Testlauf
Analysieren von Projektgefährdung und Risiken mit PERIL
Dr. James McCaffrey
Codedownload verfügbar in der MSDN-Codegalerie
Code online durchsuchen
Inhalt
Metarisiken
Risikoerkennung
Risikoanalyse
Zusammenfassung
Alle Softwareprojekte sind mit Risiken verbunden. Ein Risiko ist ein Ereignis, das möglicherweise stattfindet und zu einer Art von Verlust führt. Zwischen Risiken und Softwaretests gibt es eine einfache Beziehung. Da ein Softwaresystem, abgesehen von seltenen Umständen, nicht vollständig getestet werden kann, werden mit der Risikoanalyse Probleme aufgedeckt, die den größten Verlust verursachen. Diese Informationen können zum Priorisieren von Tests verwendet werden. Im Artikel dieses Monats werden praktische Verfahren vorgestellt, mit denen Sie die mit einem Softwareprojekt verbundenen Risiken erkennen und analysieren können. Betrachten Sie als Erstes die folgende hypothetische Situation.
Sie entwickeln eine Art ASP.NET-Webanwendung. In Abbildung 1 sind einige der wichtigsten Begriffe und Probleme dargestellt, die mit der Softwarerisikoanalyse verbunden sind. Der Gesamtprozess der Risikoanalyse umfasst das Erkennen der jeweiligen Risiken, die Einschätzung, wie wahrscheinlich ein Risiko eintritt, die Ermittlung des mit den einzelnen Risiken verbundenen Verlusts und das Kombinieren der Wahrscheinlichkeits- und Verlustinformationen zu einem Wert, der Risikopotenzial genannt wird.
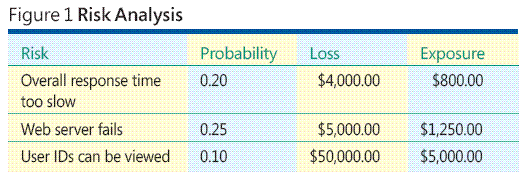
Entsprechend den Beispieldaten in Abbildung 1 birgt das Risiko, dass Benutzer-IDs angezeigt werden können, das größte Risikopotenzial. Wenn die anderen Faktoren gleichwertig sind, werden Sie beim Testen diesem Risiko wahrscheinlich oberste Priorität zuordnen, um zu verhindern, dass es zur Realität wird. Wie können Sie aber Risiken identifizieren? Wie lassen sich Risikowahrscheinlichkeit und Verlust einschätzen? Kann eine Risikoanalyse auch dann durchgeführt werden, wenn Sie die Risikowahrscheinlichkeit und den Verlust nicht einschätzen können?
Es wurde zwar mehrfach versucht, die Terminologie der Risikoanalyse zu formalisieren und zu standardisieren, in der Praxis werden in verschiedenen Problemdomänen allerdings oft unterschiedliche Begriffe verwendet. Im Folgenden bedeutet der Begriff „Risikoanalyse“ das Berechnen des Risikopotenzials durch Multiplizieren der Risikowahrscheinlichkeit mit dem Risikoverlust bzw. der Gesamtprozess der Erkennung, Analyse und Verwaltung des Softwareprojektrisikos.
Trotz der Tatsache, dass die Analyse ein sehr wichtiger Teil der Softwareentwicklung ist, sind viele Risikoanalyseverfahren meiner Erfahrung nach in der Softwaretestcommunity nicht allgemein bekannt. Wenn Sie das Web durchsuchen, finden Sie Zehntausende von Verweisen zur Softwarerisikoanalyse. Doch bei der Mehrzahl dieser Verweise wird die Risikoanalyse auf einer sehr allgemeinen Ebene behandelt, und es werden keine praktischen Verfahren bzw. nur ein spezifisches Risikoanalyseverfahren geboten und nicht erläutert, wie sich das Verfahren in ein Framework zur Gesamtrisikoanalyse einfügt. Im Folgenden erhalten Sie sowohl einen Überblick über die Risikoanalyse als auch nützliche Verfahren, die Sie sofort in Ihrer Entwicklungsumgebung einsetzen können.
In den Abschnitten dieses Artikels werden zwei Metarisiken beschrieben, die alle Softwareprojekte gemeinsam haben. Anschließend werden drei Möglichkeiten aufgezeigt, mit denen Sie spezifische mit Ihrem Softwareprojekt verbundene Risiken identifizieren können, sowie drei Möglichkeiten zur Risikoanalyse. Insbesondere wird ein interessantes neues Risikoanalyseverfahren namens „Project Exposure using Ranked Impact and Likelihood“ (PERIL) vorgestellt, das vor allem in einer Softwareentwicklungsumgebung nützlich ist. Abschließend folgt eine kurze Besprechung des Risikomanagements. Meiner Meinung nach stellen die hier erläuterten Verfahren eine äußerst wertvolle Ergänzung Ihrer Tools für Tests, Entwicklung und Verwaltung von Software dar.
Metarisiken
Zwei besondere Aspekte der Softwareprojektrisikoanalyse bestehen in der Analyse der von mir so genannten Zeit- und Kostenmetarisiken. Im herkömmlichen Projektmanagement findet sich die Definition eines Konzepts, das verschiedene Namen hat und unter anderem als das „Triple Constraint im Projektmanagement“ oder das „Magische Dreieck im Projektmanagement“ bezeichnet wird. Die Idee ist, kurz gesagt, dass praktisch jedes Projekt drei begrenzende Faktoren hat: Kosten, Zeitplan und Umfang. Die Kosten bedeuten, wie viel Geld für das Projekt ausgegeben werden darf. Der Zeitplan besagt, in welchem Zeitraum das Projekt abgeschlossen werden muss, und der Umfang bezieht sich auf alle erforderlichen Projektfeatures und deren Qualität.
Für diese drei Projekteinschränkungen gibt es eine Reihe anderer Bezeichnungen. Zum Beispiel werden die Kosten auch als Budget oder Geldaufwand bezeichnet. Der Zeitplan wird oft auch Zeit oder Länge genannt. Der Umfang wird manchmal Features oder Qualität oder auch Features/Qualität genannt. Beachten Sie, dass letztere Einschränkung (Features/Qualität) als zwei unterschiedliche Einschränkungen angesehen werden kann (was oft auch der Fall ist).
