Datenpunkte
Syndizierte Daten und isolierter Speicher in Silverlight
John Papa
Codedownload verfügbar in der MSDN-Codegalerie
Code online durchsuchen
Inhalt
Letzte Schritte
HTTP-Webanforderungen und -Threading
Hinzufügen eines Feeds
Analysieren von Feeds
Domänenübergreifende Anforderungen für Feeds
Grundlegender isolierter Speicher
Organisierter isolierter Speicher
Zusammenfassung
Silverlight ist ideal zum Erstellen einer syndizierten Nachrichtleseanwendung. Silverlight kann syndizierte RSS- und AtomPub-Formate lesen, über HTTP-Anforderungen mit Webdiensten kommunizieren und domänenübergreifende Richtlinien behandeln. Nachdem die syndizierten Daten empfangen wurden, können sie in eine Klassenstruktur eingelesen, mit LINQ analysiert und dem Benutzer über eine XAML-basierte Datenbindung angezeigt werden.
In diesem Artikel werde ich vorführen, wie diese einzigartigen Features verwendet werden können, um eine Leseanwendung für syndizierte Nachrichten zu erstellen. Ich werde Ihnen auch zeigen, wie Sie Probleme mit der Webdienstkommunikation von Silverlight aus debuggen und Daten mithilfe von isoliertem Speicher lokal speichern können. Alle Beispiele sind im MSDN-Codedownload verfügbar.
Letzte Schritte
Feedsyndikation bietet über Webdienste Zugriff auf die Formate RSS und AtomPub. Auf jeden Feed wird mit den Formaten RSS oder AtomPub über einen URI zugegriffen, der XML zurückgibt, das die Feedelemente enthält. Die mit diesem Artikel zur Verfügung gestellte Beispielanwendung stellt Verfahren vor, mit denen syndizierte Daten mithilfe von Webdienstanforderungen in eine Silverlight-Anwendung eingelesen werden können. Bevor wir ins Detail gehen, könnte es hilfreich sein, wenn ich Ihnen die Endversion der Anwendung zeige. Anschließend werde ich die Logik und verschiedene andere Aspekte des Anwendungscodes diskutieren.
Abbildung 1 zeigt die Silverlight-Anwendung, die die beiden syndizierten Feeds liest:
http://pipes.yahooapis.com/pipes/pipe.run?_id=957
d9624940693fb9f9644d7b12fb0e9&_render=rss
http://pipes.yahooapis.com/pipes/pipe.run?_id=057559bac7aad6640b
c17529f3421db0&_render=rss
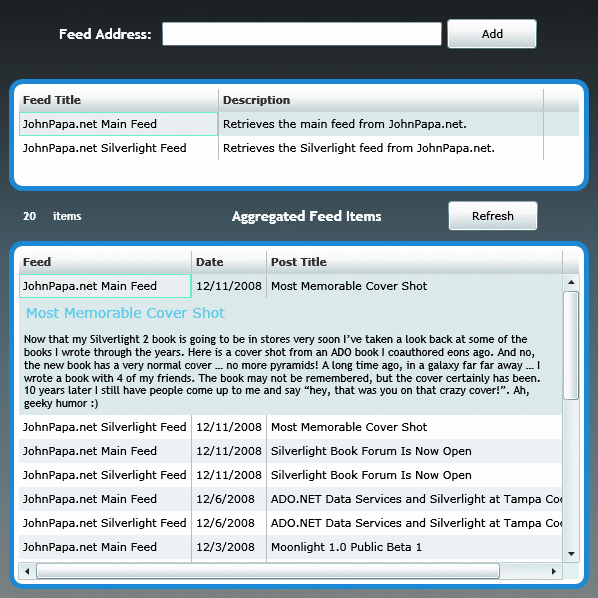
Abbildung 1 Die SilverlightSyndication-Anwendung
Eine Webanforderung wird gesendet, um Feeddaten zu sammeln, wenn der Benutzer auf die Schaltfläche „Add“ (Hinzufügen) klickt. Der URI des Feeds ist lokal auf dem Clientcomputer gespeichert, und der Titel des Feeddiensts wird im oberen DataGrid-Steuerelement angezeigt.
