NEW REFERENCE ARCHITECTURE: Batch scoring of Spark models on Azure Databricks
Our eighth AI reference architecture (on the Azure Architecture Center) is written by AzureCAT John Ehrlinger, and published by Mike Wasson.
Reference architectures provide a consistent approach and best practices for a given solution. Each architecture includes recommended practices, along with considerations for scalability, availability, manageability, security, and more. The full array of reference architectures is available on the Azure Architecture Center.
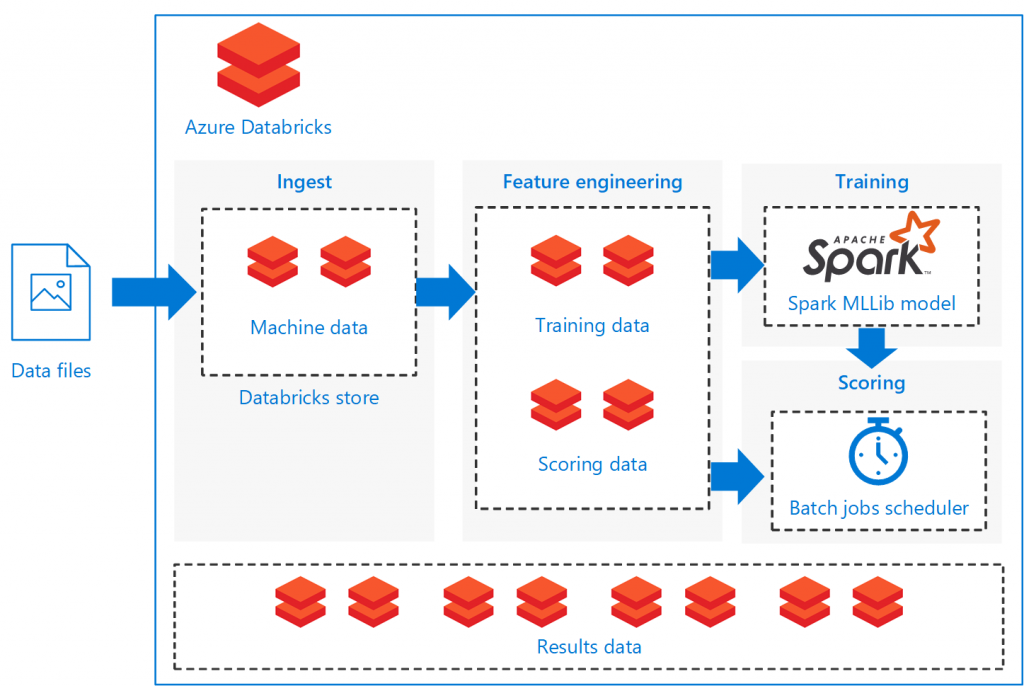
This reference architecture shows how to build a scalable solution for batch scoring an Apache Spark classification model on a schedule using Azure Databricks, an Apache Spark-based analytics platform optimized for Azure. The solution can be used as a template that can be generalized to other scenarios.
The architecture defines a data flow that is entirely contained within Azure Databricks based on a set of sequentially executed notebooks. It consists of the following components:
- Data files . The reference implementation uses a simulated data set contained in five static data files.
- Ingestion . The data ingestion notebook downloads the input data files into a collection of Databricks data sets. In a real-world scenario, data from IoT devices would stream onto Databricks-accessible storage such as Azure SQL Server or Azure Blob storage. Databricks supports multiple data sources.
- Training pipeline. This notebook executes the feature engineering notebook to create an analysis data set from the ingested data. It then executes a model building notebook that trains the machine learning model using the Apache Spark MLlib scalable machine learning library.
- Scoring pipeline. This notebook executes the feature engineering notebook to create scoring data set from the ingested data and executes the scoring notebook. The scoring notebook uses the trained Spark MLlib model to generate predictions for the observations in the scoring data set. The predictions are stored in the results store, a new data set on the Databricks data store.
- Scheduler. A scheduled Databricks job handles batch scoring with the Spark model. The job executes the scoring pipeline notebook, passing variable arguments through notebook parameters to specify the details for constructing the scoring data set and where to store the results data set.
Topics covered include:
- Architecture
- Recommendations
- Performance considerations
- Storage considerations
- Cost considerations
- Deploy the solution
- Related architectures
See also
Additional related AI reference architectures:
- Distributed training of deep learning models on Azure
- Batch scoring on Azure for deep learning models
- Batch scoring of Python models on Azure
- Real-time scoring of Python Scikit-Learn and deep learning models on Azure
- Real-time scoring of R machine learning models
- Enterprise-grade conversational bot
- Build a real-time recommendation API on Azure
Find all our reference architectures here.
![]()
AzureCAT Guidance
"Hands-on solutions, with our heads in the Cloud!"