Wichtig dabei ist die Auffassung, dass eine Änderung einer dieser Einschränkungen wahrscheinlich eine Änderung in einer anderen Einschränkung oder in den beiden anderen Einschränkungen bewirkt. Wenn Sie zum Beispiel eine Softwareanwendung entwickeln und das Projekt plötzlich in einem kürzeren Zeitraum als ursprünglich geplant abgeschlossen werden muss, müssen Sie wahrscheinlich mehr Geld ausgeben (zum Beispiel, um zusätzliche Ressourcen zu erwerben oder um einen Teil des Projekts auszulagern) oder Kürzungen in den Bereichen Features oder Qualität vornehmen. Wenn das Budget für Ihr Projekt gekürzt wurde, müssen Sie wahrscheinlich die Zeitvorgabe für den Projektabschluss erweitern, einige Features entfernen oder die Qualität des Projekts niedriger ansetzen. Da das Softwaretesten entworfen wurde, um die Qualität eines Systems zu verbessern, folgt daraus, dass beim Verwenden des Modells des magischen Projektmanagementdreiecks die zwei höchsten Risikoebenen in einem Softwareprojekt darin bestehen, dass das Projekt nicht pünktlich fertiggestellt und dass das vorgegebene Budget nicht eingehalten wird.
Es gibt eine relativ einfache aber effektive Möglichkeit, die Gesamtrisiken für den Zeitplan und die Kosten eines Softwareprojekts einzuschätzen. Als Nächstes soll nur das Metarisiko Zeit/Zeitplan untersucht werden (die Analyse des Risikos Budget/Kosten erfolgt auf die gleiche Weise). Der erste Schritt in einer grundlegenden Metarisikoanalyse besteht darin, das Gesamtprojekt in kleinere, besser überschaubare Abschnitte von Aktivitäten zu unterteilen.
Angenommen, Sie bearbeiten ein kleines Webanwendungsprojekt, das in 30 Arbeitstagen abgeschlossen sein muss. Für die Metarisikoanalyse listen Sie zunächst alle Aktivitäten auf, die das Projekt umfasst. In der Regel wird hierbei ein so genannter Projektstrukturplan erstellt (siehe Abbildung 2). Sie erstellen eine Aufgabe der obersten Ebene, die aus dem gesamten Projekt besteht. Dann unterteilen Sie diese Aufgabe in einige kleinere Unteraufgaben, normalerweise etwa drei bis sieben Aufgaben. Sie wiederholen den Prozess und unterteilen jede Unteraufgabe in kleinere Unteraufgaben, bis der für Ihre Umgebung angemessene Grad an Granularität erreicht ist.
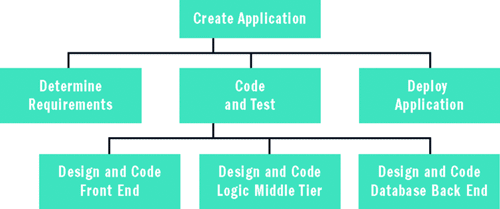
Abbildung 2 Projektstrukturplan
Die unterste Ebene, die Aufgaben von untergeordneten Knoten, werden manchmal auch Arbeitspakete genannt. Wie Sie die Aufgaben im Einzelnen unterteilen und wie granular Sie den Projektstrukturplan gestalten, hängt von einer Reihe von Faktoren ab. In einer agilen Entwicklungsumgebung ist es beispielsweise möglich, dass ein einfacher Projektstrukturplan mit zwei Ebenen Ihre Anforderungen erfüllt. Wenn Sie ein sehr großes komplexes Softwareprojekt bearbeiten und dabei eine traditionelle Softwareentwicklungs-Lebenszyklusmethodik verwenden, können Zehntausende von Arbeitspaketen vorhanden sein.
Sie können einen kleinen Projektstrukturplan manuell anhand generischer Produktivitätstools wie Microsoft Office Excel erstellen, oder aber hochentwickelte Tools wie Microsoft Office Project verwenden. Ein Projektstrukturplan enthält keine Sequenzierungs-, Zeit- oder Kosteninformationen. Anders gesagt, ein Projektstrukturplan umfasst Informationen zu den Aufgaben, die durchgeführt werden müssen, aber nicht zur jeweiligen Reihenfolge. Außerdem sind keine Daten zur Zeitdauer oder zu den Kosten der Aufgaben enthalten. Nach dem Erstellen des Projektstrukturplans besteht der nächste Schritt in der Regel darin, anhand der Arbeitspakete einen so genannten Rangfolgeplan zu erstellen.

Abbildung 3 Rangfolgeplan
Der Rangfolgeplan enthält Sequenzierungsinformationen. Der in Abbildung 3 dargestellte Plan zeigt an, dass die Anforderungsaufgabe vor der Datenbank-Back-End-Aufgabe abgeschlossen werden muss, die wiederum abgeschlossen sein muss, bevor die Aufgaben der mittleren Ebene und des Front-End beginnen können. Diese letzten beiden Aufgaben können entsprechend dem Rangfolgeplan parallel durchgeführt werden. Abschließend müssen sowohl die Aufgabe der mittleren Ebene als auch die Front-End-Aufgabe abgeschlossen werden, bevor die Anwendungsbereitstellungsaufgabe beginnen kann.
Nach dem Erstellen eines Rangfolgeplans mit den Sequenzierungsinformationen besteht der nächste Schritt in einer Zeitmetarisikoanalyse in der Schätzung der für jedes einzelne Arbeitspaket erforderlichen Zeit. Jede Zeiteinschätzung kann zwar als einzelner Datenpunkt angegeben werden, aber es empfiehlt sich ein Ansatz mit jeweils drei Schätzungen: eine optimistische Schätzung, eine bestmögliche Schätzung und eine pessimistische Schätzung.