Das Speichern des URI des Feeds auf dem Clientcomputer ermöglicht der Silverlight-Anwendung, die Feeddaten für diese Feeds beim Starten der Anwendung abzurufen. Sobald die Feeddaten gesammelt wurden, werden die Elemente in eine Liste von Objekten platziert und anschließend mittels LINQ analysiert. Die Ergebnisse werden anschließend in sortierter Reihenfolge an das untere DataGrid-Steuerelement gebunden.
HTTP-Webanforderungen und -Threading
Das Nutzen syndizierter Feeds von Silverlight-Anwendungen aus beginnt mit der Fähigkeit, Webanforderungen zu senden. Sowohl die WebClient- als auch die HttpWebRequest-Klassen können HTTP-Webanforderungen von Silverlight-Anwendungen aus senden. Der erste Schritt im Prozess entscheidet darüber, welches Verfahren zum Senden von HTTP-Webanforderungen verwendet wird. In den meisten Fällen ist die WebClient-Klasse alles, was notwendig ist, da sie einfacher zu verwenden ist (intern ruft sie auch HttpWebRequest auf). HttpWebRequest ermöglicht eine umfassendere Anpassung von Anforderungen.
In diesem Codeausschnitt wird veranschaulicht, wie eine Anforderung über WebClient gesendet werden kann:
//feedUri is of type Uri
WebClient request = new WebClient();
request.DownloadStringCompleted += AddFeedCompleted;
request.DownloadStringAsync(feedUri);
Im folgenden Code wird hingegen gezeigt, wie ein ähnlicher Aufruf mittels HttpWebRequest erfolgt:
//feedUri is of type Uri
WebRequest request = HttpWebRequest.Create(feedUri);
request.BeginGetResponse(new AsyncCallback(ReadCallback), request);
Die WebClient-Klasse ist einfacher zu verwenden, weil sie einen Teil der Funktionalität der HttpWebRequest-Klasse umschließt.
Da alle HTTP-Webanforderungen von Silverlight aus asynchron sowohl über WebClient als auch über HttpWebRequest gesendet werden, ist es wichtig zu verstehen, wie Daten verarbeitet werden, wenn die Aufrufe zurückgegeben werden. Wenn HttpWebRequest seine asynchronen Aufrufe durchführt und abgeschlossen wird, ist nicht garantiert, dass der abgeschlossene Ereignishandler im Benutzeroberflächenthread arbeitet. Wenn Daten abgerufen wurden und in einem Benutzeroberflächenelement angezeigt werden sollen, muss der Aufruf des Benutzeroberflächenelements über ein Verfahren erfolgen, das die Steuerung vom Hintergrundthread zurück zum Benutzeroberflächenthread überträgt. Dies kann mit der Dispatcher- oder der SynchronizationContext-Klasse durchgeführt werden. Der folgende Code zeigt, wie ein Aufruf durch Verwendung des Benutzeroberflächenthreads mit der BeginInvoke-Methode der Dispatcher-Klasse durchgeführt werden kann:
Deployment.Current.Dispatcher.BeginInvoke(() =>
{
MyDataGrid.DataContext = productList;
});
Dieses Codebeispiel nimmt die productList-Variable (die mit den von einem Webdienstaufruf zurückgegebenen Daten gefüllt wurde) und setzt sie auf das DataContext eines Benutzeroberflächenelements. In diesem Fall wird ein DataGrid nun an eine Produktliste gebunden. Die Dispatcher-Klasse wird jedoch nicht benötigt, wenn der Aufruf über die WebClient-Klasse erfolgte. In diesem Fall könnte der Code die Produktliste einfach direkt das DataContext des Benutzeroberflächenelements setzen.
