Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
gilt für: SQL Server Analysis Services Azure Analysis Services Fabric/Power BI Premium
SQL Server Analysis Services Azure Analysis Services Fabric/Power BI Premium
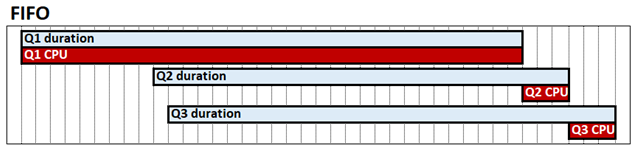
Das Abfrage-Interleaving ist eine Systemkonfiguration im tabellarischen Modus, die die Abfrageleistung in Szenarien mit hoher Parallelität verbessern kann. Standardmäßig arbeitet die tabellarische Analysis Services-Engine nach dem First-In-First-Out-Prinzip (FIFO) in Bezug auf die CPU. Wenn eine ressourcenintensive und möglicherweise langsame Speicher-Engine-Abfrage empfangen wird und ihr dann zwei ansonsten schnelle Abfragen folgen, können die schnellen Abfragen möglicherweise blockiert werden, bis die teure Abfrage abgeschlossen ist. Dieses Verhalten wird im folgenden Diagramm dargestellt, das Q1, Q2 und Q3 als die jeweiligen Abfragen, deren Dauer und CPU-Zeit anzeigt.
Das Interleaving von Abfragen mit Bevorzugung kurzer Abfragen ermöglicht gleichzeitigen Abfragen die gemeinsame Nutzung von CPU-Ressourcen, sodass schnelle Abfragen nicht durch langsame Abfragen blockiert werden. Die Zeit, die zum Abschließen aller drei Abfragen benötigt wird, ist immer noch ungefähr gleich, aber in unserem Beispiel Q2 und Q3 werden bis zum Ende nicht blockiert. Kurzabfragenbevorzugung bezeichnet schnelle Abfragen, bei denen bestimmt wird, wie viel CPU jede Abfrage zu einem bestimmten Zeitpunkt bereits verbraucht hat, sodass sie einen höheren Anteil der Ressourcen zugewiesen bekommen im Vergleich zu langlaufenden Abfragen. Im folgenden Diagramm gelten Q2- und Q3-Abfragen als schnell und werden mehr CPU als Q1 zugeordnet.
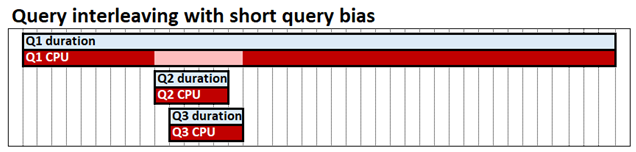
Die Interleaving von Abfragen soll nur geringe oder gar keine Leistungsauswirkungen auf Abfragen haben, die isoliert ausgeführt werden; eine einzelne Abfrage kann weiterhin so viel CPU verbrauchen wie mit dem FIFO-Modell.
Wichtige Überlegungen
Bevor Sie bestimmen, ob Query-Interleaving für Ihr Szenario geeignet ist, sollten Sie Folgendes beachten:
- Die Abfrage-Interleaving gilt nur für Importmodelle. Es wirkt sich nicht auf DirectQuery-Modelle aus.
- Abfrageinterleaving berücksichtigt nur die CPU, die von Abfragen der VertiPaq-Speichermodule verbraucht wird. Sie gilt nicht für Formel-Engine-Operationen.
- Eine einzelne DAX-Abfrage kann zu mehreren VertiPaq-Speichermodulabfragen führen. Eine DAX-Abfrage gilt als schnell oder langsam , basierend auf der CPU, die von ihren Speichermodulabfragen verbraucht wird. Die DAX-Abfrage ist die Maßeinheit.
- Aktualisierungsvorgänge sind standardmäßig vor Abfrageüberlappung geschützt. Lang andauernde Aktualisierungsvorgänge werden anders als lang andauernde Abfragen kategorisiert.
