Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird beschrieben, wie Sie Hot- und Cold Table-Partitionen verwenden, um sehr große Datenmodelle zu optimieren. Partitionen bieten eine Möglichkeit, die Daten einer Tabelle in einzelne Teilmengen aufzuteilen. Partitionen werden nicht direkt in den Standardmäßigen Power BI-Datenmodellierungstools verfügbar gemacht, aber Sie können erweiterte Partitionierungsmethoden nutzen, indem Sie eine inkrementelle Aktualisierungsrichtlinie in Power BI Desktop konfigurieren. Die inkrementelle Aktualisierung basiert auf Partitionen, wie inkrementelle Aktualisierung und Echtzeitdaten für Datasets erläutert. Das Konfigurieren von Partitionen für heiße und kalte Tabellen geht jedoch darüber hinaus, was eine inkrementelle Aktualisierungsrichtlinie erreichen kann, und setzt voraus, dass sie mit typischen Tabellenpartitionierungsschemas und XMLA-basierten Tools vertraut ist.
Voraussetzungen
Aufgrund der relativen Komplexität dieser Partitionierungstechnik eignet es sich am besten für fortgeschrittene Benutzer mit Erfahrung in den folgenden Bereichen:
Grundlegendes zu Tabellenpartitionskonzepten, wie Importmoduspartitionen, DirectQuery-Modus und Dual-Modus funktionieren.
Wissen über das Erstellen von Hybridtabellen mithilfe von XMLA-basierten Tools. Hybridtabellen verwenden eine oder mehrere Importmoduspartitionen und eine DirectQuery-Partition .
Kenntnisse über die Anforderungen der DAX-Funktionen, welche Sie verwenden können, um eine
DataCoverageDefinition. Dies ist eine neue Eigenschaft für DirectQuery-Partitionen , um zu beschreiben, welche Daten die DirectQuery-Partition einer Hybridtabelle enthält, damit das Power BI-Modul diese Partition ggf. von der Abfrageverarbeitung ausschließen kann. Das Ausschließen der DirectQuery-Partition kann dazu beitragen, unnötige Datenquellenabfragen zu vermeiden und die Leistung der DAX-Abfrageverarbeitung zu verbessern.Grundlegendes zum Unterschied zwischen regulären und eingeschränkten Tabellenbeziehungen. Die RELATED-Funktion ist beispielsweise nützlich, wenn Sie die Datenabdeckung einer Faktentabellenpartition basierend auf den Werten aus einer verknüpften Datumsdimensionstabelle definieren möchten. Beachten Sie, dass die Partition der Faktentabelle eine DirectQuery-Partition ist, die möglicherweise eine eingeschränkte Beziehung zur Datumstabelle aufweist, wodurch die RELATED-Funktion keine Werte abrufen kann. In diesem Szenario funktioniert RELATED nur, wenn die Datumsdimensionstabelle eine duale Tabelle ist. Die Datumstabelle muss sich im DirectQuery - oder Dualmodus befinden. Es kann kein reiner Import sein.
Beachten Sie, dass ein falsch definierter Fehler DataCoverageDefinition zu falschen Ergebnissen führen kann, da Power BI die DirectQuery-Partition möglicherweise falsch von der Abfrageverarbeitung ausschließen kann. Stellen Sie daher sicher, dass Sie die Ergebnisse mit und ohne DataCoverageDefinition vergleichen, um sicherzustellen, dass sie übereinstimmen.
Wann man Hot- und Cold-Table-Partitionen verwenden sollte
Hier ist ein Beispiel, in dem Hot- und Cold Partitionen helfen können, eine Hybridtabelle für historische Analysen zu optimieren. Angenommen, Sie haben eine sehr große Datenquelle, die sich über viele Jahre angesammelt hat. Die primäre Verwendung besteht darin, die neuesten Daten aus den letzten Jahren zu analysieren. Gelegentlich möchten Sie auch ältere Daten analysieren. Vielleicht bemerkten Sie im Laufe des Jahres einen deutlichen Umsatzanstieg. War das schon einmal geschehen? Ist es die höchste Umsatzspitze seit Beginn der Vertriebsnachverfolgung?
