Behandlung vorübergehender Fehler (Erstellen Real-World Cloud-Apps mit Azure)
von Rick Anderson, Tom Dykstra
Download Fix It Project oder Download E-Book
Das E-Book Building Real World Cloud Apps with Azure basiert auf einer Präsentation, die von Scott Guthrie entwickelt wurde. Es werden 13 Muster und Methoden erläutert, die Ihnen bei der erfolgreichen Entwicklung von Web-Apps für die Cloud helfen können. Informationen zum E-Book finden Sie im ersten Kapitel.
Wenn Sie eine echte Cloud-App entwerfen, müssen Sie unter anderem darüber nachdenken, wie Sie vorübergehende Dienstunterbrechungen behandeln. Dieses Problem ist in Cloud-Apps besonders wichtig, da Sie so von Netzwerkverbindungen und externen Diensten abhängig sind. Sie können häufig kleine Störungen bekommen, die in der Regel selbstheilen, und wenn Sie nicht bereit sind, sie intelligent zu behandeln, führen sie zu einer schlechten Erfahrung für Ihre Kunden.
Ursachen für vorübergehende Fehler
In der Cloudumgebung werden Sie feststellen, dass fehler- und gelöschte Datenbankverbindungen in regelmäßigen Abständen auftreten. Dies liegt zum Teil daran, dass Sie mehr Lastenausgleichsmodule durchlaufen als in der lokalen Umgebung, in der Der Webserver und der Datenbankserver über eine direkte physische Verbindung verfügen. Wenn Sie auch von einem mehrinstanzenfähigen Dienst abhängig sind, werden Aufrufe des Diensts manchmal langsamer oder timeout angezeigt, da eine andere Person, die den Dienst verwendet, stark trifft. In anderen Fällen können Sie der Benutzer sein, der den Dienst zu häufig trifft, und der Dienst drosselt Sie absichtlich – verweigert Verbindungen – um zu verhindern, dass andere Mandanten des Diensts beeinträchtigt werden.
Verwenden einer intelligenten Wiederholungs-/Back-Off-Logik, um die Auswirkungen vorübergehender Fehler zu mindern
Anstatt eine Ausnahme auszulösen und Ihrem Kunden eine Nicht verfügbare oder Fehlerseite anzuzeigen, können Sie Fehler erkennen, die in der Regel vorübergehend sind, und den Vorgang, der zu dem Fehler geführt hat, automatisch wiederholen, in der Hoffnung, dass Sie in kürze erfolgreich sind. In den meisten Fällen ist der Vorgang beim zweiten Versuch erfolgreich, und Sie werden nach dem Fehler wiederherstellen, ohne dass der Kunde jemals wusste, dass ein Problem aufgetreten ist.
Es gibt mehrere Möglichkeiten, intelligente Wiederholungslogik zu implementieren.
Die Gruppe Microsoft Patterns & Practices verfügt über einen Anwendungsblock zur Behandlung vorübergehender Fehler, der alles für Sie erledigt, wenn Sie ADO.NET für SQL-Datenbank Zugriff verwenden (nicht über Entity Framework). Sie legen einfach eine Richtlinie für Wiederholungen fest – wie oft eine Abfrage oder ein Befehl wiederholt werden soll, und wie lange zwischen Versuchen gewartet werden soll – und umschließen Sie Ihren SQL-Code in einen using-Block .
public void HandleTransients() { var connStr = "some database"; var _policy = RetryPolicy.Create < SqlAzureTransientErrorDetectionStrategy( retryCount: 3, retryInterval: TimeSpan.FromSeconds(5)); using (var conn = new ReliableSqlConnection(connStr, _policy)) { // Do SQL stuff here. } }TFH unterstützt auch Azure In-Role Cache und Service Bus.
Wenn Sie das Entity Framework verwenden, arbeiten Sie in der Regel nicht direkt mit SQL-Verbindungen, sodass Sie dieses Muster- und Methodenpaket nicht verwenden können, aber Entity Framework 6 erstellt diese Art von Wiederholungslogik direkt in das Framework. Auf ähnliche Weise geben Sie die Wiederholungsstrategie an, und EF verwendet diese Strategie dann, wenn sie auf die Datenbank zugreift.
Um dieses Feature in der Fix It-App zu verwenden, müssen wir nur eine Klasse hinzufügen, die von DbConfiguration abgeleitet ist, und die Wiederholungslogik aktivieren.