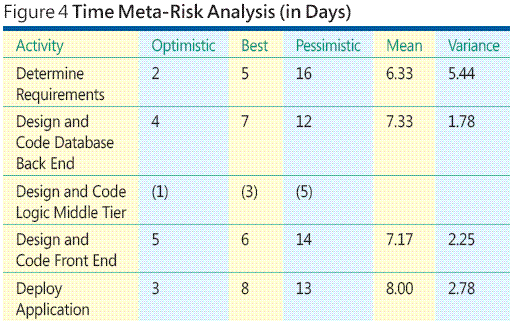
Aber woher stammen solche Schätzungen? Zeit- und Kostenschätzungen stellen bei Weitem den schwierigsten Teil bei der Analyse der Softwareprojektmetarisiken dar. Es gibt viele Möglichkeiten, die Zeit und Kosten einer Aktivität zu schätzen. Sie können frühere Erfahrungen, fundierte Vermutungen, hochentwickelte Berechnungsmodelle und so weiter verwenden. Die von Ihnen eingesetzten Verfahren hängen immer von der jeweiligen Situation ab. Unabhängig von der verwendeten Methode ist die Zeit- und Kostenschätzung für einen Satz kleinerer Aktivitäten viel einfacher als die Zeit- und Kostenschätzung einer monolithischen Aktivität. Die Tabelle in Abbildung 4 zeigt ein Beispiel für eine Zeitmetarisikoanalyse.
Bei einer optimistischen, bestmöglichen und pessimistischen Zeitdatenanalyse wird in der Regel eine einfache mathematische Verteilung namens „Beta-Verteilung“ verwendet. Der mittlere oder durchschnittliche Wert einer Beta-Verteilung wird folgendermaßen berechnet:
(optimistic + (4 * best-guess) + pessimistic) / 6
Das heißt, die durchschnittliche geschätzte Zeit für den Abschluss der Anwendungsbereitstellungsaufgabe beträgt:
mean = (3 + 4*8 + 13) / 6
= 48 / 6
= 8.0 days.
Beachten Sie, dass ein Beta-Durchschnittswert nur ein gewichteter Durchschnitt mit den Gewichtungen 1, 4 und 1 ist. Daher wird die Abweichung einer Beta-Verteilung durch diese Formel dargestellt:
((pessimistic - optimistic)/6)²
Für die Anwendungsbereitstellungsaufgabe beträgt die Abweichung folglich:
variance = ((13 - 3) / 6)²
= (10/6)²
= (1.6667)²
= 2.78 days²
Die Gesamtstandardabweichung für das Projekt ist die Quadratwurzel der Summe der Aktivitätsabweichungen. Somit sieht in diesem Beispiel die Gleichung folgendermaßen aus:
std. deviation = sqrt(5.44 + 1.78 + 2.25 + 2.78)
= sqrt(12.25)
= 3.50 days
Beachten Sie, dass in diesen Berechnungen die Daten für die Aktivität „Design and Code Logic Middle Tier“ nicht verwendet werden. Weil die Aktivität „Logic Middle Tier“ parallel mit der Datenbank-Back-End-Aktivität durchgeführt werden kann und die Front-End-Aktivität erst dann beginnen kann, wenn die beiden parallelen Aktivitäten beendet wurden, trägt die kürzere parallele Aktivität (Logic Middle Tier) nicht explizit zur Gesamtzeit für den Projektabschluss bei.
Diese Art der Analyse wird als die Methode des kritischen Pfads (Critical Path Method, CPM) bezeichnet und ist ein Standardprojektmanagementverfahren. Mit den berechneten Durchschnitts- und Abweichungsdaten können Sie jetzt die Wahrscheinlichkeit berechnen, dass der Abschluss des gesamten Projekts länger als 30 Tage dauern wird:
z = (30.00 - 28.83) / 3.50 = 0.33
p(0.33) = 0.6293
p(late) = 1.0000 - 0.6293 = 0.3707
Zuerst berechnen Sie den so genannten Z-Wert, der der Zeitdauer entspricht, die Sie für den Projektabschluss geplant haben (in diesem Fall 30 Tage), und ziehen davon die geschätzte Zeit bis zum Abschluss (28,83 Tage) ab, geteilt durch die Standardabweichung der gesamten Aufgabe (3,50 Tage). Dann suchen Sie mit dem Z-Wert (0,33) den entsprechenden P-Wert in einer Standardverteilungstabelle oder verwenden die Excel-Funktion NORMSDIST (0,6293). Abschließend subtrahieren Sie den P-Wert von 1,0000, um die Wahrscheinlichkeit zu berechnen, ob das Projekt den Zeitplan überschreiten wird.
Sie führen an dieser Stelle eine einseitige Analyse durch, weil es nur von Interesse ist, ob das Projekt länger als geplant dauert. Mit diesen Beispieldaten ist die Wahrscheinlichkeit, dass die Fertigstellung der Webanwendung mehr als 30 Tage erfordert, 0,3707 bzw. fast 40 % – eine ziemlich riskante Situation. Wenn Sie alle Faktoren bedenken, ist dieses Ergebnis recht logisch. Der geplante Zeitplan von 26 Tagen für die Entwicklung schließt zu eng an die Projektbeschränkung von 30 Tagen an, sodass Sie möglicherweise nicht genug Spielraum haben, um Zeitplanabweichungen zu berücksichtigen.
Natürlich sind die Metarisikoergebnisse nur so gut wie die Eingabedaten, d. h. in diesem Fall Ihre Zeiteinschätzungen. Wenn die eingegebenen Schätzungen falsch sind, kann die statistische Analyse keine aussagekräftigen Ergebnisse erzielen. Sie können die Metarisikowahrscheinlichkeit dafür, dass das Projekt über das geplante Budget hinausgehen wird, mit dem gleichen Verfahren berechnen, das oben für den Zeitplan beschrieben wurde. Wenn die Wahrscheinlichkeitsdaten vorliegen, dass Ihr Projekt den Zeitplan überschreiten wird, können Sie das Risikopotenzial für das Metarisiko berechnen, wenn Sie den finanziellen Verlust aufgrund der zeitlichen Verzögerung schätzen können.
