Ausführen einer n-schichtigen Anwendung in mehreren Azure Stack Hub-Regionen für Hochverfügbarkeit
Diese Referenzarchitektur zeigt eine Reihe bewährter Methoden zum Ausführen einer n-schichtigen Anwendung in mehreren Azure Stack Hub-Regionen, um Verfügbarkeit und eine stabile Infrastruktur für die Notfallwiederherstellung zu erzielen. In diesem Dokument wird Traffic Manager verwendet, um Hochverfügbarkeit zu erreichen. Wenn Traffic Manager jedoch keine bevorzugte Lösung in Ihrer Umgebung ist, kann auch ein Paar hochverfügbarer Lastenausgleiche eingesetzt werden.
Hinweis
Beachten Sie bitte, dass der in der folgenden Architektur verwendete Traffic Manager in Azure konfiguriert werden muss und die Endpunkte, die zur Konfiguration des Traffic Manager-Profils verwendet werden, öffentlich routingfähige IP-Adressen sein müssen.
Aufbau
Diese Architektur basiert auf der Architektur aus N-schichtige Anwendung mit SQL Server.
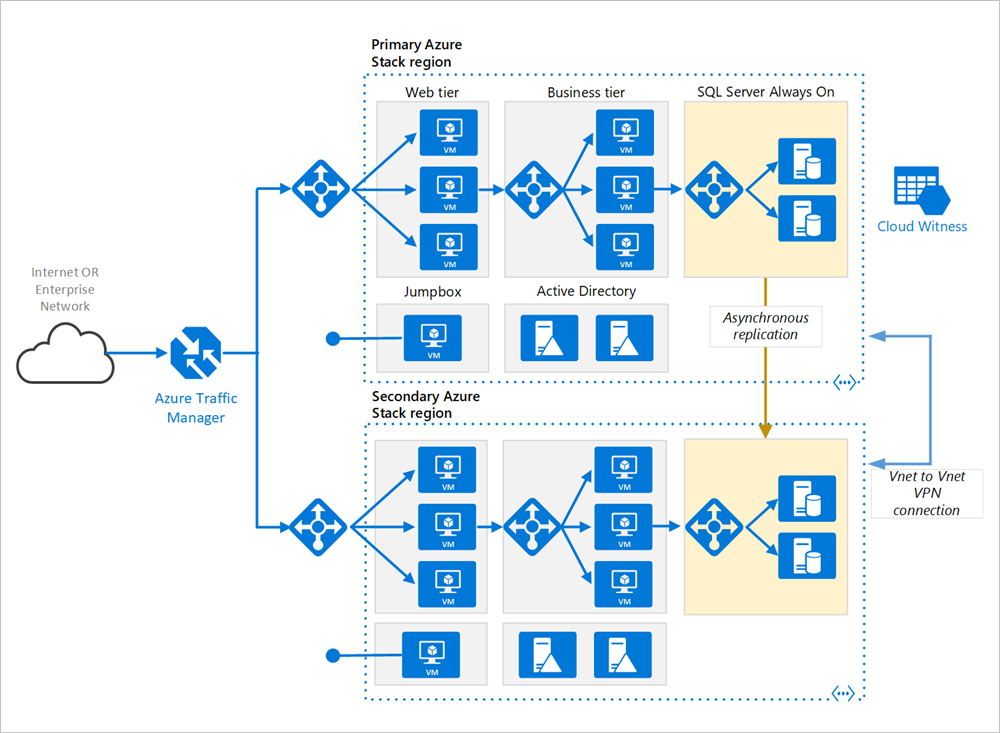
Primäre und sekundäre Regionen. Verwenden Sie zwei Regionen, um eine höhere Verfügbarkeit zu erreichen. Eine ist die primäre Region. Die andere Region ist für das Failover.
Azure Traffic Manager. Traffic Manager leitet eingehende Anforderungen an eine der Regionen weiter. Während des normalen Betriebs werden Anforderungen an die primäre Region weitergeleitet. Wenn diese Region nicht mehr verfügbar ist, führt Traffic Manager ein Failover zur sekundären Region aus. Weitere Informationen finden Sie im Abschnitt Traffic Manager-Konfiguration.
Ressourcengruppen: Erstellen Sie separate Ressourcengruppen für die primäre Region und die sekundäre Region. Dies bietet Ihnen die Flexibilität, jede Region als eine einzelne Ressourcensammlung zu verwalten. Sie können beispielsweise eine Region erneut bereitstellen, ohne die andere außer Betrieb zu nehmen. Verknüpfen Sie die Ressourcengruppen, damit Sie eine Abfrage zum Auflisten aller Ressourcen für die Anwendung ausführen können.
