Machine Reading at Scale – Transfer Learning for Large Text Corpuses
This post is authored by Anusua Trivedi, Senior Data Scientist at Microsoft.
This post builds on the MRC Blog where we discussed how machine reading comprehension (MRC) can help us “transfer learn” any text. In this post, we introduce the notion of and the need for machine reading at scale, and for transfer learning on large text corpuses.
Introduction
Machine reading for question answering has become an important testbed for evaluating how well computer systems understand human language. It is also proving to be a crucial technology for applications such as search engines and dialog systems. The research community has recently created a multitude of large-scale datasets over text sources including:
- Wikipedia (WikiReading, SQuAD, WikiHop).
- News and newsworthy articles (CNN/Daily Mail, NewsQA, RACE).
- Fictional stories (MCTest, CBT, NarrativeQA).
- General web sources (MS MARCO, TriviaQA, SearchQA).
These new datasets have, in turn, inspired an even wider array of new question answering systems.
In the MRC blog post, we trained and tested different MRC algorithms on these large datasets. We were able to successfully transfer learn smaller text excepts using these pretrained MRC algorithms. However, when we tried creating a QA system for the Gutenberg book corpus (English only) using these pretrained MRC models, the algorithms failed. MRC usually works on text excepts or documents but fails for larger text corpuses. This leads us to a newer concept – machine reading at scale (MRS). Building machines that can perform machine reading comprehension at scale would be of great interest for enterprises.
Machine Reading at Scale (MRS)
Instead of focusing on only smaller text excerpts, Danqi Chen et al. came up with a solution to a much bigger problem which is machine reading at scale. To accomplish the task of reading Wikipedia to answer open-domain questions, they combined a search component based on bigram hashing and TF-IDF matching with a multi-layer recurrent neural network model trained to detect answers in Wikipedia paragraphs.
MRC is about answering a query about a given context paragraph. MRC algorithms typically assume that a short piece of relevant text is already identified and given to the model, which is not realistic for building an open-domain QA system.
In sharp contrast, methods that use information retrieval over documents must employ search as an integral part of the solution.
MRS strikes a balance between the two approaches. It is focused on simultaneously maintaining the challenge of machine comprehension, which requires the deep understanding of text, while keeping the realistic constraint of searching over a large open resource.
Why is MRS Important for Enterprises?
The adoption of enterprise chatbots has been rapidly increasing in recent times. To further advance these scenarios, research and industry has turned toward conversational AI approaches, especially in use cases such as banking, insurance and telecommunications, where there are large corpuses of text logs involved.
One of the major challenges for conversational AI is to understand complex sentences of human speech in the same way humans do. The challenge becomes more complex when we need to do this over large volumes of text. MRS can address both these concerns where it can answer objective questions from a large corpus with high accuracy. Such approaches can be used in real-world applications like customer service.
In this post, we want to evaluate the MRS approach to solve automatic QA capability across different large corpuses.
Training MRS – DrQA Model
DrQA is a system for reading comprehension applied to open-domain question answering. DrQA is specifically targeted at the task of machine reading at scale. In this setting, we are searching for an answer to a question in a potentially very large corpus of unstructured documents (which may not be redundant). Thus, the system must combine the challenges of document retrieval (i.e. finding relevant documents) with that of machine comprehension of text (identifying the answers from those documents).
We use Deep Learning Virtual Machine (DLVM) as the compute environment with two NVIDIA Tesla P100 GPU, CUDA and cuDNN libraries. The DLVM is a specially configured variant of the Data Science Virtual Machine (DSVM) that makes it more straightforward to use GPU-based VM instances for training deep learning models. It is supported on Windows 2016 and the Ubuntu Data Science Virtual Machine. It shares the same core VM images – and hence the same rich toolset – as the DSVM, but is configured to make deep learning easier. All the experiments were run on a Linux DLVM with two NVIDIA Tesla P100 GPUs. We use the PyTorch backend to build the models. We pip installed all the dependencies in the DLVM environment.
We fork the Facebook Research GitHub for our blog work and we train the DrQA model on SQUAD dataset. We use the pre-trained MRS model for evaluating our large Gutenberg corpuses using transfer learning techniques.
Children's Gutenberg Corpus
We created a Gutenberg corpus consisting of about 36,000 English books. We then created a subset of Gutenberg corpus consisting of 528 children’s books.
Pre-processing the children’s Gutenberg dataset:
- Download books with filter (e.g. children, fairy tales etc.).
- Clean the downloaded books.
- Extract text data from book content.
How to Create a Custom Corpus for DrQA to Work?
We follow the instructions available here to create a compatible document retriever for the Gutenberg Children’s books.
