Strategien für die Datenpartitionierung (Erstellen Real-World Cloud-Apps mit Azure)
von Rick Anderson, Tom Dykstra
Download Fix It Project oder Download E-Book
Das E-Book Building Real World Cloud Apps with Azure basiert auf einer Präsentation, die von Scott Guthrie entwickelt wurde. Es werden 13 Muster und Methoden erläutert, die Ihnen bei der erfolgreichen Entwicklung von Web-Apps für die Cloud helfen können. Informationen zur Reihe finden Sie im ersten Kapitel.
Zuvor haben wir gesehen, wie einfach es ist, die Webebene einer Cloudanwendung durch Hinzufügen und Entfernen von Webservern zu skalieren. Wenn sie jedoch alle denselben Datenspeicher treffen, wechselt der Engpass Ihrer Anwendung vom Front-End zum Back-End, und die Datenebene ist am schwersten zu skalieren. In diesem Kapitel erfahren Sie, wie Sie Ihre Datenebene skalierbar machen können, indem Sie Daten in mehrere relationale Datenbanken partitionieren oder relationalen Datenbankspeicher mit anderen Datenspeicheroptionen kombinieren.
Das Einrichten eines Partitionierungsschemas erfolgt am besten im Voraus aus demselben Grund, der zuvor erwähnt wurde: Es ist sehr schwierig, Ihre Datenspeicherstrategie zu ändern, nachdem sich eine App in der Produktion befindet. Wenn Sie im Voraus über verschiedene Ansätze nachdenken, können Sie einen "Twitter-Moment" vermeiden, wenn Ihre App abstürzt oder für einen längeren Zeitraum ausfällt, während Sie die Daten und den Datenzugriffscode Ihrer App neu organisieren.
Die drei Vs-Datenspeicher
Um zu ermitteln, ob Sie eine Partitionierungsstrategie benötigen und was sie sein sollte, sollten Sie sich drei Fragen zu Ihren Daten stellen:
- Volume: Wie viele Daten werden letztendlich gespeichert? Ein paar Gigabyte? Ein paar hundert Gigabyte? Terabyte? Petabyte?
- Geschwindigkeit: Mit welcher Geschwindigkeit wachsen Ihre Daten? Handelt es sich um eine interne App, die nicht viele Daten generiert? Eine externe App, in die Kunden Bilder und Videos hochladen?
- Vielfalt– Welche Art von Daten werden gespeichert? Relationale, Bilder, Schlüssel-Wert-Paare, soziale Graphen?
Wenn Sie der Meinung sind, dass Sie viel Volumen, Geschwindigkeit oder Vielfalt haben werden, müssen Sie sorgfältig überlegen, welche Art von Partitionierungsschema es Ihrer App am besten ermöglicht, effizient und effektiv zu skalieren, wenn sie wächst, und um sicherzustellen, dass sie nicht zu Engpässen kommt.
Es gibt im Grunde drei Ansätze für die Partitionierung:
- Vertikale Partitionierung
- Horizontale Partitionierung
- Hybridpartitionierung
Vertikale Partitionierung
Die vertikale Portionierung ist wie das Aufteilen einer Tabelle nach Spalten: Eine Gruppe von Spalten geht in einen Datenspeicher ein, und eine andere Gruppe von Spalten geht in einen anderen Datenspeicher.
Angenommen, meine App speichert Daten zu Personen, einschließlich Bildern:
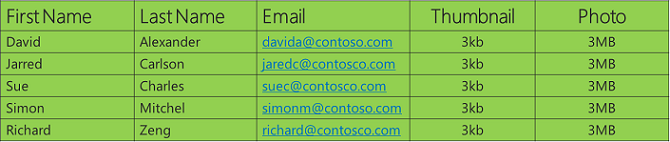
Wenn Sie diese Daten als Tabelle darstellen und die verschiedenen Arten von Daten betrachten, können Sie sehen, dass die drei Spalten auf der linken Seite Zeichenfolgendaten enthalten, die effizient von einer relationalen Datenbank gespeichert werden können, während die beiden Spalten auf der rechten Seite im Wesentlichen Bytearrays sind, die aus Bilddateien stammen. Es ist möglich, Bilddateidaten in einer relationalen Datenbank zu speichern, und viele Benutzer tun dies, weil sie die Daten nicht im Dateisystem speichern möchten. Möglicherweise verfügen sie nicht über ein Dateisystem, das die erforderlichen Datenvolumes speichern kann, oder sie möchten möglicherweise kein separates Sicherungs- und Wiederherstellungssystem verwalten. Dieser Ansatz eignet sich gut für lokale Datenbanken und für kleine Datenmengen in Clouddatenbanken. In der lokalen Umgebung kann es einfacher sein, den DBA einfach alles erledigen zu lassen.