Um die SynchronizationContext-Klasse zu verwenden, muss eine Instanz der SynchronizationContext-Klasse an einem Ort erstellt werden, wo der Benutzeroberflächenthread bekanntermaßen zur Verfügung steht. Der Konstruktor und Ladeereignishandler sind gute Orte zum Erstellen einer SynchronizationContext-Instanz. Dieses Codebeispiel zeigt, wie das _syncContext-Feld im Klassenkonstruktor initialisiert wird:
public Page() {
_syncContext = SynchronizationContext.Current;
}
Dieser Code zeigt außerdem, wie die SynchronizationContext-Instanz ihre Post-Methode verwendet, um den Aufruf der LoadProducts-Methode durchzuführen. Dies stellt sicher, dass die LoadProducts-Methode Zugriff auf den Benutzeroberflächenthread hat:
if (_syncContext != null) {
_syncContext.Post(delegate(object state){ LoadProducts(products); }
,null);
}
Neben der Tatsache, dass sie einfacher anzuwenden sind, kommen WebClient-Anforderungen im Benutzeroberflächenthread immer zurück. Dies bedeutet, dass alle Ergebnisse der WebClient-Anforderung problemlos an die Benutzeroberflächenelemente gebunden werden können, ohne die Dispatcher-Klasse (oder optional die SynchronizationContext-Klasse statt Dispatcher) einbeziehen zu müssen. Zum Lesen der syndizierten Daten ist die WebClient-Klasse angemessen und wird für die Beispielanwendung in diesem Artikel verwendet.
Hinzufügen eines Feeds
In der Beispielanwendung wird der in Abbildung 2 gezeigte Code ausgeführt, wenn der Benutzer eine Feedadresse eingibt und auf die Schaltfläche „Add “ klickt. Zuerst versucht der Code, einen URI aus der Adresse zu erstellen, und verwendet dabei nach Möglichkeit die Uri.TryCreate-Methode. Wenn es ihm gelingt, einen URI zu erstellen, wird der URI an die lokale feedUri-Variable zurückgegeben. Andernfalls bleibt feedUri null, und der Code wird beendet.
Abbildung 2 Hinzufügen eines Feeds
private void btnAdd_Click(object sender, RoutedEventArgs e)
{
Uri feedUri;
Uri.TryCreate(txtAddress.Text, UriKind.Absolute, out feedUri);
if (feedUri == null)
return;
LoadFeed(feedUri);
}
public void LoadFeed(Uri feedUri)
{
WebClient request = new WebClient();
request.DownloadStringCompleted += AddFeedCompleted;
request.DownloadStringAsync(feedUri);
}
Nachdem ein gültiger URI erstellt wurde, wird die LoadFeed-Methode ausgeführt, die die HTTP-Anforderung sendet, um mithilfe der WebClient-Klasse die Feeddaten zu sammeln. Die WebClient-Instanz wird erstellt, und dem DownloadStringCompleted-Ereignis wird ein Ereignishandler zugewiesen. Wenn die DownloadStringAsync-Methode ausgeführt und bereit ist, ihre Daten zurückzugeben, muss der Ereignishandler bekannt sein, an den die Daten gehen sollen. Deshalb muss der Ereignishandler (in diesem Fall AddFeedCompleted) zugewiesen werden, bevor das asynchrone Ereignis ausgeführt wird.
Nachdem die Anforderung abgeschlossen ist, wird der AddFeedCompleted-Ereignishandler ausgeführt (siehe Abbildung 3). Der DownloadStringCompletedEventArgs-Parameter enthält eine Result- und eine Error-Eigenschaft, die beide nach jeder Webanforderung geprüft werden müssen. Die e.Error-Eigenschaft ist null, wenn keine Fehler während der Anforderung aufgetreten sind. Die e.Result-Eigenschaft enthält die Ergebnisse der Webanforderung. In der Beispielanwendung wird e.Result das XML enthalten, das die Feeddaten repräsentiert.