// EF follows a Code based Configuration model and will look for a class that // derives from DbConfiguration for executing any Connection Resiliency strategies public class EFConfiguration : DbConfiguration { public EFConfiguration() { AddExecutionStrategy(() => new SqlAzureExecutionStrategy()); } }Für SQL-Datenbank Ausnahmen, die das Framework in der Regel als vorübergehende Fehler identifiziert, weist der gezeigte Code EF an, den Vorgang bis zu drei Mal zu wiederholen, mit einer exponentiellen Backoffverzögerung zwischen Wiederholungen und einer maximalen Verzögerung von 5 Sekunden. Exponentielles Backoff bedeutet, dass nach jeder fehlgeschlagenen Wiederholung ein längerer Zeitraum gewartet wird, bevor es erneut versucht wird. Wenn drei Versuche in einer Zeile fehlschlagen, wird eine Ausnahme ausgelöst. Im folgenden Abschnitt zu Trennschaltern wird erläutert, warum Sie exponentielles Backoff und eine begrenzte Anzahl von Wiederholungen benötigen.
Sie können ähnliche Probleme haben, wenn Sie den Azure Storage-Dienst verwenden, wie dies bei der Fix It-App für Blobs der Fall ist, und die .NET-Speicherclient-API implementiert bereits die gleiche Art von Logik. Sie geben einfach die Wiederholungsrichtlinie an, oder Sie müssen dies nicht einmal tun, wenn Sie mit den Standardeinstellungen zufrieden sind.
Trennschalter
Es gibt mehrere Gründe, warum Sie nicht zu oft über einen zu langen Zeitraum wiederholen möchten:
- Zu viele Benutzer, die dauerhaft fehlerhafte Anforderungen wiederholen, können die Erfahrung anderer Benutzer beeinträchtigen. Wenn Millionen von Personen wiederholte Wiederholungsanforderungen stellen, können Sie IIS-Dispatchwarteschlangen binden und verhindern, dass Ihre App Anforderungen verarbeitet, die andernfalls erfolgreich verarbeitet werden könnten.
- Wenn alle Benutzer aufgrund eines Dienstfehlers einen Wiederholungsversuch ausführen, werden möglicherweise so viele Anforderungen in die Warteschlange gestellt, dass der Dienst überflutet wird, wenn er mit der Wiederherstellung beginnt.
- Wenn der Fehler auf eine Drosselung zurückzuführen ist und ein Zeitfenster vorhanden ist, das der Dienst für die Drosselung verwendet, können fortgesetzte Wiederholungsversuche dieses Fensters verschieben und dazu führen, dass die Drosselung fortgesetzt wird.
- Möglicherweise wartet ein Benutzer darauf, dass eine Webseite gerendert wird. Die Leute zu lange warten zu lassen, ist möglicherweise ärgerlicher, als dass sie relativ schnell raten, es später erneut zu versuchen.
Exponentielles Backoff behebt einige dieser Probleme, indem die Häufigkeit von Wiederholungen eingeschränkt wird, die ein Dienst von Ihrer Anwendung erhalten kann. Sie benötigen aber auch Trennschalter: Dies bedeutet, dass Ihre App ab einem bestimmten Wiederholungsschwellenwert die Wiederholung beendet und eine andere Aktion ausführt, z. B. eine der folgenden:
- Benutzerdefinierter Fallback. Wenn Sie keinen Aktienkurs von Reuters erhalten können, können Sie ihn vielleicht von Bloomberg bekommen; Oder wenn Sie keine Daten aus der Datenbank abrufen können, können Sie sie vielleicht aus dem Cache abrufen.
- Fehler im Hintergrund. Wenn Sie von einem Dienst nicht alles oder nichts für Ihre App benötigen, geben Sie einfach NULL zurück, wenn Sie die Daten nicht abrufen können. Wenn Sie einen Fix It-Task anzeigen und der Blobdienst nicht reagiert, können Sie die Vorgangsdetails ohne das Bild anzeigen.
- Fail fast. Geben Sie dem Benutzer einen Fehler aus, um zu vermeiden, dass der Dienst mit Wiederholungsanforderungen überflutet wird, was zu Dienstunterbrechungen für andere Benutzer führen oder ein Drosselungsfenster erweitern kann. Sie können eine benutzerfreundliche Meldung "Später erneut versuchen" anzeigen.
Es gibt keine 1-Size-Fits-All-Wiederholungsrichtlinie. Sie können es in einem asynchronen Hintergrundarbeitsprozess häufiger wiederholen und länger warten als in einer synchronen Web-App, bei der ein Benutzer auf eine Antwort wartet. Sie können länger zwischen Wiederholungen für einen relationalen Datenbankdienst warten als bei einem Cachedienst. Hier finden Sie einige empfohlene Wiederholungsrichtlinien, um Ihnen eine Vorstellung davon zu geben, wie die Zahlen variieren können. ("Fast First" bedeutet keine Verzögerung vor dem ersten Wiederholungsversuch.