Konfigurieren
Um das Abfrage-Interleaving zu konfigurieren, legen Sie die Threadpool\SchedulingBehavior-Eigenschaft fest. Diese Eigenschaft kann mit den folgenden Werten angegeben werden:
| Wert | Description |
|---|---|
| -1 | Automatisch. Die Engine wählt den Warteschlangentyp aus. |
| 0 (Standard für SSAS 2019) | Erstes rein, erstes raus (FIFO). |
| 1 | Verzerrung bei kurzen Abfragen. Die Engine drosselt sukzessive lange ausgeführte Abfragen, wenn sie unter Druck steht, zugunsten von schnellen Abfragen. |
| 3 (Standardeinstellung für Azure AS, Power BI, SSAS 2022 und höher) | Kurze Abfrageverzerrung mit schneller Abbruch. Verbessert die Reaktionszeiten von Benutzerabfragen in Szenarien mit hoher Parallelität. Gilt nur für Azure AS, Power BI, SSAS 2022 und höher. |
Zurzeit kann die SchedulingBehavior-Eigenschaft nur mithilfe von XMLA festgelegt werden. In SQL Server Management Studio legt der folgende XMLA-Codeausschnitt die SchedulingBehavior-Eigenschaft auf 1, kurze Abfrageverzerrung fest.
<Alter AllowCreate="true" ObjectExpansion="ObjectProperties" xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object />
<ObjectDefinition>
<Server xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ddl2="http://schemas.microsoft.com/analysisservices/2003/engine/2" xmlns:ddl2_2="http://schemas.microsoft.com/analysisservices/2003/engine/2/2" xmlns:ddl100_100="http://schemas.microsoft.com/analysisservices/2008/engine/100/100" xmlns:ddl200="http://schemas.microsoft.com/analysisservices/2010/engine/200" xmlns:ddl200_200="http://schemas.microsoft.com/analysisservices/2010/engine/200/200" xmlns:ddl300="http://schemas.microsoft.com/analysisservices/2011/engine/300" xmlns:ddl300_300="http://schemas.microsoft.com/analysisservices/2011/engine/300/300" xmlns:ddl400="http://schemas.microsoft.com/analysisservices/2012/engine/400" xmlns:ddl400_400="http://schemas.microsoft.com/analysisservices/2012/engine/400/400" xmlns:ddl500="http://schemas.microsoft.com/analysisservices/2013/engine/500" xmlns:ddl500_500="http://schemas.microsoft.com/analysisservices/2013/engine/500/500">
<ID>myserver</ID>
<Name>myserver</Name>
<ServerProperties>
<ServerProperty>
<Name>ThreadPool\SchedulingBehavior</Name>
<Value>1</Value>
</ServerProperty>
</ServerProperties>
</Server>
</ObjectDefinition>
</Alter>
Von Bedeutung
Ein Neustart der Serverinstanz ist erforderlich. In Azure Analysis Services müssen Sie den Server anhalten und dann wiederherstellen, um ihn effektiv neu zu starten.
Zusätzliche Eigenschaften
In den meisten Fällen ist SchedulingBehavior die einzige Eigenschaft, die Sie festlegen müssen. Die folgenden zusätzlichen Eigenschaften weisen Standardwerte auf, die in den meisten Szenarien mit kurzen Abfrageverzerrungen funktionieren sollten, sie können jedoch bei Bedarf geändert werden. Die folgenden Eigenschaften haben keine Auswirkung, es sei denn, Query-Interleaving ist aktiviert, indem die SchedulingBehavior-Eigenschaft festgelegt wird.
ReservedComputeForFastQueries – Legt die Anzahl der reservierten logischen Kerne für schnelle Abfragen fest. Alle Abfragen gelten als schnell , bis sie verfallen, da sie eine bestimmte CPU-Menge verbraucht haben. ReservedComputeForFastQueries ist eine ganze Zahl zwischen 0 und 100. Der Standardwert ist 75.
Die Maßeinheit für ReservedComputeForFastQueries ist der Prozentsatz der Kerne. Beispielsweise versucht ein Wert von 80 auf einem Server mit 20 Kernen, 16 Kerne für schnelle Abfragen zu reservieren (während keine Aktualisierungsvorgänge ausgeführt werden). ReservedComputeForFastQueries rundet auf die nächste ganze Anzahl von Kernen auf. Es wird empfohlen, diesen Eigenschaftswert nicht unter 50 festzulegen. Dies liegt daran, dass schnelle Abfragen benachteiligt werden können und dem Gesamtentwurf des Features entgegenwirken.