Möglicherweise stehen Sie unter Vertrag, ein Softwaresystem zu erstellen, und der Vertrag enthält klar definierte und erhebliche Strafen im Fall von Verzögerungen. Angenommen, der Vertrag enthält die Klausel, dass bei einer verspäteten Bereitstellung eine Zahlung von 10.000 $ fällig wird. Ihr Metarisikopotenzial beträgt 10.000 $ * 0,3707 = 3.707 $. In manchen Fällen ist die Kosteneinschätzung für ein aktuelles Softwareprojekt zu schwierig und geht nicht über „sehr, sehr teuer“ hinaus.
Beachten Sie aber, dass die Zeitmetarisikoanalyse auch ohne ein Risikopotenzial nützliche Informationen bietet. Bei näherer Untersuchung der Daten in Abbildung 4 wird ersichtlich, dass die Aufgabe zur Anforderungsermittlung die größte Abweichung vom Zeitplan aufweist. Daher können Sie die Aufgabenabweichung verringern, wenn Sie schon frühzeitig im Projekt zusätzliche Ressourcen einsetzen, was wiederum die Wahrscheinlichkeit der Zeitplanüberschreitung vermindert.
Risikoerkennung
Im Unterschied zu Zeit- und Kostenmetarisiken, bei denen die Risikoereignisse schrittweise (wenn auch keineswegs leicht) bestimmt werden können, indem die Aufgaben iterativ in kleinere Unteraufgaben unterteilt werden, geht die Erkennung der Risiken im Allgemeinen nicht so mechanisch vor sich. In einer Umgebung, in der Software entwickelt und getestet wird, gibt es hauptsächlich drei Verfahren zum Erkennen von Risiken: das taxonomiebasierte, das szenariobasierte und das spezifikationsbasierte Verfahren.
Eine Taxonomie ist lediglich eine Klassifizierungsliste. Ziehen Sie die folgende Analogie in Betracht. Sie planen eine Flugreise, also verwenden Sie, wie vor jeder Reise, eine Standarderinnerungsliste. Die Liste enthält Anweisungen oder Fragen, z. B. „Ausweis?“ und „Nachgeprüft, ob mein Flug pünktlich ist?“.
Im Lauf der Jahre wurden von Einzelpersonen und Organisationen eine ganze Reihe von Softwarerisikotaxonomien erstellt. Eine solche Liste wurde von Barry Boehm erstellt, einem der ersten Pioniere und einem bekannten Forscher im Bereich Softwareprojektrisiken. 1989 ermittelte Boehm eine Top-10-Softwarerisikotaxonomie. Er aktualisierte die Liste im Jahr 1995. Die Version der Top-10-Softwareprojektrisikotaxonomie von 1995 ist hier aufgeführt:
- Personaldefizite
- Zeitpläne, Budgets, Prozess
- Kommerziell vorrätige Software, externe Komponenten
- Fehlanpassung von Anforderungen
- Fehlanpassung der Benutzeroberfläche
- Architektur, Leistung, Qualität
- Änderungen der Qualitätsanforderungen
- Legacysoftware
- Extern durchgeführte Aufgaben
- Fehleinschätzung des Stands der Technik
Es ist Ihnen vermutlich klar, dass mit der Top-10-Risikoliste von Boehm Risiken nicht sofort erkannt werden. Die Taxonomie bietet Ihnen lediglich einen Anfangspunkt, an dem Sie Überlegungen zu Risiken anstellen und diese auf Ihr Softwareprojekt anwenden können. Zum Beispiel umfasst das erste Risiko „Personaldefizite“ viele verschiedene mögliche Risiken in Bezug auf die Mitarbeiter an einem Projekt. Möglicherweise steht für Ihr Projekt keine ausreichende Anzahl von Entwicklern zur Verfügung, um die Anwendung oder das System zu erstellen. Beispielsweise fällt ein wichtiger Entwickler mitten im Projekt aus. Die Mitarbeiter in der Entwicklung verfügen vielleicht nicht über die technischen Fähigkeiten, die für das Projekt erforderlich sind. Es gibt noch viele weitere Beispiele.
Die meisten der Top-10-Risikokategorien dürften Ihnen vertraut sein, außer vielleicht der 10. Risikokategorie „Fehleinschätzung des Stands der Technik“. Das ist sozusagen eine allumfassende Kategorie und deckt beispielsweise Aufgaben in Bezug auf die technische Analyse, die Kosten-Nutzen-Analyse und das Erstellen von Prototypen ab.
Eine andere allgemein gebräuchliche Liste für die Softwarerisikotaxonomie wurde vom Software Engineering Institute (SEI) erstellt. Das SEI ist eines von 36 staatlich geförderten Forschungs- und Entwicklungszentren in den USA. Diese Forschungszentren sind recht eigenartige Hybridorganisationen, die durch öffentliche Gelder finanziert werden, aber Produkte und Dienstleistungen verkaufen. Die SEI-Softwarerisikotaxonomie wurde 1993 erstellt und besteht aus ungefähr 200 Fragen. Frage Nr. 1 lautet zum Beispiel: „Sind die Anforderungen stabil? Wenn nein, welche Auswirkung hat dies auf das System (Qualität, Funktionalität, Zeitplan, Integration, Entwurf, Tests)?“ Frage Nr. 16 lautet: „Wie wird die Durchführbarkeit von Algorithmen und Entwürfen (Erstellen von Prototypen, Modellierung, Analyse, Simulation) bestimmt?“ Sie finden die SEI-Risikotaxonomie in einem Anhang zum Dokument.
Bei der szenariobasierten Erkennung von Softwarerisiken versetzen Sie sich in verschiedene Rollen, erstellen Szenarios für diese Rollen und legen fest, was in jedem Szenario schief gehen könnte. Ähnlich wie in der weiter oben beschriebenen Analogie mit der Flugreise können Sie die Schritte gedanklich nachverfolgen, die Sie auf der Reise unternehmen. Zum Beispiel: „Zuerst fahre ich zum Flughafen. Dann parke ich mein Auto. Als Nächstes checke ich am Schalter der Fluggesellschaft ein.“ Dieser Szenarioprozess könnte viele Risiken aufdecken, einschließlich Verspätungen aufgrund von Straßenarbeiten oder eines Verkehrsunfalls, aufgrund nicht vorhandener Parkplätze oder eines vergessenen Ausweises und so weiter.