Ohne Unterstützung für heiße und kalte Partitionen würde diese Art von historischen Analysen erfordern, dass Sie alle historischen Daten zusammen mit den aktuelleren Daten in die Faktentabelle importieren. Am besten ist dies eine ineffiziente Verwendung von Ressourcen, da die primäre Analyse keine der älteren historischen Daten verwendet. Im schlimmsten Fall ist das Datenvolumen so groß, dass es nicht einmal vollständig importiert werden kann. Sie müssen entweder das Datenmodell in den DirectQuery-Modus wechseln und eine Leistungsstrafe im Vergleich zum Importmodus akzeptieren, oder Sie können separate Modelle erstellen und ihre Benutzer zwingen, zwischen Berichten zu wechseln. Eine Hybridtabelle mit Hot- und Cold Partitionen bietet Ihnen eine bessere Option.
So verwenden Sie Partitionen für heiße und kalte Tabellen
Konfigurieren Sie zunächst die Vertriebstabelle mit einer Partition für den heißen Importmodus für die neuesten Daten und behalten Sie die älteren Daten in einer kaltenDirectQuery-Partition bei, wie das folgende Diagramm für die FactInternetSales-Tabelle eines AdventureWorks-Beispieldatenmodells veranschaulicht. Alle Zeilen mit einem OrderDateKey größer oder gleich 20200101 werden über die Hot Import-Mode-Partition in das Datenmodell importiert. Zeilen mit einem OrderDateKey kleiner als 20200101 werden über die kalte DirectQuery-Partition abgedeckt. Jetzt kann Power BI die primären Anwendungsfälle schnell mit dem Importmodus bereitstellen, und Sie müssen keine großen Mengen von historischen Daten importieren, die Sie nur gelegentlich analysieren, da die DirectQuery-Partition dies abgedeckt hat.
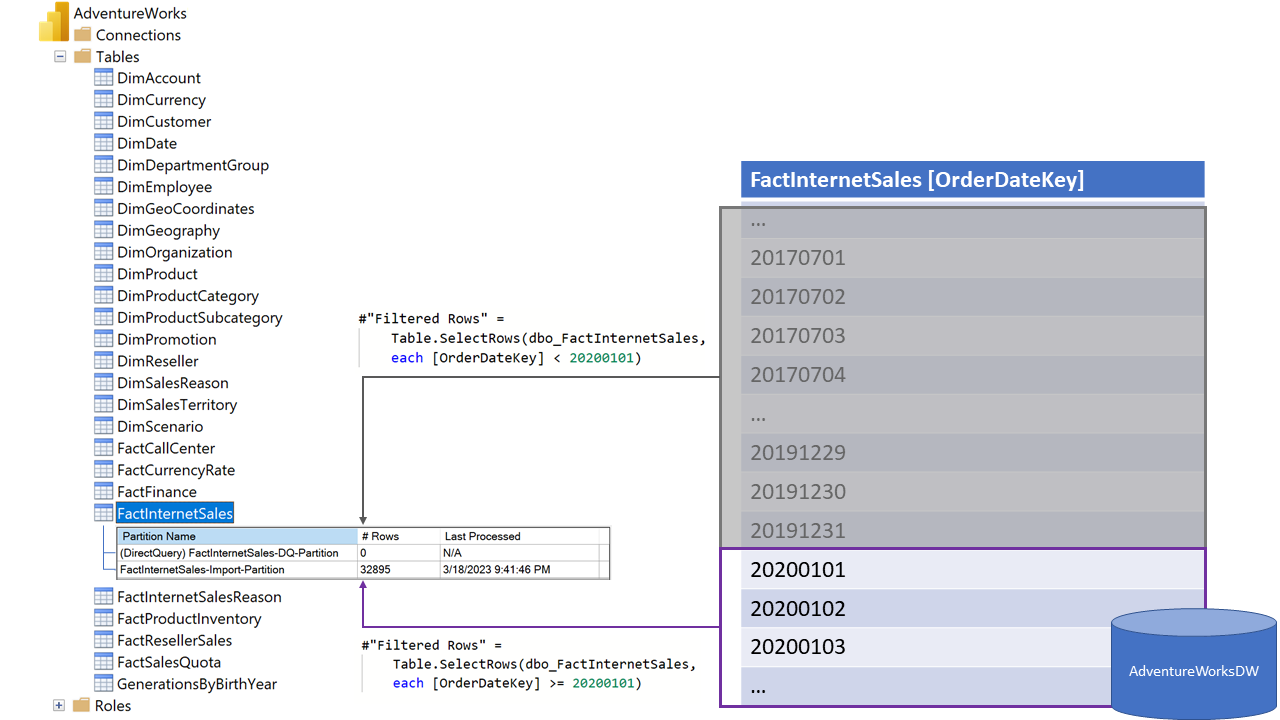
