturen unterstützt, können Sie von SQL Server 2019 (15.x) unter Windows Server 2019 zu SQL Server 2025 (17.x) wechseln, die unter Windows Server 2025 ausgeführt wird.
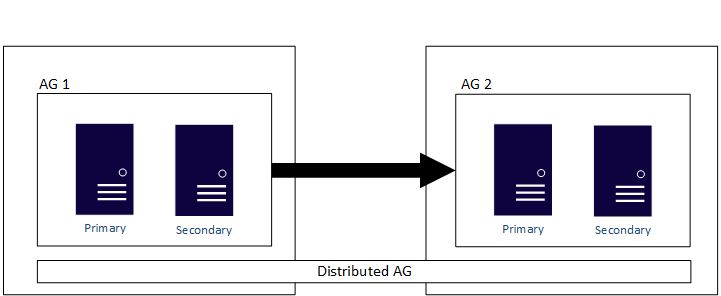
Schließlich sind AGs mit einem Clustertyp "Keine" für die Migration oder das Upgrade nützlich. Sie können Clustertypen nicht in einer typischen AG-Konfiguration kombinieren und abgleichen, sodass alle Replikate eine Art von None sein müssen. Eine verteilte Verfügbarkeitsgruppe kann verwendet werden, um Verfügbarkeitsgruppen zu erweitern, die mit verschiedenen Clustertypen konfiguriert sind. Diese Methode wird auf den verschiedenen Betriebssystemplattformen unterstützt.
Alle Varianten von AGs für Migrationen und Upgrades ermöglichen es, die Datensynchronisierung, den zeitaufwendigsten Teil der Arbeit, über einen längeren Zeitraum zu verteilen. Wenn es an der Zeit ist, den Umstieg auf die neue Konfiguration zu starten, ist der Wechsel eine kurze Unterbrechung im Vergleich zu einer langen Ausfallzeit, bei der alle Arbeiten, einschließlich der Synchronisierung von Daten, abgeschlossen werden müssen.
AGs können minimale Ausfallzeiten während des Patchings des zugrunde liegenden Betriebssystems bereitstellen, indem manuell ein Failover der primären auf ein sekundäres Replikat ausgeführt wird, während der Patchvorgang ausgeführt wird. Aus Sicht des Betriebssystems ist dies häufiger unter Windows Server, da die Wartung des zugrunde liegenden Betriebssystems einen Neustart erfordern kann. Das Patchen von Linux benötigt manchmal einen Neustart, aber es ist weniger üblich.
Eine weitere Möglichkeit, Ausfallzeiten zu minimieren, besteht darin, SQL Server-Instanzen zu patchen, die an einer Verfügbarkeitsgruppe teilnehmen, je nachdem, wie komplex die AG-Architektur ist. Sie patchen zuerst ein sekundäres Replikat. Sobald die richtige Anzahl von Replikaten gepatcht wurde, führen Sie manuell einen Failover des primären Replikats zu einem anderen Knoten durch, um das Upgrade durchzuführen. Aktualisieren Sie alle verbleibenden sekundären Replikate zu diesem Zeitpunkt.
Failoverclusterinstanzen
FCIs alleine können bei einer herkömmlichen Migration oder einem herkömmlichen Upgrade nicht unterstützt werden. Sie müssen eine AG oder einen Protokollversand für die Datenbanken im FCI konfigurieren und alle anderen Objekte berücksichtigen. FCIs unter Windows Server sind jedoch immer noch eine beliebte Option, wenn Sie die zugrunde liegenden Windows-Server patchen müssen. Wenn Sie ein manuelles Failover initiieren, ersetzt der kurze Ausfall, dass die Instanz für die gesamte Zeit, auf die Windows Server gepatcht wird, nicht verfügbar ist.
Sie können ein FCI-Upgrade auf spätere Versionen von SQL Server durchführen. Weitere Informationen finden Sie unter Upgrade einer Failoverclusterinstanz.