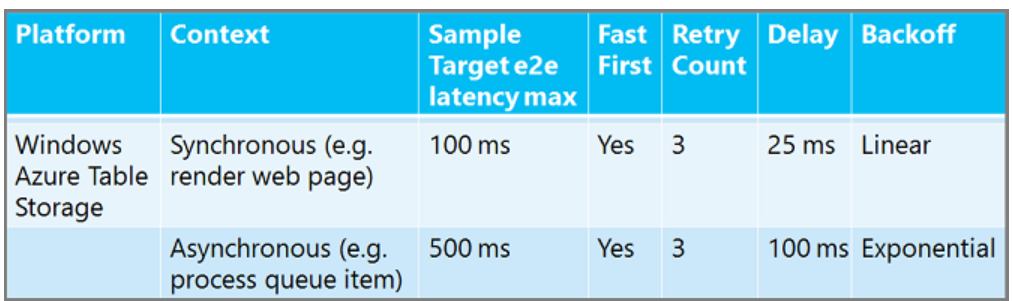
Informationen zu SQL-Datenbank Wiederholungsrichtlinien finden Sie unter Behandeln vorübergehender Fehler und Verbindungsfehler für SQL-Datenbank.
Zusammenfassung
Eine Wiederholungs-/Back-off-Strategie kann dazu beitragen, temporäre Fehler für den Kunden die meiste Zeit unsichtbar zu machen, und Microsoft stellt Frameworks bereit, mit denen Sie Ihre Arbeit bei der Implementierung einer Strategie minimieren können, unabhängig davon, ob Sie ADO.NET, Entity Framework oder den Azure Storage-Dienst verwenden.
Im nächsten Kapitel erfahren Sie, wie Sie die Leistung und Zuverlässigkeit mithilfe der verteilten Zwischenspeicherung verbessern können.
Ressourcen
Weitere Informationen finden Sie in den folgenden Ressourcen:
Dokumentation
- Bewährte Methoden für den Entwurf von Large-Scale Services in Azure Cloud Services. Whitepaper von Mark Simms und Michael Thomassy. Ähnlich wie bei der Failsafe-Serie, geht aber in weitere Anleitungen ein. Weitere Informationen finden Sie im Abschnitt Telemetrie und Diagnose.
- Failsafe: Leitfaden für resiliente Cloudarchitekturen. Whitepaper von Marc Mercuri, Ulrich Homann und Andrew Townhill. Webseitenversion der FailSafe-Videoreihe.
- Microsoft-Muster und -Methoden: Azure-Leitfaden. Weitere Informationen finden Sie unter Wiederholungsmuster, Scheduler Agent Supervisor-Muster.
- Entity Framework: Verbindungsresilienz/Wiederholungslogik. Verwenden und Anpassen des Features zur Behandlung vorübergehender Fehler von Entity Framework 6
- Verbindungsresilienz und Befehlsinterception mit dem Entity Framework in einer ASP.NET MVC-Anwendung. Im vierten Teil einer neunteiligen Tutorialreihe wird gezeigt, wie Sie die Ef 6-Verbindungsresilienzfunktion für SQL-Datenbank einrichten.
Videos
- FailSafe: Erstellen skalierbarer, resilienter Cloud Services. Neunteilige Serie von Ulrich Homann, Marc Mercuri und Mark Simms. Präsentiert allgemeine Konzepte und Architekturprinzipien auf sehr zugängliche und interessante Weise, mit Geschichten, die aus der Erfahrung des Microsoft Customer Advisory Teams (CAT) mit tatsächlichen Kunden stammen. Sehen Sie sich die Diskussion über Trennschalter in Folge 3 ab 40:55 Uhr an.
- Building Big: Lessons learned from Azure customers ( Teil II) Mark Simms spricht über das Entwerfen für Fehler, die Behandlung vorübergehender Fehler und die Instrumentierung alles.
Codebeispiel
- Clouddienstgrundlagen in Azure. Beispielanwendung, die vom Microsoft Azure-Kundenberatungsteam erstellt wurde und die die Verwendung des Enterprise Library Transient Fault Handling Block (TFH) veranschaulicht. Weitere Informationen finden Sie unter Clouddienst-Grundlagen Datenzugriffsebene - Handhabung vorübergehender Fehler. TFH wird für den Datenbankzugriff mit ADO.NET direkt (ohne Verwendung von Entity Framework) empfohlen.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für