Abbildung 3 AddFeedCompleted
private void AddFeedCompleted(object sender,
DownloadStringCompletedEventArgs e)
{
if (e.Error != null)
return;
string xml = e.Result;
if (xml.Length == 0)
return;
StringReader stringReader = new StringReader(xml);
XmlReader reader = XmlReader.Create(stringReader);
SyndicationFeed feed = SyndicationFeed.Load(reader);
if (_feeds.Where(f => f.Title.Text == feed.Title.Text).ToList().Count > 0)
return;
_feeds.Add(feed); // This also saves the feeds to isolated storage
ReBindAggregatedItems();
txtAddress.Text = string.Empty;
}
Nachdem Feeddaten gesammelt wurden, können sie mithilfe der Load-Methode der SyndicationFeed-Klasse in die System.ServiceModel.SyndicationFeed-Klasse eingelesen werden. Beachten Sie, dass, wenn Feeddaten abgerufen und schreibgeschützt verwendet werden, die Verwendung von LINQ to XML zum Abrufen und Laden des Feeds in ein benutzerdefiniertes Objekt eine bessere Option als SyndicationFeed sein kann. SyndicationFeed hat mehr Features, aber wenn sie nicht verwendet werden, ist es möglicherweise nicht die zusätzliche Größe wert, die der XAP-Datei hinzugefügt wird. SyndicationFeed fügt der XAP-Datei über 150 KB hinzu, während es bei LINQ to XML etwa 40 KB sind. Mit der zusätzlichen Leistungskraft von SyndicationFeed werden ebenfalls durch die Größe Kosten entstehen.
SyndicationFeed ist eine besondere Klasse, die weiß, wie Feeddaten (sowohl RSS als auch AtomPub) als Objekt zu repräsentieren sind. Es enthält Eigenschaften, die den Feed selbst beschreiben, wie z. B. Title und Description, sowie eine Items-Eigenschaft, die ein IEnumerable<SyndicationItem> enthält. Jede SyndicationItem-Klasseninstanz repräsentiert ein Feedelement für den Feed. Die Feeds werden beispielsweise von Instanzen der SyndicationFeed-Klasse repräsentiert, und ihre Items-Auflistungen enthalten die einzelnen Beiträge aus den Feeds.
Nachdem die SyndicationFeed-Klasse mit dem Feed und seinen Elementen geladen wurde, führt der in Abbildung 3 gezeigte Code eine Überprüfung durch, um zu sehen, ob der gleiche Feed bereits aufgefordert wurde. Wenn dies der Fall ist, wird der Code sofort beendet. Andernfalls wird das Feed zum lokalen ObservableCollection<SyndicationFeed> namens „_feeds“ hinzugefügt. Durch die ReBindAggregatedItems-Methode werden anschließend die Feedelemente aus allen geladenen Feeds gefiltert, sortiert und an das untere DataGrid gebunden. Da die WebClient-Klasse die HTTP-Webanforderung gesendet hat, hat der AddFeedCompleted-Ereignishandler Zugriff auf den Benutzeroberflächenthread. Deshalb kann der Code innerhalb der ReBindAggregatedItems-Methode die Daten ohne die Hilfe der Dispatcher-Klasse an das DataGrid-Benutzeroberflächenelement binden.
Analysieren von Feeds
Wenn die ReBindAggregatedItems-Methode ausgeführt wird, werden die Feeddaten in einer Auflistung von SyndicatedFeed-Instanzen und den entsprechenden Auflistungen von SyndicatedItem-Instanzen gespeichert. LINQ ist ideal zum Abfragen der Feeddaten, da es sich jetzt in einer Objektstruktur befindet. Die Daten mussten nicht in SyndicatedFeed-Objekte geladen werden. Stattdessen konnten sie in ihrem systemeigenen XML-Format (RSS oder AtomPub) bleiben und mithilfe von XmlReader oder LINQ to XML analysiert werden. Die SyndicatedFeed-Klasse vereinfacht jedoch die Verwaltung, und LINQ kann immer noch zum Abfragen von Daten verwendet werden.
Das Anzeigen der Feedelemente für mehrere Feeds erfordert, dass alle Feedelemente zusammengeführt werden. Mit der in Abbildung 4 dargestellten LINQ-Abfrage wird veranschaulicht, wie alle Feedelemente (SyndicationItem-Instanzen) für alle Feeds (SyndicationFeed-Instanzen) erfasst und nach ihrem Veröffentlichungsdatum sortiert werden können.