Virtuelle Netzwerke. Erstellen Sie für jede Region ein separates virtuelles Netzwerk. Stellen Sie sicher, dass sich die Adressräume nicht überschneiden.
SQL Server Always On-Verfügbarkeitsgruppe. Bei Verwendung von SQL Server werden SQL Always On-Verfügbarkeitsgruppen empfohlen, um Hochverfügbarkeit zu erzielen. Erstellen Sie eine einzelne Verfügbarkeitsgruppe, die SQL Server-Instanzen in beiden Regionen enthält.
VNET-zu-VNET-VPN-Verbindung. Da VNET-Peering noch nicht für Azure Stack Hub verfügbar ist, verwenden Sie eine VNET-zu-VNET-VPN-Verbindung, um die beiden VNETs zu verbinden. Weitere Informationen finden Sie unter Gewusst wie: Verbinden von zwei VNETs per Peering.
Empfehlungen
Eine Architektur mit mehreren Regionen kann eine höhere Verfügbarkeit als eine Bereitstellung in einer einzelnen Region bieten. Wenn ein regionaler Ausfall die primäre Region beeinträchtigt, können Sie mit Traffic Manager ein Failover zur sekundären Region ausführen. Diese Architektur kann auch hilfreich sein, wenn bei einem einzelnen Subsystem der Anwendung ein Fehler auftritt.
Es gibt mehrere allgemeine Vorgehensweisen für das Erreichen von Hochverfügbarkeit mit mehreren Regionen:
Aktiv/Passiv mit unmittelbar betriebsbereitem Standbyserver. Der Datenverkehr wird an eine Region weitergeleitet, während die andere im Hot Standby wartet. Hot Standby (unmittelbar betriebsbereit) bedeutet, dass die virtuellen Computer in der sekundären Region jederzeit zugeordnet sind und ausgeführt werden.
Aktiv/Passiv mit Standbymodus „Verzögert betriebsbereit“ . Der Datenverkehr wird an eine Region weitergeleitet, während die andere im Cold Standby wartet. Cold Standby (verzögert betriebsbereit) bedeutet, dass die virtuellen Computer in der sekundären Region erst zugewiesen werden, wenn sie für das Failover benötigt werden. Dieser Ansatz erfordert weniger Ausführungszeit, es dauert aber im Allgemeinen länger, bis bei einem Ausfall alle Komponenten online geschaltet sind.
Aktiv/Aktiv. Beide Regionen sind aktiv, und Anforderungen werden per Lastenausgleich zwischen ihnen verteilt. Wenn eine Region nicht verfügbar ist, wird sie aus der Rotation entfernt.
In dieser Referenzarchitektur liegt der Fokus auf aktiv/passiv mit Hot Standby, wobei Traffic Manager für das Failover verwendet wird. Sie können eine kleine Anzahl virtueller Computer für Hot Standby bereitstellen und dann nach Bedarf aufskalieren.
Traffic Manager-Konfiguration
Beachten Sie beim Konfigurieren von Traffic Manager die folgenden Punkte:
Routing: Traffic Manager unterstützt mehrere Routingalgorithmen. Verwenden Sie für das in diesem Artikel beschriebenen Szenario Routing nach Priorität (ehemals Routingmethode Failover). Bei dieser Einstellung sendet Traffic Manager alle Anforderungen an die primäre Region, bis die primäre Region nicht mehr erreichbar ist. Zu diesem Zeitpunkt wird automatisch ein Failover zur sekundären Region ausgeführt. Weitere Informationen finden Sie unter Konfigurieren der Routingmethode „Failover“.
Integritätstest: Traffic Manager verwendet einen HTTP- oder HTTPS-Test, um die Verfügbarkeit jeder Region zu überwachen. Der Test prüft auf eine HTTP 200-Antwort für einen angegebenen URL-Pfad. Es hat sich bewährt, einen Endpunkt zu erstellen, der die Gesamtintegrität der Anwendung meldet, und diesen Endpunkt für den Integritätstest zu verwenden. Andernfalls meldet der Test eventuell einen fehlerfreien Endpunkt, obwohl wichtige Teile der Anwendung fehlerhaft sind. Weitere Informationen finden Sie unter Überwachungsmuster für den Integritätsendpunkt.