DecayIntervalCPUTime – Eine ganze Zahl, die die CPU-Zeit in Millisekunden darstellt, die eine Abfrage verbringt, bevor sie abfällt. Wenn das System unter CPU-Druck liegt, sind verfallende Abfragen auf die verbleibenden Kerne beschränkt, die nicht für schnelle Abfragen reserviert sind. Der Standardwert ist 60.000. Dies stellt 1 Minute CPU-Zeit dar, nicht verstrichene Kalenderzeit.
ReservedComputeForProcessing – Legt die Anzahl der reservierten logischen Kerne für jeden Verarbeitungsvorgang (Datenaktualisierung) fest. Der Eigenschaftswert ist eine ganze Zahl zwischen 0 und 100, wobei der Standardwert 75 ausgedrückt wird. Der Wert stellt einen Prozentsatz der Kerne dar, die durch die ReservedComputeForFastQueries -Eigenschaft bestimmt werden. Ein Wert von 0 (Null) bedeutet, dass Verarbeitungsvorgänge derselben Abfrageinterleavinglogik unterliegen wie Abfragen, sodass sie verfallen können.
Während keine Verarbeitungsvorgänge ausgeführt werden, hat ReservedComputeForProcessing keine Auswirkung. Bei einem Wert von 80 reserviert die Funktion ReservedComputeForFastQueries auf einem Server mit 20 Kernen beispielsweise 16 Kerne für schnelle Abfragen. Mit einem Wert von 75 reserviert ReservedComputeForProcessing 12 der 16 Kerne für Aktualisierungsvorgänge, wodurch 4 Kerne für schnelle Abfragen zur Verfügung stehen, während Verarbeitungsvorgänge ausgeführt werden und die CPU genutzt wird. Wie im Abschnitt "Verfallende Abfragen " weiter unten beschrieben, werden die verbleibenden 4 Kerne (nicht für schnelle Abfragen oder Verarbeitungsvorgänge reserviert) weiterhin für schnelle Abfragen und die Verarbeitung im Leerlauf verwendet.
Diese zusätzlichen Eigenschaften befinden sich unter dem Knoten " ResourceGovernance ". In SQL Server Management Studio legt der folgende XMLA-Codeausschnitt die DecayIntervalCPUTime-Eigenschaft auf einen Wert fest, der niedriger als der Standardwert ist:
<Alter AllowCreate="true" ObjectExpansion="ObjectProperties" xmlns="http://schemas.microsoft.com/analysisservices/2003/engine">
<Object />
<ObjectDefinition>
<Server xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ddl2="http://schemas.microsoft.com/analysisservices/2003/engine/2" xmlns:ddl2_2="http://schemas.microsoft.com/analysisservices/2003/engine/2/2" xmlns:ddl100_100="http://schemas.microsoft.com/analysisservices/2008/engine/100/100" xmlns:ddl200="http://schemas.microsoft.com/analysisservices/2010/engine/200" xmlns:ddl200_200="http://schemas.microsoft.com/analysisservices/2010/engine/200/200" xmlns:ddl300="http://schemas.microsoft.com/analysisservices/2011/engine/300" xmlns:ddl300_300="http://schemas.microsoft.com/analysisservices/2011/engine/300/300" xmlns:ddl400="http://schemas.microsoft.com/analysisservices/2012/engine/400" xmlns:ddl400_400="http://schemas.microsoft.com/analysisservices/2012/engine/400/400" xmlns:ddl500="http://schemas.microsoft.com/analysisservices/2013/engine/500" xmlns:ddl500_500="http://schemas.microsoft.com/analysisservices/2013/engine/500/500">
<ID>myserver</ID>
<Name>myserver</Name>
<ServerProperties>
<ServerProperty>
<Name>ResourceGovernance\DecayIntervalCPUTime</Name>
<Value>15000</Value>
</ServerProperty>
</ServerProperties>
</Server>
</ObjectDefinition>
</Alter>
Verfallene Abfragen
Die in diesem Abschnitt beschriebenen Einschränkungen gelten nur, wenn das System unter CPU-Druck liegt. Beispielsweise kann eine einzelne Abfrage, wenn es sich um die einzige Abfrage handelt, die zu einem bestimmten Zeitpunkt im System ausgeführt wird, alle verfügbaren Kerne nutzen, unabhängig davon, ob sie verfallen ist oder nicht.