Wenn Sie über ein AdventureWorks-Beispiel-Data Warehouse verfügen und die folgenden Schritte ausführen möchten, führen Sie die folgenden allgemeinen Schritte aus:
Erstellen Sie das Dataset. Verwenden Sie Power BI Desktop, um ein AdventureWorks-Dataset und einen Bericht zu erstellen. Schließen Sie alle Tabellen im reinen DirectQuery-Modus ein. Konvertieren Sie dann alle Tabellen außer der
FactInternetSales-Tabelle in den Dualmodus. Belassen Sie dieFactInternetSalesTabelle im DirectQuery-Modus .Laden Sie das Dataset hoch. Verwenden Sie einen Arbeitsbereich, der in Power BI Premium gehostet wird, wobei der XMLA-Endpunkt für Schreibvorgänge aktiviert ist.
Aktualisieren Sie die Kompatibilitätsstufe. Öffnen Sie den Arbeitsbereich mit Ihrem AdventureWorks-Dataset in SQL Server Management Studio (SSMS). Klicken Sie mit der rechten Maustaste auf das AdventureWorks-Dataset>Script>Script Database asErstellen oder Ersetzen und wählen Sie Neues Abfrageeditorfenster aus. Legen Sie die CompatibilityLevel-Eigenschaft auf 1603 (oder höher) fest. Wählen Sie "Ausführen" aus, oder drücken Sie F5. Stellen Sie sicher, dass der Vorgang erfolgreich abgeschlossen ist.

Konfigurieren Sie die FactInternetSales-Tabellenpartitionen. Klicken Sie mit der rechten Maustaste auf die AdventureWorks-Dataset-Skriptskriptdatenbank>>alsErstellen oder Ersetzen, und wählen Sie das Fenster "Neuer Abfrage-Editor" aus. Ersetzen Sie den gesamten Partitionsabschnitt durch den folgenden Abschnitt. Stellen Sie sicher, dass Sie die Sql.Database-Zeilen so aktualisieren, dass sie auf die AdventureWorksDW-Datenbank in Ihrer Umgebung verweisen. Wählen Sie "Ausführen" aus, oder drücken Sie F5. Stellen Sie sicher, dass der Vorgang erfolgreich abgeschlossen ist.