In einer Clouddatenbank ist der Speicher jedoch relativ teuer, und eine große Anzahl von Images könnte dazu führen, dass die Größe der Datenbank über die Grenzen hinausgeht, mit denen sie effizient betrieben werden kann. Sie können diese Probleme beheben, indem Sie die Daten vertikal partitionieren. Dies bedeutet, dass Sie für jede Spalte in Ihrer Datentabelle den am besten geeigneten Datenspeicher auswählen. Für dieses Beispiel kann es am besten funktionieren, die Zeichenfolgendaten in einer relationalen Datenbank und die Bilder in Blob Storage zu platzieren.
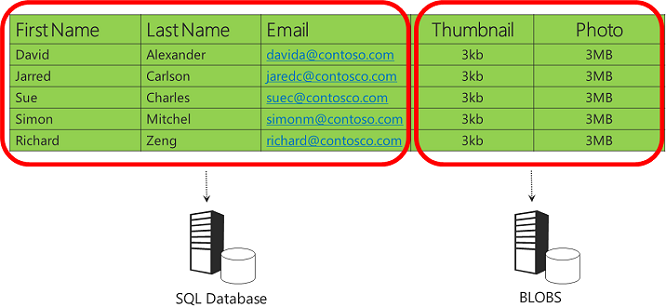
Das Speichern von Images im Blobspeicher anstelle einer Datenbank ist in der Cloud praktischer als in einer lokalen Umgebung, da Sie sich keine Gedanken über das Einrichten von Dateiservern oder das Verwalten der Sicherung und Wiederherstellung von Daten machen müssen, die außerhalb der relationalen Datenbank gespeichert sind. All dies wird automatisch vom Blob Storage-Dienst verarbeitet.
Dies ist der Partitionierungsansatz, den wir in der Fix It-App implementiert haben, und wir sehen uns den Code dafür im Kapitel Blob Storage an. Ohne dieses Partitionierungsschema und unter Der Annahme einer durchschnittlichen Bildgröße von 3 Megabyte könnte die Fix It-App nur etwa 40.000 Aufgaben speichern, bevor die maximale Datenbankgröße von 150 Gb erreicht wird. Nach dem Entfernen der Images kann die Datenbank 10-mal so viele Aufgaben speichern. Sie können viel länger gehen, bevor Sie über die Implementierung eines horizontalen Partitionierungsschemas nachdenken müssen. Und wenn die App skaliert wird, steigen Ihre Ausgaben langsamer, da der Großteil Ihrer Speicheranforderungen in sehr kostengünstigen Blobspeicher fließt.
Horizontale Partitionierung (Sharding)
Die horizontale Portionierung ist wie das Aufteilen einer Tabelle nach Zeilen: Eine Gruppe von Zeilen geht in einen Datenspeicher, und eine andere Gruppe von Zeilen geht in einen anderen Datenspeicher.
Angesichts desselben Datensatzes wäre eine andere Möglichkeit, verschiedene Bereiche von Kundennamen in verschiedenen Datenbanken zu speichern.
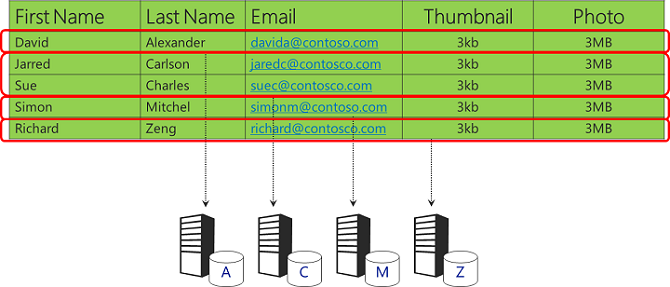
Sie möchten bei Ihrem Shardingschema sehr vorsichtig sein, um sicherzustellen, dass die Daten gleichmäßig verteilt sind, um Hotspots zu vermeiden. Dieses einfache Beispiel mit dem ersten Buchstaben des Nachnamens erfüllt diese Anforderung nicht, da viele Personen Nachnamen haben, die mit bestimmten allgemeinen Buchstaben beginnen. Sie würden die Tabellengrößenbeschränkungen früher als erwartet treffen, da einige Datenbanken sehr groß werden würden, während die meisten klein bleiben würden.
Ein Nachteil der horizontalen Partitionierung ist, dass es schwierig sein kann, Abfragen für alle Daten zu durchführen. In diesem Beispiel müsste eine Abfrage aus bis zu 26 verschiedenen Datenbanken erstellen, um alle von der App gespeicherten Daten abzurufen.