Abbildung 4 Abfragen von Feeds mit LINQ
private void ReBindAggregatedItems()
{
//Read the feed items and bind them to the lower list
var query = from f in _feeds
from i in f.Items
orderby i.PublishDate descending
select new SyndicationItemExtra
{ FeedTitle = f.Title.Text, Item = i };
var items = query.ToList();
feedItemsGridLayout.DataContext = items;
}
Beachten Sie in Abbildung 4, dass die Abfrage eine Liste von SyndicationItemExtra-Klassen zurückgibt. Die SyndicationItemExtra-Klasse ist eine benutzerdefinierte Klasse, die eine FeedTitle-Eigenschaft vom Typ „string“ und eine Item-Eigenschaft vom Typ „SyndicationItem“ enthält. Die Anwendung zeigt die Feedelemente in DataGrid an. Die meisten Daten dafür sind in der SyndicationItem-Klasse zu finden.
Da die Anwendung jedoch Elemente aus mehreren Feeds zusammenführt, wir durch Anzeigen des Titels jedes Feeds für jedes Feedelement verdeutlicht, von welchem Feed jedes Element stammt. Der Titel für den Feed ist von der SyndicationItem-Klasse nicht zugänglich. Deshalb verwendet die Anwendung eine benutzerdefinierte Klasse namens „SyndicationItemExtra“, in der SyndicationItem und der Titel des Feeds gespeichert werden.
Die Feedelemente werden anschließend an das feedItemsGridLayout-Grid-Panel in der Silverlight-Anwendung gebunden. Das Grid-Panel enthält DataGrid sowie andere Benutzeroberflächenelemente (wie z. B. die Anzahl der Elemente, die in einem TextBlock angezeigt werden), die in Datenbindungsvorgänge involviert sind, um Informationen zu den Feedelementen anzuzeigen.
Domänenübergreifende Anforderungen für Feeds
Anforderungen zum Sammeln von Feeds sind HTTP-Webanforderungen, die im Allgemeinen Anforderungen an eine andere Webdomäne senden. Jede Webanforderung von Silverlight, die mit einer anderen Domäne kommuniziert als mit der, die die Silverlight-Anwendung hostet, muss der domänenübergreifenden Richtlinie der Remotedomäne entsprechen. Das Diagramm in Abbildung 5 veranschaulicht diese Situation vor.

Abbildung 5 Domänenübergreifender Aufruf für einen Feed
Weitere Informationen zu domänenübergreifenden Richtlinien finden Sie in meinem Artikel in der Rubrik „Datenpunkte“ vom September 2008. In diesem Artikel werden die Dateiformate und die Funktionsweise der Richtlinien behandelt.
Wenn eine HTTP-Webanforderung domänenübergreifend durchgeführt wird, kommt Silverlight dieser Anforderung durch Anfordern der domänenübergreifenden Richtliniendatei vom Remotewebserver zuvor. Silverlight sucht zuerst nach der Datei „clientaccesspolicy.xml“ (domänenübergreifende Richtliniendatei von Silverlight), und wenn diese nicht gefunden wird, sucht Silverlight anschließend nach der Datei „crossdomain.xml“ (domänenübergreifende Richtliniendatei von Flash). Wenn keine der Dateien gefunden wird, schlägt die Anforderung fehl, und es wird ein Fehler ausgegeben. Dieser Fehler kann im DownloadStringCompleted-Ereignishandler erfasst und bei Bedarf dem Benutzer angezeigt werden.
Wenn der URI „http://johnpapa.net/feed/default.aspx“ in die Beispielanwendung eingegeben wird, sucht Silverlight zuerst im Stamm des johnpapa.net-Webservers nach einer der domänenübergreifenden Richtliniendateien. Wenn keine der Dateien gefunden wird, wird ein Fehler zur Anwendung zurückgegeben. An diesem Punkt kann die Anwendung bei Bedarf den Benutzer benachrichtigen. In Abbildung 6 wird das FireBug-Plug-In gezeigt, das alle Anforderungen des Browsers nachverfolgt. Es wird der Browser gezeigt, der nach domänenübergreifenden Richtliniendateien sucht, diese nicht findet und ohne Anfordern des RSS-Feeds zurückkehrt.
.gif)
Abbildung 6 Debuggen domänenübergreifender Feedaufrufe
FireBug ist ein großartiges Tool zum Beobachten von HTTP-Anforderungen in Firefox, und Web Development Helper ist ein hervorragendes Tool bei Verwendung von Internet Explorer. Eine andere Option ist Fiddler2, eine eigenständige Anwendung, die den gesamten Datenverkehr auf Ihrem Computer beobachten kann.