In einer Softwareprojektumgebung gehören Benutzer, Entwickler, Tester, Vertriebsmitarbeiter, Softwarearchitekten und Projektmanager zu den allgemeinen Rollen, die für die szenariobasierte Risikoerkennung verwendet werden. Ein Benutzerszenario könnte etwa wie folgt lauten: „Zuerst installiere ich die Anwendung. Als Nächstes starte ich die Anwendung.“ In vielen Fällen wird ein Risikoerkennungsszenario direkt einem Testfall zugeordnet.
Bei szenariobasierten Risikoerkennungsrollen handelt es sich nicht unbedingt um Personen. Rollen können auch von Softwaremodulen oder Subsystemen eingenommen werden. Angenommen, es liegt Ihnen ein C#-Objekt vor, das zur Verschlüsselung und Entschlüsselung dient. Sie können sich vorstellen, dass das Objekt die Rolle darstellt und erstellen Szenarios, wie z. B. „Zuerst akzeptiere ich eine Eingabe und instanziiere mich selbst. Anschließend akzeptiere ich eine Eingabe und leite sie an meine Verschlüsselungsmethode weiter.“ Zur szenariobasierten Erkennung von Softwarerisiken ist weniger Forschungsmaterial vorhanden als zur taxonomiebasierten Erkennung. Die wissenschaftliche Abhandlung unter Muster zur Risikoerkennung in Softwareprojekten bietet einen guten Überblick über das Gebiet und enthält einen interessanten, theoretischen, musterbasierten Ansatz für die Risikoerkennung.
Zu den taxonomie- und szenariobasierten Strategien zur Risikoerkennung kommt ein dritter Ansatz hinzu: die spezifikationsbasierte Strategie. In diesem Ansatz untersuchen Sie im Einzelnen jedes Feature und jeden Prozess in Ihren Dokumenten zur Produkt- oder Systemspezifikation und versuchen herauszufinden, welche Fehler möglicherweise auftreten könnten. Anhand der Analogie der Flugreise können Sie gegebenenfalls eine ausführliche Reiseroute untersuchen, die von einem Reisebüro für Sie erstellt wurde. Stellen Sie sich vor, dass eins Ihrer Spezifikationsdokumente für eine Webanwendung angibt, dass Sie beabsichtigen, die verschiedenen Hilfedateien für die Anwendung von einem externen Auftragnehmer erstellen zu lassen. Eine externe Projektabhängigkeit kann zu vielen verschiedenen Risiken führen. Was ist, wenn der Auftragnehmer nicht pünktlich liefert? Was ist, wenn die Arbeitsqualität des Auftragnehmers Ihren subjektiven Standards nicht gerecht wird?
Es gibt keine einzelne, optimale Risikoerkennungsstrategie, denn jede Strategie hat sowohl Vorteile als auch Nachteile. Risikotaxonomien sind eine hervorragende Möglichkeit, um den Prozess der Risikoerkennung in einem Softwareprojekt auf den Weg zu bringen. Zu Anfang ist die Vorgehensweise recht mechanisch, da Sie einfach nach und nach jede Frage oder Anweisung in der Taxonomie untersuchen. Taxonomien helfen außerdem, den Risikoerkennungsprozess auf mehrere Personen aufzuteilen, indem verschiedenen Personen verschiedene Taxonomiefragen zugewiesen werden. Ein Nachteil ist, dass die Verwendung von Taxonomien für die Risikoerkennung sehr zeitaufwändig sein kann. Außerdem sind Taxonomien naturgemäß generisch, sodass softwaresystemspezifische Risiken nur erkannt werden können, wenn Sie sich speziell um das Aufdecken dieser spezifischen Risiken bemühen.
Im Vergleich zur taxonomiebasierten Risikoerkennung hat der szenariobasierte Ansatz den Vorteil, dass er tendenziell nicht so generisch ist und Sie von Anfang an dazu zwingt, eindeutigere Angaben zu machen. Andererseits ist die szenariobasierte Risikoerkennung eher eine Kunst als eine Wissenschaft, und ein wichtiges Szenario kann leicht übersehen werden. Die spezifikationsbasierte Risikoerkennung ist in der Regel der am wenigsten generische und der spezifischste Ansatz. Ein spezifikationsbasierter Ansatz erzielt jedoch nur gute Ergebnisse, wenn Ihre Spezifikationsdokumente qualitativ gut sind. Wenn alle drei Ansätze gemeinsam verwendet werden, bieten sie eine gute Möglichkeit für eine korrekte Erkennung von Softwarerisiken.
Risikoanalyse
Die Risikoanalyse ist der Prozess, bei dem die Wahrscheinlichkeit eines Risikoereignisses mit dem finanziellen Verlust (oder der negativen Auswirkung) kombiniert wird, der beim Eintreten des Ereignisses stattfindet, um einen Wert zu erhalten, der für einen Vergleich und eine Priorisierung des Risikos gegenüber anderen Risiken verwendet werden kann. Im folgenden Abschnitt werden zwei ältere Ansätze für die Risikoanalyse (das Erwartungswertverfahren und das kategorische Verfahren) und ein neuer Ansatz namens PERIL vorgestellt. Zunächst geht es um das Erwartungswertverfahren.
Betrachten Sie das Beispiel in Abbildung 5. Angenommen, Sie haben vier Risikoereignisse erkannt. Sie sollen im Folgenden Risiko A, Risiko B, Risiko C und Risiko D genannt werden. Sie weisen jedem Risikoereignis Wahrscheinlichkeiten zu. Eine Wahrscheinlichkeit ist eine Zahl zwischen 0,00 (d. h. unmöglich) und 1,00 (d. h. mit Sicherheit), die anzeigt, mit welcher Wahrscheinlich das Ereignis eintreten wird. Als Nächstes weisen Sie jedem Risikoereignis einen finanziellen Verlustwert zu, der die Kosten darstellt, die Ihnen beim Eintreten des Risikoereignisses entstehen. Jetzt multiplizieren Sie für jedes Risikoereignis einfach die Risikowahrscheinlichkeit mit dem Risikoverlust, um das Risikopotenzial zu erhalten.