Wenn Traffic Manager ein Failover ausführt, können die Clients die Anwendung für eine bestimmte Zeit nicht erreichen. Die Dauer wird durch folgende Faktoren beeinflusst:
Der Integritätstest muss erkennen, dass die primäre Region nicht erreichbar ist.
Die DNS-Server müssen die zwischengespeicherten DNS-Einträge für die IP-Adresse aktualisieren, die von der DNS-Gültigkeitsdauer (TTL) abhängig ist. Die Standardgültigkeitsdauer beträgt 300 Sekunden (5 Minuten), Sie können diesen Wert aber bei der Erstellung des Traffic Manager-Profils anpassen.
Weitere Informationen finden Sie unter Traffic Manager-Überwachung.
Bei Failovern durch Traffic Manager sollten Sie ein manuelles Failback ausführen, anstatt ein automatisches Failback zu implementieren. Andernfalls könnte eine Situation eintreten, bei der die Anwendung zwischen den Regionen hin und her wechselt. Überprüfen Sie vor einem Failback, ob alle Subsysteme der Anwendung fehlerfrei sind.
Beachten Sie, dass Traffic Manager in der Standardeinstellung automatisch Failbacks ausführt. Um dies zu verhindern, verringern Sie die Priorität der primären Region nach einem Failover manuell. Angenommen, die primäre Region hat die Priorität 1 und die sekundäre Datenbank die Priorität 2. Nach einem Failover legen Sie dann die Priorität der primären Region auf 3 fest, um ein automatisches Failback zu verhindern. Wenn Sie wieder zurück wechseln möchten, ändern Sie die Priorität wieder in 1.
Mit dem folgenden Befehl für die Azure-Befehlszeilenschnittstelle wird die Priorität aktualisiert:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --priority 3
Ein anderer Ansatz besteht darin, den Endpunkt vorübergehend zu deaktivieren, bis Sie zum Ausführen eines Failbacks bereit sind:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --endpoint-status Disabled
Je nach Ursache eines Failovers müssen Sie die Ressourcen innerhalb einer Region möglicherweise erneut bereitstellen. Testen Sie vor dem Failback die Betriebsbereitschaft. Beim Test sollten z.B. folgende Punkte geprüft werden:
Virtuelle Computer sind richtig konfiguriert. (Alle erforderliche Software ist installiert, IIS wird ausgeführt usw.)
Subsysteme der Anwendung sind fehlerfrei.
Funktionstests. (Beispielsweise, dass die Datenbankebene von der Webebene aus erreichbar ist.)
Konfigurieren von SQL Server Always On-Verfügbarkeitsgruppen
Bei früheren Versionen als Windows Server 2016 erfordern SQL Server Always On-Verfügbarkeitsgruppen einen Domänencontroller, und alle Knoten in der Verfügbarkeitsgruppe müssen sich in der gleichen Active Directory (AD)-Domäne befinden.
So konfigurieren Sie die Verfügbarkeitsgruppe:
Platzieren Sie mindestens zwei Domänencontroller in jeder Region.
Weisen Sie jedem Domänencontroller eine statische IP-Adresse zu.
Erstellen Sie ein VPN, um eine Kommunikation zwischen zwei virtuellen Netzwerken zu ermöglichen.
Fügen Sie für jedes virtuelle Netzwerk die IP-Adressen der Domänencontroller (beider Regionen) zur DNS-Serverliste hinzu. Sie können den folgenden CLI-Befehl verwenden. Weitere Informationen finden Sie unter Ändern von DNS-Servern.
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"Erstellen Sie einen Windows Server-Failovercluster (WSFC), der die SQL Server-Instanzen in beiden Regionen enthält.
Erstellen Sie eine SQL Server Always On-Verfügbarkeitsgruppe, die SQL Server-Instanzen sowohl in der primären als auch der sekundären Region enthält. Die Schritte finden Sie unter Erweitern der Always On-Verfügbarkeitsgruppe auf ein Azure-Remoterechenzentrum (PowerShell).
Legen Sie das primäre Replikat in der primären Region ab.
Legen Sie ein oder mehrere sekundäre Replikate in der primären Region ab. Konfigurieren Sie diese für die Verwendung synchroner Commits mit automatischem Failover.
Legen Sie ein oder mehrere sekundäre Replikate in der sekundären Region ab. Konfigurieren Sie diese aus Leistungsgründen für die Verwendung asynchroner Commits. (Andernfalls müssen alle T-SQL-Transaktionen auf einem Roundtrip über das Netzwerk zur sekundären Region warten.)
Hinweis
Replikate mit asynchronem Commit unterstützen kein automatisches Failover.