Eine Lösung für dieses Problem besteht darin, den Webadministrator für den Feed zu bitten, im Stamm des Webservers eine clientaccesspolicy.xml-Datei zu platzieren. Dies kann unrealistisch sein, da Sie sehr wahrscheinlich weder den Remotewebserver kontrollieren noch wissen, wer ihn kontrolliert. Eine andere Option besteht darin zu prüfen, ob der Feed einen Mittlerdienst wie z. B. Yahoo Pipes verwendet. Der Hauptfeed unter johnpapa.net kann beispielsweise mit dem URI „http://pipes.yahooapis.com/pipes/pipe.run?_id=057559bac7aad6640bc17529f3421db0&_render=rss“ über Yahoo Pipes abgerufen werden. Da unter http://pipes.yahooapis.com/clientaccesspolicy.xml eine domänenübergreifende Richtliniendatei vorhanden ist, die einen offenen Zugriff ermöglicht, ist dies eine gute Alternative.
Eine dritte Option besteht darin, einen Dienst wie z. B. Popfly oder FeedBurner zu verwenden, um die Feeds zu aggregieren, wobei sie effektiv durch einen Dienst geleitet werden, der ebenfalls eine offene domänenübergreifende Richtlinie besitzt. Die vierte und letzte Option wäre, Ihren eigenen benutzerdefinierten Webdienst zu schreiben, der die Feeds sammelt und anschließend an die Silverlight-Anwendung leitet. Das Verwenden eines Diensts wie Popfly oder Yahoo Pipes bietet die einfachsten Lösungen.
Grundlegender isolierter Speicher
Die Beispielanwendung lässt einen Benutzer mehrere Feeds hinzufügen und alle Elemente für jeden dieser Feeds anzeigen. Wenn ein Benutzer 10 Feeds eingibt und sich dann entscheidet, die Anwendung zu schließen und die Feeds später zu lesen, würde er wahrscheinlich erwarten, dass die Feeds von der Anwendung gespeichert werden. Andernfalls müsste er den URI für jeden Feed jedes Mal eingeben, wenn die Anwendung geöffnet wird. Da diese Feeds für einen Benutzer spezifisch sind, können sie entweder (mithilfe einiger Token zur Identifizierung des Benutzers, der sie eingegeben hat) auf dem Server gespeichert oder auf dem Computer des Benutzers eingegeben werden.
Silverlight ermöglicht es, dass Daten mithilfe der Klassen im System.IO.IsolatedStorage-Namespace in einem geschützten Bereich auf dem Computer des Benutzers gespeichert werden. Isolierter Speicher von Silverlight ähnelt äußerst leistungsfähigen Cookies: Er ermöglicht Ihnen, einfache Skalarwerte oder sogar serialisierte komplexe Objektdiagramme auf dem Clientcomputer zu speichern. Die einfachste Möglichkeit, Daten in isoliertem Speicher zu speichern, besteht darin, einen ApplicationSettings-Eintrag zu erstellen und Ihre Daten darin zu speichern, wie hier dargestellt:
private void SaveFeedsToStorage_UsingSettings()
{
string data = GetFeedsFromStorage_UsingSettings() + FEED_DELIMITER +
txtAddress.Text;
if (IsolatedStorageSettings.ApplicationSettings.Contains(FEED_DATA))
IsolatedStorageSettings.ApplicationSettings[FEED_DATA] = data;
else
IsolatedStorageSettings.ApplicationSettings.Add(FEED_DATA, data);
}
Dies kann jedes Mal aufgerufen werden, wenn ein SyndicationFeed hinzugefügt wird oder aus der ObservableCollection<SyndicationFeed>-Feldinstanz namens „_feeds“ entfernt wird. Da ObservableCollection ein CollectionChanged-Ereignis verfügbar macht, kann dem Ereignis, das das Speichern durchführt, ein Handler zugewiesen werden, wie hier gezeigt:
_feeds.CollectionChanged += ((sender, e) => {
SaveFeedsToStorage_UsingSettings(); });
Wenn die SaveFeedsToStorage_UsingSettings-Methode ausgeführt wird, wird zuerst die GetFeedsFromStorage_UsingSettings-Methode aufgerufen, die die Adressen aller Feeds aus dem isolierten Speicher liest und in einer einzigen, durch Sonderzeichen getrennten Zeichenfolge platziert.