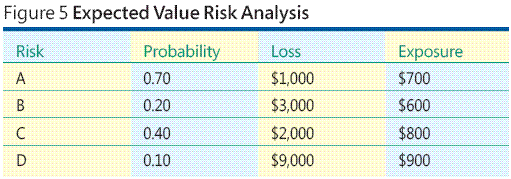
Bei dieser Methode ist das Risikopotenzial nur eine Art Erwartungswert. Offensichtlich gibt es einige größere Probleme beim Erwartungswertansatz. Wie können Risikowahrscheinlichkeiten geschätzt werden? Wie können Sie einen Risikoverlust schätzen? In einigen Situationen stehen Ihnen vielleicht gute Verlaufsdaten oder Erfahrungswerte zur Verfügung, auf denen Sie Ihre Schätzungen basieren können, aber im Allgemeinen kommt dies beim Erstellen von Software selten vor. Aufgrund meiner Erfahrung ist der Erwartungswertansatz bei der Risikoanalyse in einer Softwareentwicklungsumgebung oft nicht durchführbar.
Weil es in solchen Umgebungen schwierig oder gar unmöglich ist, die Wahrscheinlichkeit eines Risikoereignisses oder des zugeordneten Verlusts zu schätzen, besteht die Alternative häufig darin, sowohl für die Risikowahrscheinlichkeit als auch für den Risikoverlust kategorische Maßstäbe zu verwenden. Dabei handelt es sich um das kategorische Verfahren. Der Gedanke dahinter wird durch folgendes Beispiel verdeutlicht. Angenommen, Sie haben vier Risiken erkannt: Risiko A, Risiko B, Risiko C und Risiko D. Anstatt jetzt die Wahrscheinlichkeit und einen Verlust für jedes Risiko zu schätzen, generieren Sie eine Tabelle für das kategorische Risikopotenzial (siehe Abbildung 6 ganz oben).
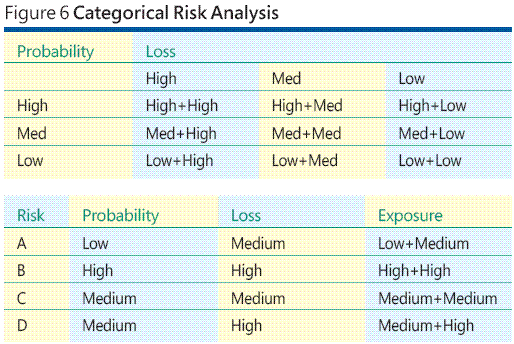
Wie Sie sehen können, gibt es insgesamt neun Kategorien für das Risikopotenzial. Es gibt drei Kategorien für die Risikowahrscheinlichkeit: gering, mittel und hoch. Es gibt drei Kategorien für den Verlust: gering, mittel und hoch. Das Kreuzprodukt der Wahrscheinlichkeits- und der Verlustkategorie ergibt neun Kategorien für das Risikopotenzial, sehr gering (geringe Wahrscheinlichkeit eines geringen Verlusts) bis sehr hoch (hohe Wahrscheinlichkeit eines hohen Verlusts). Jetzt kann jedem der vier Risikoereignisse eine geringe, mittlere oder hohe Wahrscheinlichkeit und anschließend ein geringer, mittlerer und hoher Verlust zugewiesen werden, um ein neunstufiges Risikopotenzial zu erhalten. Dahinter steht der Gedanke, dass es oft vernünftiger ist, einen Wahrscheinlichkeitswert von „Gering“ zuzuweisen statt eines genauen numerischen Werts, zum Beispiel 0,05.
Die hypothetischen Daten in der Tabelle im unteren Teil von Abbildung 6 deuten an, dass das Risiko B das höchste Risikopotenzial hat und eventuell mehr Aufmerksamkeit oder Ressourcen (einschließlich Tests) erfordert als Risiko A, das das geringste Risikopotenzial aufweist. Obwohl der Ansatz der kategorischen Risikoanalyse das Problem der Zuweisung von Wahrscheinlichkeiten und Verlustinformationen, deren Zuweisung schwierig oder unmöglich ist, etwas vereinfacht, entstehen bei diesem Ansatz neue Probleme.
Beachten Sie, dass ich willkürlich drei Kategorien sowohl für die Wahrscheinlichkeit als auch den Verlust verwende. Dies ist ein sehr grober Ansatz. Aber angenommen, Sie beschließen, die Risikoanalyse anhand der folgenden fünf Kategorien sowohl für den Wahrscheinlichkeitsfaktor als auch den Verlustfaktor zu verbessern: sehr gering, gering, mittel, hoch und sehr hoch. Jetzt ergeben sich insgesamt 25 Kategorien für das Risikopotenzial: (sehr gering + sehr gering) bis (sehr hoch + sehr hoch). Wie würden Sie diese 25 Risikopotenziale einstufen oder vergleichen? Wie lässt sich ein (sehr geringes + hohes) Risikopotenzial mit einem (hohen + mittleren) Risikopotenzial vergleichen? Wenn mehrere Personen Ihre Daten zum kategorischen Risikopotenzial evaluieren, würden sie die Daten auf die gleiche Art interpretieren?
Um die Probleme eines rein kategorischen Ansatzes der Risikoanalyse zu behandeln, habe ich vor einigen Jahren ein Verfahren namens „Project Exposure using Ranked Impact and Likelihood“ (PERIL) entwickelt. Im Kern geht es darum, Kategorien zu verwenden (wie im kategorischen Ansatz), sie aber in einen quantitativen Maßstab zu konvertieren, damit sie problemlos kombiniert werden können (wie beim Erwartungswertansatz), um numerische Metriken für das Risikopotenzial zu erhalten.