Protokollversand
Der Protokollversand ist immer noch eine beliebte Option zum Migrieren und Aktualisieren von Datenbanken. Ähnlich wie bei Verfügbarkeitsgruppen kann die Datenweitergabe vor dem Serverwechsel gestartet werden, dieses Mal wird jedoch das Transaktionsprotokoll als Synchronisierungsmethode verwendet. Zum Zweitpunkt des Wechsels, wenn der gesamte Datenverkehr an der Quelle beendet wurde, muss ein letztes Transaktionsprotokoll ausgeführt, kopiert und auf die neue Konfiguration angewendet werden. An diesem Punkt kann die Datenbank online geschaltet werden.
Der Protokollversand ist oft toleranter gegenüber langsameren Netzwerken, und während der Wechsel etwas länger dauern kann als bei der Verwendung einer AG oder einer verteilten AG, wird er in der Regel in Minuten, nicht in Stunden, Tagen oder Wochen gemessen.
Ähnlich wie bei AGs kann der Protokollversand während eines Wartungsfensters eine Möglichkeit bieten, auf einen anderen Server umzuschalten.
Andere SQL Server-Bereitstellungsmethoden und Verfügbarkeit
Es gibt zwei Bereitstellungsmethoden für SQL Server unter Linux: Container und das Verwenden von Azure (oder einem anderen öffentlichen Cloudanbieter). Die allgemeine Verfügbarkeitsanforderung ist unabhängig davon vorhanden, wie SQL Server bereitgestellt wird. Diese beiden Methoden haben einige spezielle Aspekte, wenn es darum geht, SQL Server hochverfügbar zu machen.
SQL Server-Container und Optionen für Hochverfügbarkeit/Notfallwiederherstellung
Die Bereitstellung von SQL Server-Containern ist eine Möglichkeit, die SQL Server-Bereitstellung, Skalierung und Lebenszyklusverwaltung in umgebungenübergreifend zu vereinfachen. Ein Container ist ein vollständiges ready-to-run-Image von SQL Server.
Je nach Containerplattform, zum Beispiel bei Nutzung eines Container-Orchestrators wie Kubernetes, kann der Container erneut bereitgestellt und wieder an den genutzten freigegebenen Speicher angeschlossen werden, falls der Container verloren geht. Dies bietet zwar eine gewisse Widerstandsfähigkeit, aber es gibt Ausfallzeiten, die bei der Wiederherstellung der Datenbank auftreten, und ist nicht wirklich hoch verfügbar, wie es bei der Verwendung einer Verfügbarkeitsgruppe oder eines FCI der Fall wäre.
Wenn Sie Hochverfügbarkeit für SQL Server-Container konfigurieren möchten, die auf Kubernetes- oder anderen Plattformen bereitgestellt werden, können Sie DH2i DxEnterprise als eine der Clusterlösungen verwenden, für die Sie eine Verfügbarkeitsgruppe im Hochverfügbarkeitsmodus konfigurieren können. Diese Option bietet ein Recovery Point Objective (RPO) und ein Recovery Time Objective (RTO), das von einer Hochverfügbarkeitslösung erwartet wird.
Linux-basierte VM-Bereitstellung
Linux kann mit SQL Server auf virtuellen Linux-Computern bereitgestellt werden. Wie bei lokal basierten Installationen erfordert eine unterstützte Installation die Verwendung einer Absicherung für einen fehlgeschlagenen Knoten, welcher sich außerhalb des Cluster-Agents selbst befindet. Knoten-Fencing wird über Fencing-Verfügbarkeits-Agents bereitgestellt. In einigen Verteilungen sind diese als Teil der Plattform enthalten, während andere auf externen Hardware- und Softwareanbietern basieren. Wenden Sie sich an Ihre bevorzugte Linux-Verteilung, um zu sehen, welche Formen von Knoten-Fencing bereitgestellt werden, damit eine unterstützte Lösung in der öffentlichen Cloud bereitgestellt werden kann.