"partitions": [ { "name": "FactInternetSales-DQ-Partition", "mode": "directQuery", "dataView": "full", "source": { "type": "m", "expression": [ "let", " Source = Sql.Database(\"demo.database.windows.net\", \"AdventureWorksDW\"),", " dbo_FactInternetSales = Source{[Schema=\"dbo\",Item=\"FactInternetSales\"]}[Data],", " #\"Filtered Rows\" = Table.SelectRows(dbo_FactInternetSales, each [OrderDateKey] < 20200101)", "in", " #\"Filtered Rows\"" ] } }, { "name": "FactInternetSales-Import-Partition", "mode": "import", "source": { "type": "m", "expression": [ "let", " Source = Sql.Database(\"demo.database.windows.net\", \"AdventureWorksDW\"),", " dbo_FactInternetSales = Source{[Schema=\"dbo\",Item=\"FactInternetSales\"]}[Data],", " #\"Filtered Rows\" = Table.SelectRows(dbo_FactInternetSales, each [OrderDateKey] >= 20200101)", "in", " #\"Filtered Rows\"" ] } } ],Verarbeiten des Datenmodells. Öffnen Sie im Power BI-Portal den Arbeitsbereich mit Ihrem AdventureWorks-Dataset , und führen Sie eine On-Demand-Aktualisierung des Datasets aus, um die Importpartition mit Daten zu laden.
Stellen Sie sicher, dass die Berichte aktuelle und historische Daten anzeigen. Öffnen Sie AdventureWorks , und überprüfen Sie, ob der Bericht Ergebnisse für Verkaufstransaktionen vor und nach dem 1. Januar 2020 anzeigen kann, wie im folgenden Screenshot gezeigt.
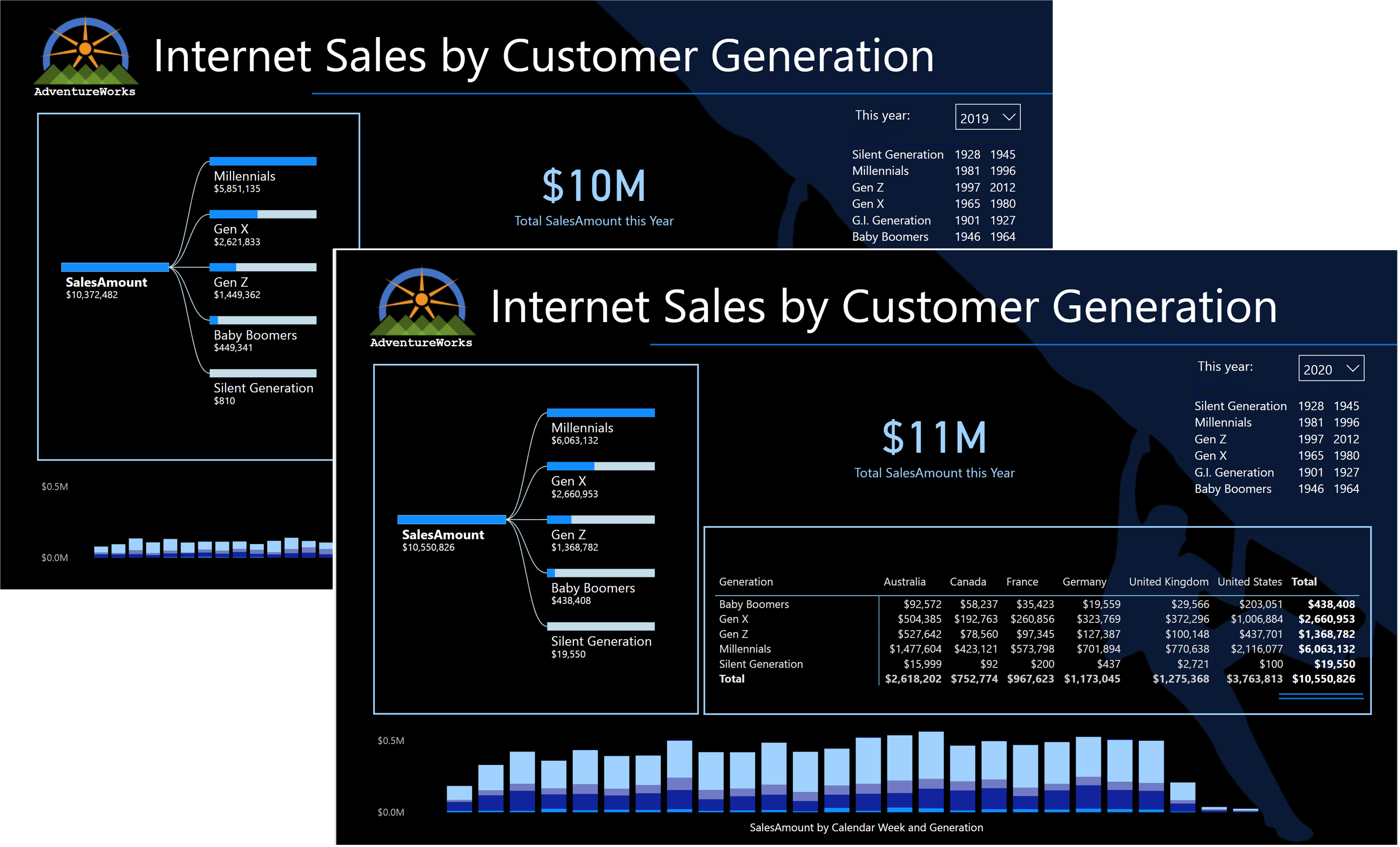
Definieren der Datenabdeckung der DirectQuery-Partition