Hier folgt ein Beispiel dazu. Angenommen, Sie haben vier Risiken erkannt. A, B, C und D. Jetzt entscheiden Sie, dass der Versuch, den einzelnen Risikowahrscheinlichkeiten und -verlusten numerische Werte zuzuweisen, einfach nicht durchführbar ist. Außerdem entscheiden Sie, dass es in Ihrer jeweiligen Umgebung logisch ist, die Risikowahrscheinlichkeit in fünf Kategorien einzuteilen: sehr gering, gering, mittel, hoch und sehr hoch. Anschließend bestimmen Sie, dass „Verlust/Auswirkungen“ in einem vierstufigen Maßstab kategorisiert werden soll: sehr gering, gering, hoch und sehr hoch. Durch das PERIL-Verfahren werden die kategorischen Daten mit einem einfachen mathematischen Konstrukt, den so genannten Rangordnungsmittelwerten einem quantitativen Maßstab zugeordnet. Das Zuordnungsverfahren wird am besten durch ein Beispiel veranschaulicht. Für den aus fünf Kategorien bestehenden Wahrscheinlichkeitsmaßstab werden in Abbildung 7 die fünf Zuordnungen für die Rangordnungsmittelwerte gezeigt.
Ähnlich werden die aus vier Kategorien bestehenden Auswirkungszuordnungen berechnet (siehe Abbildung 8). Jetzt kann die Wahrscheinlichkeit jedes Risikos mit dem Auswirkungsmittelwert kombiniert werden, um das Risikopotenzial durch eine Multiplikation zu berechnen. Betrachten Sie zum Beispiel Abbildung 9. Hier hat Risiko D eine hohe Wahrscheinlichkeit, die bei 0,25667 liegt, und eine geringe Auswirkung, die bei 0,14583 liegt. Deshalb ist das Risikopotenzial 0,25667 * 0,14583 = 0,03743. Aufgrund dieser Daten ist darauf zu schließen, dass Risiko C eindeutig das höchste Risikopotenzial aufweist. Daher sollten Sie Maßnahmen ergreifen, um das Eintreten des Risikos zu verhindern, und einen Alternativplan erstellen, falls das Risikoereignis doch eintritt.
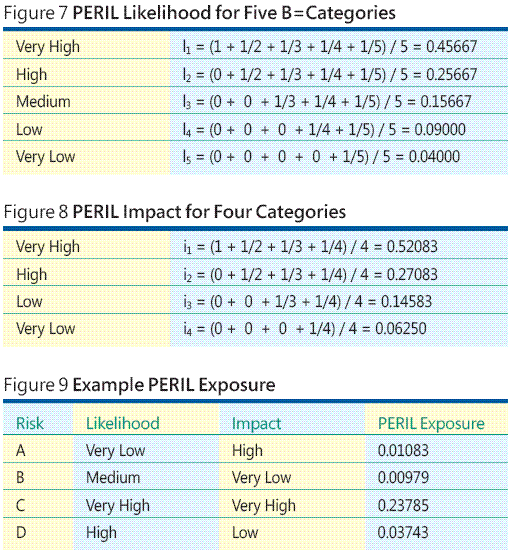
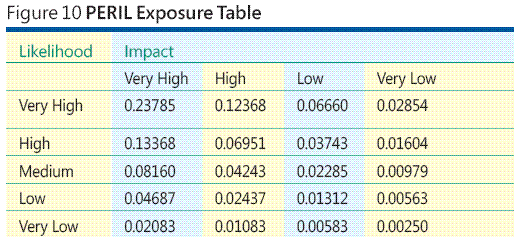
Statt das Risikopotenzial für jedes Risiko einzeln zu berechnen, können Sie eine vollständige PERIL-Risikopotenzialtabelle für fünf Wahrscheinlichkeitsebenen und vier Auswirkungsebenen erstellen und dann die PERIL-Risikopotenzialwerte von der Tabelle ablesen (siehe Abbildung 10). Das PERIL-Verfahren kann auf beliebig viele Wahrscheinlichkeits- und Auswirkungskategorien verallgemeinert werden.
Rangordnungsmittelwerte ordnen Rangordnungen (z. B. erste, zweite, dritte) numerische Werte zu (z. B. 0,61111, 0,27778, 0,11111). Beachten Sie, dass Rangordnungsmittelwerte in dem Sinn normalisiert werden, dass sie die Summe 1,0 ergeben (unter Vorbehalt von Rundungsfehlern). In der Sigma-Schreibweise ausgedrückt: Wenn N für die Anzahl der Kategorien steht, dann lautet der numerische Wert, der der k-ten Kategorie entspricht:
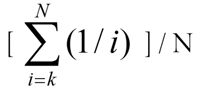
Es gibt viele weitere mathematische Zuordnungen zwischen Kategorien und numerischen Werten, aber aus bestimmten Forschungsarbeiten geht hervor, dass die Verwendung von Rangordnungsmittelwerten eine sehr gute Möglichkeit für die Zuordnung der beispielsweise in der Risikoanalyse verwendeten Rangordnungen darstellt. Eine vollständige Besprechung der Rangordnungsmittelwerte geht leider über den Rahmen dieses Artikels hinaus. Betrachten Sie aber dieses informelle Argument. Angenommen, es liegen Ihnen nur zwei Kategorien der Risikoereigniswahrscheinlichkeit vor: hoch und gering. Vermutlich hat die Ereigniswahrscheinlichkeit mit dem hohen Risikopotenzial eine Ereigniswahrscheinlichkeit von über 0,5, und deshalb hat die Ereigniswahrscheinlichkeit mit dem geringen Risikopotenzial eine Wahrscheinlichkeit von weniger als 0,5. Ohne zusätzliche Informationen können Sie annehmen, dass die hohe Ereigniswahrscheinlichkeit in der Mitte zwischen 0,5 und 1,0 liegt und deshalb 0,75 entspricht. Gleichermaßen liegt die geringe Ereigniswahrscheinlichkeit in der Mitte zwischen 0,0 und 0,5, was 0,25 entspricht. Diese beiden Werte, 0,75 und 0,25, sind Rangordnungsmittelwerte für N = 2 Kategorien (siehe Abbildung 11).
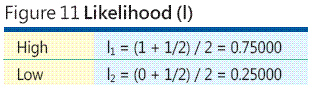
Beachten Sie, dass ich bei PERIL die Begriffe Wahrscheinlichkeit und Auswirkung anstatt Wahrscheinlichkeit und Verlust verwende. PERIL-Wahrscheinlichkeit und -Auswirkung sind relative, normalisierte Werte. Obwohl die PERIL-Wahrscheinlichkeitswerte, so wie ein Wahrscheinlichkeitssatz, eine Summe von 1,0 ergeben, muss betont werden, dass es sich bei den PERIL-Wahrscheinlichkeitswerten nicht um Wahrscheinlichkeiten handelt. Ähnlich haben die PERIL-Auswirkungswerte nur dann eine Bedeutung, wenn sie miteinander verglichen werden und keine finanziellen Verlustwerte darstellen.