To execute the DrQA model:
- Insert a query in the UI and click the search button.
- This calls the demo server (flask server running in the backend).
- The demo code initiates the DrQA pipeline.
- DrQA pipeline components are explained here.
- The question is tokenized.
- Based on the tokenized question, the document retriever uses Bigram hashing + TF-IDF matching to match the most documents.
- We retrieve the top 3 matching documents.
- The Document Reader (a multilayer RNN) is then initiated to retrieve the answers from the document.
- We use a pretrained model on the SQUAD Dataset.
- We do transfer learning on the Children's Gutenberg dataset. You can download the pre-processed Gutenberg Children’s Book corpus for the DrQA model here.
- The model embedding layer is initiated by pretrained Stanford CoreNLP embedding vector.
- The model returns the most probable answer span from each of the top 3 documents.
- We can speed up the model performance significantly through data-parallel inference, using this model on multiple GPUs.
The pipeline returns the most probable answer list from the top three most matched documents.
We then run the interactive pipeline using this trained DrQA model to test the Gutenberg Children’s Book Corpus.
For environment setup, please follow ReadMe.md in GitHub to download the code and install dependencies. For all code and related details, please refer to our GitHub link here.
MRS Using DLVM
Please follow similar steps listed in this notebook to test the DrQA model on DLVM.
Learnings from Our Evaluation Work