Die Lösung funktioniert nahtlos über aktuelle und historische Daten. Power BI fragt jedoch standardmäßig alle Tabellenpartitionen ab, da sie nicht weiß, welche Daten jede Partition abdeckt. Daher fragt Power BI die DirectQuery-Partition auch für die Jahre ab, die von der DirectQuery-Partition nicht abgedeckt werden. Die Verkaufsdaten sind in der Importpartition leicht verfügbar, und die DirectQuery-Partition trägt keine Zeilen bei, aber diese überflüssige Quellabfrage kann weiterhin spürbare Last auf die Datenquelle verursachen und zu Verzögerungen bei der DAX-Abfrageverarbeitung beitragen. Um diese überflüssige Quellabfrage zu vermeiden, verwenden Sie die DataCoverageDefinition.
Wie der folgende Screenshot zeigt, sendet der Power BI-Bericht weiterhin mehrere unnötige SQL-Abfragen für 2020 an die Datenquelle, da die DAX-Abfrage jedes visuellen Elements bewirkt, dass Power BI die DirectQuery-Partition abfragt.
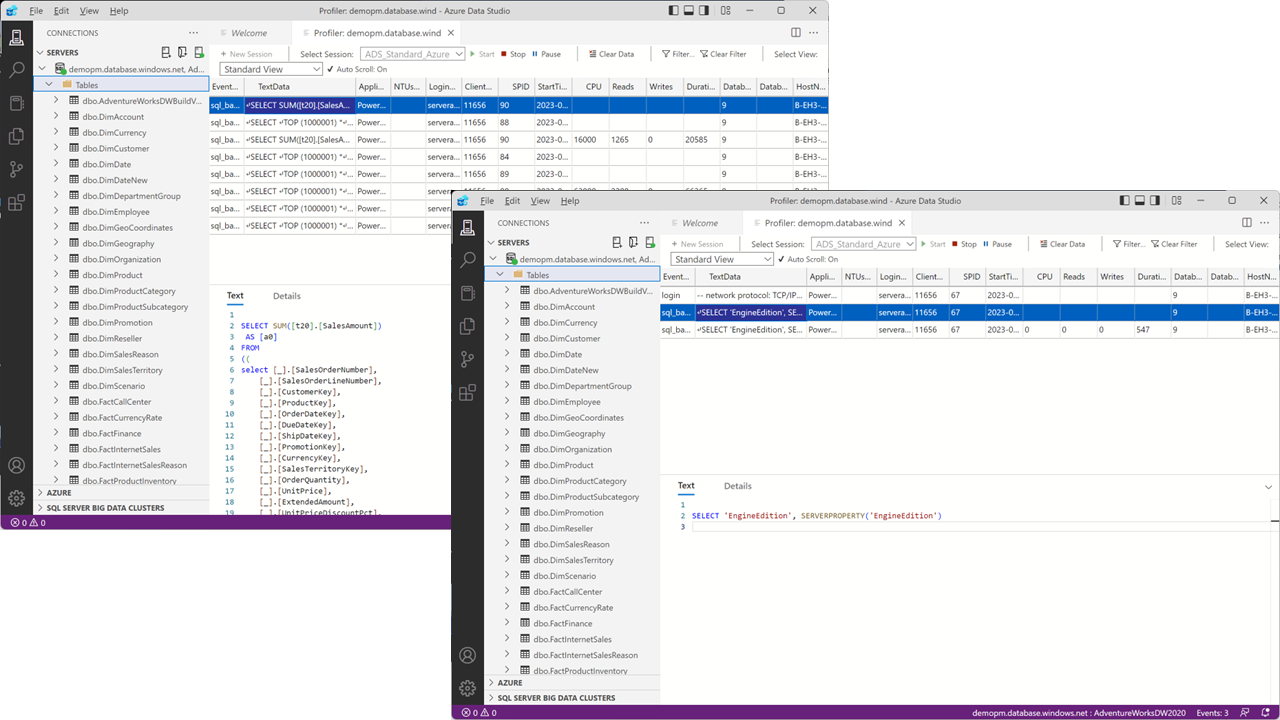
Durch Festlegen der Eigenschaft auf der dataCoverageDefinitionDirectQuery-Partition wie im folgenden TMSL-Codeausschnitt werden diese SQL-Abfragen vermieden. Beachten Sie jedoch, dass Sie das Dataset aktualisieren müssen, nachdem Sie eine Datenabdeckungsdefinition angewendet oder geändert haben. Eine Prozessneuberechnung reicht aus, um die Datenabdeckungsdefinition auszuwerten. Wenn Sie diesen Schritt vergessen haben, schlagen Abfragen, die die Partition berühren, mit einer Fehlermeldung fehl, die besagt, dass "DataCoverageDefinition der DQ-Partition in Tabelle '[Tabellenname]" nach einer letzten Änderung noch nicht berechnet wird. Es muss neu verarbeitet werden".
{