Hybridpartitionierung
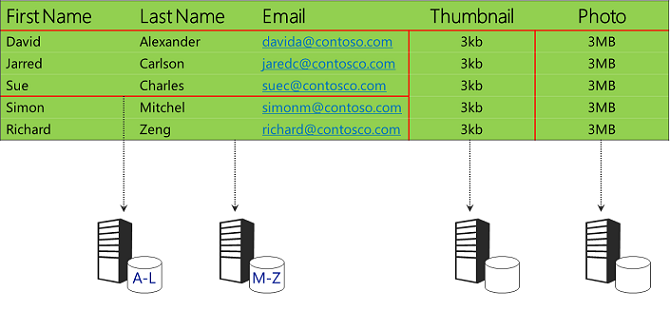
Sie können vertikale und horizontale Partitionierung kombinieren. In den Beispieldaten könnten Sie beispielsweise die Images in Blob Storage speichern und die Zeichenfolgendaten horizontal partitionieren.
Partitionieren einer Produktionsanwendung
Konzeptionell ist es leicht zu erkennen, wie ein Partitionierungsschema funktionieren würde, aber jedes Partitionierungsschema erhöht die Codekomplexität und führt zu vielen neuen Komplikationen, mit denen Sie umgehen müssen. Was tun Sie, wenn Sie Bilder in Blobspeicher verschieben, wenn der Speicherdienst ausgefallen ist? Wie gehen Sie mit der Blobsicherheit um? Was geschieht, wenn die Datenbank und der Blobspeicher nicht mehr synchronisiert werden? Wie gehen Sie beim Sharding mit Abfragen in allen Datenbanken um?
Die Komplikationen sind verwaltbar, solange Sie sie planen, bevor Sie in die Produktion gehen. Viele Leute, die diesen Wunsch später nicht getan haben. Im Durchschnitt erhält unser CAT-Team (Customer Advisory Team) etwa einmal im Monat panische Anrufe von Kunden, deren Apps wirklich gut durchstarten, und sie haben diese Planung nicht ausgeführt. Und sie sagen so etwas wie: "Hilfe! Ich habe alles in einen einzigen Datenspeicher gelegt, und in 45 Tagen wird mir der Speicherplatz dafür ausgehen!" Und wenn Sie viel Geschäftslogik in den Zugriff auf Ihren Datenspeicher integriert haben und Sie Kunden haben, die Ihre App verwenden, gibt es keine gute Zeit, während der Migration einen Tag lang auszugehen. Am Ende durchlaufen wir Herkulesbemühungen, um dem Kunden bei der laufenden Partitionierung seiner Daten ohne Downtime zu helfen. Es ist sehr aufregend und sehr beängstigend, und nicht etwas, an dem Sie beteiligt sein möchten, wenn Sie es vermeiden können! Wenn Sie sich dies im Voraus überlegen und in Ihre App integrieren, wird dies Ihr Leben erheblich erleichtern, wenn die App später wächst.
Zusammenfassung
Mit einem effektiven Partitionierungsschema kann Ihre Cloud-App ohne Engpässe auf Petabyte an Daten in der Cloud skalieren. Und Sie müssen nicht im Voraus für umfangreiche Computer oder eine umfangreiche Infrastruktur bezahlen, wie sie es bei der Ausführung der App in einem lokalen Rechenzentrum machen würden. In der Cloud können Sie kapazität nach Bedarf inkrementell hinzufügen, und Sie bezahlen nur so viel, wie Sie verwenden, wenn Sie sie verwenden.
Im nächsten Kapitel erfahren Sie, wie die App "Fix It" vertikale Partitionierung implementiert, indem Bilder in Blob Storage gespeichert werden.
Ressourcen
Weitere Informationen zu Partitionierungsstrategien finden Sie in den folgenden Ressourcen.
Dokumentation:
- Bewährte Methoden für den Entwurf von Large-Scale Services unter Windows Azure Cloud Services. Whitepaper von Mark Simms und Michael Thomassy.
- Microsoft-Muster und -Methoden: Cloudentwurfsmuster. Weitere Informationen finden Sie unter Leitfaden zur Datenpartitionierung, Shardingmuster.
Videos:
- FailSafe: Erstellen skalierbarer, resilienter Cloud Services. Neunteilige Serie von Ulrich Homann, Marc Mercuri und Mark Simms. Präsentiert allgemeine Konzepte und Architekturprinzipien auf sehr zugängliche und interessante Weise, mit Geschichten, die aus der Erfahrung des Microsoft Customer Advisory Teams (CAT) mit tatsächlichen Kunden stammen. Sehen Sie sich die Partitionierungsdiskrierung in Episode 7 an.
- Building Big: Lessons learned from Windows Azure customers ( Teil I) Mark Simms erläutert Partitionierungsschemas, Shardingstrategien, Implementieren von Sharding und SQL-Datenbank Verbunde ab 19:49 Uhr. Ähnlich wie bei der Failsafe-Serie, geht aber in weitere Anleitungen ein.
Beispielcode:
- Clouddienstgrundlagen in Windows Azure. Beispielanwendung, die eine Sharddatenbank enthält. Eine Beschreibung des implementierten Shardingschemas finden Sie unter DAL – Sharding von RDBMS im Windows Azure-Blog.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für