Für jede Abfrage sind möglicherweise viele Speichermodulaufträge erforderlich. Wenn ein Kern im Pool für veraltete Abfragen verfügbar wird, überprüft der Scheduler die älteste ausgeführte Abfrage basierend auf der verstrichenen Kalenderzeit, um festzustellen, ob er bereits seine maximale Kernberechtigung (Maximum Core Entitlement , MCE) verwendet hat. Wenn nein, wird der nächste Auftrag ausgeführt. Wenn ja, wird die nächste älteste Abfrage ausgewertet. Die Abfrage-MCE wird davon bestimmt, wie viele Verfallsintervalle bereits verwendet wurden. Für jedes verwendete Verfallsintervall wird der MCE basierend auf dem in der folgenden Tabelle gezeigten Algorithmus reduziert. Dies wird fortgesetzt, bis entweder die Abfrage abgeschlossen ist, ein Timeout auftritt, oder der MCE auf einen einzelnen Kern reduziert wird.
Im folgenden Beispiel verfügt das System über 32 Kerne, und die CPU des Systems ist unter Druck.
ReservedComputeForFastQueries ist 60 (60%).
- 20 Kerne (19,2 aufgerundet) sind für schnelle Abfragen reserviert.
- Die verbleibenden 12 Kerne werden für degradierte Abfragen zugeordnet.
DecayIntervalCPUTime ist 60.000 (1 Minute CPU-Zeit).
Der Lebenszyklus einer Abfrage kann wie folgt sein, solange sie nicht wegen eines Timeout abbricht oder abgeschlossen wird.
| Etappe | Der Status | Ausführung/Planung | MCE |
|---|---|---|---|
| 0 | Schnell | Der MCE hat 20 Kerne (reserviert für schnelle Abfragen). Die Abfrage wird in Bezug auf andere schnelle Abfragen in den reservierten 20 Kernen in FIFO-Weise ausgeführt. Das Ablauffrist von 1 Minute CPU-Zeit ist aufgebraucht. |
20 = MIN(32/2˄0, 20) |
| 1 | Kariös | Der MCE ist auf 12 Kerne festgelegt (12 verbleibende Kerne, die nicht für schnelle Abfragen reserviert sind). Aufträge werden basierend auf der Verfügbarkeit bis zu MCE ausgeführt. Das Verfallsintervall von 1 Minute CPU-Zeit ist aufgebraucht. |
12 = MIN(32/2˄1, 12) |
| 2 | Kariös | Der MCE ist auf 8 Kerne festgelegt, was einem Viertel von insgesamt 32 Kernen entspricht. Aufträge werden basierend auf der Verfügbarkeit bis zu MCE ausgeführt. Das Verfallsintervall von 1 Minute CPU-Zeit ist aufgebraucht. |
8 = MIN(32/2˄2, 12) |
| 3 | Kariös | Der MCE ist auf 4 Kerne festgelegt. Die Ausführung der Aufträge erfolgt basierend auf deren Verfügbarkeit bis zu MCE. Das Verfallsintervall für 1 Minute CPU-Zeit ist abgelaufen. |
4 = MIN(32/2˄3, 12) |
| 4 | Kariös | Der MCE ist auf 2 Kerne eingestellt. Die Ausführung der Aufträge erfolgt basierend auf deren Verfügbarkeit bis zu MCE. Das Verfallsintervall für 1 Minute CPU-Zeit ist abgelaufen. |
2 = MIN(32/2˄4, 12) |
| 5 | Kariös | Der MCE ist auf 1 Kern festgelegt. Die Ausführung der Aufträge erfolgt basierend auf deren Verfügbarkeit bis zu MCE. Das Verfallsintervall gilt nicht, da die Abfrage ihren Tiefstpunkt erreicht hat. Kein weiterer Verfall, da mindestens 1 Kern erreicht wird. |
1 = MIN(32/2˄5, 12) |
Wenn sich das System unter CPU-Druck befindet, wird jeder Abfrage nicht mehr Kerne als dem MCE zugewiesen. Wenn alle Kerne derzeit von Abfragen innerhalb ihrer jeweiligen MCEs verwendet werden, warten andere Abfragen, bis Kerne verfügbar sind. Sobald Kerne verfügbar werden, wird die älteste anspruchsberechtigte Abfrage basierend auf ihrer verstrichenen Kalenderzeit ausgewählt. Der MCE ist eine Obergrenze unter Druck; er garantiert nicht, dass die Anzahl der Kerne zu einem beliebigen Zeitpunkt verfügbar ist.