Überlegungen zur Verfügbarkeit
Bei einer komplexen n-schichtigen Anwendung müssen Sie möglicherweise nicht die gesamte Anwendung in der sekundären Region replizieren. Stattdessen replizieren Sie nur ein kritisches Subsystem, das zur Unterstützung der Geschäftskontinuität erforderlich ist.
Traffic Manager ist eine mögliche Schwachstelle im System. Wenn beim Traffic Manager-Dienst ein Fehler auftritt, können Clients während der Ausfallzeit nicht auf Ihre Anwendung zugreifen. In der Vereinbarung zum Servicelevel (SLA) für Traffic Manager erfahren Sie, ob Ihre geschäftlichen Anforderungen für Hochverfügbarkeit mit Traffic Manager allein erfüllt werden. Wenn dies nicht der Fall ist, erwägen Sie als Failback eine andere Verwaltungslösung für den Datenverkehr. Wenn der Azure Traffic Manager-Dienst fehlerhaft ist, ändern Sie die CNAME-Einträge im DNS so, dass diese auf die andere Verwaltungslösung für den Datenverkehr verweisen. (Dieser Schritt muss manuell durchgeführt werden. Bis die DNS-Änderungen weitergegeben wurden, ist die Anwendung nicht verfügbar.)
Für den SQL Server-Cluster sind zwei Failoverszenarien zu berücksichtigen:
Bei allen SQL Server-Datenbankreplikaten in der primären Region treten Fehler auf. Dies kann z. B. während eines regionalen Ausfalls vorkommen. In diesem Fall müssen Sie für die Verfügbarkeitsgruppe ein manuelles Failover ausführen, obwohl Traffic Manager automatisch ein Failover auf dem Front-End ausführt. Führen Sie die Schritte unter Ausführen eines erzwungenen manuellen Failovers einer SQL Server-Verfügbarkeitsgruppe aus, in denen beschrieben ist, wie ein erzwungenes Failover mithilfe von SQL Server Management Studio, Transact-SQL oder PowerShell in SQL Server 2016 ausgeführt wird.
Warnung
Bei einem erzwungenem Failover besteht das Risiko eines Datenverlusts. Sobald die primäre Region wieder online ist, erstellen Sie eine Momentaufnahme der Datenbank, und verwenden Sie tablediff, um die Unterschiede zu ermitteln.
Traffic Manager führt ein Failover zur sekundären Region aus, doch ist das primäre SQL Server-Datenbankreplikat weiterhin verfügbar. So kann beispielsweise die Front-End-Ebene fehlgeschlagen, ohne dass dies Auswirkungen auf die virtuellen SQL Server-Computer hat. In diesem Fall wird der Internetdatenverkehr an die sekundäre Region weitergeleitet, und diese Region kann immer noch eine Verbindung mit dem primären Replikat herstellen. Es kommt jedoch zu erhöhter Latenz, da die SQL Server-Verbindungen regionsübergreifend verlaufen. In dieser Situation sollten Sie auf folgende Weise ein manuelles Failover ausführen:
Wechseln Sie bei einem SQL Server-Datenbankreplikat in der sekundären Region vorübergehend zu synchronen Commits. Dadurch wird sichergestellt, dass während des Failovers kein Datenverlust auftritt.
Führen Sie ein Failover zu diesem Replikat aus.
Wenn Sie ein Failback zur primären Region ausführen, ändern Sie die Einstellung wieder in asynchrone Commits.
Überlegungen zur Verwaltbarkeit
Beim Aktualisieren der Bereitstellung aktualisieren Sie immer jeweils eine Region, um die Möglichkeit eines globalen Fehlers aufgrund einer falschen Konfiguration oder eines Fehlers in der Anwendung zu reduzieren.
Testen Sie die Resilienz des Systems gegenüber Fehlern. Hier sind einige häufige Fehlerszenarien aufgeführt, die getestet werden können:
Herunterfahren von VM-Instanzen
Auslasten von Ressourcen, z.B. CPU und Speicher
Trennen/Verzögern des Netzwerks
Absturz von Prozessen
Ablauf von Zertifikaten
Simulieren von Hardwarefehlern
Herunterfahren des DNS-Diensts auf den Domänencontrollern
Messen Sie die Wiederherstellungszeiten, und stellen Sie sicher, dass diese Ihren geschäftlichen Anforderungen entsprechen. Testen Sie auch Kombinationen von Fehlermodi.
Nächste Schritte
- Weitere Informationen zu Azure-Cloudmustern finden Sie unter Cloudentwurfsmuster.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für