Die drei Verfahren zum Bestimmen des Risikopotenzials – das Erwartungswertverfahren, das kategorische Verfahren und das PERIL-Verfahren – haben ihre Vor- und Nachteile. Wenn Ihnen stabile Verlaufsdaten vorliegen, die es ermöglichen, die Wahrscheinlichkeiten von Risikoereignissen und den finanziellen Verlust zu schätzen, die mit jedem Ereignis verbunden sind, dann ist das Erwartungswertverfahren meist der beste Ansatz. In einer Umgebung zum Entwickeln und Testen von Software stehen jedoch selten ausreichend Daten für aussagekräftige Wahrscheinlichkeits- und Verlustschätzungen zur Verfügung.
Wenn Ihnen andererseits praktisch keine Verlaufsrisikodaten vorliegen, dann stellt das kategorische Verfahren, mit zwei oder drei Kategorien der Risikowahrscheinlichkeit und dem damit verbundenen Risikoverlust, einen vernünftigen Ansatz dar. In Situationen, in denen Sie die Risikoereignis-Wahrscheinlichkeit und die damit verbundene Risikoauswirkung (die ein finanzieller Verlust sein kann oder nichts mit Geld zu tun haben muss, z. B. Arbeitsmoral) in etwa fünf Kategorien einteilen können, ist das PERIL-Verfahren oft eine hervorragende Wahl.
Unabhängig davon, welches Risikoanalyseverfahren Sie in Ihrer Umgebung verwenden möchten, müssen Sie die Ergebnisse sorgfältig interpretieren. Bedenken Sie, dass die Risikoanalyse fast immer große Schwankungen bei den Eingabeschätzungen aufweist. Mit anderen Worten, die Risikoanalyse stellt Ihnen Richtlinien, aber keine Regeln bereit, mit denen Sie die Prioritäten für Softwaretests setzen können.
Risikoressourcen
Weitere Informationen zum Thema Risiko erhalten Sie in den folgenden Artikeln im MSDN Magazin:
| "Testlauf: Wettbewerbsanalyse mit MAGIQ" |
| "Testlauf: Der analytische Hierarchieprozess" |
Zusammenfassung
Ein Teil des Gesamtprozesses der Risikoanalyse, der in diesem Artikel nicht behandelt wurde, ist das Risikomanagement. Risikomanagement erfordert Aktivitäten wie das Einrichten eines Systems für das Eingeben und Speichern von Risikodaten sowie das Überwachen der Risikoinformationen im Verlauf eines Softwareprojekts. Risikomanagementsysteme reichen von einem informellen System, das auf E-Mail-basiert, über einen einfachen Ansatz auf Grundlage von Excel-Tabellen, bis zu einem hochentwickelten Ansatz, der auf der Verwendung von Risikoelementen in einem Microsoft Team Foundation Server-System basiert.
Wichtig ist das Verständnis, dass die Risikoanalyse ein kontinuierlicher, iterativer Prozess sein muss, unabhängig davon, für welche Art des Risikomanagements Sie sich entscheiden. Da es sich bei der Softwareprojektentwicklung um eine sehr dynamische Aktivität handelt, müssen Sie die Risikodaten und Ergebnisse im Verlauf des Projekts überarbeiten.
Der gesunde Menschenverstand legt nahe, dass die Softwarerisikoanalyse in keinem Softwareprojekt fehlen darf. Alle Projekte, angefangen bei winzigen, von einem einzigen Entwickler in einer Woche bearbeiteten Projekten bis zu riesigen, mehrjährigen Projekten mit Hunderten oder gar Tausenden von Entwicklern, sollten eine Art von Risikoanalyse beinhalten. Zahlreiche Umfrageergebnisse belegen jedoch, dass Risikoanalysen oft nicht durchgeführt werden, vor allem bei mittelgroßen oder kleinen Softwareprojekten.
Dafür gibt es mehrere plausible Erklärungen. Ich vermute einen Grund dafür darin, dass für die Risikoanalyse Verfahren und Kompetenzen erforderlich sind, die fast das Gegenteil der Fähigkeiten und Kompetenzen darstellen, die für das Programmieren nötig sind. Dies lässt sich folgendermaßen erklären. Die meisten Aktivitäten beim Entwickeln von Software sind relativ klar definiert, basieren auf einem geschlossenen System, sind auf Mikroziele ausgerichtet und bieten meist unmittelbares Feedback. Wenn Sie zum Beispiel einen Code schreiben, können Sie sofort Feedback abrufen, wenn Sie den Code kompilieren und anschließend ausführen. Wenn der Code wie erwartet ausgeführt wird, sind Sie in der Regel einigermaßen zufrieden. Das Durchführen einer Softwarerisikoanalyse ist eine ganz andere Art von Aktivität. Dabei steht die von Ihnen gewohnte Art von Feedback oder Zufriedenheit nicht auf dem Plan.
Die Softwarerisikoanalyse unterscheidet sich also grundlegend vom Programmiervorgang. Hoffentlich wurden Sie durch diesen Artikel davon überzeugt, wie wichtig es ist, eine Risikoanalyse durchzuführen, und haben einige interessante Verfahren für das Erstellen besserer, zuverlässiger Software erhalten.
Senden Sie Ihre Fragen und Kommentare für James McCaffrey in englischer Sprache an testrun@microsoft.com.
Dr. James McCaffrey arbeitet für Volt Information Sciences Inc. und organisiert technische Schulungen für Softwareentwickler bei Microsoft in Redmond, Washington. Er hat an mehreren Microsoft-Produkten gearbeitet, darunter Internet Explorer und MSN-Suche, und ist Autor des Buchs .NET Test Automation: A Problem-Solution Approach (Apress, 2006). Sie erreichen ihn unter jmccaffrey@volt.com oder v-jammc@microsoft.com.