Wenn die Anwendung zum ersten Mal gestartet wird, ruft die LoadFeedsFromStorage_UsingSettings-Methode die Feeds aus dem isolierten Speicher ab:
private void LoadFeedsFromStorage_UsingSettings()
{
string data = LoadFeedsFromStorage_UsingSettings();
string[] feedList = data.Split(new string[1] { FEED_DELIMITER },
StringSplitOptions.RemoveEmptyEntries);
foreach (var address in feedList)
LoadFeed(new Uri(address));
}
Der Code liest zuerst die Liste von URI-Adressen für jedes Feed aus dem isolierten Speicher. Anschließend werden die Adressen aufgerufen, und jeder Feed wird einzeln mithilfe der LoadFeed-Methode geladen.
Organisierter isolierter Speicher
Dieses Feature ermöglicht der Anwendung, sich an die Feedadressen für den Benutzer zu erinnern und sie zu laden, wenn der Benutzer die Anwendung ausführt. Das Verpacken der URI-Adressen in eine durch Trennzeichen getrennte Zeichenfolge ist einfach, aber weder elegant noch effizient. Wenn Sie beispielsweise mehr als nur einen einzelnen Skalarwert speichern möchten, würde dies mit diesem Verfahren kompliziert werden.
Eine andere Möglichkeit, Daten in isoliertem Speicher zu speichern, besteht darin, die Klassen „IsolatedStorageFile“ und „IsolatedStorageFileStream“ zu verwenden, wodurch Sie für jeden Benutzer komplexere Datenstrukturen speichern können, einschließlich serialisierter Objekte. Die Daten können sogar in verschiedene Dateien und Ordner in isoliertem Speicher segmentiert werden. Dies ist ideal für das Organisieren von Daten, die in isoliertem Speicher gespeichert werden. Zum Beispiel könnte ein Ordner für alle statischen Datenlisten erstellt werden, und es könnte eine separate Datei für jede Liste erstellt werden. Auf diese Weise kann es innerhalb eines Ordners im isolierten Speicher eine Datei für Namenpräfixe, eine für das Geschlecht und eine weitere Datei für Länder geben.
Die Beispielanwendung könnte im isolierten Speicher eine Datei erstellen, die eine Liste mit URI-Adressen enthält. Die Daten müssen zuerst serialisiert und anschließend an die Datei im isolierten Speicher gesendet werden (siehe Abbildung 7). Zuerst wird mithilfe der GetUserStoreForApplication-Methode eine Instanz der IsolatedStorageFile-Klasse für den aktuellen Benutzer erstellt. Danach wird ein Dateistrom erstellt, damit die Anwendung die URI-Adresse schreiben kann. Die Daten werden anschließend serialisiert und in die IsolatedStorageFileStream-Instanz geschrieben. Im Beispiel für diese Anwendung wird eine Zeichenfolge serialisiert, aber es kann jedes serialisierbare Objekt in den isolierten Speicher geschrieben werden.
Abbildung 7 Speichern serialisierter Daten in einer isolierten Speicherdatei
private void SaveFeedsToStorage_UsingFile() {
using (var isoStore = IsolatedStorageFile.GetUserStoreForApplication())
{
List<string> data = GetFeedsFromStorage_UsingFile();
if (data == null)
if (txtAddress.Text.Length == 0)
return;
else
data = new List<string>();
using (var isoStoreFileStream =
new IsolatedStorageFileStream(FEED_FILENAME,
FileMode.Create, isoStore)) {
data.Add(txtAddress.Text);
byte[] bytes = Serialize(data);
isoStoreFileStream.Write(bytes, 0, bytes.Length);
}
}
}
Das Lesen serialisierter Daten aus einer Datei in isoliertem Speicher bedeutet etwas mehr Aufwand als das vorherige Beispiel. In Abbildung 8 wird gezeigt, dass Sie zuerst eine Instanz der IsolatedStorageFile-Klasse für den Benutzer haben und dann überprüfen müssen, ob die Datei existiert, bevor Sie sie auslesen. Wenn die Datei existiert, wird die Datei für Lesezugriff geöffnet, was das Lesen der Daten über einen Datenstrom des Typs „IsolatedStorageFileStream“ ermöglicht. Die Daten werden aus dem Datenstrom gelesen, zusammengefügt und anschließend deserialisiert, damit sie zum Laden syndizierter Feeds verwendet werden können.