"name": "FactInternetSales-DQ-Partition",
"mode": "directQuery",
"dataView": "full",
"source": {
"type": "m",
"expression": [
"let",
" Source = Sql.Database(\"demopm.database.windows.net\", \"AdventureWorksDW2020\"),",
" dbo_FactInternetSales = Source{[Schema=\"dbo\",Item=\"FactInternetSales\"]}[Data],",
" #\"Filtered Rows\" = Table.SelectRows(dbo_FactInternetSales, each [OrderDateKey] < 20200101)",
"in",
" #\"Filtered Rows\""
]
},
"dataCoverageDefinition": {
"description": "DQ partition with all sales from 2017, 2018, and 2019.",
"expression": "RELATED('DimDate'[CalendarYear]) IN {2017,2018,2019}"
}
}
Wie bereits erwähnt, trägt die dataCoverageDefinition Eigenschaft dazu bei, unnötiges Laden der Datenquelle zu vermeiden. Außerdem verbessert sie die Analyseleistung für aktuelle Daten, da Power BI jetzt die DirectQuery-Partition ggf. von der DAX-Abfrageverarbeitung ausschließen kann. Sie können einfache Datenabdeckungsausdrücke für einzelne Werte sowie Bereiche mit einfachen OPERATORen UND, OR und NOT definieren. Sie können auch die RELATED-Funktion verwenden, um die Datenabdeckung basierend auf einer Spalte aus einer Dimensionstabelle zu definieren, die eine normale Beziehung zur Faktentabelle hat. Wenn ein Datenabdeckungsausdruck Spalten aus einer Dimensionstabelle verwendet, stellen Sie sicher, dass sich die Dimensionstabelle im dualen Modus befindet. Sie können die Datenabdeckung auch basierend auf Spalten aus der Faktentabelle selbst definieren. In der folgenden Tabelle finden Sie unterstützte Vorgänge, die in drei Gruppen kategorisiert sind.