Leitfäden zum Installieren von SQL Server für Linux sind für die folgenden Distributionen verfügbar:
- Schnellstart: Installieren von SQL Server und Erstellen einer Datenbank unter Red Hat
- Schnellstart: Installieren von SQL Server und Erstellen einer Datenbank unter Ubuntu
- Schnellstart: Installieren von SQL Server und Erstellen einer Datenbank unter SUSE Linux Enterprise Server
Lesemaßstab
Sekundäre Replikatinstanzen können für Abfragen, die nur Lesezugriff erfordern, verwendet werden. Es gibt zwei Möglichkeiten, die mit einer AG erreicht werden können:
- Ermöglichen Sie direkten Zugriff auf das Sekundäre
- Konfigurieren des schreibgeschützten Routings, das die Verwendung des Listeners erfordert. In SQL Server 2016 (13.x) wurde die Möglichkeit eingeführt, einen Lastenausgleich für schreibgeschützte Verbindungen über den Listener vorzunehmen, für den ein Roundrobin-Algorithmus verwendet wird. Dadurch können schreibgeschützte Anforderungen auf alle lesbaren Replikate verteilt werden.
Hinweis
Lesbare sekundäre Replikate sind nur in Enterprise Edition verfügbar. Jede Instanz, die ein lesbares Replikat hosten, benötigt eine SQL Server-Lizenz.
Die Skalierung lesbarer Kopien einer Datenbank über AGs wurde erstmals mit verteilten AGs in SQL Server 2016 (13.x) eingeführt. Dieses Feature bietet schreibgeschützte Kopien der Datenbank nicht nur lokal, sondern auch regional und global mit minimaler Konfiguration. Mit diesem Setup wird der Netzwerkdatenverkehr und die Latenz reduziert, indem Abfragen lokal ausgeführt werden. Jedes primäre Replikat einer AG kann zwei weitere AGs seeden, auch wenn es nicht die vollständige Lese-/Schreibkopie ist, und jede verteilte AG kann bis zu 27 lesbare Kopien der Daten unterstützen.

In SQL Server 2017 (14.x) und höheren Versionen können Sie eine nahezu in Echtzeit verfügbare Lösung mit AGs erstellen, die mit einem Clustertyp "None" konfiguriert sind. Wenn Ihr Ziel darin besteht, AGs für lesbare sekundäre Replikate und nicht für die Verfügbarkeit zu verwenden, entfernt dieser Ansatz die Komplexität der Verwendung einer WSFC- oder einer externen Clusterlösung unter Linux. Sie bietet die verständlichen Vorteile einer AG in einem einfacheren Implementierungsverfahren.
Der einzige wesentliche Vorbehalt ist, dass die Konfiguration des schreibgeschützten Routings etwas anders ist, da kein zugrunde liegendes Cluster ohne Clustertyp vorhanden ist. Aus der Sicht von SQL Server ist immer noch ein Listener erforderlich, um die Anforderungen weiterzuleiten, obwohl kein Cluster vorhanden ist. Anstatt einen herkömmlichen Listener zu konfigurieren, verwenden Sie die IP-Adresse oder den Namen des primären Replikats. Das primäre Replikat leitet dann die Nur-Lesen-Anfragen weiter.
Ein warmer Standbymodus für den Protokollversand kann technisch für die lesbare Verwendung konfiguriert werden, indem die Datenbank WITH STANDBYwiederhergestellt wird. Da die Transaktionsprotokolle jedoch die exklusive Verwendung der Datenbank für die Wiederherstellung benötigen, können Benutzer*innen währenddessen nicht auf die Datenbank zugreifen. Dadurch ist der Protokollversand keine ideale Lösung, besonders wenn Daten nahezu in Echtzeit erforderlich sind.
Anders als bei der Transaktionsreplikation, bei der alle Daten live sind, ist jedes sekundäre Replikat in einem Lese-Szenario eine exakte Kopie des primären. Das Replikat befindet sich nicht in einem Zustand, in dem eindeutige Indizes angewendet werden können. Wenn Indizes für die Berichterstellung erforderlich sind oder Daten bearbeitet werden müssen, müssen Sie diese Indizes für die Datenbanken im primären Replikat erstellen. Wenn Sie Flexibilität benötigen, ist die Replikation die bessere Lösung für lesbare Daten.
Interoperabilität – plattformübergreifend und für Linux-Verteilungen
Mit SQL Server-Unterstützung sowohl unter Windows Server als auch unter Linux wird in diesem Abschnitt erläutert, wie sie zusätzlich zu anderen Zwecken zur Verfügbarkeit zusammenarbeiten können. Es umfasst auch die Lösungen, die mehr als eine Linux-Distribution enthalten.