Abbildung 8 Lesen serialisierter Daten aus einer isolierten Speicherdatei
private List<string> GetFeedsFromStorage_UsingFile() {
byte[] feedBytes;
var ms = new MemoryStream();
using (var isoStore =
solatedStorageFile.GetUserStoreForApplication())
{
if (!isoStore.FileExists(FEED_FILENAME)) return null;
using (var stream = isoStore.OpenFile(FEED_FILENAME,
FileMode.Open, FileAccess.Read)) {
while (true) {
byte[] tempBytes = new byte[1024];
int read = stream.Read(tempBytes, 0, tempBytes.Length);
if (read <= 0) {
//feedBytes = ms.ToArray();
break;
}
ms.Write(tempBytes, 0, read);
}
}
feedBytes = ms.ToArray();
List<string> feedList = Deserialize(typeof(List<string>),
feedBytes) as List<string>;
return feedList;
}
}
private void LoadFeedsFromStorage_UsingFile() {
var feedList = GetFeedsFromStorage_UsingFile();
foreach (var address in feedList) {
Uri feedUri;
Uri.TryCreate(address, UriKind.Absolute, out feedUri);
if (feedUri != null)
LoadFeed(feedUri);
}
}
Für einfachere Datenstrukturen ist es möglicherweise nicht notwendig, serialisierte Objekte und Dateien in isoliertem Speicher zu verwenden. Wenn isolierter Speicher jedoch für mehrere Arten lokalen Speichers verwendet wird, kann er beim Organisieren der Daten helfen und einfachen Zugriff zum Lesen und Schreiben bieten. Isolierter Speicher sollte beim Speichern von Daten, die lokal zwischengespeichert werden sollen, mit Bedacht verwendet werden.
Beachten Sie auch die Tatsache, dass Benutzer den Speicher jederzeit endgültig löschen können, da sie vollständige Kontrolle über ihre Einstellungen haben. Dies bedeutet, dass Daten, die in isoliertem Speicher gespeichert werden, nicht als garantiert permanent gespeichert betrachtet werden sollten. Ein weiteres gutes Beispiel ist das Speichern einer Liste von Ländern im isolierten Speicher, damit nicht jedes Mal, wenn ein Kombinationsfeld mit einer Liste von Ländern gefüllt werden muss, eine Webanforderung (und ein Datenbanktreffer) benötigt wird.
Zusammenfassung
In der Beispielanwendung wird veranschaulicht, wie einfach es ist, die RSS- und AtomPub-Feeds in eine Silverlight-Anwendung zu laden. Durch Silverlight wird Folgendes ermöglicht: Durchführen einer Webanforderung, Annehmen ihrer Ergebnisse, Verwalten domänenübergreifender Richtlinienaufrufe, Laden von Feeddaten in SyndicationFeed-Klassen, Abfragen der Daten mit LINQ, Binden der Daten an Benutzeroberflächenelemente und Speichern von Feeddaten in isoliertem Speicher.
Senden Sie Fragen und Kommentare für John Papa in englischer Sprache an mmdata@microsoft.com.
John Papa (johnpapa.net) ist leitender Berater bei ASPSOFT. Als leidenschaftlicher Baseballfan feuert er an den Sommerabenden zusammen mit seiner Familie die Yankees an. Er ist C#-MVP und INETA-Sprecher, hat mehrere Bücher verfasst und arbeitet derzeit an seinem aktuellen Buch Data-Driven Services with Silverlight 2. John Papa hält häufig Vorträge auf Konferenzen wie DevConnections und VSLive.