In this post, we investigated the performance of the MRS model on our own custom dataset. We tested the performance of the transfer learning approach for creating a QA system for around 528 children’s books from the Project Gutenberg Corpus using the pretrained DrQA model. Our evaluation results are captured in the exhibits below and in the explanation that follows. Note that these results are particular to our evaluation scenario – results will vary for other documents or scenarios.
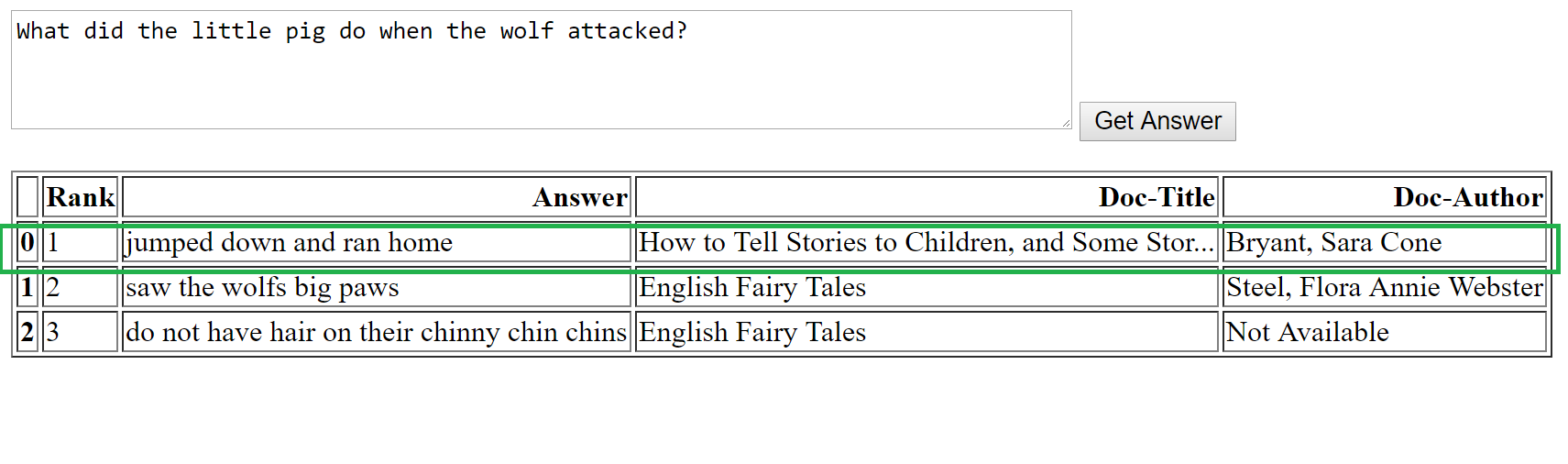

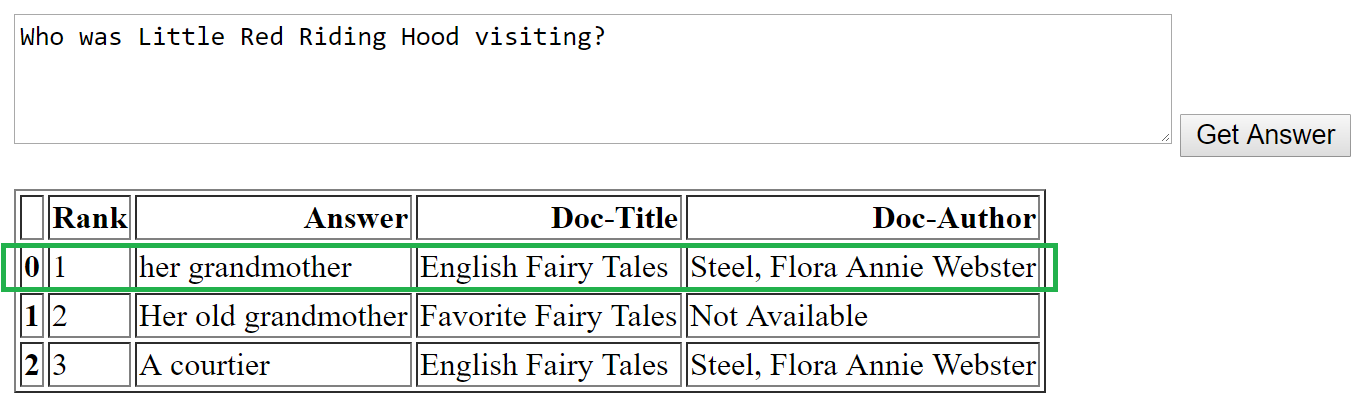
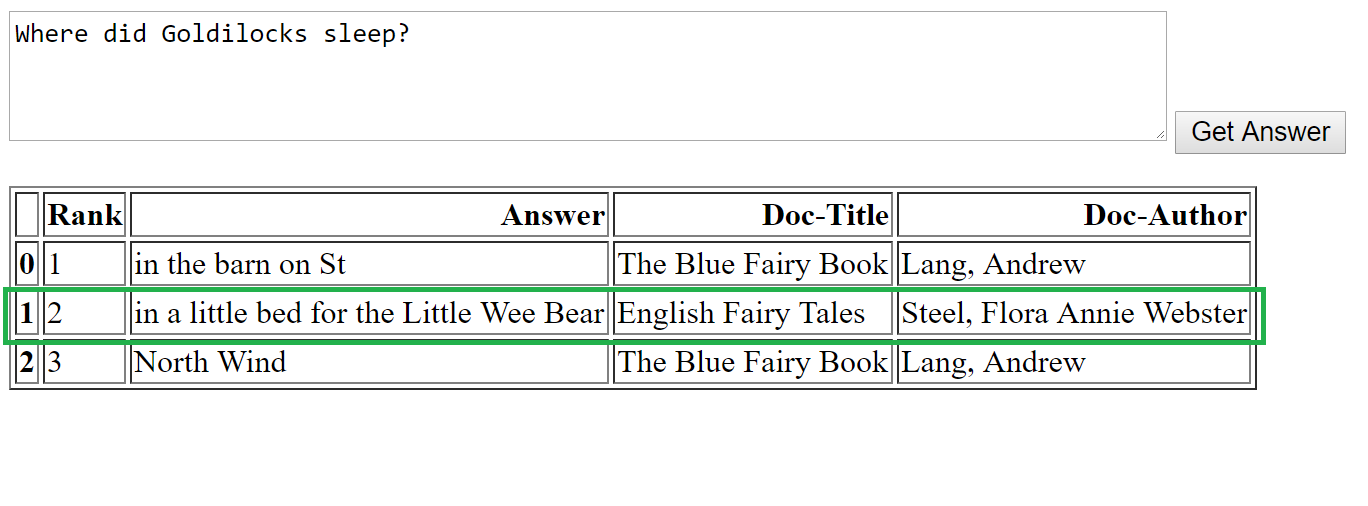

In the above examples, we tried questions beginning with What, How, Who, Where and Why – and there’s an important aspect about MRS that is worth noting, namely:
- MRS is best suited for “factoid” questions. Factoid questions are about providing concise facts. E.g. "Who is the headmaster of Hogwarts?" or "What is the population of Mars”. Thus, for the What, Who and Where types of questions above, MRS works well.
- For non-factoid questions (e.g. Why), MRS does not do a very good job.
The green box represents the correct answer for each question. As we see here, for factoid questions, the answers chosen by the MRS model are in line with the correct answer. In the case of the non-factoid “Why” question, however, the correct answer is the third one, and it’s the only one that makes any sense.
Overall, our evaluation scenario shows that for generic large document corpuses, the DrQA model does a good job of answering factoid questions.
Anusua
@anurive | Email Anusua at antriv@microsoft.com for questions pertaining to this post.