Hinweis
Es gibt keine Szenarien, in denen eine WSFC-basierte Failoverclusterinstanz (FCI) oder Verfügbarkeitsgruppe (AG) direkt mit einem linuxbasierten FCI oder einer AG arbeitet. Ein Windows Server-Failovercluster (WSFC) kann nicht durch einen Pacemaker-Knoten erweitert werden und umgekehrt.
Verteilte Verfügbarkeitsgruppen
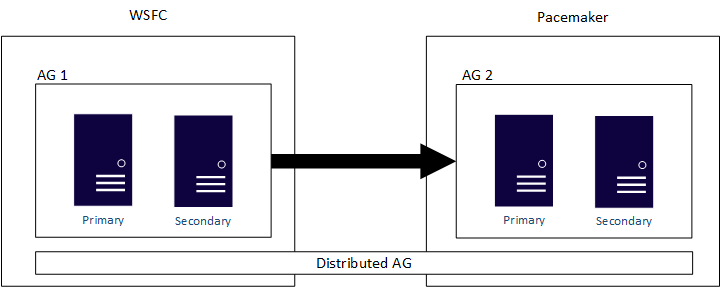
Verteilte Verfügbarkeitsgruppen wurden dafür entwickelt, mehrere Konfigurationen für Verfügbarkeitsgruppen zu umfassen, unabhängig davon, ob die zwei zugrunde liegenden Cluster der Verfügbarkeitsgruppen zwei verschiedene WSFCs oder Linux-Distributionen sind oder ob einer sich auf einem WSFC und der andere unter Linux befindet. Eine distributed AG ist die primäre Methode, eine plattformübergreifende Lösung zu haben. Eine verteilte Verfügbarkeitsgruppe ist außerdem die primäre Lösung für Migrationsvorgänge, z. B. für das Konvertieren von einer Windows Server-basierten SQL Server-Infrastruktur zu einer Linux-basierten, wenn Ihr Unternehmen dies durchführen möchte. Wie bereits erwähnt, würden AGs, insbesondere verteilte AGs, die Dauer minimieren, dass eine Anwendung nicht zur Verwendung verfügbar ist. Ein Beispiel für eine verteilte AG, die einen WSFC und Pacemaker umfasst, ist im folgenden Diagramm dargestellt:
Wenn Sie eine AG mit dem Clustertyp None konfigurieren, kann diese sowohl Windows Server und Linux als auch verschiedene Linux-Distributionen umfassen. Da diese Konfiguration keine echte Hochverfügbarkeit bietet, verwenden Sie sie nicht für unternehmenskritische Anwendungen. Verwenden Sie sie stattdessen für Lese-, Migrations- und Upgrade-Szenarien.
Protokollversand
Der Protokollversand basiert auf der Sicherung und Wiederherstellung, sodass es keine Unterschiede in den Datenbanken, Dateistrukturen und anderen Elementen für SQL Server unter Windows Server und SQL Server unter Linux gibt. Sie können den Protokollversand zwischen einer Windows Server-basierten SQL Server-Installation und einer Linux-Installation und zwischen Verteilungen von Linux konfigurieren. Alles andere bleibt unverändert.
Genau wie bei einer AG funktioniert der Protokollversand nicht, wenn sich der Quellserver bei einer höheren SQL Server-Hauptversion befindet, gegen ein Ziel, das bei einer niedrigeren Hauptversion liegt.
Zusammenfassung
Sie können Instanzen und Datenbanken von SQL Server 2017 (14.x) und höheren Versionen hoch verfügbar machen, indem Sie dieselben Features sowohl unter Windows Server als auch unter Linux verwenden. Neben Standardverfügbarkeitsszenarien lokaler Hochverfügbarkeit und Notfallwiederherstellung können Sie Ausfallzeiten minimieren, die mit Upgrades und Migrationen verbunden sind, indem Sie die Verfügbarkeitsfeatures in SQL Server verwenden. AGs können auch zusätzliche Kopien einer Datenbank als Teil derselben Architektur bereitstellen, um die Anzahl der lesbaren Kopien zu erhöhen. Ob Sie eine neue Lösung bereitstellen möchten oder ein Upgrade erwägen: SQL Server bietet Ihnen die Verfügbarkeit und Zuverlässigkeit, die Sie benötigen.