| Typ | Kommentare | Examples |
|---|---|---|
| Einzelnes Prädikat (Wertbasiert) | Gleichheit, Ungleichheit und IN-Operatoren Unterstützung von Dimensions- und Faktentabellen |
RELATED('Date'[Year]) = 2020 NOT RELATED('Date'[Year]) = 2020 RELATED('Date'[Year]) IN {2020, 2021, 2022} InternetSales'[SalesAmt] = CURRENCY(100.0) NICHT InternetSales'[SalesAmt] = CURRENCY(100,0) InternetSales'[SalesAmt] IN {WÄHRUNG(100.0), WÄHRUNG(200.0)} |
| Einzelnes Prädikat (bereichsbasiert) | Kann Vergleichsoperatoren wie >, <, >=, <= sein Die Dimensionstabelle muss sich im Dualmodus befinden |
RELATED('Date'[Year]) > 2020 RELATED('Date'[Year]) <= 2020 |
| Mehrere Prädikate | Gleichheit, Ungleichheit und Vergleich IN-Operator wird nicht unterstützt. Begrenzt auf eine einzelne Dimensionstabelle im Dualmodus |
RELATED('Date'[Year]) > 2010 && RELATED('Date'[Year]) > 2020 RELATED('Date'[Year]) = 2020 && RELATED('Date'[Calendar Quarter]) = 1 RELATED('Date'[Year]) > 2020 && NOT RELATED('Date'[Calendar Quarter]) = 1 RELATED('Date'[Year]) > 2020 && RELATED('Date'[Calendar Quarter]) < 3 RELATED('Date'[Year]) > 2020 && (RELATED('Date'[Calendar Quarter]) = 1 || RELATED('Date'[Calendar Quarter]) = 2) |
Mit der DataCoverageDefinition Eigenschaft auf DirectQuery-Partitionen können Sie sogar die größten Power BI-Datenmodelle basierend auf heißen Partitionen im Importmodus und kalten Partitionen im DirectQuery-Modus optimieren, indem Sie unnötige Abfragen der Datenquelle vermeiden.
Diese Reduzierung der Quellabfrage trägt dazu bei, die Berichtsleistung beim Analysieren von heißen Daten zu steigern. Es hilft auch, die Last der Datenquelle zu verringern, und auf diese Weise hilft, die Skalierung Ihrer Datenquelle zu maximieren. Bedenken Sie jedoch, dass das Optimieren eines Datenmodells mithilfe der dataCoverageDefinition Eigenschaft noch ein erweitertes Szenario ist. Stellen Sie sicher, dass Sie die Ergebnisse sorgfältig überprüfen.
Überlegungen und Einschränkungen
Derzeit erfordert die
DataCoverageDefinitionEigenschaft auf DirectQuery-Partitionen statische Werte, z. B. RELATED('Date'[Year]) = 2020 oder RELATED('Date'[Year]) IN {2020, 2021, 2022}. Dynamische Zuordnungen werden nicht unterstützt, z. B. RELATED('Date'[DateKey]) = TODAY().Die inkrementelle Aktualisierung mit Echtzeitdaten nutzt die
DataCoverageDefinitionEigenschaft nicht. Wenn Sie eine Datenabdeckungsdefinition auf eine DirectQuery-Partition (Echtzeit) anwenden, entfernt die inkrementelle Aktualisierung die Datenabdeckungsdefinition bei der Neuerstellung der Partition.